15 Sep 2025
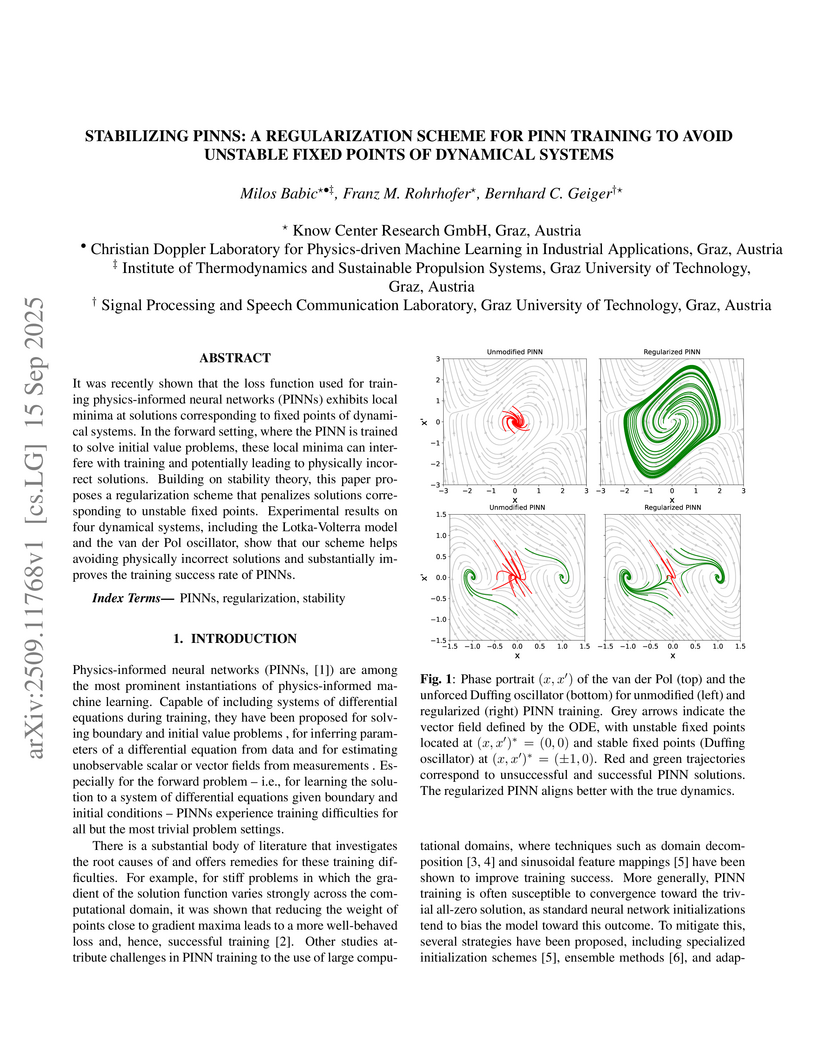
It was recently shown that the loss function used for training physics-informed neural networks (PINNs) exhibits local minima at solutions corresponding to fixed points of dynamical systems. In the forward setting, where the PINN is trained to solve initial value problems, these local minima can interfere with training and potentially leading to physically incorrect solutions. Building on stability theory, this paper proposes a regularization scheme that penalizes solutions corresponding to unstable fixed points. Experimental results on four dynamical systems, including the Lotka-Volterra model and the van der Pol oscillator, show that our scheme helps avoiding physically incorrect solutions and substantially improves the training success rate of PINNs.
15 Sep 2025
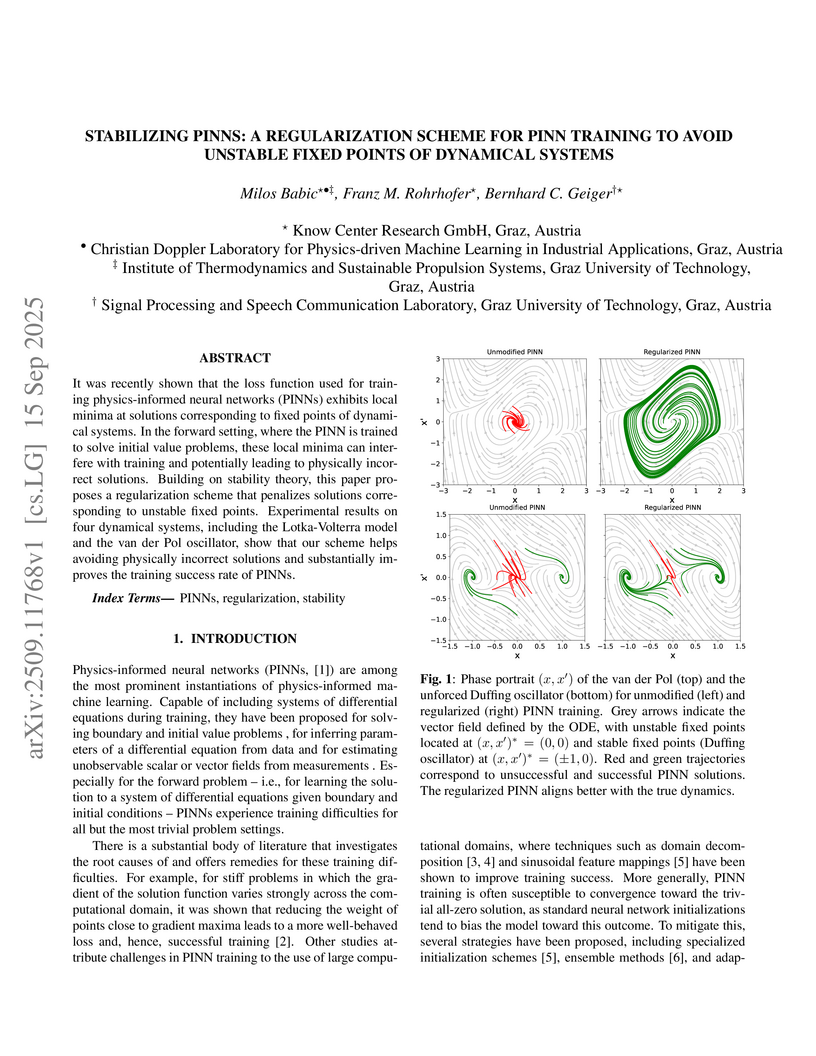
It was recently shown that the loss function used for training physics-informed neural networks (PINNs) exhibits local minima at solutions corresponding to fixed points of dynamical systems. In the forward setting, where the PINN is trained to solve initial value problems, these local minima can interfere with training and potentially leading to physically incorrect solutions. Building on stability theory, this paper proposes a regularization scheme that penalizes solutions corresponding to unstable fixed points. Experimental results on four dynamical systems, including the Lotka-Volterra model and the van der Pol oscillator, show that our scheme helps avoiding physically incorrect solutions and substantially improves the training success rate of PINNs.

16 Jul 2025
This paper presents the first multistakeholder approach for translating diverse stakeholder values into an evaluation metric setup for Recommender Systems (RecSys) in digital archives. While commercial platforms mainly rely on engagement metrics, cultural heritage domains require frameworks that balance competing priorities among archivists, platform owners, researchers, and other stakeholders. To address this challenge, we conducted high-profile focus groups (5 groups x 5 persons) with upstream, provider, system, consumer, and downstream stakeholders, identifying value priorities across critical dimensions: visibility/representation, expertise adaptation, and transparency/trust. Our analysis shows that stakeholder concerns naturally align with four sequential research funnel stages: discovery, interaction, integration, and impact. The resulting evaluation setup addresses domain-specific challenges including collection representation imbalances, non-linear research patterns, and tensions between specialized expertise and broader accessibility. We propose directions for tailored metrics in each stage of this research journey, such as research path quality for discovery, contextual appropriateness for interaction, metadata-weighted relevance for integration, and cross-stakeholder value alignment for impact assessment. Our contributions extend beyond digital archives to the broader RecSys community, offering transferable evaluation approaches for domains where value emerges through sustained engagement rather than immediate consumption.

18 Feb 2025
In this work-in-progress, we investigate the certification of AI systems,
focusing on the practical application and limitations of existing certification
catalogues in the light of the AI Act by attempting to certify a publicly
available AI system. We aim to evaluate how well current approaches work to
effectively certify an AI system, and how publicly accessible AI systems, that
might not be actively maintained or initially intended for certification, can
be selected and used for a sample certification process. Our methodology
involves leveraging the Fraunhofer AI Assessment Catalogue as a comprehensive
tool to systematically assess an AI model's compliance with certification
standards. We find that while the catalogue effectively structures the
evaluation process, it can also be cumbersome and time-consuming to use. We
observe the limitations of an AI system that has no active development team
anymore and highlighted the importance of complete system documentation.
Finally, we identify some limitations of the certification catalogues used and
proposed ideas on how to streamline the certification process.

02 Oct 2025
Differential privacy (DP) is a prominent method for protecting information about individuals during data analysis. Training neural networks with differentially private stochastic gradient descent (DPSGD) influences the model's learning dynamics and, consequently, its output. This can affect the model's performance and fairness. While the majority of studies on the topic report a negative impact on fairness, it has recently been suggested that fairness levels comparable to non-private models can be achieved by optimizing hyperparameters for performance directly on differentially private models (rather than re-using hyperparameters from non-private models, as is common practice). In this work, we analyze the generalizability of this claim by 1) comparing the disparate impact of DPSGD on different performance metrics, and 2) analyzing it over a wide range of hyperparameter settings. We highlight that a disparate impact on one metric does not necessarily imply a disparate impact on another. Most importantly, we show that while optimizing hyperparameters directly on differentially private models does not mitigate the disparate impact of DPSGD reliably, it can still lead to improved utility-fairness trade-offs compared to re-using hyperparameters from non-private models. We stress, however, that any form of hyperparameter tuning entails additional privacy leakage, calling for careful considerations of how to balance privacy, utility and fairness. Finally, we extend our analyses to DPSGD-Global-Adapt, a variant of DPSGD designed to mitigate the disparate impact on accuracy, and conclude that this alternative may not be a robust solution with respect to hyperparameter choice.

27 Feb 2025
Incremental Learning scenarios do not always represent real-world inference
use-cases, which tend to have less strict task boundaries, and exhibit
repetition of common classes and concepts in their continual data stream. To
better represent these use-cases, new scenarios with partial repetition and
mixing of tasks are proposed, where the repetition patterns are innate to the
scenario and unknown to the strategy. We investigate how exemplar-free
incremental learning strategies are affected by data repetition, and we adapt a
series of state-of-the-art approaches to analyse and fairly compare them under
both settings. Further, we also propose a novel method (Horde), able to
dynamically adjust an ensemble of self-reliant feature extractors, and align
them by exploiting class repetition. Our proposed exemplar-free method achieves
competitive results in the classic scenario without repetition, and
state-of-the-art performance in the one with repetition.

28 Aug 2025
Algorithmic decision-support systems, i.e., recommender systems, are popular digital tools that help tourists decide which places and attractions to explore. However, algorithms often unintentionally direct tourist streams in a way that negatively affects the environment, local communities, or other stakeholders. This issue can be partly attributed to the computer science community's limited understanding of the complex relationships and trade-offs among stakeholders in the real world.
In this work, we draw on the practical findings and methods from tourism management to inform research on multistakeholder fairness in algorithmic decision-support. Leveraging a semi-systematic literature review, we synthesize literature from tourism management as well as literature from computer science. Our findings suggest that tourism management actively tries to identify the specific needs of stakeholders and utilizes qualitative, inclusive and participatory methods to study fairness from a normative and holistic research perspective. In contrast, computer science lacks sufficient understanding of the stakeholder needs and primarily considers fairness through descriptive factors, such as measureable discrimination, while heavily relying on few mathematically formalized fairness criteria that fail to capture the multidimensional nature of fairness in tourism.
With the results of this work, we aim to illustrate the shortcomings of purely algorithmic research and stress the potential and particular need for future interdisciplinary collaboration. We believe such a collaboration is a fundamental and necessary step to enhance algorithmic decision-support systems towards understanding and supporting true multistakeholder fairness in tourism.

08 May 2025
Recommender systems often rely on sub-symbolic machine learning approaches
that operate as opaque black boxes. These approaches typically fail to account
for the cognitive processes that shape user preferences and decision-making. In
this vision paper, we propose a hybrid user modeling framework based on the
cognitive architecture ACT-R that integrates symbolic and sub-symbolic
representations of human memory. Our goal is to combine ACT-R's declarative
memory, which is responsible for storing symbolic chunks along sub-symbolic
activations, with its procedural memory, which contains symbolic production
rules. This integration will help simulate how users retrieve past experiences
and apply decision-making strategies. With this approach, we aim to provide
more transparent recommendations, enable rule-based explanations, and
facilitate the modeling of cognitive biases. We argue that our approach has the
potential to inform the design of a new generation of human-centered,
psychology-informed recommender systems.

09 Jul 2025

Children are often exposed to items curated by recommendation algorithms. Yet, research seldom considers children as a user group, and when it does, it is anchored on datasets where children are underrepresented, risking overlooking their interests, favoring those of the majority, i.e., mainstream users. Recently, Ungruh et al. demonstrated that children's consumption patterns and preferences differ from those of mainstream users, resulting in inconsistent recommendation algorithm performance and behavior for this user group. These findings, however, are based on two datasets with a limited child user sample. We reproduce and replicate this study on a wider range of datasets in the movie, music, and book domains, uncovering interaction patterns and aspects of child-recommender interactions consistent across domains, as well as those specific to some user samples in the data. We also extend insights from the original study with popularity bias metrics, given the interpretation of results from the original study. With this reproduction and extension, we uncover consumption patterns and differences between age groups stemming from intrinsic differences between children and others, and those unique to specific datasets or domains.

22 Jul 2025
In recent years, various methods have been proposed to evaluate gender bias in large language models (LLMs). A key challenge lies in the transferability of bias measurement methods initially developed for the English language when applied to other languages. This work aims to contribute to this research strand by presenting five German datasets for gender bias evaluation in LLMs. The datasets are grounded in well-established concepts of gender bias and are accessible through multiple methodologies. Our findings, reported for eight multilingual LLM models, reveal unique challenges associated with gender bias in German, including the ambiguous interpretation of male occupational terms and the influence of seemingly neutral nouns on gender perception. This work contributes to the understanding of gender bias in LLMs across languages and underscores the necessity for tailored evaluation frameworks.
02 Jul 2025
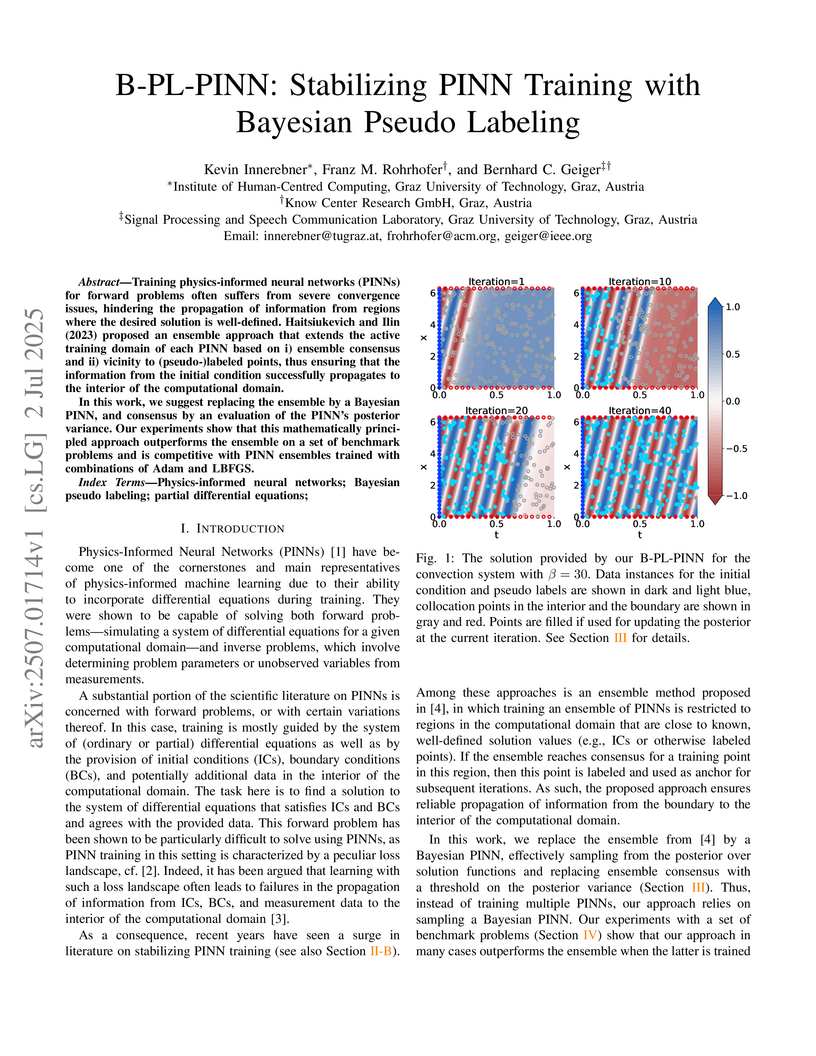
Training physics-informed neural networks (PINNs) for forward problems often suffers from severe convergence issues, hindering the propagation of information from regions where the desired solution is well-defined. Haitsiukevich and Ilin (2023) proposed an ensemble approach that extends the active training domain of each PINN based on i) ensemble consensus and ii) vicinity to (pseudo-)labeled points, thus ensuring that the information from the initial condition successfully propagates to the interior of the computational domain.
In this work, we suggest replacing the ensemble by a Bayesian PINN, and consensus by an evaluation of the PINN's posterior variance. Our experiments show that this mathematically principled approach outperforms the ensemble on a set of benchmark problems and is competitive with PINN ensembles trained with combinations of Adam and LBFGS.

28 Oct 2024
This extended abstract describes the challenges in implementing recommender systems for digital archives in the humanities, focusing on this http URL, a platform for historical legal documents. We discuss three key aspects: (i) the unique characteristics of so-called charters as items for recommendation, (ii) the complex multi-stakeholder environment, and (iii) the distinct information-seeking behavior of scholars in the humanities. By examining these factors, we aim to contribute to the development of more effective and tailored recommender systems for (digital) humanities research.

22 Apr 2025

Multistakeholder recommender systems are those that account for the impacts
and preferences of multiple groups of individuals, not just the end users
receiving recommendations. Due to their complexity, these systems cannot be
evaluated strictly by the overall utility of a single stakeholder, as is often
the case of more mainstream recommender system applications. In this article,
we focus our discussion on the challenges of multistakeholder evaluation of
recommender systems. We bring attention to the different aspects involved --
from the range of stakeholders involved (including but not limited to providers
and consumers) to the values and specific goals of each relevant stakeholder.
We discuss how to move from theoretical principles to practical implementation,
providing specific use case examples. Finally, we outline open research
directions for the RecSys community to explore. We aim to provide guidance to
researchers and practitioners about incorporating these complex and
domain-dependent issues of evaluation in the course of designing, developing,
and researching applications with multistakeholder aspects.

02 Apr 2025
In this work, we investigate causal learning of independent causal mechanisms
from a Bayesian perspective. Confirming previous claims from the literature, we
show in a didactically accessible manner that unlabeled data (i.e., cause
realizations) do not improve the estimation of the parameters defining the
mechanism. Furthermore, we observe the importance of choosing an appropriate
prior for the cause and mechanism parameters, respectively. Specifically, we
show that a factorized prior results in a factorized posterior, which resonates
with Janzing and Sch\"olkopf's definition of independent causal mechanisms via
the Kolmogorov complexity of the involved distributions and with the concept of
parameter independence of Heckerman et al.

13 May 2025
Recommender systems have become an integral part of our daily online
experience by analyzing past user behavior to suggest relevant content in
entertainment domains such as music, movies, and books. Today, they are among
the most widely used applications of AI and machine learning. Consequently,
regulations and guidelines for trustworthy AI, such as the European AI Act,
which addresses issues like bias and fairness, are highly relevant to the
design, development, and evaluation of recommender systems. One particularly
important type of bias in this context is popularity bias, which results in the
unfair underrepresentation of less popular content in recommendation lists.
This work summarizes our research on investigating the amplification of
popularity bias in recommender systems within the entertainment sector.
Analyzing datasets from three entertainment domains, music, movies, and anime,
we demonstrate that an item's recommendation frequency is positively correlated
with its popularity. As a result, user groups with little interest in popular
content receive less accurate recommendations compared to those who prefer
widely popular items. Furthermore, this work contributes to a better
understanding of the connection between recommendation accuracy, calibration
quality of algorithms, and popularity bias amplification.

26 Sep 2024
Recommender systems remain underutilized in humanities and historical research, despite their potential to enhance the discovery of cultural records. This paper offers an initial value identification of the multiple stakeholders that might be impacted by recommendations in this http URL, a digital archive for historical legal documents. Specifically, we discuss the diverse values and objectives of its stakeholders, such as editors, aggregators, platform owners, researchers, publishers, and funding agencies. These in-depth insights into the potentially conflicting values of stakeholder groups allow designing and adapting recommender systems to enhance their usefulness for humanities and historical research. Additionally, our findings will support deeper engagement with additional stakeholders to refine value models and evaluation metrics for recommender systems in the given domains. Our conclusions are embedded in and applicable to other digital archives and a broader cultural heritage context.

24 Jul 2025
Optical Music Recognition (OMR) for historical Chinese musical notations, such as suzipu and lülüpu, presents unique challenges due to high class imbalance and limited training data. This paper introduces significant advancements in OMR for Jiang Kui's influential collection Baishidaoren Gequ from 1202. In this work, we develop and evaluate a character recognition model for scarce imbalanced data. We improve upon previous baselines by reducing the Character Error Rate (CER) from 10.4% to 7.1% for suzipu, despite working with 77 highly imbalanced classes, and achieve a remarkable CER of 0.9% for lülüpu. Our models outperform human transcribers, with an average human CER of 15.9% and a best-case CER of 7.6%. We employ temperature scaling to achieve a well-calibrated model with an Expected Calibration Error (ECE) below 0.0162. Using a leave-one-edition-out cross-validation approach, we ensure robust performance across five historical editions. Additionally, we extend the KuiSCIMA dataset to include all 109 pieces from Baishidaoren Gequ, encompassing suzipu, lülüpu, and jianzipu notations. Our findings advance the digitization and accessibility of historical Chinese music, promoting cultural diversity in OMR and expanding its applicability to underrepresented music traditions.
There are no more papers matching your filters at the moment.
