
29 Oct 2025

While Multimodal Large Language Models (MLLMs) offer strong perception and reasoning capabilities for image-text input, Visual Question Answering (VQA) focusing on small image details still remains a challenge. Although visual cropping techniques seem promising, recent approaches have several limitations: the need for task-specific fine-tuning, low efficiency due to uninformed exhaustive search, or incompatibility with efficient attention implementations. We address these shortcomings by proposing a training-free visual cropping method, dubbed FOCUS, that leverages MLLM-internal representations to guide the search for the most relevant image region. This is accomplished in four steps: first, we identify the target object(s) in the VQA prompt; second, we compute an object relevance map using the key-value (KV) cache; third, we propose and rank relevant image regions based on the map; and finally, we perform the fine-grained VQA task using the top-ranked region. As a result of this informed search strategy, FOCUS achieves strong performance across four fine-grained VQA datasets and three types of MLLMs. It outperforms three popular visual cropping methods in both accuracy and efficiency, and matches the best-performing baseline, ZoomEye, while requiring 3 - 6.5 x less compute.

29 Oct 2024
Researchers at CARIAD SE developed an advanced LLM-powered agentic framework with a modular architecture and novel evaluation metrics to improve adaptability and performance in industrial process automation. Their analysis revealed that structural accuracy is critical for sequential tasks, while effective tool selection is paramount for parallel tasks, providing targeted insights for system optimization.

02 Dec 2024
Spatial understanding of the semantics of the surroundings is a key capability needed by autonomous cars to enable safe driving decisions. Recently, purely vision-based solutions have gained increasing research interest. In particular, approaches extracting a bird's eye view (BEV) from multiple cameras have demonstrated great performance for spatial understanding. This paper addresses the dependency on learned positional encodings to correlate image and BEV feature map elements for transformer-based methods. We propose leveraging epipolar geometric constraints to model the relationship between cameras and the BEV by Epipolar Attention Fields. They are incorporated into the attention mechanism as a novel attribution term, serving as an alternative to learned positional encodings. Experiments show that our method EAFormer outperforms previous BEV approaches by 2% mIoU for map semantic segmentation and exhibits superior generalization capabilities compared to implicitly learning the camera configuration.

11 Dec 2024
This paper demonstrates that simple fine-tuning of Vision-Language Model (VLM) pre-trained encoders is highly effective for domain generalization in dense perception tasks, achieving competitive or superior performance on synthetic-to-real and real-to-real benchmarks without relying on complex domain adaptation techniques. It shows that VLMs, especially EVA-CLIP, provide a powerful foundation for building robust perception systems by inherently generalizing across various data distributions.

13 Aug 2025
ParkDiffusion presents a diffusion-model-based framework for heterogeneous multi-agent multi-modal trajectory prediction tailored for automated parking scenarios. It establishes a new state-of-the-art for this domain, achieving superior prediction accuracy, particularly for pedestrians, while demonstrating robustness in complex, shared environments.

05 Nov 2024

LiDAR Semantic Segmentation is a fundamental task in autonomous driving perception consisting of associating each LiDAR point to a semantic label. Fully-supervised models have widely tackled this task, but they require labels for each scan, which either limits their domain or requires impractical amounts of expensive annotations. Camera images, which are generally recorded alongside LiDAR pointclouds, can be processed by the widely available 2D foundation models, which are generic and dataset-agnostic. However, distilling knowledge from 2D data to improve LiDAR perception raises domain adaptation challenges. For example, the classical perspective projection suffers from the parallax effect produced by the position shift between both sensors at their respective capture times. We propose a Semi-Supervised Learning setup to leverage unlabeled LiDAR pointclouds alongside distilled knowledge from the camera images. To self-supervise our model on the unlabeled scans, we add an auxiliary NeRF head and cast rays from the camera viewpoint over the unlabeled voxel features. The NeRF head predicts densities and semantic logits at each sampled ray location which are used for rendering pixel semantics. Concurrently, we query the Segment-Anything (SAM) foundation model with the camera image to generate a set of unlabeled generic masks. We fuse the masks with the rendered pixel semantics from LiDAR to produce pseudo-labels that supervise the pixel predictions. During inference, we drop the NeRF head and run our model with only LiDAR. We show the effectiveness of our approach in three public LiDAR Semantic Segmentation benchmarks: nuScenes, SemanticKITTI and ScribbleKITTI.
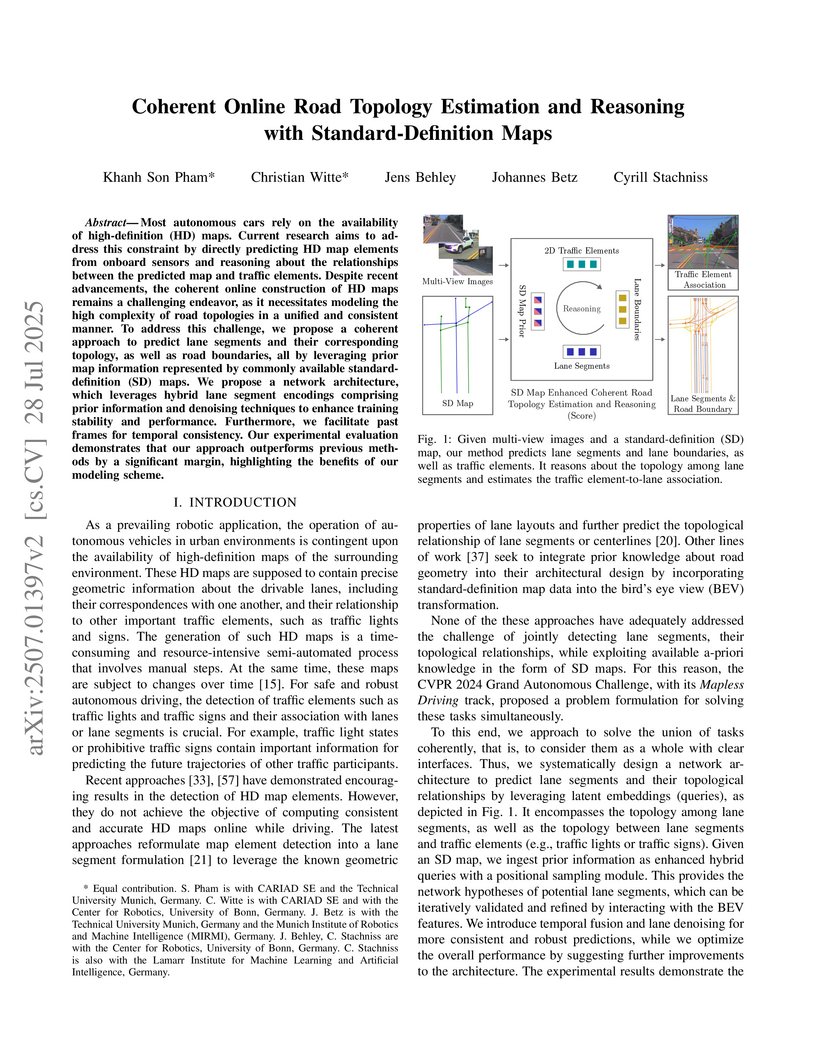
28 Jul 2025
Most autonomous cars rely on the availability of high-definition (HD) maps. Current research aims to address this constraint by directly predicting HD map elements from onboard sensors and reasoning about the relationships between the predicted map and traffic elements. Despite recent advancements, the coherent online construction of HD maps remains a challenging endeavor, as it necessitates modeling the high complexity of road topologies in a unified and consistent manner. To address this challenge, we propose a coherent approach to predict lane segments and their corresponding topology, as well as road boundaries, all by leveraging prior map information represented by commonly available standard-definition (SD) maps. We propose a network architecture, which leverages hybrid lane segment encodings comprising prior information and denoising techniques to enhance training stability and performance. Furthermore, we facilitate past frames for temporal consistency. Our experimental evaluation demonstrates that our approach outperforms previous methods by a large margin, highlighting the benefits of our modeling scheme.

05 Aug 2025
Simultaneous localization and mapping (SLAM) is a critical capability for autonomous systems. Traditional SLAM approaches, which often rely on visual or LiDAR sensors, face significant challenges in adverse conditions such as low light or featureless environments. To overcome these limitations, we propose a novel Doppler-aided radar-inertial and LiDAR-inertial SLAM framework that leverages the complementary strengths of 4D radar, FMCW LiDAR, and inertial measurement units. Our system integrates Doppler velocity measurements and spatial data into a tightly-coupled front-end and graph optimization back-end to provide enhanced ego velocity estimation, accurate odometry, and robust mapping. We also introduce a Doppler-based scan-matching technique to improve front-end odometry in dynamic environments. In addition, our framework incorporates an innovative online extrinsic calibration mechanism, utilizing Doppler velocity and loop closure to dynamically maintain sensor alignment. Extensive evaluations on both public and proprietary datasets show that our system significantly outperforms state-of-the-art radar-SLAM and LiDAR-SLAM frameworks in terms of accuracy and robustness. To encourage further research, the code of our Doppler-SLAM and our dataset are available at: this https URL.

25 Sep 2024
Semantic segmentation networks have achieved significant success under the assumption of independent and identically distributed data. However, these networks often struggle to detect anomalies from unknown semantic classes due to the limited set of visual concepts they are typically trained on. To address this issue, anomaly segmentation often involves fine-tuning on outlier samples, necessitating additional efforts for data collection, labeling, and model retraining. Seeking to avoid this cumbersome work, we take a different approach and propose to incorporate Vision-Language (VL) encoders into existing anomaly detectors to leverage the semantically broad VL pre-training for improved outlier awareness. Additionally, we propose a new scoring function that enables data- and training-free outlier supervision via textual prompts. The resulting VL4AD model, which includes max-logit prompt ensembling and a class-merging strategy, achieves competitive performance on widely used benchmark datasets, thereby demonstrating the potential of vision-language models for pixel-wise anomaly detection.

03 Apr 2025

Scene flow estimation is a foundational task for many robotic applications,
including robust dynamic object detection, automatic labeling, and sensor
synchronization. Two types of approaches to the problem have evolved: 1)
Supervised and 2) optimization-based methods. Supervised methods are fast
during inference and achieve high-quality results, however, they are limited by
the need for large amounts of labeled training data and are susceptible to
domain gaps. In contrast, unsupervised test-time optimization methods do not
face the problem of domain gaps but usually suffer from substantial runtime,
exhibit artifacts, or fail to converge to the right solution. In this work, we
mitigate several limitations of existing optimization-based methods. To this
end, we 1) introduce a simple voxel grid-based model that improves over the
standard MLP-based formulation in multiple dimensions and 2) introduce a new
multiframe loss formulation. 3) We combine both contributions in our new
method, termed Floxels. On the Argoverse 2 benchmark, Floxels is surpassed only
by EulerFlow among unsupervised methods while achieving comparable performance
at a fraction of the computational cost. Floxels achieves a massive speedup of
more than ~60 - 140x over EulerFlow, reducing the runtime from a day to 10
minutes per sequence. Over the faster but low-quality baseline, NSFP, Floxels
achieves a speedup of ~14x.

29 Nov 2024
Self-supervised monocular depth estimation (MDE) has gained popularity for obtaining depth predictions directly from videos. However, these methods often produce scale invariant results, unless additional training signals are provided. Addressing this challenge, we introduce a novel self-supervised metric-scaled MDE model that requires only monocular video data and the camera's mounting position, both of which are readily available in modern vehicles. Our approach leverages planar-parallax geometry to reconstruct scene structure. The full pipeline consists of three main networks, a multi-frame network, a singleframe network, and a pose network. The multi-frame network processes sequential frames to estimate the structure of the static scene using planar-parallax geometry and the camera mounting position. Based on this reconstruction, it acts as a teacher, distilling knowledge such as scale information, masked drivable area, metric-scale depth for the static scene, and dynamic object mask to the singleframe network. It also aids the pose network in predicting a metric-scaled relative pose between two subsequent images. Our method achieved state-of-the-art results for the driving benchmark KITTI for metric-scaled depth prediction. Notably, it is one of the first methods to produce self-supervised metric-scaled depth prediction for the challenging Cityscapes dataset, demonstrating its effectiveness and versatility.

05 Dec 2025

Scalable multi-agent driving simulation requires behavior models that are both realistic and computationally efficient. We address this by optimizing the behavior model that controls individual traffic participants. To improve efficiency, we adopt an instance-centric scene representation, where each traffic participant and map element is modeled in its own local coordinate frame. This design enables efficient, viewpoint-invariant scene encoding and allows static map tokens to be reused across simulation steps. To model interactions, we employ a query-centric symmetric context encoder with relative positional encodings between local frames. We use Adversarial Inverse Reinforcement Learning to learn the behavior model and propose an adaptive reward transformation that automatically balances robustness and realism during training. Experiments demonstrate that our approach scales efficiently with the number of tokens, significantly reducing training and inference times, while outperforming several agent-centric baselines in terms of positional accuracy and robustness.
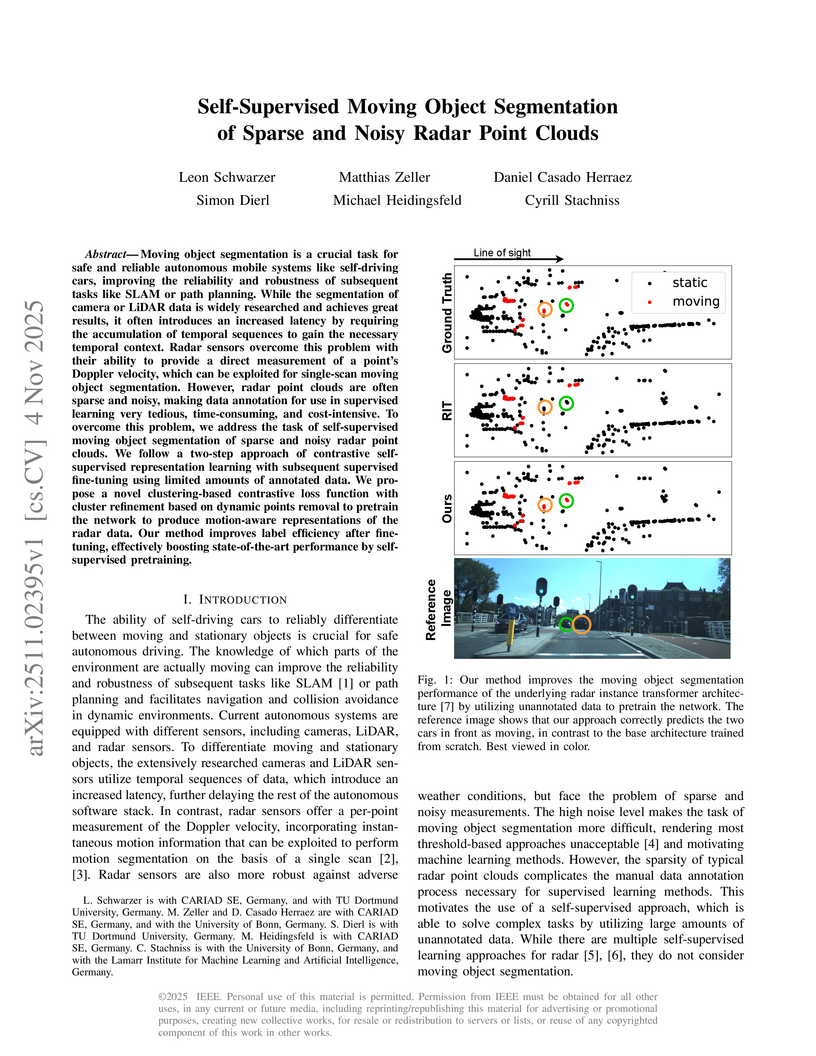
04 Nov 2025
Moving object segmentation is a crucial task for safe and reliable autonomous mobile systems like self-driving cars, improving the reliability and robustness of subsequent tasks like SLAM or path planning. While the segmentation of camera or LiDAR data is widely researched and achieves great results, it often introduces an increased latency by requiring the accumulation of temporal sequences to gain the necessary temporal context. Radar sensors overcome this problem with their ability to provide a direct measurement of a point's Doppler velocity, which can be exploited for single-scan moving object segmentation. However, radar point clouds are often sparse and noisy, making data annotation for use in supervised learning very tedious, time-consuming, and cost-intensive. To overcome this problem, we address the task of self-supervised moving object segmentation of sparse and noisy radar point clouds. We follow a two-step approach of contrastive self-supervised representation learning with subsequent supervised fine-tuning using limited amounts of annotated data. We propose a novel clustering-based contrastive loss function with cluster refinement based on dynamic points removal to pretrain the network to produce motion-aware representations of the radar data. Our method improves label efficiency after fine-tuning, effectively boosting state-of-the-art performance by self-supervised pretraining.

11 Jul 2025
Accurate prediction of surrounding road users' trajectories is essential for safe and efficient autonomous driving. While deep learning models have improved performance, challenges remain in preventing off-road predictions and ensuring kinematic feasibility. Existing methods incorporate road-awareness modules and enforce kinematic constraints but lack plausibility guarantees and often introduce trade-offs in complexity and flexibility. This paper proposes a novel framework that formulates trajectory prediction as a constrained regression guided by permissible driving directions and their boundaries. Using the agent's current state and an HD map, our approach defines the valid boundaries and ensures on-road predictions by training the network to learn superimposed paths between left and right boundary polylines. To guarantee feasibility, the model predicts acceleration profiles that determine the vehicle's travel distance along these paths while adhering to kinematic constraints. We evaluate our approach on the Argoverse-2 dataset against the HPTR baseline. Our approach shows a slight decrease in benchmark metrics compared to HPTR but notably improves final displacement error and eliminates infeasible trajectories. Moreover, the proposed approach has superior generalization to less prevalent maneuvers and unseen out-of-distribution scenarios, reducing the off-road rate under adversarial attacks from 66% to just 1%. These results highlight the effectiveness of our approach in generating feasible and robust predictions.

24 Apr 2023
Unsupervised Domain Adaptation (UDA) and domain generalization (DG) are two research areas that aim to tackle the lack of generalization of Deep Neural Networks (DNNs) towards unseen domains. While UDA methods have access to unlabeled target images, domain generalization does not involve any target data and only learns generalized features from a source domain. Image-style randomization or augmentation is a popular approach to improve network generalization without access to the target domain. Complex methods are often proposed that disregard the potential of simple image augmentations for out-of-domain generalization. For this reason, we systematically study the in- and out-of-domain generalization capabilities of simple, rule-based image augmentations like blur, noise, color jitter and many more. Based on a full factorial design of experiment design we provide a systematic statistical evaluation of augmentations and their interactions. Our analysis provides both, expected and unexpected, outcomes. Expected, because our experiments confirm the common scientific standard that combination of multiple different augmentations out-performs single augmentations. Unexpected, because combined augmentations perform competitive to state-of-the-art domain generalization approaches, while being significantly simpler and without training overhead. On the challenging synthetic-to-real domain shift between Synthia and Cityscapes we reach 39.5% mIoU compared to 40.9% mIoU of the best previous work. When additionally employing the recent vision transformer architecture DAFormer we outperform these benchmarks with a performance of 44.2% mIoU

27 Jul 2025
Trajectory prediction is crucial for autonomous driving, enabling vehicles to navigate safely by anticipating the movements of surrounding road users. However, current deep learning models often lack trustworthiness as their predictions can be physically infeasible and illogical to humans. To make predictions more trustworthy, recent research has incorporated prior knowledge, like the social force model for modeling interactions and kinematic models for physical realism. However, these approaches focus on priors that suit either vehicles or pedestrians and do not generalize to traffic with mixed agent classes. We propose incorporating interaction and kinematic priors of all agent classes--vehicles, pedestrians, and cyclists with class-specific interaction layers to capture agent behavioral differences. To improve the interpretability of the agent interactions, we introduce DG-SFM, a rule-based interaction importance score that guides the interaction layer. To ensure physically feasible predictions, we proposed suitable kinematic models for all agent classes with a novel pedestrian kinematic model. We benchmark our approach on the Argoverse 2 dataset, using the state-of-the-art transformer HPTR as our baseline. Experiments demonstrate that our method improves interaction interpretability, revealing a correlation between incorrect predictions and divergence from our interaction prior. Even though incorporating the kinematic models causes a slight decrease in accuracy, they eliminate infeasible trajectories found in the dataset and the baseline model. Thus, our approach fosters trust in trajectory prediction as its interaction reasoning is interpretable, and its predictions adhere to physics.
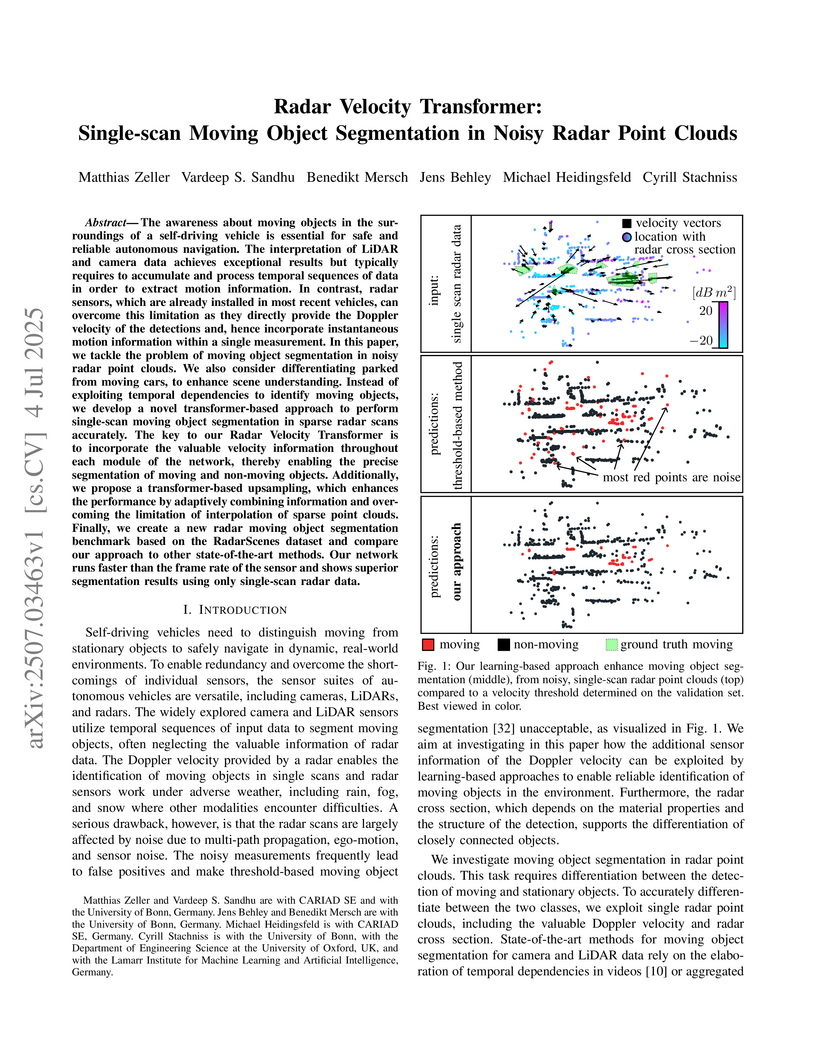
04 Jul 2025

The awareness about moving objects in the surroundings of a self-driving vehicle is essential for safe and reliable autonomous navigation. The interpretation of LiDAR and camera data achieves exceptional results but typically requires to accumulate and process temporal sequences of data in order to extract motion information. In contrast, radar sensors, which are already installed in most recent vehicles, can overcome this limitation as they directly provide the Doppler velocity of the detections and, hence incorporate instantaneous motion information within a single measurement. % In this paper, we tackle the problem of moving object segmentation in noisy radar point clouds. We also consider differentiating parked from moving cars, to enhance scene understanding. Instead of exploiting temporal dependencies to identify moving objects, we develop a novel transformer-based approach to perform single-scan moving object segmentation in sparse radar scans accurately. The key to our Radar Velocity Transformer is to incorporate the valuable velocity information throughout each module of the network, thereby enabling the precise segmentation of moving and non-moving objects. Additionally, we propose a transformer-based upsampling, which enhances the performance by adaptively combining information and overcoming the limitation of interpolation of sparse point clouds. Finally, we create a new radar moving object segmentation benchmark based on the RadarScenes dataset and compare our approach to other state-of-the-art methods. Our network runs faster than the frame rate of the sensor and shows superior segmentation results using only single-scan radar data.

10 Oct 2024

Autonomous vehicles demand detailed maps to maneuver reliably through
traffic, which need to be kept up-to-date to ensure a safe operation. A
promising way to adapt the maps to the ever-changing road-network is to use
crowd-sourced data from a fleet of vehicles. In this work, we present a mapping
system that fuses local submaps gathered from a fleet of vehicles at a central
instance to produce a coherent map of the road environment including drivable
area, lane markings, poles, obstacles and more as a 3D mesh. Each vehicle
contributes locally reconstructed submaps as lightweight meshes, making our
method applicable to a wide range of reconstruction methods and sensor
modalities. Our method jointly aligns and merges the noisy and incomplete local
submaps using a scene-specific Neural Signed Distance Field, which is
supervised using the submap meshes to predict a fused environment
representation. We leverage memory-efficient sparse feature-grids to scale to
large areas and introduce a confidence score to model uncertainty in scene
reconstruction. Our approach is evaluated on two datasets with different local
mapping methods, showing improved pose alignment and reconstruction over
existing methods. Additionally, we demonstrate the benefit of multi-session
mapping and examine the required amount of data to enable high-fidelity map
learning for autonomous vehicles.
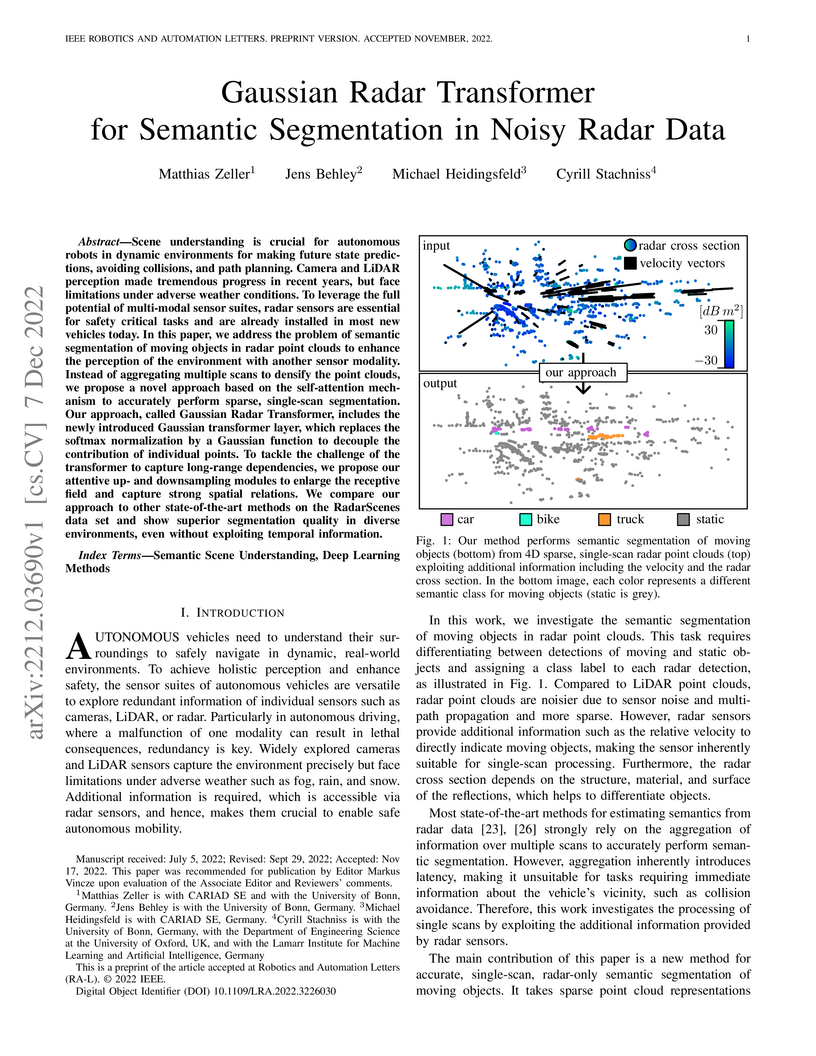
07 Dec 2022
Scene understanding is crucial for autonomous robots in dynamic environments
for making future state predictions, avoiding collisions, and path planning.
Camera and LiDAR perception made tremendous progress in recent years, but face
limitations under adverse weather conditions. To leverage the full potential of
multi-modal sensor suites, radar sensors are essential for safety critical
tasks and are already installed in most new vehicles today. In this paper, we
address the problem of semantic segmentation of moving objects in radar point
clouds to enhance the perception of the environment with another sensor
modality. Instead of aggregating multiple scans to densify the point clouds, we
propose a novel approach based on the self-attention mechanism to accurately
perform sparse, single-scan segmentation. Our approach, called Gaussian Radar
Transformer, includes the newly introduced Gaussian transformer layer, which
replaces the softmax normalization by a Gaussian function to decouple the
contribution of individual points. To tackle the challenge of the transformer
to capture long-range dependencies, we propose our attentive up- and
downsampling modules to enlarge the receptive field and capture strong spatial
relations. We compare our approach to other state-of-the-art methods on the
RadarScenes data set and show superior segmentation quality in diverse
environments, even without exploiting temporal information.

09 Jul 2025
Semantic scene understanding, including the perception and classification of moving agents, is essential to enabling safe and robust driving behaviours of autonomous vehicles. Cameras and LiDARs are commonly used for semantic scene understanding. However, both sensor modalities face limitations in adverse weather and usually do not provide motion information. Radar sensors overcome these limitations and directly offer information about moving agents by measuring the Doppler velocity, but the measurements are comparably sparse and noisy. In this paper, we address the problem of panoptic segmentation in sparse radar point clouds to enhance scene understanding. Our approach, called SemRaFiner, accounts for changing density in sparse radar point clouds and optimizes the feature extraction to improve accuracy. Furthermore, we propose an optimized training procedure to refine instance assignments by incorporating a dedicated data augmentation. Our experiments suggest that our approach outperforms state-of-the-art methods for radar-based panoptic segmentation.
There are no more papers matching your filters at the moment.
