
09 Dec 2025
A modular neural image signal processing framework was developed to transform raw sensor data into high-quality sRGB images, addressing the limitations of "black-box" neural ISPs by offering fine-grained control and enhanced interpretability. This system achieves state-of-the-art performance, supports diverse photographic styles, and generalizes robustly to various cameras, demonstrated by quantitative metrics and user preferences.

09 Dec 2025



Recent research in Vision-Language Models (VLMs) has significantly advanced our capabilities in cross-modal reasoning. However, existing methods suffer from performance degradation with domain changes or require substantial computational resources for fine-tuning in new domains. To address this issue, we develop a new adaptation method for large vision-language models, called \textit{Training-free Dual Hyperbolic Adapters} (T-DHA). We characterize the vision-language relationship between semantic concepts, which typically has a hierarchical tree structure, in the hyperbolic space instead of the traditional Euclidean space. Hyperbolic spaces exhibit exponential volume growth with radius, unlike the polynomial growth in Euclidean space. We find that this unique property is particularly effective for embedding hierarchical data structures using the Poincaré ball model, achieving significantly improved representation and discrimination power. Coupled with negative learning, it provides more accurate and robust classifications with fewer feature dimensions. Our extensive experimental results on various datasets demonstrate that the T-DHA method significantly outperforms existing state-of-the-art methods in few-shot image recognition and domain generalization tasks.

10 Dec 2025

Recent advances in multimodal large language models (MLLMs) have led to impressive progress across various benchmarks. However, their capability in understanding infrared images remains unexplored. To address this gap, we introduce IF-Bench, the first high-quality benchmark designed for evaluating multimodal understanding of infrared images. IF-Bench consists of 499 images sourced from 23 infrared datasets and 680 carefully curated visual question-answer pairs, covering 10 essential dimensions of image understanding. Based on this benchmark, we systematically evaluate over 40 open-source and closed-source MLLMs, employing cyclic evaluation, bilingual assessment, and hybrid judgment strategies to enhance the reliability of the results. Our analysis reveals how model scale, architecture, and inference paradigms affect infrared image comprehension, providing valuable insights for this area. Furthermore, we propose a training-free generative visual prompting (GenViP) method, which leverages advanced image editing models to translate infrared images into semantically and spatially aligned RGB counterparts, thereby mitigating domain distribution shifts. Extensive experiments demonstrate that our method consistently yields significant performance improvements across a wide range of MLLMs. The benchmark and code are available at this https URL.

07 Dec 2025
Video Instance Segmentation (VIS) faces significant annotation challenges due to its dual requirements of pixel-level masks and temporal consistency labels. While recent unsupervised methods like VideoCutLER eliminate optical flow dependencies through synthetic data, they remain constrained by the synthetic-to-real domain gap. We present AutoQ-VIS, a novel unsupervised framework that bridges this gap through quality-guided self-training. Our approach establishes a closed-loop system between pseudo-label generation and automatic quality assessment, enabling progressive adaptation from synthetic to real videos. Experiments demonstrate state-of-the-art performance with 52.6 on YouTubeVIS-2019 set, surpassing the previous state-of-the-art VideoCutLER by 4.4%, while requiring no human annotations. This demonstrates the viability of quality-aware self-training for unsupervised VIS. We will release the code at this https URL.

08 Dec 2025
Universal deepfake detection aims to identify AI-generated images across a broad range of generative models, including unseen ones. This requires robust generalization to new and unseen deepfakes, which emerge frequently, while minimizing computational overhead to enable large-scale deepfake screening, a critical objective in the era of Green AI. In this work, we explore frequency-domain masking as a training strategy for deepfake detectors. Unlike traditional methods that rely heavily on spatial features or large-scale pretrained models, our approach introduces random masking and geometric transformations, with a focus on frequency masking due to its superior generalization properties. We demonstrate that frequency masking not only enhances detection accuracy across diverse generators but also maintains performance under significant model pruning, offering a scalable and resource-conscious solution. Our method achieves state-of-the-art generalization on GAN- and diffusion-generated image datasets and exhibits consistent robustness under structured pruning. These results highlight the potential of frequency-based masking as a practical step toward sustainable and generalizable deepfake detection. Code and models are available at: [this https URL](this https URL).

10 Dec 2025
We examine the non-asymptotic properties of robust density ratio estimation (DRE) in contaminated settings. Weighted DRE is the most promising among existing methods, exhibiting doubly strong robustness from an asymptotic perspective. This study demonstrates that Weighted DRE achieves sparse consistency even under heavy contamination within a non-asymptotic framework. This method addresses two significant challenges in density ratio estimation and robust estimation. For density ratio estimation, we provide the non-asymptotic properties of estimating unbounded density ratios under the assumption that the weighted density ratio function is bounded. For robust estimation, we introduce a non-asymptotic framework for doubly strong robustness under heavy contamination, assuming that at least one of the following conditions holds: (i) contamination ratios are small, and (ii) outliers have small weighted values. This work provides the first non-asymptotic analysis of strong robustness under heavy contamination.

04 Dec 2025
The Nex-AGI Team developed a unified ecosystem, Nex, for constructing large-scale, diverse, and realistically grounded interactive environments to train autonomous AI agents. Their Nex-N1 models, trained using this infrastructure, demonstrate competitive to superior performance on complex agentic tasks, including coding and deep research, across various benchmarks and real-world evaluations.

08 Dec 2025
The Affordance Field Intervention (AFI) framework from the University of Sydney integrates 3D Spatial Affordance Fields into Vision-Language-Action (VLA) models to mitigate "Memory Traps" during robotic manipulation in new environments. This approach achieved average success rate gains of 17% to 26% across various out-of-distribution tasks on a real robot, significantly improving robustness without requiring VLA retraining.

09 Dec 2025
This research introduces a method that uses semantically grounded linguistic "motion tokens" to abstract continuous robot actions, enabling a two-stage pretraining and fine-tuning strategy to bridge numerical scale discrepancies across diverse robotic datasets. The approach achieves up to 14.1% higher average success rates on benchmarks like SimplerEnv compared to baselines and reduces the modality gap between action and language representations.

09 Dec 2025
With the rise of Large Language Models (LLMs) such as GPT-3, these models exhibit strong generalization capabilities. Through transfer learning techniques such as fine-tuning and prompt tuning, they can be adapted to various downstream tasks with minimal parameter adjustments. This approach is particularly common in the field of Natural Language Processing (NLP). This paper aims to explore the effectiveness of common prompt tuning methods in 3D object detection. We investigate whether a model trained on the large-scale Waymo dataset can serve as a foundation model and adapt to other scenarios within the 3D object detection field. This paper sequentially examines the impact of prompt tokens and prompt generators, and further proposes a Scene-Oriented Prompt Pool (\textbf{SOP}). We demonstrate the effectiveness of prompt pools in 3D object detection, with the goal of inspiring future researchers to delve deeper into the potential of prompts in the 3D field.
10 Dec 2025


In-context learning with attention enables large neural networks to make context-specific predictions by selectively focusing on relevant examples. Here, we adapt this idea to supervised learning procedures such as lasso regression and gradient boosting, for tabular data. Our goals are to (1) flexibly fit personalized models for each prediction point and (2) retain model simplicity and interpretability.
Our method fits a local model for each test observation by weighting the training data according to attention, a supervised similarity measure that emphasizes features and interactions that are predictive of the outcome. Attention weighting allows the method to adapt to heterogeneous data in a data-driven way, without requiring cluster or similarity pre-specification. Further, our approach is uniquely interpretable: for each test observation, we identify which features are most predictive and which training observations are most relevant. We then show how to use attention weighting for time series and spatial data, and we present a method for adapting pretrained tree-based models to distributional shift using attention-weighted residual corrections. Across real and simulated datasets, attention weighting improves predictive performance while preserving interpretability, and theory shows that attention-weighting linear models attain lower mean squared error than the standard linear model under mixture-of-models data-generating processes with known subgroup structure.

08 Dec 2025


A large language model's (LLM's) out-of-distribution (OOD) generalisation ability is crucial to its deployment. Previous work assessing LLMs' generalisation performance, however, typically focuses on a single out-of-distribution dataset. This approach may fail to precisely evaluate the capabilities of the model, as the data shifts encountered once a model is deployed are much more diverse. In this work, we investigate whether OOD generalisation results generalise. More specifically, we evaluate a model's performance across multiple OOD testsets throughout a finetuning run; we then evaluate the partial correlation of performances across these testsets, regressing out in-domain performance. This allows us to assess how correlated are generalisation performances once in-domain performance is controlled for. Analysing OLMo2 and OPT, we observe no overarching trend in generalisation results: the existence of a positive or negative correlation between any two OOD testsets depends strongly on the specific choice of model analysed.

08 Dec 2025
Distribution shifts at test time degrade image classifiers. Recent continual test-time adaptation (CTTA) methods use masking to regulate learning, but often depend on calibrated uncertainty or stable attention scores and introduce added complexity. We ask: do we need custom-made masking designs, or can a simple random masking schedule suffice under strong corruption? We introduce Mask to Adapt (M2A), a simple CTTA approach that generates a short sequence of masked views (spatial or frequency) and adapts with two objectives: a mask consistency loss that aligns predictions across different views and an entropy minimization loss that encourages confident outputs. Motivated by masked image modeling, we study two common masking families -- spatial masking and frequency masking -- and further compare subtypes within each (spatial: patch vs.\ pixel; frequency: all vs.\ low vs.\ high). On CIFAR10C/CIFAR100C/ImageNetC (severity~5), M2A (Spatial) attains 8.3\%/19.8\%/39.2\% mean error, outperforming or matching strong CTTA baselines, while M2A (Frequency) lags behind. Ablations further show that simple random masking is effective and robust. These results indicate that a simple random masking schedule, coupled with consistency and entropy objectives, is sufficient to drive effective test-time adaptation without relying on uncertainty or attention signals.

10 Dec 2025
The proliferation of hate speech on Chinese social media poses urgent societal risks, yet traditional systems struggle to decode context-dependent rhetorical strategies and evolving slang. To bridge this gap, we propose a novel three-stage LLM-based framework: Prompt Engineering, Supervised Fine-tuning, and LLM Merging. First, context-aware prompts are designed to guide LLMs in extracting implicit hate patterns. Next, task-specific features are integrated during supervised fine-tuning to enhance domain adaptation. Finally, merging fine-tuned LLMs improves robustness against out-of-distribution cases. Evaluations on the STATE-ToxiCN benchmark validate the framework's effectiveness, demonstrating superior performance over baseline methods in detecting fine-grained hate speech.
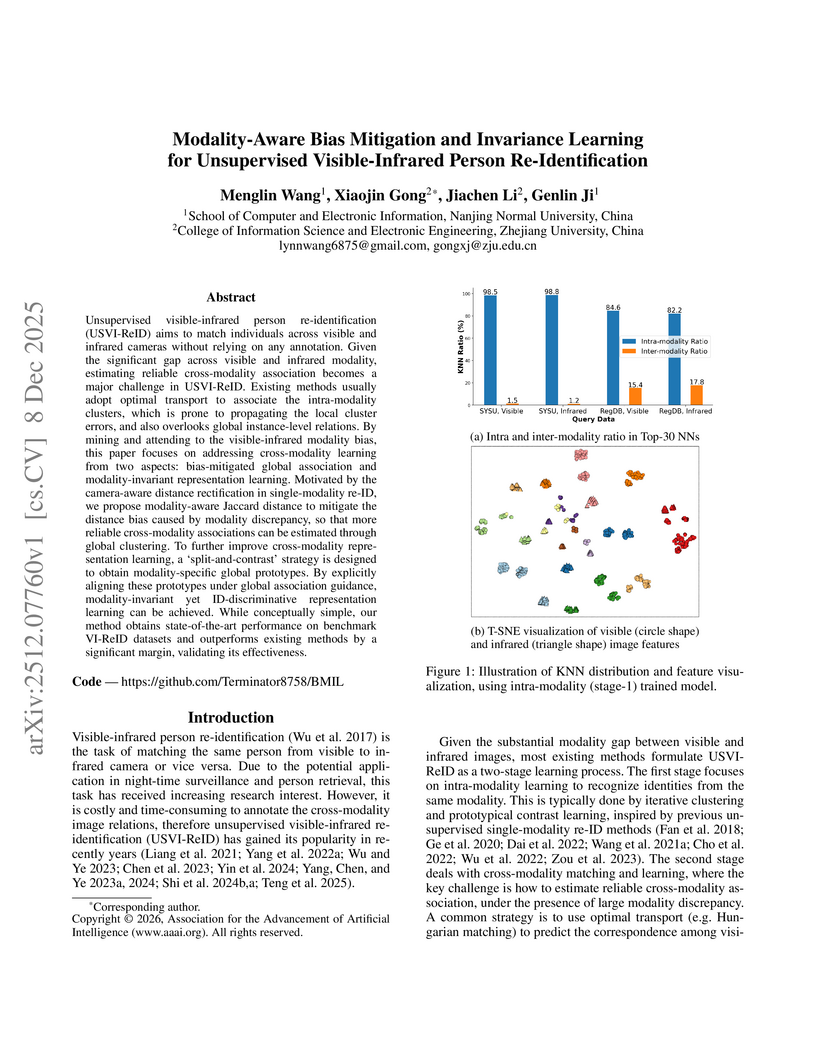
08 Dec 2025
Unsupervised visible-infrared person re-identification (USVI-ReID) aims to match individuals across visible and infrared cameras without relying on any annotation. Given the significant gap across visible and infrared modality, estimating reliable cross-modality association becomes a major challenge in USVI-ReID. Existing methods usually adopt optimal transport to associate the intra-modality clusters, which is prone to propagating the local cluster errors, and also overlooks global instance-level relations. By mining and attending to the visible-infrared modality bias, this paper focuses on addressing cross-modality learning from two aspects: bias-mitigated global association and modality-invariant representation learning. Motivated by the camera-aware distance rectification in single-modality re-ID, we propose modality-aware Jaccard distance to mitigate the distance bias caused by modality discrepancy, so that more reliable cross-modality associations can be estimated through global clustering. To further improve cross-modality representation learning, a `split-and-contrast' strategy is designed to obtain modality-specific global prototypes. By explicitly aligning these prototypes under global association guidance, modality-invariant yet ID-discriminative representation learning can be achieved. While conceptually simple, our method obtains state-of-the-art performance on benchmark VI-ReID datasets and outperforms existing methods by a significant margin, validating its effectiveness.

08 Dec 2025
Configuring computational fluid dynamics (CFD) simulations requires significant expertise in physics modeling and numerical methods, posing a barrier to non-specialists. Although automating scientific tasks with large language models (LLMs) has attracted attention, applying them to the complete, end-to-end CFD workflow remains a challenge due to its stringent domain-specific requirements. We introduce CFD-copilot, a domain-specialized LLM framework designed to facilitate natural language-driven CFD simulation from setup to post-processing. The framework employs a fine-tuned LLM to directly translate user descriptions into executable CFD setups. A multi-agent system integrates the LLM with simulation execution, automatic error correction, and result analysis. For post-processing, the framework utilizes the model context protocol (MCP), an open standard that decouples LLM reasoning from external tool execution. This modular design allows the LLM to interact with numerous specialized post-processing functions through a unified and scalable interface, improving the automation of data extraction and analysis. The framework was evaluated on benchmarks including the NACA~0012 airfoil and the three-element 30P-30N airfoil. The results indicate that domain-specific adaptation and the incorporation of the MCP jointly enhance the reliability and efficiency of LLM-driven engineering workflows.

08 Dec 2025
Conformal prediction provides a pivotal and flexible technique for uncertainty quantification by constructing prediction sets with a predefined coverage rate. Many online conformal prediction methods have been developed to address data distribution shifts in fully adversarial environments, resulting in overly conservative prediction sets. We propose Conformal Optimistic Prediction (COP), an online conformal prediction algorithm incorporating underlying data pattern into the update rule. Through estimated cumulative distribution function of non-conformity scores, COP produces tighter prediction sets when predictable pattern exists, while retaining valid coverage guarantees even when estimates are inaccurate. We establish a joint bound on coverage and regret, which further confirms the validity of our approach. We also prove that COP achieves distribution-free, finite-sample coverage under arbitrary learning rates and can converge when scores are . The experimental results also show that COP can achieve valid coverage and construct shorter prediction intervals than other baselines.

10 Dec 2025
Environmental variables are increasingly affecting agricultural decision-making, yet accessible and scalable tools for soil assessment remain limited. This study presents a robust and scalable modeling system for estimating soil properties in croplands, including soil organic carbon (SOC), total nitrogen (N), available phosphorus (P), exchangeable potassium (K), and pH, using remote sensing data and environmental covariates. The system employs a hybrid modeling approach, combining the indirect methods of modeling soil through proxies and drivers with direct spectral modeling. We extend current approaches by using interpretable physics-informed covariates derived from radiative transfer models (RTMs) and complex, nonlinear embeddings from a foundation model. We validate the system on a harmonized dataset that covers Europes cropland soils across diverse pedoclimatic zones. Evaluation is conducted under a robust validation framework that enforces strict spatial blocking, stratified splits, and statistically distinct train-test sets, which deliberately make the evaluation harder and produce more realistic error estimates for unseen regions. The models achieved their highest accuracy for SOC and N. This performance held across unseen locations, under both spatial cross-validation and an independent test set. SOC obtained a MAE of 5.12 g/kg and a CCC of 0.77, and N obtained a MAE of 0.44 g/kg and a CCC of 0.77. We also assess uncertainty through conformal calibration, achieving 90 percent coverage at the target confidence level. This study contributes to the digital advancement of agriculture through the application of scalable, data-driven soil analysis frameworks that can be extended to related domains requiring quantitative soil evaluation, such as carbon markets.

08 Dec 2025



Training end-to-end policies from image data to directly predict navigation actions for robotic systems has proven inherently difficult. Existing approaches often suffer from either the sim-to-real gap during policy transfer or a limited amount of training data with action labels. To address this problem, we introduce Vision-Language Distance (VLD) learning, a scalable framework for goal-conditioned navigation that decouples perception learning from policy learning. Instead of relying on raw sensory inputs during policy training, we first train a self-supervised distance-to-goal predictor on internet-scale video data. This predictor generalizes across both image- and text-based goals, providing a distance signal that can be minimized by a reinforcement learning (RL) policy. The RL policy can be trained entirely in simulation using privileged geometric distance signals, with injected noise to mimic the uncertainty of the trained distance predictor. At deployment, the policy consumes VLD predictions, inheriting semantic goal information-"where to go"-from large-scale visual training while retaining the robust low-level navigation behaviors learned in simulation. We propose using ordinal consistency to assess distance functions directly and demonstrate that VLD outperforms prior temporal distance approaches, such as ViNT and VIP. Experiments show that our decoupled design achieves competitive navigation performance in simulation while supporting flexible goal modalities, providing an alternative and, most importantly, scalable path toward reliable, multimodal navigation policies.

05 Dec 2025
Researchers at Fudan University and Microsoft Research Asia developed HiMoE-VLA, a generalist vision-language-action model, which employs a Hierarchical Mixture-of-Experts architecture to effectively manage the inherent heterogeneity in large-scale robotic datasets. This model achieved state-of-the-art performance, including 3.967 consecutively completed tasks on CALVIN and 97.8% average success on LIBERO, alongside robust generalization in real-world single and dual-arm manipulation.
There are no more papers matching your filters at the moment.
