
15 Dec 2021


Deep generative models applied to audio have improved by a large margin the
state-of-the-art in many speech and music related tasks. However, as raw
waveform modelling remains an inherently difficult task, audio generative
models are either computationally intensive, rely on low sampling rates, are
complicated to control or restrict the nature of possible signals. Among those
models, Variational AutoEncoders (VAE) give control over the generation by
exposing latent variables, although they usually suffer from low synthesis
quality. In this paper, we introduce a Realtime Audio Variational autoEncoder
(RAVE) allowing both fast and high-quality audio waveform synthesis. We
introduce a novel two-stage training procedure, namely representation learning
and adversarial fine-tuning. We show that using a post-training analysis of the
latent space allows a direct control between the reconstruction fidelity and
the representation compactness. By leveraging a multi-band decomposition of the
raw waveform, we show that our model is the first able to generate 48kHz audio
signals, while simultaneously running 20 times faster than real-time on a
standard laptop CPU. We evaluate synthesis quality using both quantitative and
qualitative subjective experiments and show the superiority of our approach
compared to existing models. Finally, we present applications of our model for
timbre transfer and signal compression. All of our source code and audio
examples are publicly available.

12 May 2022
Automatic Music Transcription (AMT) has been recognized as a key enabling technology with a wide range of applications. Given the task's complexity, best results have typically been reported for systems focusing on specific settings, e.g. instrument-specific systems tend to yield improved results over instrument-agnostic methods. Similarly, higher accuracy can be obtained when only estimating frame-wise values and neglecting the harder note event detection. Despite their high accuracy, such specialized systems often cannot be deployed in the real-world. Storage and network constraints prohibit the use of multiple specialized models, while memory and run-time constraints limit their complexity. In this paper, we propose a lightweight neural network for musical instrument transcription, which supports polyphonic outputs and generalizes to a wide variety of instruments (including vocals). Our model is trained to jointly predict frame-wise onsets, multipitch and note activations, and we experimentally show that this multi-output structure improves the resulting frame-level note accuracy. Despite its simplicity, benchmark results show our system's note estimation to be substantially better than a comparable baseline, and its frame-level accuracy to be only marginally below those of specialized state-of-the-art AMT systems. With this work we hope to encourage the community to further investigate low-resource, instrument-agnostic AMT systems.

07 Jan 2025


MusicGen-Stem introduces an autoregressive model capable of generating and editing multi-stem music, producing separated bass, drums, and "other" instrument tracks. It achieves quality comparable to mixture-level models for general generation while demonstrating superior rhythmic and harmonic coherence in stem-level editing compared to prior approaches.

13 Oct 2025

Human communication is multimodal, with speech and gestures tightly coupled, yet most computational methods for generating speech and gestures synthesize them sequentially, weakening synchrony and prosody alignment. We introduce Gelina, a unified framework that jointly synthesizes speech and co-speech gestures from text using interleaved token sequences in a discrete autoregressive backbone, with modality-specific decoders. Gelina supports multi-speaker and multi-style cloning and enables gesture-only synthesis from speech inputs. Subjective and objective evaluations demonstrate competitive speech quality and improved gesture generation over unimodal baselines.

15 Nov 2025

Neural codec language models, built on transformer architecture, have revolutionized text-to-speech (TTS) synthesis, excelling in voice cloning by treating it as a prefix continuation task. However, their limited context length hinders their effectiveness to short speech samples. As a result, the voice cloning ability is restricted to a limited coverage and diversity of the speaker's prosody and style. Besides, adapting prosody, accent, or appropriate emotion from a short prefix remains a challenging task. Finally, the quadratic complexity of self-attention limits inference throughput. In this work, we introduce Lina-Speech, a TTS model with Gated Linear Attention (GLA) to replace standard self-attention as a principled backbone, improving inference throughput while matching state-of-the-art performance. Leveraging the stateful property of recurrent architecture, we introduce an Initial-State Tuning (IST) strategy that unlocks the possibility of multiple speech sample conditioning of arbitrary numbers and lengths and provides a comprehensive and efficient strategy for voice cloning and out-of-domain speaking style and emotion adaptation. We demonstrate the effectiveness of this approach for controlling fine-grained characteristics such as prosody and emotion. Code, checkpoints, and demo are freely available: this https URL

29 May 2022








What audio embedding approach generalizes best to a wide range of downstream tasks across a variety of everyday domains without fine-tuning? The aim of the HEAR benchmark is to develop a general-purpose audio representation that provides a strong basis for learning in a wide variety of tasks and scenarios. HEAR evaluates audio representations using a benchmark suite across a variety of domains, including speech, environmental sound, and music. HEAR was launched as a NeurIPS 2021 shared challenge. In the spirit of shared exchange, each participant submitted an audio embedding model following a common API that is general-purpose, open-source, and freely available to use. Twenty-nine models by thirteen external teams were evaluated on nineteen diverse downstream tasks derived from sixteen datasets. Open evaluation code, submitted models and datasets are key contributions, enabling comprehensive and reproducible evaluation, as well as previously impossible longitudinal studies. It still remains an open question whether one single general-purpose audio representation can perform as holistically as the human ear.

31 Jul 2024
Deep generative models are now able to synthesize high-quality audio signals, shifting the critical aspect in their development from audio quality to control capabilities. Although text-to-music generation is getting largely adopted by the general public, explicit control and example-based style transfer are more adequate modalities to capture the intents of artists and musicians.
In this paper, we aim to unify explicit control and style transfer within a single model by separating local and global information to capture musical structure and timbre respectively. To do so, we leverage the capabilities of diffusion autoencoders to extract semantic features, in order to build two representation spaces. We enforce disentanglement between those spaces using an adversarial criterion and a two-stage training strategy. Our resulting model can generate audio matching a timbre target, while specifying structure either with explicit controls or through another audio example. We evaluate our model on one-shot timbre transfer and MIDI-to-audio tasks on instrumental recordings and show that we outperform existing baselines in terms of audio quality and target fidelity. Furthermore, we show that our method can generate cover versions of complete musical pieces by transferring rhythmic and melodic content to the style of a target audio in a different genre.

06 Feb 2024

A hybrid deep learning model processes both time-domain waveforms and frequency-domain spectrograms to achieve highly accurate, full-sphere binaural sound source localization. This approach delivers precise spatial sound perception from a two-microphone setup, significantly outperforming existing methods.

09 Jun 2024
Music generation schemes using language modeling rely on a vocabulary of audio tokens, generally provided as codes in a discrete latent space learnt by an auto-encoder. Multi-stage quantizers are often employed to produce these tokens, therefore the decoding strategy used for token prediction must be adapted to account for multiple codebooks: either it should model the joint distribution over all codebooks, or fit the product of the codebook marginal distributions. Modelling the joint distribution requires a costly increase in the number of auto-regressive steps, while fitting the product of the marginals yields an inexact model unless the codebooks are mutually independent. In this work, we introduce an independence-promoting loss to regularize the auto-encoder used as the tokenizer in language models for music generation. The proposed loss is a proxy for mutual information based on the maximum mean discrepancy principle, applied in reproducible kernel Hilbert spaces. Our criterion is simple to implement and train, and it is generalizable to other multi-stream codecs. We show that it reduces the statistical dependence between codebooks during auto-encoding. This leads to an increase in the generated music quality when modelling the product of the marginal distributions, while generating audio much faster than the joint distribution model.

22 Nov 2015
This paper resumes the results of a research conducted in a music production situation Therefore, it is more a final lab report, a prospective methodology then a scientific experience. The methodology we are presenting was developed as an answer to a musical problem raised by the Italian composer Marta Gentilucci. The problem was "how to extract a temporal structure from a vowel tremolo, on a tenuto (steady state) pitch." The musical goal was to apply, in a compositional context the vowel tremolo time structure on a tenuto pitch chord, as a transposition this http URL this context we decide to follow, to explore the potential of low-level MPEG7 audio descriptors to build event detection functions. One of the main problems using low-level audio descriptors in audio analysis is the redundancy of information among them. We describe an "ad hoc" interactive methodology, based on side effect use of dimensionality reduction by PCA, to choose a feature from a set of low-level audio descriptors, to be used to detect a vowel tremolo rhythm. This methodology is supposed to be interactive and easy enough to be used in a live creative context.

27 Feb 2023
Despite significant advances in deep models for music generation, the use of
these techniques remains restricted to expert users. Before being democratized
among musicians, generative models must first provide expressive control over
the generation, as this conditions the integration of deep generative models in
creative workflows. In this paper, we tackle this issue by introducing a deep
generative audio model providing expressive and continuous descriptor-based
control, while remaining lightweight enough to be embedded in a hardware
synthesizer. We enforce the controllability of real-time generation by
explicitly removing salient musical features in the latent space using an
adversarial confusion criterion. User-specified features are then reintroduced
as additional conditioning information, allowing for continuous control of the
generation, akin to a synthesizer knob. We assess the performance of our method
on a wide variety of sounds including instrumental, percussive and speech
recordings while providing both timbre and attributes transfer, allowing new
ways of generating sounds.

09 Apr 2020
This paper presents Att-HACK, the first large database of acted speech with
social attitudes. Available databases of expressive speech are rare and very
often restricted to the primary emotions: anger, joy, sadness, fear. This
greatly limits the scope of the research on expressive speech. Besides, a
fundamental aspect of speech prosody is always ignored and missing from such
databases: its variety, i.e. the possibility to repeat an utterance while
varying its prosody. This paper represents a first attempt to widen the scope
of expressivity in speech, by providing a database of acted speech with social
attitudes: friendly, seductive, dominant, and distant. The proposed database
comprises 25 speakers interpreting 100 utterances in 4 social attitudes, with
3-5 repetitions each per attitude for a total of around 30 hours of speech. The
Att-HACK is freely available for academic research under a Creative Commons
Licence.

07 Jul 2025
Precise control over speech characteristics, such as pitch, duration, and speech rate, remains a significant challenge in the field of voice conversion. The ability to manipulate parameters like pitch and syllable rate is an important element for effective identity conversion, but can also be used independently for voice transformation, achieving goals that were historically addressed by vocoder-based methods.
In this work, we explore a convolutional neural network-based approach that aims to provide means for modifying fundamental frequency (F0), phoneme sequences, intensity, and speaker identity. Rather than relying on disentanglement techniques, our model is explicitly conditioned on these factors to generate mel spectrograms, which are then converted into waveforms using a universal neural vocoder. Accordingly, during inference, F0 contours, phoneme sequences, and speaker embeddings can be freely adjusted, allowing for intuitively controlled voice transformations.
We evaluate our approach on speaker conversion and expressive speech tasks using both perceptual and objective metrics. The results suggest that the proposed method offers substantial flexibility, while maintaining high intelligibility and speaker similarity.

19 Oct 2018
This article introduces the Projective Orchestral Database (POD), a collection of MIDI scores composed of pairs linking piano scores to their corresponding orchestrations. To the best of our knowledge, this is the first database of its kind, which performs piano or orchestral prediction, but more importantly which tries to learn the correlations between piano and orchestral scores. Hence, we also introduce the projective orchestration task, which consists in learning how to perform the automatic orchestration of a piano score. We show how this task can be addressed using learning methods and also provide methodological guidelines in order to properly use this database.

19 Oct 2018
This article introduces the Projective Orchestral Database (POD), a collection of MIDI scores composed of pairs linking piano scores to their corresponding orchestrations. To the best of our knowledge, this is the first database of its kind, which performs piano or orchestral prediction, but more importantly which tries to learn the correlations between piano and orchestral scores. Hence, we also introduce the projective orchestration task, which consists in learning how to perform the automatic orchestration of a piano score. We show how this task can be addressed using learning methods and also provide methodological guidelines in order to properly use this database.

27 Apr 2021
This work introduces a contrastive learning-based data cleansing method designed to identify errors in structured, time-varying annotations for Music Information Retrieval, specifically vocal note events. The approach significantly improves the performance of downstream vocal pitch transcription models by filtering or weighting training data based on estimated annotation correctness, and quantifies the prevalence of errors in large-scale datasets like DALI.
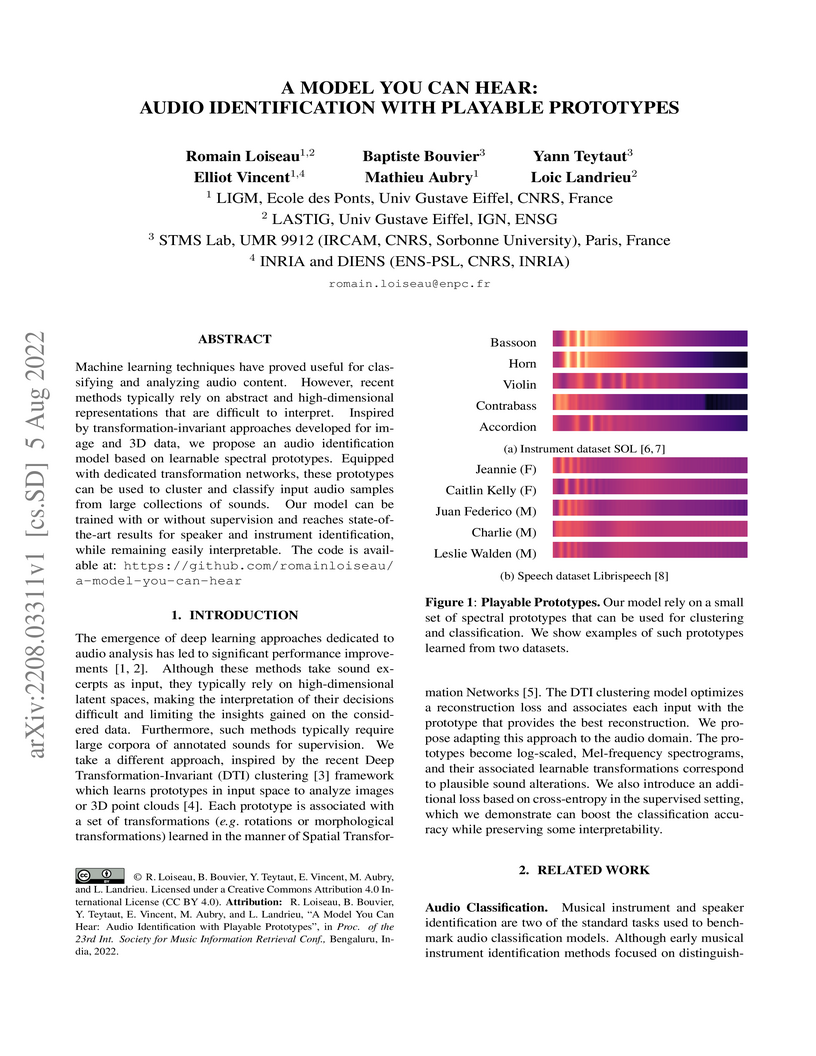
05 Aug 2022
Machine learning techniques have proved useful for classifying and analyzing audio content. However, recent methods typically rely on abstract and high-dimensional representations that are difficult to interpret. Inspired by transformation-invariant approaches developed for image and 3D data, we propose an audio identification model based on learnable spectral prototypes. Equipped with dedicated transformation networks, these prototypes can be used to cluster and classify input audio samples from large collections of sounds. Our model can be trained with or without supervision and reaches state-of-the-art results for speaker and instrument identification, while remaining easily interpretable. The code is available at: this https URL

03 Jul 2021

Granular sound synthesis is a popular audio generation technique based on
rearranging sequences of small waveform windows. In order to control the
synthesis, all grains in a given corpus are analyzed through a set of acoustic
descriptors. This provides a representation reflecting some form of local
similarities across the grains. However, the quality of this grain space is
bound by that of the descriptors. Its traversal is not continuously invertible
to signal and does not render any structured temporality.
We demonstrate that generative neural networks can implement granular
synthesis while alleviating most of its shortcomings. We efficiently replace
its audio descriptor basis by a probabilistic latent space learned with a
Variational Auto-Encoder. In this setting the learned grain space is
invertible, meaning that we can continuously synthesize sound when traversing
its dimensions. It also implies that original grains are not stored for
synthesis. Another major advantage of our approach is to learn structured paths
inside this latent space by training a higher-level temporal embedding over
arranged grain sequences.
The model can be applied to many types of libraries, including pitched notes
or unpitched drums and environmental noises. We report experiments on the
common granular synthesis processes as well as novel ones such as conditional
sampling and morphing.

03 Aug 2022
Modeling virtual agents with behavior style is one factor for personalizing
human agent interaction. We propose an efficient yet effective machine learning
approach to synthesize gestures driven by prosodic features and text in the
style of different speakers including those unseen during training. Our model
performs zero shot multimodal style transfer driven by multimodal data from the
PATS database containing videos of various speakers. We view style as being
pervasive while speaking, it colors the communicative behaviors expressivity
while speech content is carried by multimodal signals and text. This
disentanglement scheme of content and style allows us to directly infer the
style embedding even of speaker whose data are not part of the training phase,
without requiring any further training or fine tuning. The first goal of our
model is to generate the gestures of a source speaker based on the content of
two audio and text modalities. The second goal is to condition the source
speaker predicted gestures on the multimodal behavior style embedding of a
target speaker. The third goal is to allow zero shot style transfer of speakers
unseen during training without retraining the model. Our system consists of:
(1) a speaker style encoder network that learns to generate a fixed dimensional
speaker embedding style from a target speaker multimodal data and (2) a
sequence to sequence synthesis network that synthesizes gestures based on the
content of the input modalities of a source speaker and conditioned on the
speaker style embedding. We evaluate that our model can synthesize gestures of
a source speaker and transfer the knowledge of target speaker style variability
to the gesture generation task in a zero shot setup. We convert the 2D gestures
to 3D poses and produce 3D animations. We conduct objective and subjective
evaluations to validate our approach and compare it with a baseline.

28 Jan 2021
Software tools for generating digital sound often present users with
high-dimensional, parametric interfaces, that may not facilitate exploration of
diverse sound designs. In this paper, we propose to investigate artificial
agents using deep reinforcement learning to explore parameter spaces in
partnership with users for sound design. We describe a series of user-centred
studies to probe the creative benefits of these agents and adapting their
design to exploration. Preliminary studies observing users' exploration
strategies with parametric interfaces and testing different agent exploration
behaviours led to the design of a fully-functioning prototype, called
Co-Explorer, that we evaluated in a workshop with professional sound designers.
We found that the Co-Explorer enables a novel creative workflow centred on
human-machine partnership, which has been positively received by practitioners.
We also highlight varied user exploration behaviors throughout partnering with
our system. Finally, we frame design guidelines for enabling such
co-exploration workflow in creative digital applications.
There are no more papers matching your filters at the moment.
