
05 Nov 2025
A survey categorizes Large Language Model approaches for scientific idea generation, analyzing their capacity to produce both novel and scientifically sound ideas using established cognitive science frameworks. The work maps current methods to different levels of creativity and identifies key challenges and future directions for advancing LLMs towards transformative scientific discovery.

05 Nov 2025
Accurate segmentation and classification of brain tumors from Magnetic Resonance Imaging (MRI) remain key challenges in medical image analysis, primarily due to the lack of high-quality, balanced, and diverse datasets with expert annotations. In this work, we address this gap by introducing BRISC, a dataset designed for brain tumor segmentation and classification tasks, featuring high-resolution segmentation masks. The dataset comprises 6,000 contrast-enhanced T1-weighted MRI scans, which were collated from multiple public datasets that lacked segmentation labels. Our primary contribution is the subsequent expert annotation of these images, performed by certified radiologists and physicians. It includes three major tumor types, namely glioma, meningioma, and pituitary, as well as non-tumorous cases. Each sample includes high-resolution labels and is categorized across axial, sagittal, and coronal imaging planes to facilitate robust model development and cross-view generalization. To demonstrate the utility of the dataset, we provide benchmark results for both tasks using standard deep learning models. The BRISC dataset is made publicly available. datasetlink: Kaggle (this https URL), Figshare (this https URL), Zenodo (this https URL)

12 Sep 2025
Supervised Fine-Tuning (SFT) is essential for training large language models (LLMs), significantly enhancing critical capabilities such as instruction following and in-context learning. Nevertheless, creating suitable training datasets tailored for specific domains remains challenging due to unique domain constraints and data scarcity. In this paper, we propose SearchInstruct, an innovative method explicitly designed to construct high quality instruction datasets for SFT. Our approach begins with a limited set of domain specific, human generated questions, which are systematically expanded using a large language model. Subsequently, domain relevant resources are dynamically retrieved to generate accurate and contextually appropriate answers for each augmented question. Experimental evaluation demonstrates that SearchInstruct enhances both the diversity and quality of SFT datasets, leading to measurable improvements in LLM performance within specialized domains. Additionally, we show that beyond dataset generation, the proposed method can also effectively facilitate tasks such as model editing, enabling efficient updates to existing models. To facilitate reproducibility and community adoption, we provide full implementation details, the complete set of generated instruction response pairs, and the source code in a publicly accessible Git repository: [this https URL](this https URL)

03 Jun 2023


Denoising diffusion models, a class of generative models, have garnered
immense interest lately in various deep-learning problems. A diffusion
probabilistic model defines a forward diffusion stage where the input data is
gradually perturbed over several steps by adding Gaussian noise and then learns
to reverse the diffusion process to retrieve the desired noise-free data from
noisy data samples. Diffusion models are widely appreciated for their strong
mode coverage and quality of the generated samples despite their known
computational burdens. Capitalizing on the advances in computer vision, the
field of medical imaging has also observed a growing interest in diffusion
models. To help the researcher navigate this profusion, this survey intends to
provide a comprehensive overview of diffusion models in the discipline of
medical image analysis. Specifically, we introduce the solid theoretical
foundation and fundamental concepts behind diffusion models and the three
generic diffusion modelling frameworks: diffusion probabilistic models,
noise-conditioned score networks, and stochastic differential equations. Then,
we provide a systematic taxonomy of diffusion models in the medical domain and
propose a multi-perspective categorization based on their application, imaging
modality, organ of interest, and algorithms. To this end, we cover extensive
applications of diffusion models in the medical domain. Furthermore, we
emphasize the practical use case of some selected approaches, and then we
discuss the limitations of the diffusion models in the medical domain and
propose several directions to fulfill the demands of this field. Finally, we
gather the overviewed studies with their available open-source implementations
at
https://github.com/amirhossein-kz/Awesome-Diffusion-Models-in-Medical-Imaging.

25 Jun 2025
Parameter-efficient fine-tuning (PEFT) has gained widespread adoption across various applications. Among PEFT techniques, Low-Rank Adaptation (LoRA) and its extensions have emerged as particularly effective, allowing efficient model adaptation while significantly reducing computational overhead. However, existing approaches typically rely on global low-rank factorizations, which overlook local or multi-scale structure, failing to capture complex patterns in the weight updates. To address this, we propose WaRA, a novel PEFT method that leverages wavelet transforms to decompose the weight update matrix into a multi-resolution representation. By performing low-rank factorization in the wavelet domain and reconstructing updates through an inverse transform, WaRA obtains compressed adaptation parameters that harness multi-resolution analysis, enabling it to capture both coarse and fine-grained features while providing greater flexibility and sparser representations than standard LoRA. Through comprehensive experiments and analysis, we demonstrate that WaRA performs superior on diverse vision tasks, including image generation, classification, and semantic segmentation, significantly enhancing generated image quality while reducing computational complexity. Although WaRA was primarily designed for vision tasks, we further showcase its effectiveness in language tasks, highlighting its broader applicability and generalizability. The code is publicly available at \href{GitHub}{this https URL}.

30 Jul 2023
Implicit neural representations (INRs) have gained prominence as a powerful paradigm in scene reconstruction and computer graphics, demonstrating remarkable results. By utilizing neural networks to parameterize data through implicit continuous functions, INRs offer several benefits. Recognizing the potential of INRs beyond these domains, this survey aims to provide a comprehensive overview of INR models in the field of medical imaging. In medical settings, numerous challenging and ill-posed problems exist, making INRs an attractive solution. The survey explores the application of INRs in various medical imaging tasks, such as image reconstruction, segmentation, registration, novel view synthesis, and compression. It discusses the advantages and limitations of INRs, highlighting their resolution-agnostic nature, memory efficiency, ability to avoid locality biases, and differentiability, enabling adaptation to different tasks. Furthermore, the survey addresses the challenges and considerations specific to medical imaging data, such as data availability, computational complexity, and dynamic clinical scene analysis. It also identifies future research directions and opportunities, including integration with multi-modal imaging, real-time and interactive systems, and domain adaptation for clinical decision support. To facilitate further exploration and implementation of INRs in medical image analysis, we have provided a compilation of cited studies along with their available open-source implementations on \href{this https URL}. Finally, we aim to consistently incorporate the most recent and relevant papers regularly.

15 Oct 2025
Story continuation focuses on generating the next image in a narrative sequence so that it remains coherent with both the ongoing text description and the previously observed images. A central challenge in this setting lies in utilizing prior visual context effectively, while ensuring semantic alignment with the current textual input. In this work, we introduce AVC (Adaptive Visual Conditioning), a framework for diffusion-based story continuation. AVC employs the CLIP model to retrieve the most semantically aligned image from previous frames. Crucially, when no sufficiently relevant image is found, AVC adaptively restricts the influence of prior visuals to only the early stages of the diffusion process. This enables the model to exploit visual context when beneficial, while avoiding the injection of misleading or irrelevant information. Furthermore, we improve data quality by re-captioning a noisy dataset using large language models, thereby strengthening textual supervision and semantic alignment. Quantitative results and human evaluations demonstrate that AVC achieves superior coherence, semantic consistency, and visual fidelity compared to strong baselines, particularly in challenging cases where prior visuals conflict with the current input.

12 Mar 2025

The Word2winners system, developed by Iran University of Science and Technology, proposes an approach for multilingual and crosslingual fact-checked claim retrieval, matching new social media content to existing fact-checks. The system achieves 92% accuracy in monolingual scenarios and 82% in crosslingual scenarios by combining fine-tuned transformer-based models and an ensemble strategy.
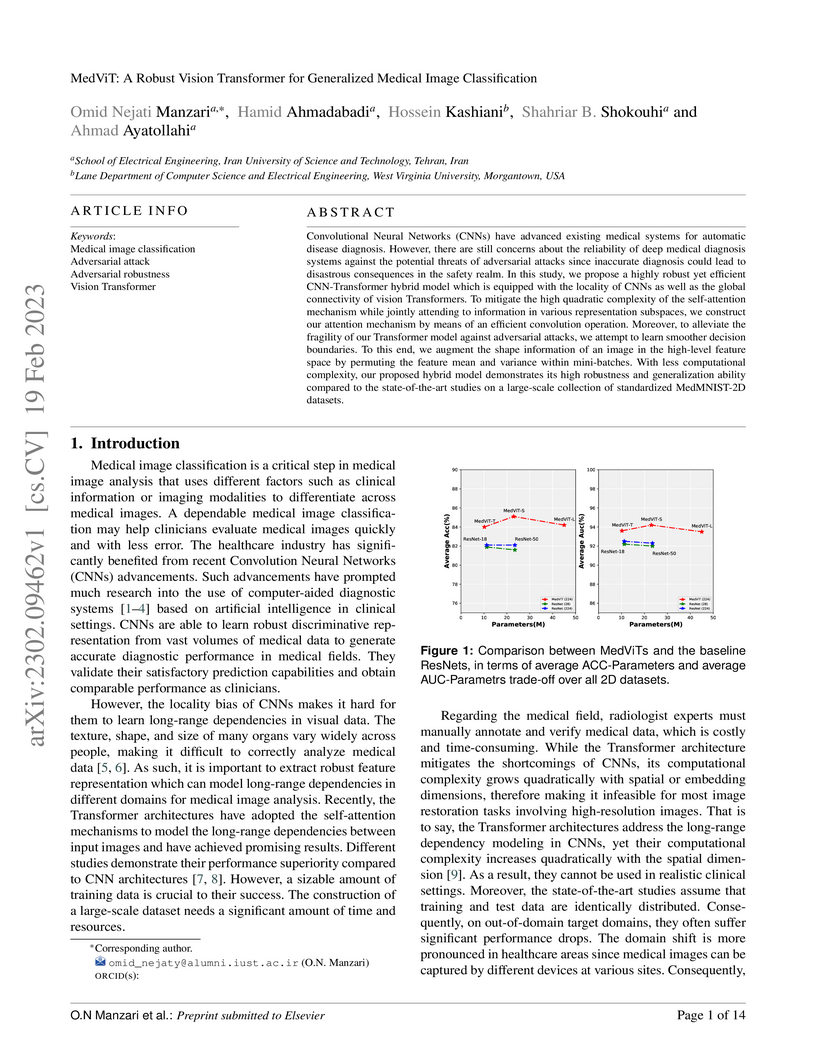
19 Feb 2023
Convolutional Neural Networks (CNNs) have advanced existing medical systems
for automatic disease diagnosis. However, there are still concerns about the
reliability of deep medical diagnosis systems against the potential threats of
adversarial attacks since inaccurate diagnosis could lead to disastrous
consequences in the safety realm. In this study, we propose a highly robust yet
efficient CNN-Transformer hybrid model which is equipped with the locality of
CNNs as well as the global connectivity of vision Transformers. To mitigate the
high quadratic complexity of the self-attention mechanism while jointly
attending to information in various representation subspaces, we construct our
attention mechanism by means of an efficient convolution operation. Moreover,
to alleviate the fragility of our Transformer model against adversarial
attacks, we attempt to learn smoother decision boundaries. To this end, we
augment the shape information of an image in the high-level feature space by
permuting the feature mean and variance within mini-batches. With less
computational complexity, our proposed hybrid model demonstrates its high
robustness and generalization ability compared to the state-of-the-art studies
on a large-scale collection of standardized MedMNIST-2D datasets.

09 Jan 2023
HiFormer: Hierarchical Multi-scale Representations Using Transformers for Medical Image Segmentation
HiFormer: Hierarchical Multi-scale Representations Using Transformers for Medical Image Segmentation

Convolutional neural networks (CNNs) have been the consensus for medical image segmentation tasks. However, they suffer from the limitation in modeling long-range dependencies and spatial correlations due to the nature of convolution operation. Although transformers were first developed to address this issue, they fail to capture low-level features. In contrast, it is demonstrated that both local and global features are crucial for dense prediction, such as segmenting in challenging contexts. In this paper, we propose HiFormer, a novel method that efficiently bridges a CNN and a transformer for medical image segmentation. Specifically, we design two multi-scale feature representations using the seminal Swin Transformer module and a CNN-based encoder. To secure a fine fusion of global and local features obtained from the two aforementioned representations, we propose a Double-Level Fusion (DLF) module in the skip connection of the encoder-decoder structure. Extensive experiments on various medical image segmentation datasets demonstrate the effectiveness of HiFormer over other CNN-based, transformer-based, and hybrid methods in terms of computational complexity, and quantitative and qualitative results. Our code is publicly available at: this https URL

27 Apr 2025
This survey paper from Sharif University of Technology, Iran University of Science and Technology, and Qatar Computing Research Institute presents a comprehensive overview of how generative artificial intelligence techniques are transforming character animation. It integrates advances across previously fragmented areas like facial animation, avatar creation, and motion synthesis, demonstrating how AI can automate and augment traditional animation processes, leading to more accessible and efficient content creation.

13 Mar 2023
A potential-based reward shaping technique is presented that utilizes an agent's cumulative episode rewards to dynamically modify the feedback signal in reinforcement learning environments. This method, developed by researchers from the University of Kansas, University of New Mexico, and Iran University of Science and Technology, consistently sped up learning and frequently led to better final policies for both single and multi-task agents in Atari games.

26 Jul 2023
Transformers have recently gained attention in the computer vision domain due
to their ability to model long-range dependencies. However, the self-attention
mechanism, which is the core part of the Transformer model, usually suffers
from quadratic computational complexity with respect to the number of tokens.
Many architectures attempt to reduce model complexity by limiting the
self-attention mechanism to local regions or by redesigning the tokenization
process. In this paper, we propose DAE-Former, a novel method that seeks to
provide an alternative perspective by efficiently designing the self-attention
mechanism. More specifically, we reformulate the self-attention mechanism to
capture both spatial and channel relations across the whole feature dimension
while staying computationally efficient. Furthermore, we redesign the skip
connection path by including the cross-attention module to ensure the feature
reusability and enhance the localization power. Our method outperforms
state-of-the-art methods on multi-organ cardiac and skin lesion segmentation
datasets without requiring pre-training weights. The code is publicly available
at this https URL

20 Oct 2025
Effortless and ergonomically designed surgical lighting is critical for precision and safety during procedures. However, traditional systems often rely on manual adjustments, leading to surgeon fatigue, neck strain, and inconsistent illumination due to drift and shadowing. To address these challenges, we propose a novel surgical lighting system that leverages the YOLOv11 object detection algorithm to identify a blue marker placed above the target surgical site. A high-power LED light source is then directed to the identified location using two servomotors equipped with tilt-pan brackets. The YOLO model achieves 96.7% mAP@50 on the validation set consisting of annotated images simulating surgical scenes with the blue spherical marker. By automating the lighting process, this machine vision-based solution reduces physical strain on surgeons, improves consistency in illumination, and supports improved surgical outcomes.

04 Oct 2025
This paper presents the development of Rezwan, a large-scale AI-assisted Hadith corpus comprising over 1.2M narrations, extracted and structured through a fully automated pipeline. Building on digital repositories such as Maktabat Ahl al-Bayt, the pipeline employs Large Language Models (LLMs) for segmentation, chain--text separation, validation, and multi-layer enrichment. Each narration is enhanced with machine translation into twelve languages, intelligent diacritization, abstractive summarization, thematic tagging, and cross-text semantic analysis. This multi-step process transforms raw text into a richly annotated research-ready infrastructure for digital humanities and Islamic studies. A rigorous evaluation was conducted on 1,213 randomly sampled narrations, assessed by six domain experts. Results show near-human accuracy in structured tasks such as chain--text separation (9.33/10) and summarization (9.33/10), while highlighting ongoing challenges in diacritization and semantic similarity detection. Comparative analysis against the manually curated Noor Corpus demonstrates the superiority of Najm in both scale and quality, with a mean overall score of 8.46/10 versus 3.66/10. Furthermore, cost analysis confirms the economic feasibility of the AI approach: tasks requiring over 229,000 hours of expert labor were completed within months at a fraction of the cost. The work introduces a new paradigm in religious text processing by showing how AI can augment human expertise, enabling large-scale, multilingual, and semantically enriched access to Islamic heritage.

20 Sep 2025
Generative 3D modeling has advanced rapidly, driven by applications in VR/AR, metaverse, and robotics. However, most methods represent the target object as a closed mesh devoid of any structural information, limiting editing, animation, and semantic understanding. Part-aware 3D generation addresses this problem by decomposing objects into meaningful components, but existing pipelines face challenges: in existing methods, the user has no control over which objects are separated and how model imagine the occluded parts in isolation phase. In this paper, we introduce MMPart, an innovative framework for generating part-aware 3D models from a single image. We first use a VLM to generate a set of prompts based on the input image and user descriptions. In the next step, a generative model generates isolated images of each object based on the initial image and the previous step's prompts as supervisor (which control the pose and guide model how imagine previously occluded areas). Each of those images then enters the multi-view generation stage, where a number of consistent images from different views are generated. Finally, a reconstruction model converts each of these multi-view images into a 3D model.

20 Jan 2025

This review paper examines advancements in Ground Penetrating Radar (GPR) technology for railway track monitoring, integrating synthetic modeling and machine learning algorithms to enhance subsurface defect detection. It consolidates research on automating GPR data analysis, showing how computational methods improve the accuracy and efficiency of identifying trackbed issues like ballast fouling and subgrade settlement.

06 Dec 2025
Left ventricular ejection fraction (LVEF) is a key indicator of cardiac function and is routinely used to diagnose heart failure and guide treatment decisions. Although deep learning has advanced automated LVEF estimation, many existing approaches are computationally demanding and underutilize the joint structure of spatial and temporal information in echocardiography videos, limiting their suitability for real-time clinical deployment. We propose Echo-ENet, an efficient endocardial spatio-temporal network specifically designed for LVEF estimation from echocardiography videos. Echo-ENet comprises two complementary modules: (1) a dual-phase Endocardial Border Detector (ECBD), which uses phase-specific cross-attention to predict ED/ES endocardial landmarks (EBs) and learn phase-aware landmark embeddings (LEs), and (2) an Endocardial Feature Aggregator (EFA), which fuses these embeddings with global statistical descriptors (mean, maximum, variance) of deep feature maps to refine EF regression. A multi-component loss function, inspired by Simpson's biplane method, jointly supervises EF, volumes, and landmark geometry, thereby aligning optimization with the clinical definition of LVEF and promoting robust spatio-temporal representation learning. Evaluated on the EchoNet-Dynamic dataset, Echo-ENet achieves an RMSE of 5.20 and an score of 0.82, while using only 1.54M parameters and 8.05 GFLOPs. The model operates without external pre-training, heavy data augmentation, or test-time ensembling, making it highly suitable for real-time point-of-care ultrasound (POCUS) applications. Code is available at this https URL.

13 Feb 2024
The accurate segmentation of medical images is critical for various healthcare applications. Convolutional neural networks (CNNs), especially Fully Convolutional Networks (FCNs) like U-Net, have shown remarkable success in medical image segmentation tasks. However, they have limitations in capturing global context and long-range relations, especially for objects with significant variations in shape, scale, and texture. While transformers have achieved state-of-the-art results in natural language processing and image recognition, they face challenges in medical image segmentation due to image locality and translational invariance issues. To address these challenges, this paper proposes an innovative U-shaped network called BEFUnet, which enhances the fusion of body and edge information for precise medical image segmentation. The BEFUnet comprises three main modules, including a novel Local Cross-Attention Feature (LCAF) fusion module, a novel Double-Level Fusion (DLF) module, and dual-branch encoder. The dual-branch encoder consists of an edge encoder and a body encoder. The edge encoder employs PDC blocks for effective edge information extraction, while the body encoder uses the Swin Transformer to capture semantic information with global attention. The LCAF module efficiently fuses edge and body features by selectively performing local cross-attention on features that are spatially close between the two modalities. This local approach significantly reduces computational complexity compared to global cross-attention while ensuring accurate feature matching. BEFUnet demonstrates superior performance over existing methods across various evaluation metrics on medical image segmentation datasets.

13 Oct 2025

Selecting an effective step-size is a fundamental challenge in first-order optimization, especially for problems with non-Euclidean geometries. This paper presents a novel adaptive step-size strategy for optimization algorithms that rely on linear minimization oracles, as used in the Conditional Gradient or non-Euclidean Normalized Steepest Descent algorithms. Using a simple heuristic to estimate a local Lipschitz constant for the gradient, we can determine step-sizes that guarantee sufficient decrease at each iteration. More precisely, we establish convergence guarantees for our proposed Adaptive Conditional Gradient Descent algorithm, which covers as special cases both the classical Conditional Gradient algorithm and non-Euclidean Normalized Steepest Descent algorithms with adaptive step-sizes. Our analysis covers optimization of continuously differentiable functions in non-convex, quasar-convex, and strongly convex settings, achieving convergence rates that match state-of-the-art theoretical bounds. Comprehensive numerical experiments validate our theoretical findings and illustrate the practical effectiveness of Adaptive Conditional Gradient Descent. The results exhibit competitive performance, underscoring the potential of the adaptive step-size for applications.
There are no more papers matching your filters at the moment.
