
13 Oct 2025


LONGLIVE is a framework enabling real-time interactive long video generation, achieving 20.7 FPS on a single H100 GPU for videos up to 240 seconds. It integrates a causal autoregressive design with novel techniques like KV-Recache for smooth prompt switching and a frame sink for maintaining long-range consistency with efficient short-window attention.

26 May 2025





A comparative study by researchers from Hong Kong University, UC Berkeley, NYU, and Google DeepMind empirically demonstrates that Reinforcement Learning (RL) promotes generalization to novel rules and visual inputs, while Supervised Fine-Tuning (SFT) tends to induce memorization, particularly in complex reasoning tasks for foundation models like Llama-3.2-Vision-11B. RL improved out-of-distribution performance by up to +61.1% on visual tasks and also enhanced underlying visual recognition capabilities.

01 Dec 2025




Tuna, a native unified multimodal model developed by Meta BizAI, introduces a novel cascaded VAE and representation encoder to construct a single, continuous visual representation for both understanding and generation. This architecture achieves state-of-the-art performance across diverse image and video understanding, generation, and editing benchmarks, often outperforming larger, specialized models while utilizing smaller LLM decoders.

20 Oct 2024
Depth Anything V2 introduces a new paradigm for monocular depth estimation by leveraging precise synthetic data for detail and massive pseudo-labeled real data for robustness. The model family achieves state-of-the-art performance in zero-shot relative depth estimation, with the largest model reaching 97.4% accuracy on the new DA-2K benchmark, while maintaining high inference efficiency.

25 Mar 2024

Point Transformer V3 (PTv3) presents a streamlined and highly efficient point cloud transformer architecture designed to capitalize on the power of scale in 3D deep learning. This approach leads to a 3.3x increase in inference speed and a 10.2x reduction in memory consumption compared to its predecessor, enabling the model to achieve new state-of-the-art performance across over 20 diverse indoor and outdoor 3D perception tasks.

30 Sep 2025
LongVILA-R1 is a comprehensive framework that equips Vision-Language Models with advanced reasoning capabilities for long video sequences, leveraging a novel dataset and a highly efficient training infrastructure. It achieves state-of-the-art performance on various long video benchmarks and accelerates reinforcement learning training by up to 2.1x for 7B models.
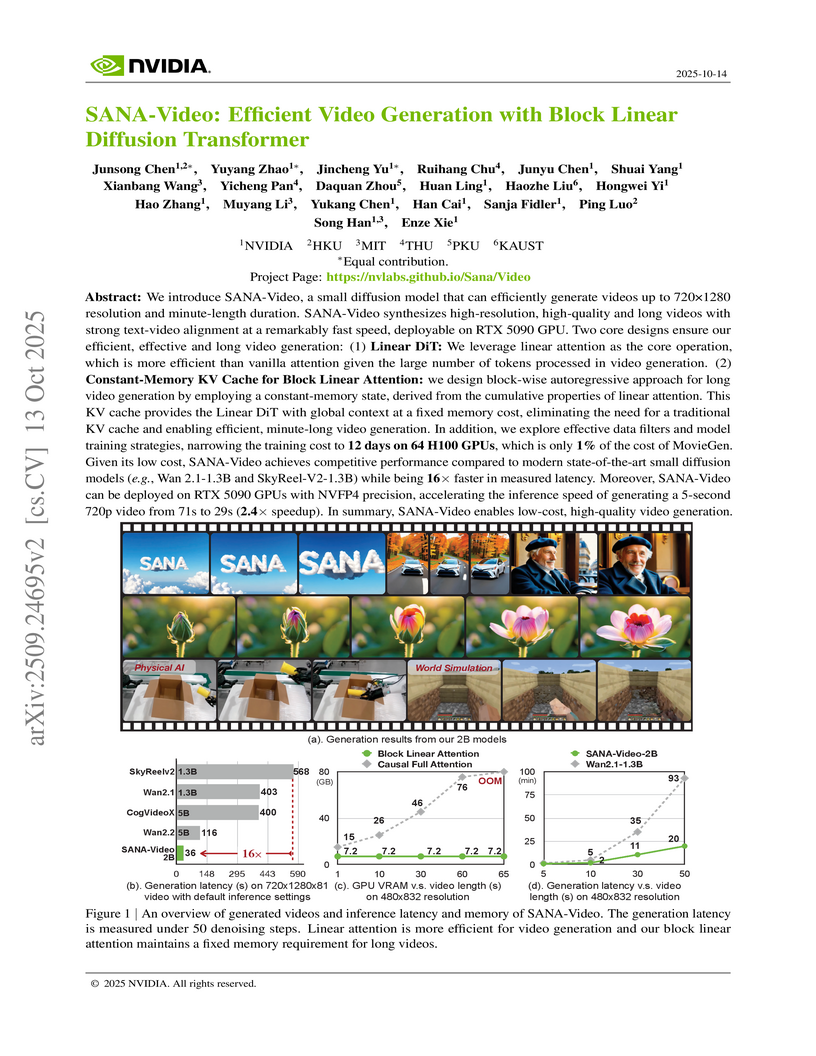
13 Oct 2025


NVIDIA researchers and collaborators developed SANA-Video, an efficient video generation model that uses a Block Linear Diffusion Transformer to enable high-resolution, long-duration video synthesis with significantly reduced computational costs. The model reduces training cost to 1% of MovieGen and achieves 16x faster inference than existing small diffusion models, generating a 5-second 720p video in 36 seconds on an H100 GPU.

25 Sep 2025
P³-SAM, developed by Tencent Hunyuan and academic collaborators, introduces a native 3D point-promptable part segmentation model trained on a new 3.7 million model dataset, achieving fully automatic and precise segmentation of complex 3D objects. This approach bypasses limitations of 2D-dependent methods, leading to superior quantitative performance and robust generalization.

08 Oct 2025



DreamOmni2 introduces a multimodal instruction-based editing and generation framework that enables image manipulation using both text and multiple reference images for concrete objects and abstract attributes. The system, supported by a novel synthetic data pipeline and an enhanced Diffusion Transformer, achieves leading performance in human evaluations for image editing (e.g., 68.29% for abstract attribute editing) and competitive results in generation compared to commercial models.

30 May 2025

Researchers from Nanjing University, CASIA, HKU, and other institutions introduced Video-MME, a comprehensive benchmark for evaluating multi-modal large language models (MLLMs) in video analysis, covering diverse domains, temporal lengths, and modalities. Evaluations on Video-MME revealed that commercial MLLMs, particularly Gemini 1.5 Pro, achieved higher accuracy than open-source models, and performance across all models declined with increasing video duration, despite gains from integrating subtitles and audio.
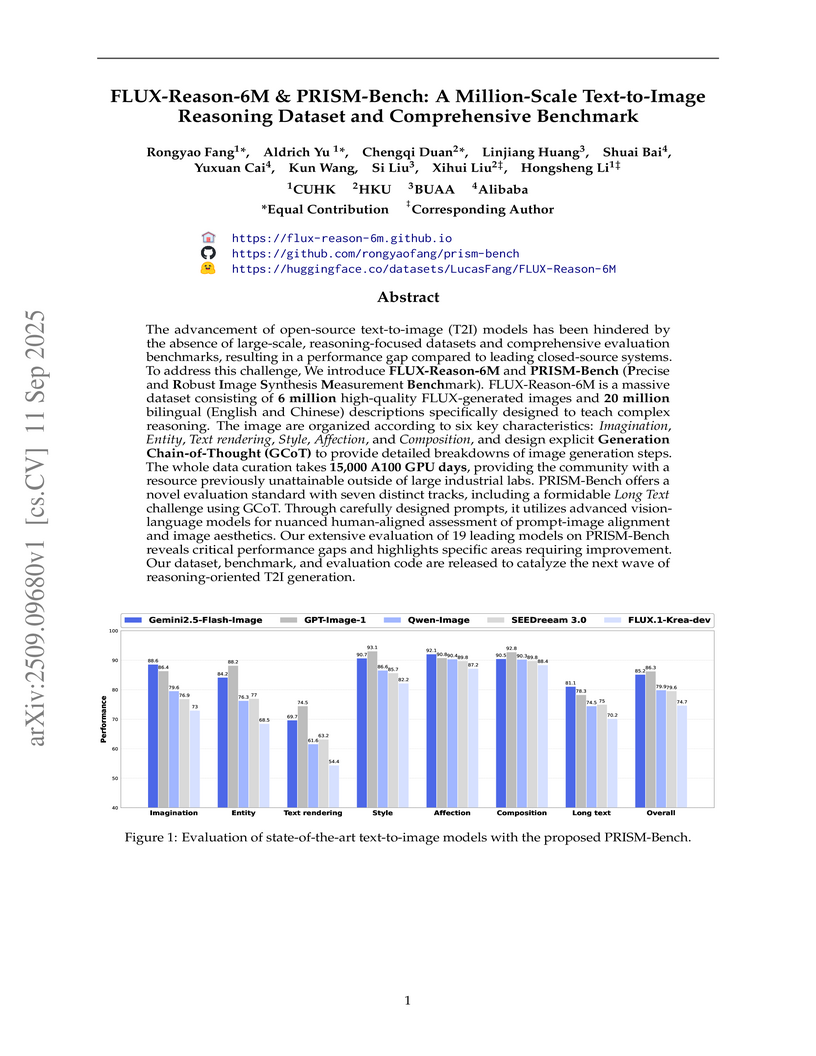
11 Sep 2025
Researchers from CUHK, HKU, Beihang University, and Alibaba introduced FLUX-Reason-6M, a 6-million-image, reasoning-focused text-to-image dataset, and PRISM-Bench, a comprehensive benchmark for evaluating T2I models. This work provides an open-source resource with 20 million bilingual captions, including Generation Chain-of-Thought prompts, aiming to advance T2I reasoning capabilities and offering a robust evaluation of 19 leading models, highlighting persistent challenges in text rendering and long instruction following.

27 Nov 2025

G
G
²VLM integrates 3D reconstruction and spatial reasoning within a single Vision-Language Model, addressing the spatial intelligence limitations of current VLMs. It learns explicit visual geometry from 2D data using a Mixture-of-Transformer-Experts architecture, leading to robust spatial understanding and strong performance on both 3D reconstruction and complex spatial reasoning benchmarks.

13 Oct 2025
CodePlot-CoT introduces a code-driven Chain-of-Thought paradigm, enabling Vision Language Models (VLMs) to generate precise visual aids by producing executable plotting code that is then rendered and re-integrated into the reasoning process. This method, along with the new Math-VR dataset, allowed CodePlot-CoT to achieve up to a 21% performance increase on mathematical visual reasoning tasks, surpassing larger models and those using direct image generation.

24 Sep 2025
Generating 3D shapes at part level is pivotal for downstream applications such as mesh retopology, UV mapping, and 3D printing. However, existing part-based generation methods often lack sufficient controllability and suffer from poor semantically meaningful decomposition. To this end, we introduce X-Part, a controllable generative model designed to decompose a holistic 3D object into semantically meaningful and structurally coherent parts with high geometric fidelity. X-Part exploits the bounding box as prompts for the part generation and injects point-wise semantic features for meaningful decomposition. Furthermore, we design an editable pipeline for interactive part generation. Extensive experimental results show that X-Part achieves state-of-the-art performance in part-level shape generation. This work establishes a new paradigm for creating production-ready, editable, and structurally sound 3D assets. Codes will be released for public research.

29 Dec 2023
PIXART-α is a Diffusion Transformer-based model that produces photorealistic text-to-image synthesis comparable to leading models, achieving a COCO FID-30K of 7.32 while drastically cutting training costs to approximately $28,400 (753 A100 GPU days) through a novel three-stage training strategy and efficient architectural designs.

13 Nov 2025
Transformers are increasingly prevalent for multi-view computer vision tasks, where geometric relationships between viewpoints are critical for 3D perception. To leverage these relationships, multi-view transformers must use camera geometry to ground visual tokens in 3D space. In this work, we compare techniques for conditioning transformers on cameras: token-level raymap encodings, attention-level relative pose encodings, and a new relative encoding we propose -- Projective Positional Encoding (PRoPE) -- that captures complete camera frustums, both intrinsics and extrinsics, as a relative positional encoding. Our experiments begin by showing how relative camera conditioning improves performance in feedforward novel view synthesis, with further gains from PRoPE. This holds across settings: scenes with both shared and varying intrinsics, when combining token- and attention-level conditioning, and for generalization to inputs with out-of-distribution sequence lengths and camera intrinsics. We then verify that these benefits persist for different tasks, stereo depth estimation and discriminative spatial cognition, as well as larger model sizes.

05 Jun 2025
The Perceive Anything Model (PAM) extends the Segment Anything Model 2 (SAM 2) framework to achieve comprehensive region-level visual understanding, performing recognition, explanation, captioning, and segmentation in both images and videos. PAM operates 1.2-2.4 times faster and consumes less GPU memory than prior models, while achieving state-of-the-art performance across various image and video benchmarks, including novel streaming video region captioning tasks.
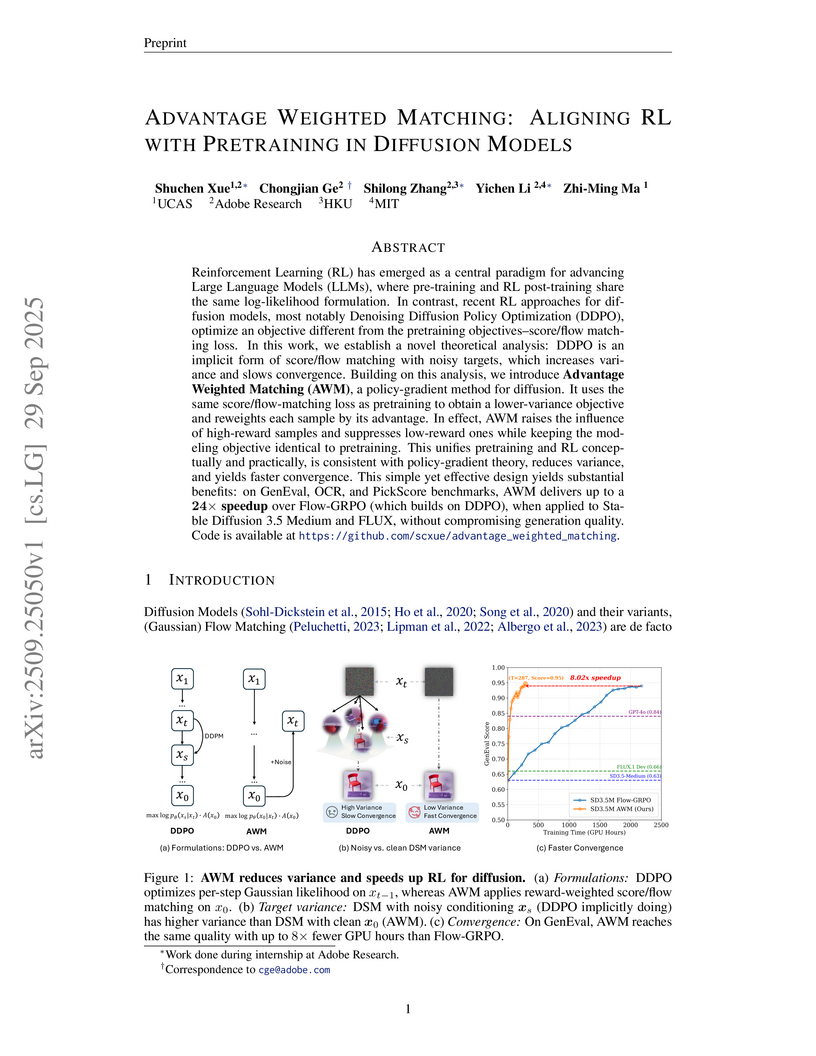
29 Sep 2025

Reinforcement Learning (RL) has emerged as a central paradigm for advancing Large Language Models (LLMs), where pre-training and RL post-training share the same log-likelihood formulation. In contrast, recent RL approaches for diffusion models, most notably Denoising Diffusion Policy Optimization (DDPO), optimize an objective different from the pretraining objectives--score/flow matching loss. In this work, we establish a novel theoretical analysis: DDPO is an implicit form of score/flow matching with noisy targets, which increases variance and slows convergence. Building on this analysis, we introduce \textbf{Advantage Weighted Matching (AWM)}, a policy-gradient method for diffusion. It uses the same score/flow-matching loss as pretraining to obtain a lower-variance objective and reweights each sample by its advantage. In effect, AWM raises the influence of high-reward samples and suppresses low-reward ones while keeping the modeling objective identical to pretraining. This unifies pretraining and RL conceptually and practically, is consistent with policy-gradient theory, reduces variance, and yields faster convergence. This simple yet effective design yields substantial benefits: on GenEval, OCR, and PickScore benchmarks, AWM delivers up to a speedup over Flow-GRPO (which builds on DDPO), when applied to Stable Diffusion 3.5 Medium and FLUX, without compromising generation quality. Code is available at this https URL.

24 Nov 2025

CUPID introduces a unified framework for generative 3D reconstruction by jointly modeling canonical 3D objects and their object-centric camera poses from a single 2D image. The approach achieves new state-of-the-art in monocular geometry accuracy and input-view consistency, while enabling robust compositional scene reconstruction.

11 Jun 2025
Researchers from HKU, DAMO Academy (Alibaba Group), and HUST develop PlayerOne, the first egocentric realistic world simulator that enables users to actively explore dynamic environments through free human motion control, achieving superior performance with 67.8 DINO-Score vs 38.0-51.6 for state-of-the-art competitors through a diffusion transformer architecture featuring part-disentangled motion injection that categorizes human motion into body/feet, hands, and head components with dedicated encoders, joint scene-frame reconstruction using point maps for 4D consistency, and a coarse-to-fine training strategy combining large-scale egocentric text-video pre-training with fine-grained motion-video alignment on a curated dataset from EgoExo-4D and other sources, demonstrating real-time generation at 8 FPS while maintaining strict alignment between generated egocentric videos and real-scene human motion captured by exocentric cameras across diverse realistic scenarios.
There are no more papers matching your filters at the moment.
