
03 Jun 2025

Classifier-free guidance (CFG) is crucial for improving both generation
quality and alignment between the input condition and final output in diffusion
models. While a high guidance scale is generally required to enhance these
aspects, it also causes oversaturation and unrealistic artifacts. In this
paper, we revisit the CFG update rule and introduce modifications to address
this issue. We first decompose the update term in CFG into parallel and
orthogonal components with respect to the conditional model prediction and
observe that the parallel component primarily causes oversaturation, while the
orthogonal component enhances image quality. Accordingly, we propose
down-weighting the parallel component to achieve high-quality generations
without oversaturation. Additionally, we draw a connection between CFG and
gradient ascent and introduce a new rescaling and momentum method for the CFG
update rule based on this insight. Our approach, termed adaptive projected
guidance (APG), retains the quality-boosting advantages of CFG while enabling
the use of higher guidance scales without oversaturation. APG is easy to
implement and introduces practically no additional computational overhead to
the sampling process. Through extensive experiments, we demonstrate that APG is
compatible with various conditional diffusion models and samplers, leading to
improved FID, recall, and saturation scores while maintaining precision
comparable to CFG, making our method a superior plug-and-play alternative to
standard classifier-free guidance.

22 Jul 2025
Human motion generation and editing are key components of computer vision. However, current approaches in this field tend to offer isolated solutions tailored to specific tasks, which can be inefficient and impractical for real-world applications. While some efforts have aimed to unify motion-related tasks, these methods simply use different modalities as conditions to guide motion generation. Consequently, they lack editing capabilities, fine-grained control, and fail to facilitate knowledge sharing across tasks. To address these limitations and provide a versatile, unified framework capable of handling both human motion generation and editing, we introduce a novel paradigm: \textbf{Motion-Condition-Motion}, which enables the unified formulation of diverse tasks with three concepts: source motion, condition, and target motion. Based on this paradigm, we propose a unified framework, \textbf{MotionLab}, which incorporates rectified flows to learn the mapping from source motion to target motion, guided by the specified conditions. In MotionLab, we introduce the 1) MotionFlow Transformer to enhance conditional generation and editing without task-specific modules; 2) Aligned Rotational Position Encoding to guarantee the time synchronization between source motion and target motion; 3) Task Specified Instruction Modulation; and 4) Motion Curriculum Learning for effective multi-task learning and knowledge sharing across tasks. Notably, our MotionLab demonstrates promising generalization capabilities and inference efficiency across multiple benchmarks for human motion. Our code and additional video results are available at: this https URL.

13 May 2024
Researchers from ETH Zurich and DisneyResearch|Studios introduce CADS, an inference-time sampling strategy that enhances the output diversity of conditional diffusion models while preserving generation quality. This method achieves new state-of-the-art FID scores for class-conditional ImageNet generation, reaching 1.70 at 256x256 and 2.31 at 512x512 resolutions, solely through an improved sampling approach.

03 Jun 2025
Researchers from ETH Zürich and DisneyResearch|Studios introduce Independent Condition Guidance (ICG) and Time-Step Guidance (TSG) to address practical limitations of Classifier-Free Guidance in diffusion models. ICG enables CFG benefits for pre-trained conditional models without auxiliary training overhead, and TSG extends quality-boosting guidance to any diffusion model, including unconditional ones.

06 Nov 2024
By training over large-scale datasets, zero-shot monocular depth estimation (MDE) methods show robust performance in the wild but often suffer from insufficient detail. Although recent diffusion-based MDE approaches exhibit a superior ability to extract details, they struggle in geometrically complex scenes that challenge their geometry prior, trained on less diverse 3D data. To leverage the complementary merits of both worlds, we propose BetterDepth to achieve geometrically correct affine-invariant MDE while capturing fine details. Specifically, BetterDepth is a conditional diffusion-based refiner that takes the prediction from pre-trained MDE models as depth conditioning, in which the global depth layout is well-captured, and iteratively refines details based on the input image. For the training of such a refiner, we propose global pre-alignment and local patch masking methods to ensure BetterDepth remains faithful to the depth conditioning while learning to add fine-grained scene details. With efficient training on small-scale synthetic datasets, BetterDepth achieves state-of-the-art zero-shot MDE performance on diverse public datasets and on in-the-wild scenes. Moreover, BetterDepth can improve the performance of other MDE models in a plug-and-play manner without further re-training.

16 Sep 2025


Existing single-view 3D generative models typically adopt multiview diffusion priors to reconstruct object surfaces, yet they remain prone to inter-view inconsistencies and are unable to faithfully represent complex internal structure or nontrivial topologies. In particular, we encode geometry information by projecting it onto a bounding sphere and unwrapping it into a compact and structural multi-layer 2D Spherical Projection (SP) representation. Operating solely in the image domain, SPGen offers three key advantages simultaneously: (1) Consistency. The injective SP mapping encodes surface geometry with a single viewpoint which naturally eliminates view inconsistency and ambiguity; (2) Flexibility. Multi-layer SP maps represent nested internal structures and support direct lifting to watertight or open 3D surfaces; (3) Efficiency. The image-domain formulation allows the direct inheritance of powerful 2D diffusion priors and enables efficient finetuning with limited computational resources. Extensive experiments demonstrate that SPGen significantly outperforms existing baselines in geometric quality and computational efficiency.

01 Dec 2025


Despite major advances brought by diffusion-based models, current 3D texture generation systems remain hindered by cross-view inconsistency -- textures that appear convincing from one viewpoint often fail to align across others. We find that this issue arises from attention ambiguity, where unstructured full attention is applied indiscriminately across tokens and modalities, causing geometric confusion and unstable appearance-structure coupling. To address this, we introduce CaliTex, a framework of geometry-calibrated attention that explicitly aligns attention with 3D structure. It introduces two modules: Part-Aligned Attention that enforces spatial alignment across semantically matched parts, and Condition-Routed Attention which routes appearance information through geometry-conditioned pathways to maintain spatial fidelity. Coupled with a two-stage diffusion transformer, CaliTex makes geometric coherence an inherent behavior of the network rather than a byproduct of optimization. Empirically, CaliTex produces seamless and view-consistent textures and outperforms both open-source and commercial baselines.
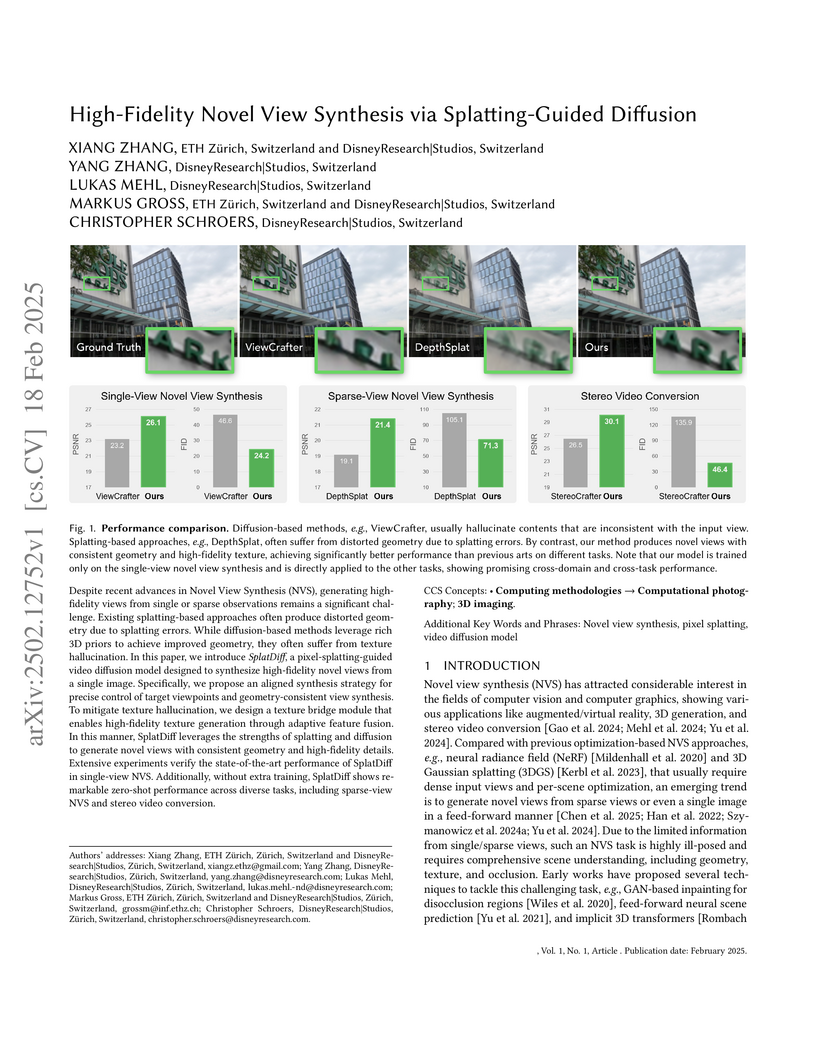
18 Feb 2025
ETH Zürich and DisneyResearch|Studios researchers introduce SplatDiff, a groundbreaking framework that combines splatting-based and diffusion approaches for novel view synthesis, achieving superior fidelity through clever integration of texture preservation mechanisms while enabling high-quality view generation from single images.

21 Jan 2025
LiteVAE, developed by researchers at ETH Zürich and DisneyResearch|Studios, is an efficient Variational Autoencoder designed for Latent Diffusion Models that uses a wavelet-based architecture to reduce encoder parameters by a factor of six and nearly double throughput. This approach maintains or improves reconstruction quality compared to standard VAEs, enhancing the scalability of high-resolution generative AI.

09 May 2025

The motion planning problem involves finding a collision-free path from a
robot's starting to its target configuration. Recently, self-supervised
learning methods have emerged to tackle motion planning problems without
requiring expensive expert demonstrations. They solve the Eikonal equation for
training neural networks and lead to efficient solutions. However, these
methods struggle in complex environments because they fail to maintain key
properties of the Eikonal equation, such as optimal value functions and
geodesic distances. To overcome these limitations, we propose a novel
self-supervised temporal difference metric learning approach that solves the
Eikonal equation more accurately and enhances performance in solving complex
and unseen planning tasks. Our method enforces Bellman's principle of
optimality over finite regions, using temporal difference learning to avoid
spurious local minima while incorporating metric learning to preserve the
Eikonal equation's essential geodesic properties. We demonstrate that our
approach significantly outperforms existing self-supervised learning methods in
handling complex environments and generalizing to unseen environments, with
robot configurations ranging from 2 to 12 degrees of freedom (DOF).

25 Nov 2024
A new mesh reduction method extends Quadric Error Metrics to simplify quad-dominant 3D models while preserving their quad structure and animation characteristics. The approach maintains geometric accuracy and preserves approximately twice as many quads as traditional methods at 75% vertex reduction.

13 Oct 2025

Selecting high-quality and diverse training samples from extensive datasets plays a crucial role in reducing training overhead and enhancing the performance of Large Language Models (LLMs). However, existing studies fall short in assessing the overall value of selected data, focusing primarily on individual quality, and struggle to strike an effective balance between ensuring diversity and minimizing data point traversals. Therefore, this paper introduces a novel choice-based sample selection framework that shifts the focus from evaluating individual sample quality to comparing the contribution value of different samples when incorporated into the subset. Thanks to the advanced language understanding capabilities of LLMs, we utilize LLMs to evaluate the value of each option during the selection process. Furthermore, we design a greedy sampling process where samples are incrementally added to the subset, thereby improving efficiency by eliminating the need for exhaustive traversal of the entire dataset with the limited budget. Extensive experiments demonstrate that selected data from our method not only surpasses the performance of the full dataset but also achieves competitive results with recent powerful studies, while requiring fewer selections. Moreover, we validate our approach on a larger medical dataset, highlighting its practical applicability in real-world applications. Our code and data are available at this https URL.

30 May 2024

In this paper, we examine 3 important issues in the practical use of
state-of-the-art facial landmark detectors and show how a combination of
specific architectural modifications can directly improve their accuracy and
temporal stability. First, many facial landmark detectors require face
normalization as a preprocessing step, which is accomplished by a
separately-trained neural network that crops and resizes the face in the input
image. There is no guarantee that this pre-trained network performs the optimal
face normalization for landmark detection. We instead analyze the use of a
spatial transformer network that is trained alongside the landmark detector in
an unsupervised manner, and jointly learn optimal face normalization and
landmark detection. Second, we show that modifying the output head of the
landmark predictor to infer landmarks in a canonical 3D space can further
improve accuracy. To convert the predicted 3D landmarks into screen-space, we
additionally predict the camera intrinsics and head pose from the input image.
As a side benefit, this allows to predict the 3D face shape from a given image
only using 2D landmarks as supervision, which is useful in determining landmark
visibility among other things. Finally, when training a landmark detector on
multiple datasets at the same time, annotation inconsistencies across datasets
forces the network to produce a suboptimal average. We propose to add a
semantic correction network to address this issue. This additional lightweight
neural network is trained alongside the landmark detector, without requiring
any additional supervision. While the insights of this paper can be applied to
most common landmark detectors, we specifically target a recently-proposed
continuous 2D landmark detector to demonstrate how each of our additions leads
to meaningful improvements over the state-of-the-art on standard benchmarks.

29 Aug 2024

Tokenising continuous speech into sequences of discrete tokens and modelling them with language models (LMs) has led to significant success in text-to-speech (TTS) synthesis. Although these models can generate speech with high quality and naturalness, their synthesised samples can still suffer from artefacts, mispronunciation, word repeating, etc. In this paper, we argue these undesirable properties could partly be caused by the randomness of sampling-based strategies during the autoregressive decoding of LMs. Therefore, we look at maximisation-based decoding approaches and propose Temporal Repetition Aware Diverse Beam Search (TRAD-BS) to find the most probable sequences of the generated speech tokens. Experiments with two state-of-the-art LM-based TTS models demonstrate that our proposed maximisation-based decoding strategy generates speech with fewer mispronunciations and improved speaker consistency.

23 May 2025
Recent years have seen a tremendous improvement in the quality of video
generation and editing approaches. While several techniques focus on editing
appearance, few address motion. Current approaches using text, trajectories, or
bounding boxes are limited to simple motions, so we specify motions with a
single motion reference video instead. We further propose to use a pre-trained
image-to-video model rather than a text-to-video model. This approach allows us
to preserve the exact appearance and position of a target object or scene and
helps disentangle appearance from motion. Our method, called motion-textual
inversion, leverages our observation that image-to-video models extract
appearance mainly from the (latent) image input, while the text/image embedding
injected via cross-attention predominantly controls motion. We thus represent
motion using text/image embedding tokens. By operating on an inflated
motion-text embedding containing multiple text/image embedding tokens per
frame, we achieve a high temporal motion granularity. Once optimized on the
motion reference video, this embedding can be applied to various target images
to generate videos with semantically similar motions. Our approach does not
require spatial alignment between the motion reference video and target image,
generalizes across various domains, and can be applied to various tasks such as
full-body and face reenactment, as well as controlling the motion of inanimate
objects and the camera. We empirically demonstrate the effectiveness of our
method in the semantic video motion transfer task, significantly outperforming
existing methods in this context.
Project website: this https URL

17 Dec 2024
Gaussian Billboards enhances 2D Gaussian Splatting (2DGS) by introducing per-primitive texture mapping, moving beyond solid colors to represent spatially-varying details. This method, developed by DisneyResearch|Studios, allows for sharper and more expressive scene reconstructions, often requiring fewer primitives for a given level of detail.

01 Sep 2025
Researchers from ETH Zürich and DisneyResearch|Studios developed a monocular capture method that reconstructs high-fidelity 3D facial geometry and appearance properties (albedo, specular intensity, roughness) in unconstrained environments, enabling photorealistic relighting without prior lighting assumptions.

20 Dec 2024

We introduce a novel offset meshing approach that can robustly handle a 3D
surface mesh with an arbitrary geometry and topology configurations, while
nicely capturing the sharp features on the original input for both inward and
outward offsets. Compared to the existing approaches focusing on
constant-radius offset, to the best of our knowledge, we propose the first-ever
solution for mitered offset that can well preserve sharp features. Our method
is designed based on several core principals: 1) explicitly generating the
offset vertices and triangles with feature-capturing energy and constraints; 2)
prioritizing the generation of the offset geometry before establishing its
connectivity, 3) employing exact algorithms in critical pipeline steps for
robustness, balancing the use of floating-point computations for efficiency, 4)
applying various conservative speed up strategies including early reject
non-contributing computations to the final output. Our approach further
uniquely supports variable offset distances on input surface elements, offering
a wider range practical applications compared to conventional methods.
We have evaluated our method on a subset of Thinkgi10K, containing models
with diverse topological and geometric complexities created by practitioners in
various fields. Our results demonstrate the superiority of our approach over
current state-of-the-art methods in terms of element count, feature
preservation, and non-uniform offset distances of the resulting offset mesh
surfaces, marking a significant advancement in the field.

07 Oct 2024
We have developed a high-performance Chinese Chess AI that operates without reliance on search algorithms. This AI has demonstrated the capability to compete at a level commensurate with the top 0.1\% of human players. By eliminating the search process typically associated with such systems, this AI achieves a Queries Per Second (QPS) rate that exceeds those of systems based on the Monte Carlo Tree Search (MCTS) algorithm by over a thousandfold and surpasses those based on the AlphaBeta pruning algorithm by more than a hundredfold. The AI training system consists of two parts: supervised learning and reinforcement learning. Supervised learning provides an initial human-like Chinese chess AI, while reinforcement learning, based on supervised learning, elevates the strength of the entire AI to a new level. Based on this training system, we carried out enough ablation experiments and discovered that 1. The same parameter amount of Transformer architecture has a higher performance than CNN on Chinese chess; 2. Possible moves of both sides as features can greatly improve the training process; 3. Selective opponent pool, compared to pure self-play training, results in a faster improvement curve and a higher strength limit. 4. Value Estimation with Cutoff(VECT) improves the original PPO algorithm training process and we will give the explanation.

08 Oct 2024
Incorporating diffusion models in the image compression domain has the potential to produce realistic and detailed reconstructions, especially at extremely low bitrates. Previous methods focus on using diffusion models as expressive decoders robust to quantization errors in the conditioning signals, yet achieving competitive results in this manner requires costly training of the diffusion model and long inference times due to the iterative generative process. In this work we formulate the removal of quantization error as a denoising task, using diffusion to recover lost information in the transmitted image latent. Our approach allows us to perform less than 10% of the full diffusion generative process and requires no architectural changes to the diffusion model, enabling the use of foundation models as a strong prior without additional fine tuning of the backbone. Our proposed codec outperforms previous methods in quantitative realism metrics, and we verify that our reconstructions are qualitatively preferred by end users, even when other methods use twice the bitrate.
There are no more papers matching your filters at the moment.
