 Google DeepMind
Google DeepMind
29 Sep 2025
Google DeepMind's research reveals that large generative video models, specifically Veo 3, exhibit emergent zero-shot learning and reasoning capabilities across a broad spectrum of visual tasks, from perception to complex reasoning. This demonstrates that such models can function as general-purpose vision foundation models, performing well on quantitative benchmarks like achieving an OIS F1-score of 0.77 for edge detection and a 78% pass@10 rate for 5x5 maze solving.

28 Aug 2025

This research formally proves that single-vector embedding models possess fundamental theoretical and practical limitations in representing complex, combinatorial relevance definitions, irrespective of model size or training data. It demonstrates that these constraints manifest in realistic scenarios, causing state-of-the-art models to struggle on specially designed stress-test datasets.

29 Sep 2025
Google DeepMind's Dreamer 4 introduces a scalable and efficient world model that enables learning complex control tasks by reinforcement learning entirely within imagination. It achieves the first-ever offline acquisition of diamonds in Minecraft, reaching a 0.7% success rate while performing real-time interactive inference at 21 frames per second on a single GPU.

25 Oct 2025




Mixture-of-Recursions (MoR) introduces a unified framework for language models that combines parameter efficiency, adaptive computation, and efficient KV caching. It achieves strong performance, outperforming vanilla Transformers with nearly 50% fewer parameters and reducing training FLOPs by 25%, while increasing inference throughput by up to 2.06x.

05 Sep 2024



OpenVLA introduces a fully open-source, 7B-parameter Vision-Language-Action model that sets a new state of the art for generalist robot manipulation, outperforming larger closed-source models by 16.5% absolute success rate. The model also demonstrates effective and efficient fine-tuning strategies for adapting to new robot setups and tasks on commodity hardware.

27 Oct 2024

Researchers introduce spectral regularization, a method that maintains neural network plasticity and trainability by explicitly controlling the spectral norms of layer weights. This technique consistently improved performance in diverse continual supervised and reinforcement learning tasks while demonstrating robustness across various non-stationarities and reduced hyperparameter sensitivity.

16 Jun 2025
AlphaEvolve, from Google DeepMind, combines large language models with an evolutionary search framework to autonomously discover novel algorithms and optimize code. This system identified a faster procedure for 4x4 complex matrix multiplication, improved state-of-the-art for several open mathematical problems, and delivered tangible optimizations for Google's computing ecosystem, including recovering 0.7% of fleet-wide compute resources.
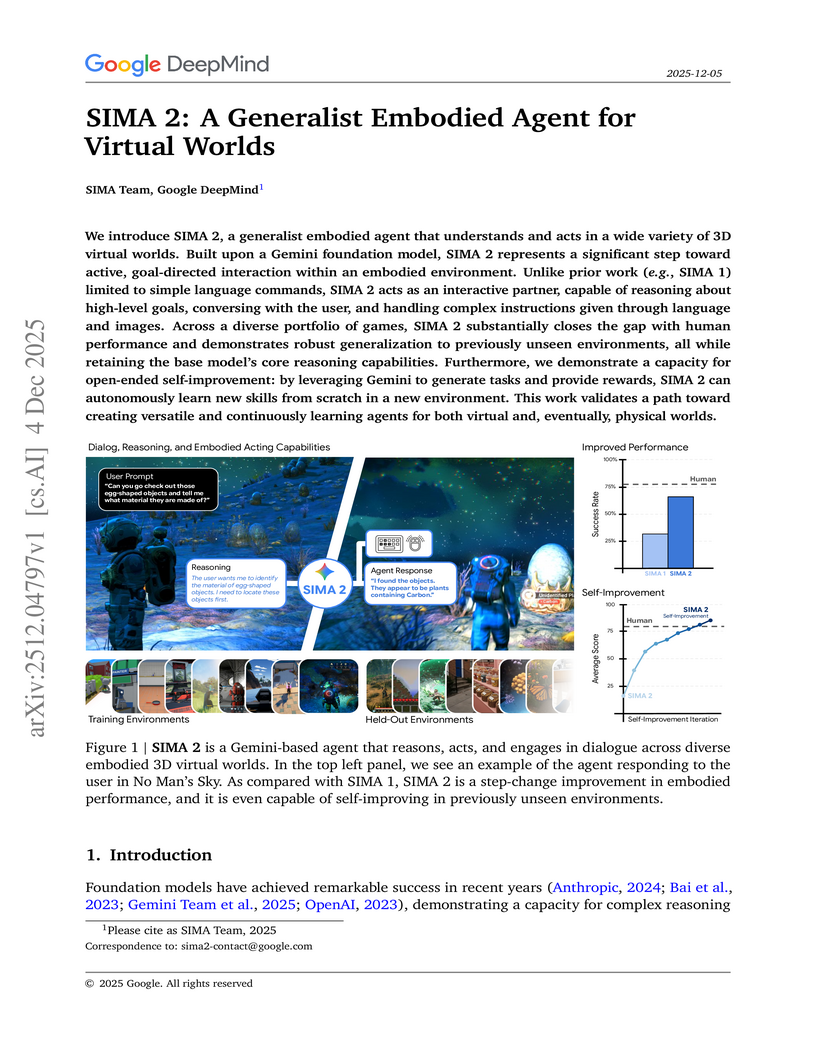
04 Dec 2025
Google DeepMind developed SIMA 2, a generalist embodied agent powered by a Gemini Flash-Lite model, capable of understanding and acting in diverse 3D virtual worlds. It substantially doubles the task success rate of its predecessor SIMA 1, generalizes to unseen commercial games and photorealistic environments, and demonstrates autonomous skill acquisition through a Gemini-based self-improvement mechanism.
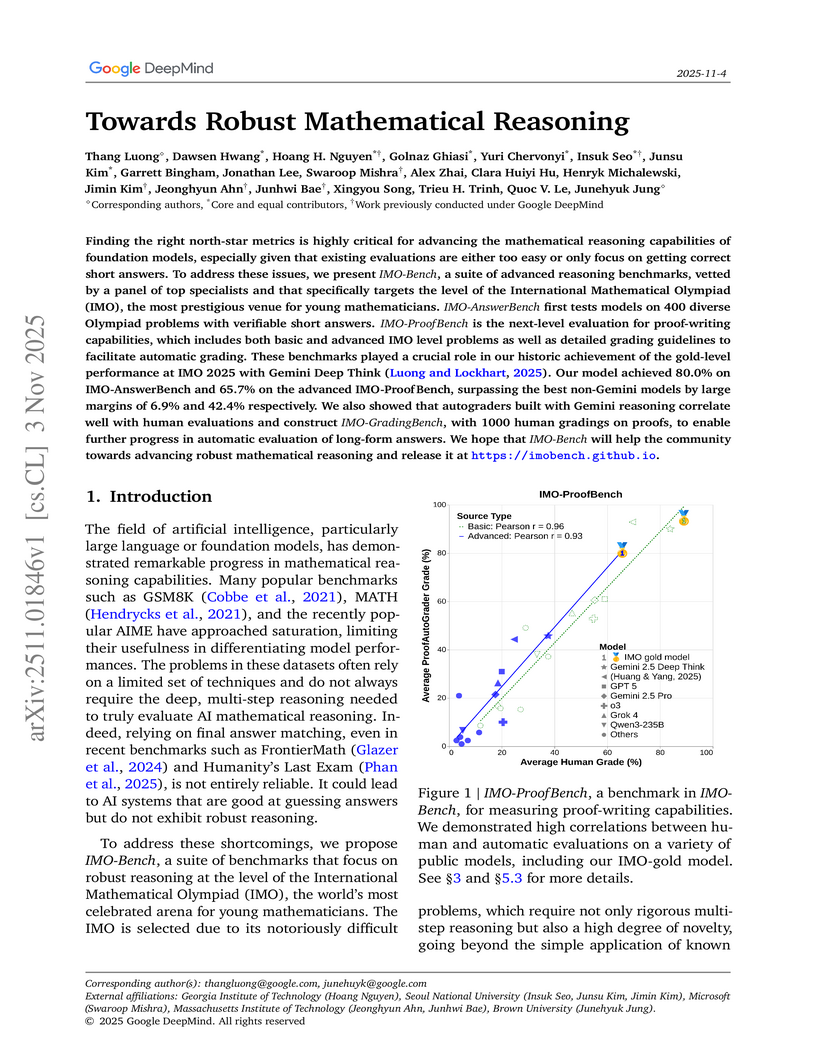
03 Nov 2025




Google DeepMind developed IMO-Bench, a benchmark suite designed to assess advanced mathematical reasoning in large language models through problem-solving, proof writing, and proof grading tasks. The Gemini Deep Think (IMO Gold) model achieved 80.0% accuracy on robustified problems and 65.7% on challenging proof-writing tasks.

29 Mar 2022
Google DeepMind research establishes new compute-optimal scaling laws for large language models, demonstrating that model size and training data should scale equally for efficient training. The resulting 70B parameter Chinchilla model, trained on 1.4 trillion tokens, achieved lower perplexity and outperformed larger models like Gopher and GPT-3 on various benchmarks, validating the new scaling approach.
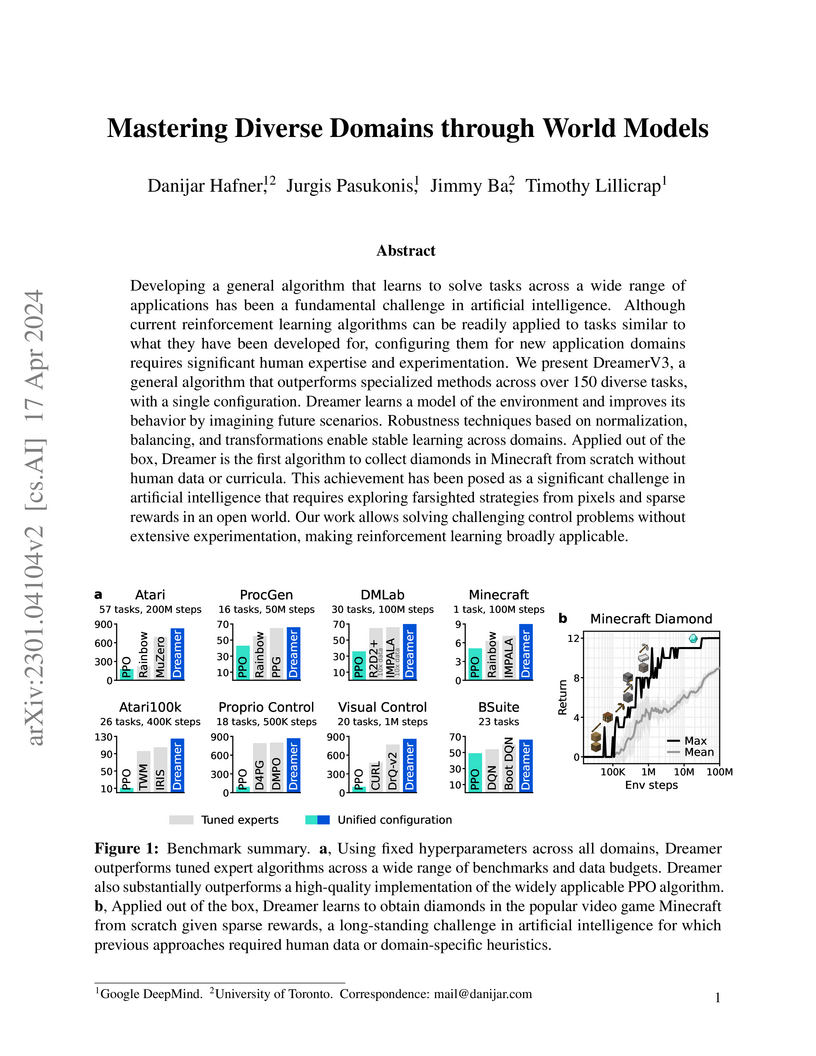
18 Apr 2024

DreamerV3 is an algorithm that achieves state-of-the-art performance across a wide range of reinforcement learning domains using a single, fixed set of hyperparameters. This algorithm is the first to reliably collect diamonds in Minecraft from scratch without human data or curricula, demonstrating broad applicability.

17 Sep 2025

This research details the first systematic discovery of new families of unstable singularities in canonical fluid systems, achieving unprecedented numerical accuracy including near double-float machine precision for specific solutions. It also reveals empirical asymptotic formulas relating blow-up rates to instability orders, advancing the understanding of fundamental mathematical challenges in fluid dynamics.

25 Mar 2025
Google DeepMind introduces Gemma 3, an open-source language model family that combines multimodal capabilities with 128K token context windows through an interleaved local/global attention architecture, enabling competitive performance with larger closed-source models while running on consumer-grade hardware.

20 Feb 2025
Google DeepMind's SigLIP 2 introduces a family of multilingual vision-language encoders, integrating decoder-based pretraining, self-supervised losses, and active data curation to enhance semantic understanding, localization, and dense features. It consistently outperforms previous SigLIP models and other open-source baselines across zero-shot classification, retrieval, dense prediction, and localization tasks, while also reducing representation bias.

06 Nov 2025
Research from Google DeepMind and Stanford University demonstrates that current parametric AI systems lack the ability for latent learning, struggling to flexibly reuse implicitly acquired information for new, uncued tasks. Implementing an episodic memory-like retrieval mechanism consistently and significantly improves generalization across various benchmarks, suggesting it complements parametric learning by enabling on-demand, in-context reuse of past experiences.

03 Dec 2023

Researchers from Princeton University and Google DeepMind developed Tree of Thoughts (ToT), a framework enabling large language models to perform deliberate problem-solving by explicitly exploring and evaluating multiple reasoning paths. This approach, which allows LLMs to self-generate and self-evaluate intermediate thoughts, achieved a 74% success rate on the Game of 24 and improved coherence in creative writing tasks compared to traditional Chain-of-Thought methods.

30 Sep 2025



Researchers at Harvard University, Google DeepMind, and collaborating institutions reverse-engineered successful Implicit Chain-of-Thought (ICoT) Transformers to understand why standard models fail at multi-digit multiplication. They discovered that ICoT models establish long-range dependencies through attention trees for partial product caching and represent digits using Fourier bases, findings that led to a simple auxiliary loss intervention enabling a standard Transformer to achieve 99% accuracy on 4x4 multiplication.

17 Jan 2024
Generalized Knowledge Distillation (GKD) is a framework for distilling auto-regressive language models by training on the student's self-generated output sequences to mitigate train-inference distribution mismatch. GKD consistently improves the performance of smaller student models, achieving gains (e.g., 2.1x on summarization, 1.9x on reasoning) compared to supervised fine-tuning across various tasks, and demonstrates compatibility with RL fine-tuning for improved model alignment.

01 Nov 2024


A new method enables autoregressive models to generate images using continuous-valued representations, bypassing the need for vector quantization. It integrates diffusion processes to model per-token probability distributions, achieving competitive FID scores as low as 1.55 on ImageNet 256x256 while maintaining fast generation speeds of less than 0.3 seconds per image.

26 May 2025


A comparative study by researchers from Hong Kong University, UC Berkeley, NYU, and Google DeepMind empirically demonstrates that Reinforcement Learning (RL) promotes generalization to novel rules and visual inputs, while Supervised Fine-Tuning (SFT) tends to induce memorization, particularly in complex reasoning tasks for foundation models like Llama-3.2-Vision-11B. RL improved out-of-distribution performance by up to +61.1% on visual tasks and also enhanced underlying visual recognition capabilities.
There are no more papers matching your filters at the moment.
