
10 Dec 2025
ChronusOmni introduces a framework enhancing temporal awareness in omni large language models for both explicit and implicit audiovisual temporal grounding. It employs a novel temporal interleaved tokenization, a two-stage training strategy, and the new ChronusAV dataset, achieving state-of-the-art performance across six distinct audiovisual temporal grounding subtasks.

05 Dec 2025

IMAgent introduces an open-source vision agent trained entirely through end-to-end reinforcement learning to excel at complex multi-image tasks. This agent, developed by MeiTuan and USTC, integrates specialized visual tools and achieves state-of-the-art performance by dynamically managing visual attention across multiple images during multi-step reasoning.

09 Dec 2025
Understanding objects is fundamental to computer vision. Beyond object recognition that provides only a category label as typical output, in-depth object understanding represents a comprehensive perception of an object category, involving its components, appearance characteristics, inter-category relationships, contextual background knowledge, etc. Developing such capability requires sufficient multi-modal data, including visual annotations such as parts, attributes, and co-occurrences for specific tasks, as well as textual knowledge to support high-level tasks like reasoning and question answering. However, these data are generally task-oriented and not systematically organized enough to achieve the expected understanding of object categories. In response, we propose the Visual Knowledge Base that structures multi-modal object knowledge as graphs, and present a construction framework named VisKnow that extracts multi-modal, object-level knowledge for object understanding. This framework integrates enriched aligned text and image-source knowledge with region annotations at both object and part levels through a combination of expert design and large-scale model application. As a specific case study, we construct AnimalKB, a structured animal knowledge base covering 406 animal categories, which contains 22K textual knowledge triplets extracted from encyclopedic documents, 420K images, and corresponding region annotations. A series of experiments showcase how AnimalKB enhances object-level visual tasks such as zero-shot recognition and fine-grained VQA, and serves as challenging benchmarks for knowledge graph completion and part segmentation. Our findings highlight the potential of automatically constructing visual knowledge bases to advance visual understanding and its practical applications. The project page is available at this https URL.

04 Dec 2025

MemLoRA introduces a framework for deploying memory-augmented conversational AI systems directly on edge devices by distilling specialized expert adapters into small language models. This approach reduces memory and computational costs by 10-20x while achieving performance comparable to cloud-based large models, and MemLoRA-V further enables native visual understanding with high accuracy.

02 Dec 2025


WorldMM, developed by researchers at KAIST, NTU, and DeepAuto.ai, introduces a dynamic multimodal memory agent for reasoning over ultra-long videos. The system achieved an average accuracy of 69.5% across five long video question-answering benchmarks, representing an 8.4% performance gain over the strongest prior baseline by adaptively integrating textual and visual memories across multiple temporal scales.

10 Dec 2025

Recent advances in multimodal large language models (MLLMs) have led to impressive progress across various benchmarks. However, their capability in understanding infrared images remains unexplored. To address this gap, we introduce IF-Bench, the first high-quality benchmark designed for evaluating multimodal understanding of infrared images. IF-Bench consists of 499 images sourced from 23 infrared datasets and 680 carefully curated visual question-answer pairs, covering 10 essential dimensions of image understanding. Based on this benchmark, we systematically evaluate over 40 open-source and closed-source MLLMs, employing cyclic evaluation, bilingual assessment, and hybrid judgment strategies to enhance the reliability of the results. Our analysis reveals how model scale, architecture, and inference paradigms affect infrared image comprehension, providing valuable insights for this area. Furthermore, we propose a training-free generative visual prompting (GenViP) method, which leverages advanced image editing models to translate infrared images into semantically and spatially aligned RGB counterparts, thereby mitigating domain distribution shifts. Extensive experiments demonstrate that our method consistently yields significant performance improvements across a wide range of MLLMs. The benchmark and code are available at this https URL.
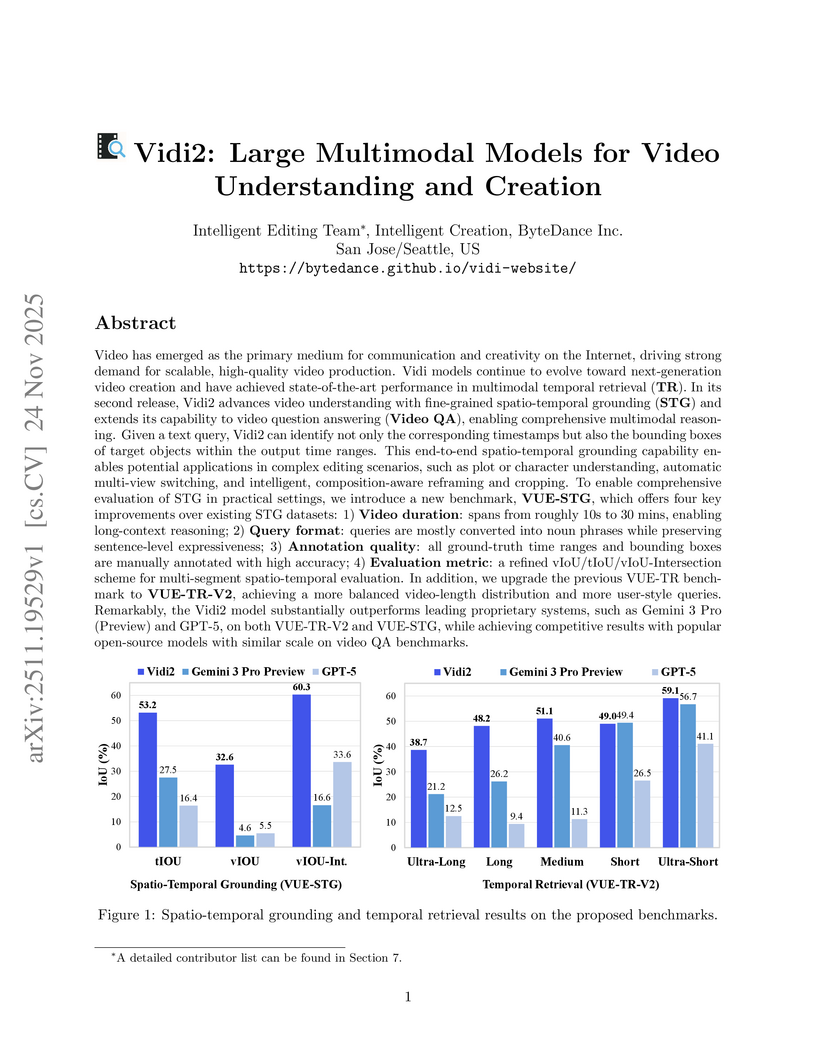
24 Nov 2025

ByteDance's Vidi2 is a large multimodal model for video understanding and creation, achieving state-of-the-art performance in end-to-end spatio-temporal grounding and enhanced temporal retrieval on newly introduced benchmarks. The model notably outperforms proprietary competitors like Gemini 3 Pro in spatio-temporal accuracy and temporal retrieval, serving as a foundation for intelligent video editing applications.

04 Dec 2025
Jina AI introduced JINA-VLM, a 2.4-billion parameter vision-language model, which sets a new benchmark for multilingual visual question answering among open models of similar size. The model also demonstrates robust performance on general English VQA tasks and incorporates an attention-pooling connector that reduces visual tokens by 4x, enhancing efficiency.

26 Nov 2025
Recent advances in multimodal large language models (LLMs) have highlighted their potential for medical and surgical applications. However, existing surgical datasets predominantly adopt a Visual Question Answering (VQA) format with heterogeneous taxonomies and lack support for pixel-level segmentation, limiting consistent evaluation and applicability. We present SurgMLLMBench, a unified multimodal benchmark explicitly designed for developing and evaluating interactive multimodal LLMs for surgical scene understanding, including the newly collected Micro-surgical Artificial Vascular anastomosIS (MAVIS) dataset. It integrates pixel-level instrument segmentation masks and structured VQA annotations across laparoscopic, robot-assisted, and micro-surgical domains under a unified taxonomy, enabling comprehensive evaluation beyond traditional VQA tasks and richer visual-conversational interactions. Extensive baseline experiments show that a single model trained on SurgMLLMBench achieves consistent performance across domains and generalizes effectively to unseen datasets. SurgMLLMBench will be publicly released as a robust resource to advance multimodal surgical AI research, supporting reproducible evaluation and development of interactive surgical reasoning models.

03 Dec 2025
Turing Inc. and academic collaborators developed Text-Printed Image (TPI), a framework that bridges the image-text modality gap for training Large Vision-Language Models (LVLMs) in text-centric settings. The method generates synthetic images by rendering textual descriptions, leading to superior downstream performance over Text-to-Image baselines and dramatically faster data generation at 154.40 images/second on a CPU.

05 Dec 2025


Researchers introduced M4-RAG, a comprehensive benchmark for evaluating Retrieval-Augmented Generation (RAG) in multilingual, multicultural, and multimodal contexts, finding that RAG benefits smaller Vision-Language Models but shows diminishing returns or performance degradation for larger models, along with a pervasive English bias in reasoning.

04 Dec 2025
Researchers from East China Normal University, Zhejiang University of Technology, and INSAIT introduced StreamEQA, the first benchmark for streaming video question answering in embodied scenarios. The benchmark systematically evaluates Video-LLMs across perception, interaction, and planning tasks with backward, real-time, and forward reasoning, revealing that state-of-the-art models achieve only about 61% accuracy at best and struggle significantly with higher-level embodied reasoning and anticipatory tasks.

04 Dec 2025
Preference-conditioned image generation seeks to adapt generative models to individual users, producing outputs that reflect personal aesthetic choices beyond the given textual prompt. Despite recent progress, existing approaches either fail to capture nuanced user preferences or lack effective mechanisms to encode personalized visual signals. In this work, we propose a multimodal framework that leverages multimodal large language models (MLLMs) to extract rich user representations and inject them into diffusion-based image generation. We train the MLLM with a preference-oriented visual question answering task to capture fine-grained semantic cues. To isolate preference-relevant features, we introduce two complementary probing tasks: inter-user discrimination to distinguish between different users, and intra-user discrimination to separate liked from disliked content. To ensure compatibility with diffusion text encoders, we design a maximum mean discrepancy-based alignment loss that bridges the modality gap while preserving multimodal structure. The resulting embeddings are used to condition the generator, enabling faithful adherence to both prompts and user preferences. Extensive experiments demonstrate that our method substantially outperforms strong baselines in both image quality and preference alignment, highlighting the effectiveness of representation extraction and alignment for personalized generation.

02 Dec 2025
Vision-Language Models (VLMs) show promise in medical diagnosis, yet suffer from reasoning detachment, where linguistically fluent explanations drift from verifiable image evidence, undermining clinical trust. Recent multi-agent frameworks simulate Multidisciplinary Team (MDT) debates to mitigate single-model bias, but open-ended discussions amplify textual noise and computational cost while failing to anchor reasoning to visual evidence, the cornerstone of medical decision-making. We propose UCAgents, a hierarchical multi-agent framework enforcing unidirectional convergence through structured evidence auditing. Inspired by clinical workflows, UCAgents forbids position changes and limits agent interactions to targeted evidence verification, suppressing rhetorical drift while amplifying visual signal extraction. In UCAgents, a one-round inquiry discussion is introduced to uncover potential risks of visual-textual misalignment. This design jointly constrains visual ambiguity and textual noise, a dual-noise bottleneck that we formalize via information theory. Extensive experiments on four medical VQA benchmarks show UCAgents achieves superior accuracy (71.3% on PathVQA, +6.0% over state-of-the-art) with 87.7% lower token cost, the evaluation results further confirm that UCAgents strikes a balance between uncovering more visual evidence and avoiding confusing textual interference. These results demonstrate that UCAgents exhibits both diagnostic reliability and computational efficiency critical for real-world clinical deployment. Code is available at this https URL.

29 Nov 2025
Multimodal Large Language Models (MLLMs) have emerged as powerful tools for chart comprehension. However, they heavily rely on extracted content via OCR, which leads to numerical hallucinations when chart textual annotations are sparse. While existing methods focus on scaling instructions, they fail to address the fundamental challenge, i.e., reasoning with visual perception. In this paper, we identify a critical observation: MLLMs exhibit weak grounding in chart elements and proportional relationships, as evidenced by their inability to localize key positions to match their reasoning. To bridge this gap, we propose PointCoT, which integrates reflective interaction into chain-of-thought reasoning in charts. By prompting MLLMs to generate bounding boxes and re-render charts based on location annotations, we establish connections between textual reasoning steps and visual grounding regions. We further introduce an automated pipeline to construct ChartPoint-SFT-62k, a dataset featuring 19.2K high-quality chart samples with step-by-step CoT, bounding box, and re-rendered visualizations. Leveraging this data, we develop two instruction-tuned models, ChartPointQ2 and ChartPointQ2.5, which outperform state-of-the-art across several chart benchmarks, e.g., +5.04\% on ChartBench.

27 Nov 2025

In a globalized world, cultural elements from diverse origins frequently appear together within a single visual scene. We refer to these as culture mixing scenarios, yet how Large Vision-Language Models (LVLMs) perceive them remains underexplored. We investigate culture mixing as a critical challenge for LVLMs and examine how current models behave when cultural items from multiple regions appear together. To systematically analyze these behaviors, we construct CultureMix, a food Visual Question Answering (VQA) benchmark with 23k diffusion-generated, human-verified culture mixing images across four subtasks: (1) food-only, (2) food+food, (3) food+background, and (4) food+food+background. Evaluating 10 LVLMs, we find consistent failures to preserve individual cultural identities in mixed settings. Models show strong background reliance, with accuracy dropping 14% when cultural backgrounds are added to food-only baselines, and they produce inconsistent predictions for identical foods across different contexts. To address these limitations, we explore three robustness strategies. We find supervised fine-tuning using a diverse culture mixing dataset substantially improve model consistency and reduce background sensitivity. We call for increased attention to culture mixing scenarios as a critical step toward developing LVLMs capable of operating reliably in culturally diverse real-world environments.

28 Nov 2025
Existing Multimodal Knowledge-Based Visual Question Answering (MKB-VQA) benchmarks suffer from "visual shortcuts", as the query image typically matches the primary subject entity of the target document. We demonstrate that models can exploit these shortcuts, achieving comparable results using visual cues alone. To address this, we introduce Relational Entity Text-Image kNowledge Augmented (RETINA) benchmark, automatically constructed using an LLM-driven pipeline, consisting of 120k training and 2k human-curated test set. RETINA contains queries referencing secondary subjects (i.e. related entities) and pairs them with images of these related entities, removing the visual shortcut. When evaluated on RETINA existing models show significantly degraded performance, confirming their reliance on the shortcut. Furthermore, we propose Multi-Image MultImodal Retriever (MIMIR), which enriches document embeddings by augmenting images of multiple related entities, effectively handling RETINA, unlike prior work that uses only a single image per document. Our experiments validate the limitations of existing benchmarks and demonstrate the effectiveness of RETINA and MIMIR. Our project is available at: Project Page.

28 Nov 2025
Recent advances in large vision-language models (VLMs) have shown significant promise for 3D scene understanding. Existing VLM-based approaches typically align 3D scene features with the VLM's embedding space. However, this implicit alignment often yields suboptimal performance due to the scarcity of 3D data and the inherent complexity of spatial relationships in 3D environments. To address these limitations, we propose a novel hierarchical multimodal representation for 3D scene reasoning that explicitly aligns with VLMs at the input space by leveraging both multi-view images and text descriptions. The text descriptions capture spatial relationships by referencing the 3D coordinates of detected objects, while the multi-view images include a top-down perspective and four directional views (forward, left, right, and backward), ensuring comprehensive scene coverage. Additionally, we introduce a hierarchical feature representation that aggregates patch-level image features into view-level and scene-level representations, enabling the model to reason over both local and global scene context. Experimental results on both situated 3D Q&A and general 3D Q&A benchmarks demonstrate the effectiveness of our approach.

27 Nov 2025
We introduce WearVQA, the first benchmark specifically designed to evaluate the Visual Question Answering (VQA) capabilities of multi-model AI assistant on wearable devices like smart glasses. Unlike prior benchmarks that focus on high-quality, third-person imagery, WearVQA reflects the unique challenges of ego-centric interaction-where visual inputs may be occluded, poorly lit, unzoomed, or blurry, and questions are grounded in realistic wearable use cases. The benchmark comprises 2,520 carefully curated image-question-answer triplets, spanning 7 diverse image domains including both text-centric and general scenes, 10 cognitive task types ranging from basic recognition to various forms of reasoning, and 6 common wearables-specific image quality issues. All questions are designed to be answerable using only the visual input and common senses. WearVQA is paired with a rigorous LLM-as-a-judge evaluation framework with 96% labeling accuracy. Open-source and proprietary multi-model LLMs achieved a QA accuracy as low as 24-52% on WearVQA, with substantial drops on lower-quality images and reasoning-heavy tasks. These observations position WearVQA as a comprehensive and challenging benchmark for guiding technical advancement towards robust, real-world multi-model wearables AI systems.
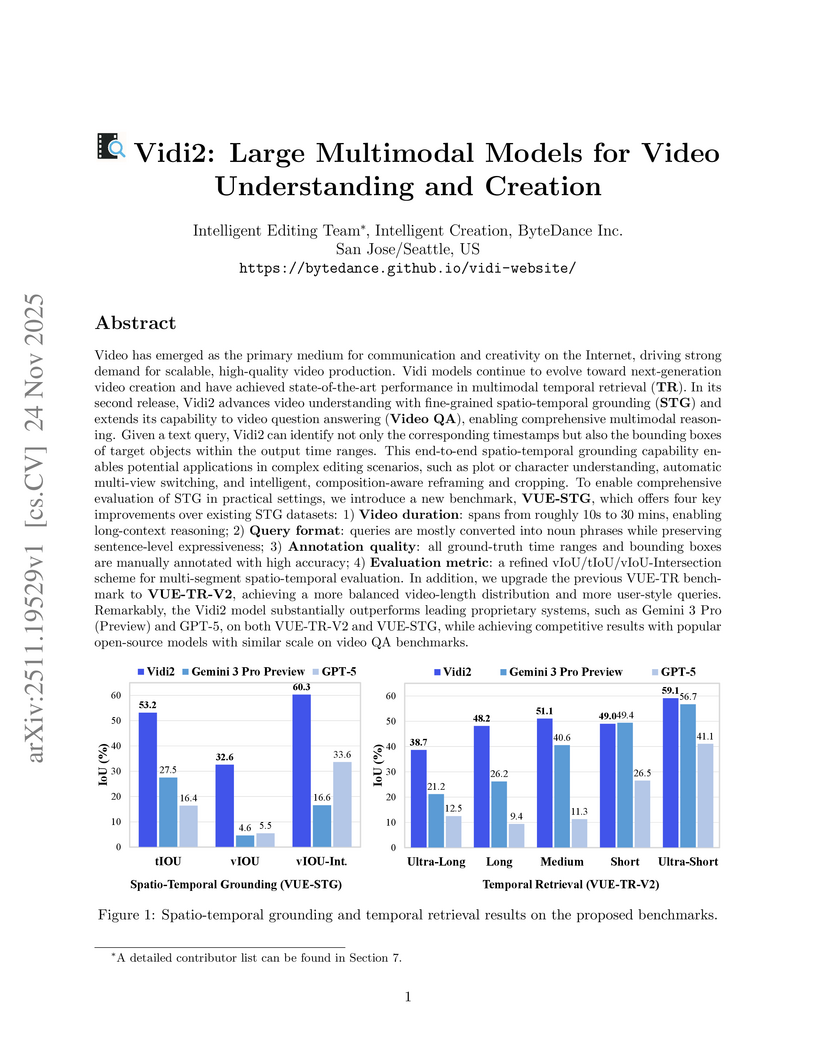
24 Nov 2025
Vidi2 is a large multimodal model developed by ByteDance that integrates fine-grained spatio-temporal grounding and enhanced temporal retrieval for video content. It demonstrates superior performance over models like Gemini 3 Pro and GPT-5 on new benchmarks, enabling precise localization of objects in both time and space from natural language queries to facilitate advanced video creation.
There are no more papers matching your filters at the moment.
