
16 Oct 2025


The WoW project introduces a generative world model, grounded in 7,300 hours of robot interaction data, that develops authentic physical intuition by integrating perception, imagination, reflection, and action. It achieves state-of-the-art performance on a new benchmark, WoWBench, and demonstrates robust real-world robot manipulation.

20 Oct 2025

RoboBench introduces a comprehensive evaluation benchmark for Multimodal Large Language Models (MLLMs) acting as embodied brains, assessing five cognitive dimensions through real-world robotic data and a novel MLLM-as-world-simulator for planning. The benchmark reveals that current MLLMs still lag behind human performance across all evaluated cognitive abilities, particularly in complex planning and execution failure analysis.

01 Oct 2025


Diffusion-based models for robotic control, including vision-language-action (VLA) and vision-action (VA) policies, have demonstrated significant capabilities. Yet their advancement is constrained by the high cost of acquiring large-scale interaction datasets. This work introduces an alternative paradigm for enhancing policy performance without additional model training. Perhaps surprisingly, we demonstrate that the composed policies can exceed the performance of either parent policy. Our contribution is threefold. First, we establish a theoretical foundation showing that the convex composition of distributional scores from multiple diffusion models can yield a superior one-step functional objective compared to any individual score. A Grönwall-type bound is then used to show that this single-step improvement propagates through entire generation trajectories, leading to systemic performance gains. Second, motivated by these results, we propose General Policy Composition (GPC), a training-free method that enhances performance by combining the distributional scores of multiple pre-trained policies via a convex combination and test-time search. GPC is versatile, allowing for the plug-and-play composition of heterogeneous policies, including VA and VLA models, as well as those based on diffusion or flow-matching, irrespective of their input visual modalities. Third, we provide extensive empirical validation. Experiments on Robomimic, PushT, and RoboTwin benchmarks, alongside real-world robotic evaluations, confirm that GPC consistently improves performance and adaptability across a diverse set of tasks. Further analysis of alternative composition operators and weighting strategies offers insights into the mechanisms underlying the success of GPC. These results establish GPC as a simple yet effective method for improving control performance by leveraging existing policies.

08 Oct 2025

A 4D generative world model named WristWorld synthesizes high-quality wrist-view videos for robotic manipulation solely from third-person anchor views. This framework reduces the data gap between anchor and wrist perspectives, yielding a 42.4% reduction in the anchor-wrist performance gap and a 5% increase in task completion success rates for downstream Vision-Language-Action (VLA) models on the Calvin benchmark.
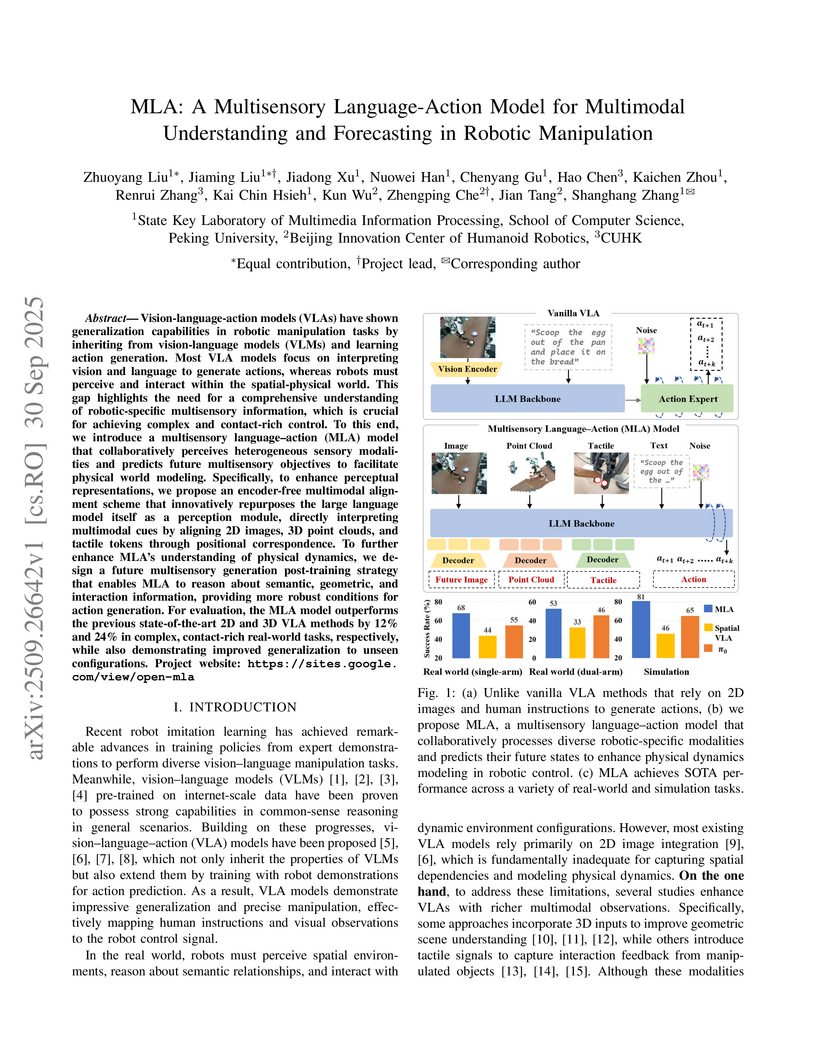
30 Sep 2025

The MLA model integrates 2D images, 3D point clouds, and tactile signals through an encoder-free LLM-based perception module, coupled with a multisensory future generation strategy, to enhance physical-world understanding and action generation in robotic manipulation. This approach achieves superior success rates on complex real-world tasks and demonstrates improved generalization compared to prior methods.

21 Feb 2025

ChatVLA presents a Vision-Language-Action model that successfully unifies multimodal understanding and embodied robot control into a single end-to-end neural network. The model achieves state-of-the-art performance in both visual question answering and 25 real-world robot manipulation tasks by mitigating common training challenges.

27 May 2025

RoboMIND introduces a large-scale, multi-embodiment dataset for robot manipulation, collected under unified standards across four distinct robot types, including a humanoid. This dataset significantly enhances the performance and generalization capabilities of Vision-Language-Action models, enabling higher success rates on complex real-world tasks and facilitating cross-embodiment policy transfer.

04 Nov 2025

The XR-1 framework introduces Unified Vision-Motion Codes (UVMC) to integrate visual dynamics and robotic motion into a shared latent space, enabling scalable pretraining for Vision-Language-Action (VLA) models. This approach demonstrates superior performance and generalization across diverse real-world robotic tasks and embodiments, outperforming state-of-the-art baselines.

27 Oct 2025
Self-evolution, the ability of agents to autonomously improve their reasoning and behavior, is essential for the embodied domain with long-horizon, real-world tasks. Despite current advancements in reinforcement fine-tuning (RFT) showing strong performance in enhancing reasoning in LLMs, its potential to enable self-evolving embodied intelligence with multi-modal interactions remains largely unexplored. Specifically, reinforcement fine-tuning faces two fundamental obstacles in embodied settings: (i) the lack of accessible intermediate rewards in multi-step reasoning tasks limits effective learning signals, and (ii) reliance on hand-crafted reward functions restricts generalization to novel tasks and environments. To address these challenges, we present Self-Evolving Embodied Agents-R1, SEEA-R1, the first RFT framework designed for enabling the self-evolving capabilities of embodied agents. Specifically, to convert sparse delayed rewards into denser intermediate signals that improve multi-step reasoning, we propose Tree-based group relative policy optimization (Tree-GRPO) integrates Monte Carlo Tree Search into GRPO. To generalize reward estimation across tasks and scenes, supporting autonomous adaptation and reward-driven self-evolution, we further introduce Multi-modal Generative Reward Model (MGRM). To holistically evaluate the effectiveness of SEEA-R1, we evaluate on the ALFWorld benchmark, surpassing state-of-the-art methods with scores of 85.07% (textual) and 46.27% (multi-modal), outperforming prior models including GPT-4o. SEEA-R1 also achieves scores of 80.3% (textual) and 44.03% (multi-modal) without ground truth reward, surpassing all open-source baselines and highlighting its scalability as a self-evolving embodied agent. Additional experiments and qualitative analysis further support the potential of SEEA-R1 for future research in scalable embodied intelligence.

14 Nov 2024
ScaleDP introduces a novel Transformer architecture that enables Diffusion Policy models for visuomotor robot control to scale effectively up to 1 billion parameters. This approach overcomes previous architectural limitations, leading to superior performance and enhanced generalization across a wide range of simulated and real-world robotic manipulation tasks.

08 Oct 2025

Recently, Vision-Language-Action models (VLA) have advanced robot imitation learning, but high data collection costs and limited demonstrations hinder generalization and current imitation learning methods struggle in out-of-distribution scenarios, especially for long-horizon tasks. A key challenge is how to mitigate compounding errors in imitation learning, which lead to cascading failures over extended trajectories. To address these challenges, we propose the Diffusion Trajectory-guided Policy (DTP) framework, which generates 2D trajectories through a diffusion model to guide policy learning for long-horizon tasks. By leveraging task-relevant trajectories, DTP provides trajectory-level guidance to reduce error accumulation. Our two-stage approach first trains a generative vision-language model to create diffusion-based trajectories, then refines the imitation policy using them. Experiments on the CALVIN benchmark show that DTP outperforms state-of-the-art baselines by 25% in success rate, starting from scratch without external pretraining. Moreover, DTP significantly improves real-world robot performance.

14 Mar 2025
EmbodiedVSR enhances spatial reasoning in embodied AI by integrating dynamic scene graph generation with physics-constrained chain-of-thought reasoning. This approach achieves improved performance on a new eSpatial-Benchmark and demonstrates robust capabilities in real-world robotic assembly tasks.

04 Jun 2025
Beijing Innovation Center of Humanoid Robotics researchers develop SwitchVLA, a Vision-Language-Action model that enables robots to dynamically switch tasks mid-execution through execution-aware behavioral control, achieving 50.9% success in challenging mid-switch scenarios (when robots are physically interacting with objects) compared to 8.3-11.1% for state-of-the-art baselines like π0 and OpenVLA, using a unified framework that conditions action generation on contact states and behavior modes (forward/rollback/advance) without requiring specialized task-switching demonstration data, with the system demonstrating robust performance across 95.1-96.5% success rates in real-world dual-arm Franka robot experiments where traditional VLA models completely fail (0-4.8% success), addressing the critical limitation that existing models assume static task intent and cannot adapt to changing human instructions during ongoing manipulation tasks.

28 May 2025

The UniPano framework enables efficient text-to-360-degree panorama generation by revealing and strategically leveraging the distinct roles of attention components in LoRA fine-tuning. This approach leads to reduced memory usage and faster training while producing high-quality panoramic images.

07 May 2025
Researchers from Beijing Innovation Center of Humanoid Robotics, Beijing Institute of Technology, and Hong Kong University of Science and Technology (Guangzhou) developed RoboOccWorld, an occupancy world model designed for predicting 3D scene evolution in indoor robotic environments. The model outperforms existing approaches on next-state and autoregressive occupancy prediction tasks, with improvements of up to 22.34 IoU points and 12.21 mIoU points on a new indoor benchmark dataset.

07 Jul 2025
A training-free framework, T2-VLM, generates temporally consistent rewards for robotic manipulation by leveraging Vision-Language Models for initial task understanding and then using particle filters for dynamic subgoal tracking. This approach enables more stable reinforcement learning training and achieves an average of 93% recovery success rate from online failures, demonstrating improved performance over existing methods.

20 Apr 2025
3D occupancy prediction enables the robots to obtain spatial fine-grained
geometry and semantics of the surrounding scene, and has become an essential
task for embodied perception. Existing methods based on 3D Gaussians instead of
dense voxels do not effectively exploit the geometry and opacity properties of
Gaussians, which limits the network's estimation of complex environments and
also limits the description of the scene by 3D Gaussians. In this paper, we
propose a 3D occupancy prediction method which enhances the geometric and
semantic scene understanding for robots, dubbed RoboOcc. It utilizes the
Opacity-guided Self-Encoder (OSE) to alleviate the semantic ambiguity of
overlapping Gaussians and the Geometry-aware Cross-Encoder (GCE) to accomplish
the fine-grained geometric modeling of the surrounding scene. We conduct
extensive experiments on Occ-ScanNet and EmbodiedOcc-ScanNet datasets, and our
RoboOcc achieves state-of the-art performance in both local and global camera
settings. Further, in ablation studies of Gaussian parameters, the proposed
RoboOcc outperforms the state-of-the-art methods by a large margin of (8.47,
6.27) in IoU and mIoU metric, respectively. The codes will be released soon.

30 Sep 2025
Learning from long-horizon demonstrations with complex action sequences presents significant challenges for visual imitation learning, particularly in understanding temporal relationships of actions and spatial relationships between objects. In this paper, we propose a new agent framework that incorporates two dedicated reflection modules to enhance both plan and code generation. The plan generation module produces an initial action sequence, which is then verified by the plan reflection module to ensure temporal coherence and spatial alignment with the demonstration video. The code generation module translates the plan into executable code, while the code reflection module verifies and refines the generated code to ensure correctness and consistency with the generated plan. These two reflection modules jointly enable the agent to detect and correct errors in both the plan generation and code generation, improving performance in tasks with intricate temporal and spatial dependencies. To support systematic evaluation, we introduce LongVILBench, a benchmark comprising 300 human demonstrations with action sequences of up to 18 steps. LongVILBench emphasizes temporal and spatial complexity across multiple task types. Experimental results demonstrate that existing methods perform poorly on this benchmark, whereas our new framework establishes a strong baseline for long-horizon visual imitation learning.

09 Jul 2025
Object navigation in open-world environments remains a formidable and pervasive challenge for robotic systems, particularly when it comes to executing long-horizon tasks that require both open-world object detection and high-level task planning. Traditional methods often struggle to integrate these components effectively, and this limits their capability to deal with complex, long-range navigation missions. In this paper, we propose LOVON, a novel framework that integrates large language models (LLMs) for hierarchical task planning with open-vocabulary visual detection models, tailored for effective long-range object navigation in dynamic, unstructured environments. To tackle real-world challenges including visual jittering, blind zones, and temporary target loss, we design dedicated solutions such as Laplacian Variance Filtering for visual stabilization. We also develop a functional execution logic for the robot that guarantees LOVON's capabilities in autonomous navigation, task adaptation, and robust task completion. Extensive evaluations demonstrate the successful completion of long-sequence tasks involving real-time detection, search, and navigation toward open-vocabulary dynamic targets. Furthermore, real-world experiments across different legged robots (Unitree Go2, B2, and H1-2) showcase the compatibility and appealing plug-and-play feature of LOVON.

07 Aug 2025
An MLLM-driven agent framework automates the synthesis of high-quality, diverse 2D, 3D, and 4D world data for AI-Generated Content. This framework, guided by models like GPT-4o, improves the performance of existing generative models for tasks such as object removal, 3D reconstruction, and 4D video generation, notably reducing FID from 62.48 to 60.32 and FVD from 160.72 to 155.71 in 4D generation.
There are no more papers matching your filters at the moment.
