 Leiden University
Leiden University
31 Aug 2025




This survey paper defines and systematically reviews the emerging paradigm of self-evolving AI agents, which bridge static foundation models with dynamic lifelong adaptability. It introduces a unified conceptual framework and a comprehensive taxonomy of evolution techniques, mapping the progression towards continuous self-improvement in AI systems.

02 Jun 2024
Galaxy cluster gas temperatures () play a crucial role in many
cosmological and astrophysical studies. However, it has been shown that
measurements can vary between different X-ray telescopes. These biases can
propagate to several cluster applications for which can be used. Thus, it
is important to accurately cross-calibrate X-ray instruments to account for
systematic biases. In this work, we present the cross-calibration between
SRG/eROSITA and Chandra/ACIS, and between SRG/eROSITA and XMM-Newton/EPIC,
using for the first time a large sample of galaxy cluster . To do so, we use
the first eROSITA All-Sky Survey data and a large X-ray flux-limited cluster
catalog. We measure X-ray for 186 independent cluster regions with both
SRG/eROSITA and Chandra/ACIS in a self-consistent way, for three energy bands;
0.7-7 keV (full), 0.5-4 keV (soft), and 1.5-7 keV (hard). We do the same with
SRG/eROSITA and XMM-Newton/EPIC for 71 different cluster regions and all three
bands. We find that SRG/eROSITA measures systematically lower than the
other two instruments. For the full band, SRG/eROSITA returns 20 and 14
lower than Chandra/ACIS and XMM-Newton/EPIC respectively, when the two
latter instruments measure keV each. The discrepancy
increases to 38\% and 32\% when Chandra/ACIS and XMM-Newton/EPIC measure
keV respectively. For low- galaxy groups, the
discrepancy becomes milder. The soft band shows a marginally lower discrepancy
than the full band. In the hard band, the cross-calibration of SRG/eROSITA and
the other instruments show stronger differences. We could not identify any
possible systematic biases that significantly alleviated the tension. Finally,
we provide conversion factors between SRG/eROSITA, Chandra/ACIS, and
XMM-Newton/EPIC which will be beneficial for future cluster studies.

27 Sep 2024

As the closest galaxy cluster, the Virgo Cluster is an exemplary environment for the study of the large-scale filamentary structure and physical effects that are present in cluster outskirts but absent from the more easily studied inner regions. Here, we present an analysis of the SRG/eROSITA data from five all-sky surveys. eROSITA allows us to resolve the entire Virgo cluster and its outskirts on scales between 1 kpc and 3 Mpc, covering a total area on the sky of about 25 by 25. We utilized image manipulation techniques and surface brightness profiles to search for extended emission, surface brightness edges, and features in the outskirts. We employed a method of comparing mean and median profiles to measure gas clumping out to and beyond the virial radius. Surface brightness analysis of the cluster and individual sectors of the cluster reveal the full extent of previously identified cold fronts to the north and south. The emissivity bias due to gas clumping, which we quantify over three orders of magnitude in the radial range, is found to be mild, consistent with previous findings. We find uniform clumping measurements in all directions, with no enhancements along candidate filaments. We find an estimated virial gas mass of $M_{\mathrm{gas},r

22 Nov 2025

This paper offers a comprehensive survey of agentic Large Language Models (LLMs), defining them by their capacities to reason, act, and interact, and proposes a future research agenda. It outlines how these models address key limitations of traditional LLMs and details a "virtuous cycle" for continuous self-improvement through generated empirical data.

05 Aug 2025




Recent studies have claimed the detection of an active massive black hole (BH) in the low-metallicity blue compact dwarf galaxy SBS 0335-052 E based on near-infrared (NIR) time variability and broad H wings. This interpretation remains questionable given the observed broad wings in forbidden [O III] emission. Based on spectroscopic properties derived from our KCWI/KCRM integral-field observation of super star clusters 1 and 2 (SSCs 12), we propose instead that these BH signatures originate from a luminous blue variable (LBV) outburst in a binary system like Carinae. First, the [Fe II] emission-line ratio and detected O I 8446 pumped emission require high-density gas ( ). This dense gas resides in the circumstellar medium (CSM) formed by pre-outburst stellar winds. Subsequent shock interaction between the LBV outburst ejecta and CSM efficiently produces warm dust and the corresponding NIR excess. Second, SSCs 12 are nitrogen-enriched relative to other SSCs. This enrichment arises from ejections of CNO-cycled material by multiple LBV outbursts. Third, we detect asymmetric broad H wings extending from to . This asymmetry results from electron scattering in the expanding, optically thick CSM. The proposed CSM shock interaction naturally explains the luminosities of [Fe V] and ultra-luminous X-ray emission. Contrarily, [Fe II] and [Fe IV] emission originates primarily from gas photoionized by the cool primary LBV and hot secondary stars, respectively. Our results highlight how the shock interaction of massive stars with high-density CSM mimics active massive BH signatures in low-metallicity dwarf galaxies.

06 Oct 2025
Large language models are rapidly transforming social science research by enabling the automation of labor-intensive tasks like data annotation and text analysis. However, LLM outputs vary significantly depending on the implementation choices made by researchers (e.g., model selection or prompting strategy). Such variation can introduce systematic biases and random errors, which propagate to downstream analyses and cause Type I (false positive), Type II (false negative), Type S (wrong sign), or Type M (exaggerated effect) errors. We call this phenomenon where configuration choices lead to incorrect conclusions LLM hacking.
We find that intentional LLM hacking is strikingly simple. By replicating 37 data annotation tasks from 21 published social science studies, we show that, with just a handful of prompt paraphrases, virtually anything can be presented as statistically significant.
Beyond intentional manipulation, our analysis of 13 million labels from 18 different LLMs across 2361 realistic hypotheses shows that there is also a high risk of accidental LLM hacking, even when following standard research practices. We find incorrect conclusions in approximately 31% of hypotheses for state-of-the-art LLMs, and in half the hypotheses for smaller language models. While higher task performance and stronger general model capabilities reduce LLM hacking risk, even highly accurate models remain susceptible. The risk of LLM hacking decreases as effect sizes increase, indicating the need for more rigorous verification of LLM-based findings near significance thresholds. We analyze 21 mitigation techniques and find that human annotations provide crucial protection against false positives. Common regression estimator correction techniques can restore valid inference but trade off Type I vs. Type II errors.
We publish a list of practical recommendations to prevent LLM hacking.
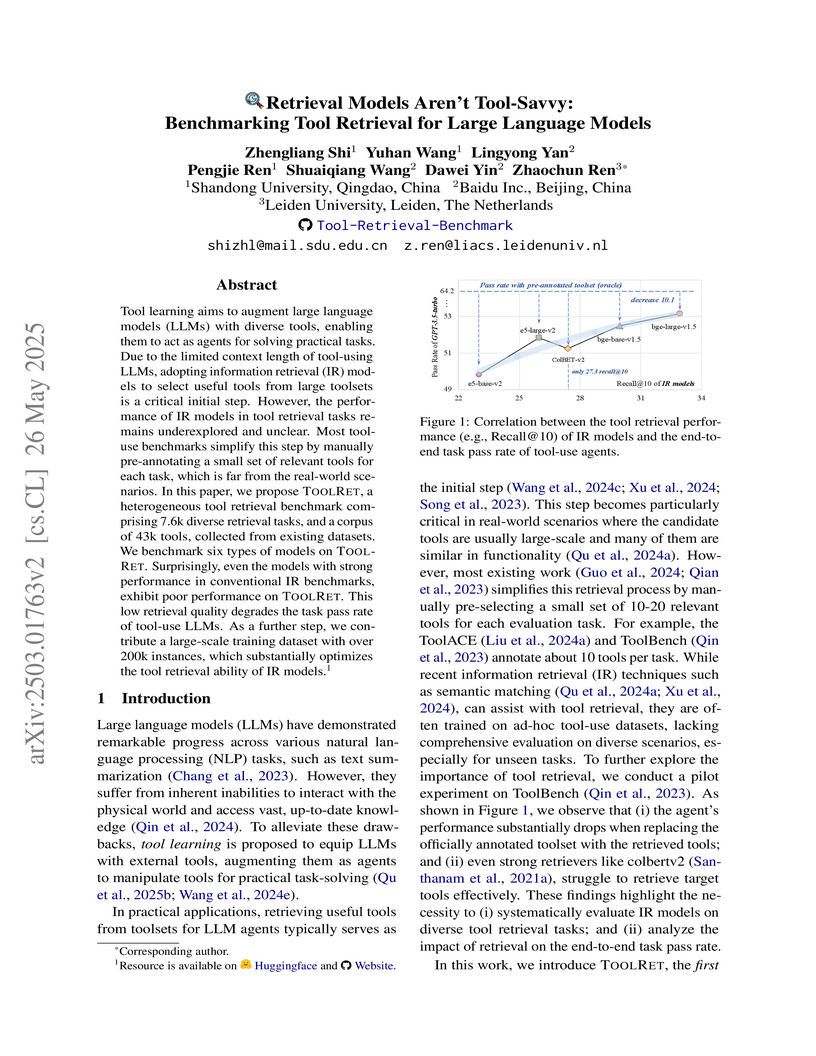
26 May 2025


A new benchmark and training dataset, TOOLRET, is introduced to evaluate information retrieval models for selecting tools for large language models. The work demonstrates that while existing retrieval models perform poorly on this task, training them on the TOOLRET dataset significantly improves their performance and the end-to-end task success of tool-augmented LLMs.

26 May 2025

The EXSEARCH framework trains large language models to function as agentic searchers by iteratively performing thinking, search, and recording actions, guided by a self-incentivized Generalized Expectation-Maximization algorithm. This approach, developed by researchers from Baidu, Leiden University, University of Amsterdam, and Shandong University, enables LLMs to dynamically retrieve and extract information, yielding up to +7.55% average F1 score improvement over direct reasoning LLMs and outperforming advanced RAG baselines on knowledge-intensive benchmarks.

29 Nov 2025

Training high-performing Small Language Models (SLMs) remains costly, even with knowledge distillation and pruning from larger teacher models. Existing work often faces three key challenges: (1) information loss from hard pruning, (2) inefficient alignment of representations, and (3) underutilization of informative activations, particularly from Feed-Forward Networks (FFNs). To address these challenges, we introduce Low-Rank Clone (LRC), an efficient pre-training method that constructs SLMs aspiring to behavioral equivalence with strong teacher models. LRC trains a set of low-rank projection matrices that jointly enable soft pruning by compressing teacher weights, and activation clone by aligning student activations, including FFN signals, with those of the teacher. This unified design maximizes knowledge transfer while removing the need for explicit alignment modules. Extensive experiments with open-source teachers (e.g., Llama-3.2-3B-Instruct, Qwen2.5-3B/7B-Instruct) show that LRC matches or surpasses state-of-the-art models trained on trillions of tokens--while using only 20B tokens, achieving over 1,000x training efficiency. Our codes and model checkpoints are available at this https URL and this https URL.

04 Mar 2025

Researchers at Shandong University, Leiden University, and Baidu Inc. developed AutoTools, a framework that enables Large Language Models to automatically encapsulate raw tool documentation into callable functions and programmatically integrate them to solve complex tasks. The framework, along with a multi-task learning approach for open-source models, achieved a 15.51 percentage point improvement in success rate on a challenging new benchmark that emphasizes long-term planning and inter-tool dependencies.

12 Oct 2025

Generative retrieval (GR) reformulates information retrieval (IR) by framing it as the generation of document identifiers (docids), thereby enabling an end-to-end optimization and seamless integration with generative language models (LMs). Despite notable progress under supervised training, GR still struggles to generalize to zero-shot IR scenarios, which are prevalent in real-world applications. To tackle this challenge, we propose \textsc{ZeroGR}, a zero-shot generative retrieval framework that leverages natural language instructions to extend GR across a wide range of IR tasks. Specifically, \textsc{ZeroGR} is composed of three key components: (i) an LM-based docid generator that unifies heterogeneous documents (e.g., text, tables, code) into semantically meaningful docids; (ii) an instruction-tuned query generator that generates diverse types of queries from natural language task descriptions to enhance corpus indexing; and (iii) a reverse annealing decoding strategy to balance precision and recall during docid generation. We investigate the impact of instruction fine-tuning scale and find that performance consistently improves as the number of IR tasks encountered during training increases. Empirical results on the BEIR and MAIR benchmarks demonstrate that \textsc{ZeroGR} outperforms strong dense retrieval and generative baselines in zero-shot settings, establishing a new state-of-the-art for instruction-driven GR.

25 May 2025
This work from Baidu Inc. and collaborating universities introduces DTA-Llama, an efficient tool learning method for Large Language Models that utilizes a "Divide-Then-Aggregate" paradigm for parallel tool invocation. It achieved a 66.1% Solvable Pass Rate and 59.1% Solvable Win Rate on StableToolBench using a Llama2-7B model, outperforming other open-source methods and demonstrating reduced inference steps and token consumption compared to prior approaches.

09 Oct 2025





We present JWST observations of the environments surrounding two high-redshift quasars -- J02520503 at and J10072115 at -- which enable the first constraints on quasar-galaxy clustering at . Galaxies in the vicinity of the quasars are selected through ground-based and JWST/NIRCam imaging and then spectroscopically confirmed with JWST/NIRSpec using the multi-shutter assembly (MSA). Over both fields, we identify 51 galaxies, of which eight are found within a line-of-sight velocity window from the quasars and another eight in the background. The galaxy J0252\_8713, located just and from quasar J02520503, emerges as a compelling candidate for one of the most distant quasar-galaxy mergers. Combining the galaxy discoveries over the two fields, we measure the quasar-galaxy cross-correlation and obtain a correlation length of , based on a power-law model with a fixed slope of . Under the assumption that quasars and galaxies trace the same underlying dark matter density fluctuations, we infer a minimum dark matter halo mass for quasars of in a halo model framework. Compared to measurements from EIGER at and ASPIRE at (where ), our clustering results provide tentative evidence for a non-monotonic redshift evolution of quasar clustering properties. We further estimate a quasar duty cycle of , consistent with constraints from quasar proximity zones and IGM damping wings. (abridged)

02 Nov 2025
This survey from Leiden University introduces a novel 'generate-evaluate-control' taxonomy to organize the rapidly expanding field of multi-step reasoning with Large Language Models. It consolidates diverse approaches, highlights key advancements from Chain-of-Thought prompting to integrated search algorithms, and outlines a research agenda for future development.

22 Jun 2024
The ConAgents framework enhances Large Language Models' (LLMs) ability to use external tools by employing a cooperative and interactive multi-agent system. This approach achieves up to 14% higher success rates on tool-use benchmarks compared to single-agent methods and effectively enables specialized tool-use capabilities in open-source LLMs through distillation.

30 Oct 2019
The Leiden algorithm, developed by researchers at Leiden University, corrects a critical flaw in the widely used Louvain algorithm by guaranteeing that detected communities are well-connected, while also achieving faster computation and higher quality partitions across various networks. This advancement ensures more structurally sound and interpretable community structures in complex systems.

24 Mar 2025

This article presents experiments performed using a computational laboratory
environment for language acquisition experiments. It implements a multi-agent
system consisting of two agents: an adult language model and a daughter
language model that aims to learn the mother language. Crucially, the daughter
agent does not have access to the internal knowledge of the mother language
model but only to the language exemplars the mother agent generates. These
experiments illustrate how this system can be used to acquire abstract
grammatical knowledge. We demonstrate how statistical analyses of patterns in
the input data corresponding to grammatical categories yield discrete
grammatical rules. These rules are subsequently added to the grammatical
knowledge of the daughter language model. To this end, hierarchical
agglomerative cluster analysis was applied to the utterances consecutively
generated by the mother language model. It is argued that this procedure can be
used to acquire structures resembling grammatical categories proposed by
linguists for natural languages. Thus, it is established that non-trivial
grammatical knowledge has been acquired. Moreover, the parameter configuration
of this computational laboratory environment determined using training data
generated by the mother language model is validated in a second experiment with
a test set similarly resulting in the acquisition of non-trivial categories.

31 Mar 2022
This survey provides a comprehensive and systematic review of Model-based Reinforcement Learning (MBRL), establishing a unified definition and a detailed taxonomy that categorizes diverse methodologies from classical approaches to modern deep learning integrations. It clarifies core concepts, identifies key challenges, and outlines future research directions, serving as a foundational resource for the field.

01 Oct 2025

Large language models (LLMs) are increasingly entrusted with high-stakes decisions that affect human welfare. However, the principles and values that guide these models when distributing scarce societal resources remain largely unexamined. To address this, we introduce the Social Welfare Function (SWF) Benchmark, a dynamic simulation environment where an LLM acts as a sovereign allocator, distributing tasks to a heterogeneous community of recipients. The benchmark is designed to create a persistent trade-off between maximizing collective efficiency (measured by Return on Investment) and ensuring distributive fairness (measured by the Gini coefficient). We evaluate 20 state-of-the-art LLMs and present the first leaderboard for social welfare allocation. Our findings reveal three key insights: (i) A model's general conversational ability, as measured by popular leaderboards, is a poor predictor of its allocation skill. (ii) Most LLMs exhibit a strong default utilitarian orientation, prioritizing group productivity at the expense of severe inequality. (iii) Allocation strategies are highly vulnerable, easily perturbed by output-length constraints and social-influence framing. These results highlight the risks of deploying current LLMs as societal decision-makers and underscore the need for specialized benchmarks and targeted alignment for AI governance.

27 May 2025
Leiden University researchers develop LLaMEA-BO, the first framework to automatically generate complete Bayesian Optimization algorithms using large language models guided by evolutionary strategies, where generated algorithms like ATRBO and TREvol consistently match or outperform state-of-the-art baselines (CMA-ES, HEBO, TuRBO1) on BBOB test functions across dimensions 5-40 while demonstrating strong generalization to real-world hyperparameter tuning tasks, establishing LLMs as capable algorithmic co-designers that can autonomously evolve functional Python implementations including initial design, surrogate modeling, and acquisition functions through a closed-loop generate-evaluate-improve process.
There are no more papers matching your filters at the moment.
