
01 Dec 2024
Compared to p-values, e-values provably guarantee safe, valid inference. If the goal is to test multiple hypotheses simultaneously, one can construct e-values for each individual test and then use the recently developed e-BH procedure to properly correct for multiplicity. Standard e-value constructions, however, require distributional assumptions that may not be justifiable. This paper demonstrates that the generalized universal inference framework can be used along with the e-BH procedure to control frequentist error rates in multiple testing when the quantities of interest are minimizers of risk functions, thereby avoiding the need for distributional assumptions. We demonstrate the validity and power of this approach via a simulation study, testing the significance of a predictor in quantile regression.

09 Oct 2024
A common goal in statistics and machine learning is estimation of unknowns. Point estimates alone are of little value without an accompanying measure of uncertainty, but traditional uncertainty quantification methods, such as confidence sets and p-values, often require strong distributional or structural assumptions that may not be justified in modern problems. The present paper considers a very common case in machine learning, where the quantity of interest is the minimizer of a given risk (expected loss) function. For such cases, we propose a generalization of the recently developed universal inference procedure that is designed for inference on risk minimizers. Notably, our generalized universal inference attains finite-sample frequentist validity guarantees under a condition common in the statistical learning literature. One version of our procedure is also anytime-valid in the sense that it maintains the finite-sample validity properties regardless of the stopping rule used for the data collection process, thereby providing a link between safe inference and fast convergence rates in statistical learning. Practical use of our proposal requires tuning, and we offer a data-driven procedure with strong empirical performance across a broad range of challenging statistical and machine learning examples.

31 Oct 2025

Researchers from Carnegie Mellon University developed PAPRIKA, a framework that fine-tunes Large Language Models using preference-based optimization and curriculum learning to imbue them with generalized strategic exploration and sequential decision-making abilities. This approach led to an average 47% increase in success rate for Llama-3.1-8B-Instruct across diverse interactive tasks and demonstrated zero-shot transfer to unseen environments without degrading base model capabilities.

08 Feb 2025






A comprehensive survey establishes a unified framework for understanding trustworthiness in Retrieval-Augmented Generation (RAG) systems for Large Language Models, systematically categorizing challenges, solutions, and evaluation across six key dimensions: Reliability, Privacy, Safety, Fairness, Explainability, and Accountability. This work provides a detailed roadmap and identifies future research directions to guide the development of more dependable RAG deployments in critical real-world applications.

09 Feb 2024
FNSPID is a comprehensive financial dataset integrating 24 years of time-aligned stock prices and financial news for 4,775 S&P500 companies, featuring LLM-derived sentiment scores and multiple summarization methods. Experiments using FNSPID showed that Transformer models achieved a 0.988 R-squared for stock prediction, with LLM-based sentiment consistently improving accuracy across various deep learning architectures.

16 Jul 2025


A comprehensive survey categorizes the evolving roles of Large Language Models in scientific innovation using a novel pyramidal framework, classifying them as Evaluators, Collaborators, or Scientists. The work details LLM capabilities in scientific knowledge synthesis, hypothesis generation, and autonomous discovery, analyzing associated benchmarks, algorithms, and ethical considerations across these roles.

26 Jun 2025


A new Text-to-Text Regression approach leverages Regression Language Models to predict performance for large industrial systems. It achieves up to a 0.99 Spearman rank correlation and 100x lower MSE compared to tabular methods on Google's Borg compute cluster by processing raw textual system data.

20 Oct 2025



Text-Attributed Graphs (TAGs), where each node is associated with text descriptions, are ubiquitous in real-world scenarios. They typically exhibit distinctive structure and domain-specific knowledge, motivating the development of a Graph Foundation Model (GFM) that generalizes across diverse graphs and tasks. Despite large efforts to integrate Large Language Models (LLMs) and Graph Neural Networks (GNNs) for TAGs, existing approaches suffer from decoupled architectures with two-stage alignment, limiting their synergistic potential. Even worse, existing methods assign out-of-vocabulary (OOV) tokens to graph nodes, leading to graph-specific semantics, token explosion, and incompatibility with task-oriented prompt templates, which hinders cross-graph and cross-task transferability. To address these challenges, we propose PromptGFM, a versatile GFM for TAGs grounded in graph vocabulary learning. PromptGFM comprises two key components: (1) Graph Understanding Module, which explicitly prompts LLMs to replicate the finest GNN workflow within the text space, facilitating seamless GNN-LLM integration and elegant graph-text alignment; (2) Graph Inference Module, which establishes a language-based graph vocabulary ensuring expressiveness, transferability, and scalability, enabling readable instructions for LLM fine-tuning. Extensive experiments demonstrate our superiority and transferability across diverse graphs and tasks. The code is available at this: this https URL.

23 May 2023


ReWOO introduces a "Plan-Work-Solve" paradigm that decouples reasoning from external observations in Augmented Language Models, leading to a 64% average reduction in token consumption and up to 5x token efficiency while maintaining or improving task accuracy. This approach also demonstrates the feasibility of offloading complex reasoning capabilities from large language models to smaller, specialized models.

20 Nov 2025
Peer review serves as the gatekeeper of science, yet the surge in submissions and widespread adoption of large language models (LLMs) in scholarly evaluation present unprecedented challenges. While recent work has focused on using LLMs to improve review efficiency, unchecked deficient reviews from both human experts and AI systems threaten to systematically undermine academic integrity. To address this issue, we introduce ReviewGuard, an automated system for detecting and categorizing deficient reviews through a four-stage LLM-driven framework: data collection from ICLR and NeurIPS on OpenReview, GPT-4.1 annotation with human validation, synthetic data augmentation yielding 6,634 papers with 24,657 real and 46,438 synthetic reviews, and fine-tuning of encoder-based models and open-source LLMs. Feature analysis reveals that deficient reviews exhibit lower rating scores, higher self-reported confidence, reduced structural complexity, and more negative sentiment than sufficient reviews. AI-generated text detection shows dramatic increases in AI-authored reviews since ChatGPT's emergence. Mixed training with synthetic and real data substantially improves detection performance - for example, Qwen 3-8B achieves recall of 0.6653 and F1 of 0.7073, up from 0.5499 and 0.5606 respectively. This study presents the first LLM-driven system for detecting deficient peer reviews, providing evidence to inform AI governance in peer review. Code, prompts, and data are available at this https URL

17 Sep 2025
Hybrid quantum-high performance computing (Q-HPC) workflows are emerging as a key strategy for running quantum applications at scale in current noisy intermediate-scale quantum (NISQ) devices. These workflows must operate seamlessly across diverse simulators and hardware backends since no single simulator offers the best performance for every circuit type. Simulation efficiency depends strongly on circuit structure, entanglement, and depth, making a flexible and backend-agnostic execution model essential for fair benchmarking, informed platform selection, and ultimately the identification of quantum advantage opportunities. In this work, we extend the Quantum Framework (QFw), a modular and HPC-aware orchestration layer, to integrate multiple local backends (Qiskit Aer, NWQ-Sim, QTensor, and TN-QVM) and a cloud-based quantum backend (IonQ) under a unified interface. Using this integration, we execute a number of non-variational as well as variational workloads. The results highlight workload-specific backend advantages: while Qiskit Aer's matrix product state excels for large Ising models, NWQ-Sim not only leads on large-scale entanglement and Hamiltonian but also shows the benefits of concurrent subproblem execution in a distributed manner for optimization problems. These findings demonstrate that simulator-agnostic, HPC-aware orchestration is a practical path toward scalable, reproducible, and portable Q-HPC ecosystems, thereby accelerating progress toward demonstrating quantum advantage.

30 May 2025
Researchers at North Carolina State University introduced a method that integrates explicit safety signals into Large Language Models (LLMs) via a dedicated classification token and strategic decoding. This approach achieved significantly lower Attack Success Rates (ASR) against various adversarial attacks, such as reducing Prefill attack ASR from 92.7% to 0.4% in Llama2-7B-CLS, with less than 0.2x inference overhead while also providing interpretable refusal justifications.

11 Feb 2024


This research introduces PirateNets, a novel neural network architecture enabling the stable and efficient training of deep physics-informed models. The approach addresses the performance degradation observed in deep Physics-Informed Neural Networks by employing adaptive residual connections and a unique physics-informed initialization, achieving state-of-the-art accuracy across various partial differential equation benchmarks.

13 Nov 2025
This work from North Carolina State University identifies that Layer Normalization (LN) serves distinct roles in Transformer architectures: it is essential for learning stability in Pre-LayerNorm models, while facilitating memorization in Post-LayerNorm models. Removing LN's learnable parameters in Post-LN models effectively mitigates memorization and improves true label recovery without disrupting generalization.

01 Nov 2024
In recent years, there has been a growing trend of applying Reinforcement Learning (RL) in financial applications.
This approach has shown great potential to solve decision-making tasks in finance.
In this survey, we present a comprehensive study of the applications of RL in finance and conduct a series of meta-analyses to investigate the common themes in the literature, such as the factors that most significantly affect RL's performance compared to traditional methods.
Moreover, we identify challenges including explainability, Markov Decision Process (MDP) modeling, and robustness that hinder the broader utilization of RL in the financial industry and discuss recent advancements in overcoming these challenges.
Finally, we propose future research directions, such as benchmarking, contextual RL, multi-agent RL, and model-based RL to address these challenges and to further enhance the implementation of RL in finance.

02 Feb 2023
A research team from North Carolina State University developed an unsupervised physics-informed machine learning algorithm to solve two-dimensional quantum eigenvalue problems for diverse potential well geometries. The method accurately computes energy eigenvalues and visualizes eigenfunctions for both classically integrable and chaotic systems, including rectangles, ellipses, triangles, and cardioids, with low relative errors.

22 Oct 2025
 CNRS
CNRS Chinese Academy of Sciences
Chinese Academy of Sciences the University of TokyoUniversität Heidelberg
the University of TokyoUniversität Heidelberg Arizona State UniversityNational Astronomical ObservatoriesMax-Planck-Institut für AstrophysikNorth Carolina State UniversityAix-Marseille UnivUniversidad de ChileSwinburne University of Technology
Arizona State UniversityNational Astronomical ObservatoriesMax-Planck-Institut für AstrophysikNorth Carolina State UniversityAix-Marseille UnivUniversidad de ChileSwinburne University of Technology European Southern ObservatoryCNESNew Mexico State UniversityARC Centre of Excellence for All Sky Astrophysics in 3 Dimensions (ASTRO 3D)Universität PotsdamARC Centre of Excellence for All Sky Astrophysics in 3 DimensionsKavli IPMU (WPI)Aix-Marseille Universit",
European Southern ObservatoryCNESNew Mexico State UniversityARC Centre of Excellence for All Sky Astrophysics in 3 Dimensions (ASTRO 3D)Universität PotsdamARC Centre of Excellence for All Sky Astrophysics in 3 DimensionsKavli IPMU (WPI)Aix-Marseille Universit",We create the first large-scale mock spectroscopic survey of gas absorption sightlines traversing the interstellar medium (ISM), circumgalactic medium (CGM), and intergalactic medium (IGM) surrounding galaxies of virtual Universes. That is, we create mock, or synthetic, absorption spectra by drawing lines-of-sight through cosmological hydrodynamical simulations, using a new mesh-free Voronoi ray-tracing algorithm. The result is the Synthetic Absorption Line Spectral Almanac (SALSA), which is publicly released on a feature-rich online science platform (this http URL). It spans a range of ions, transitions, instruments, observational characteristics, assumptions, redshifts, and simulations. These include, but are not limited to: (ions) HI, OI, CI, MgI, MgII, FeII, SiII, CaII, ZnII, SiIII, SiIV, NV, CII, CIV, OVI; (instruments) SDSS-BOSS, KECK-HIRES, UVES, COS, DESI, 4MOST, WEAVE, XSHOOTER; (model choices) with/without dust depletion, noise, quasar continua, foregrounds; (redshift) from z=0 to z~6; (ancillary data) integrated equivalent widths, column densities, distances and properties of nearby galaxies; (simulations) IllustrisTNG including TNG50, TNG-Cluster, EAGLE, and SIMBA. This scope is not fixed, and will grow and evolve with community interest and requests over time -- suggestions are welcome. The resulting dataset is generic and broadly applicable, enabling diverse science goals such as: (i) studies of the underlying physical gas structures giving rise to particular absorption signatures, (ii) galaxy-absorber and halo-absorber correlations, (iii) virtual surveys and survey strategy optimization, (iv) stacking experiments and the identification of faint absorption features, (v) assessment of data reduction methods and completeness calculations, (vi) inference of physical properties from observables, and (vii) apples-to-apples comparisons between simulations and data.

19 Sep 2025
The weighted average treatment effect (WATE) defines a versatile class of causal estimands for populations characterized by propensity score weights, including the average treatment effect (ATE), treatment effect on the treated (ATT), on controls (ATC), and for the overlap population (ATO). WATE has broad applicability in social and medical research, as many datasets from these fields align with its framework. However, the literature lacks a systematic investigation into the robustness and efficiency conditions for WATE estimation. Although doubly robust (DR) estimators are well-studied for ATE, their applicability to other WATEs remains uncertain. This paper investigates whether widely used WATEs admit DR or rate doubly robust (RDR) estimators and assesses the role of nuisance function accuracy, particularly with machine learning. Using semiparametric efficient influence function (EIF) theory and double/debiased machine learning (DML), we propose three RDR estimators under specific rate and regularity conditions and evaluate their performance via Monte Carlo simulations. Applications to NHANES data on smoking and blood lead levels, and SIPP data on 401(k) eligibility, demonstrate the methods' practical relevance in medical and social sciences.

26 Apr 2022

This paper provides a comprehensive review of Graph Neural Network (GNN) applications in finance, addressing the gap between general GNN surveys and financial machine learning literature. The review systematically categorizes financial graphs and GNN methodologies tailored to their types, summarizing their use across tasks like stock movement prediction and fraud detection, while also identifying critical challenges and future research directions.
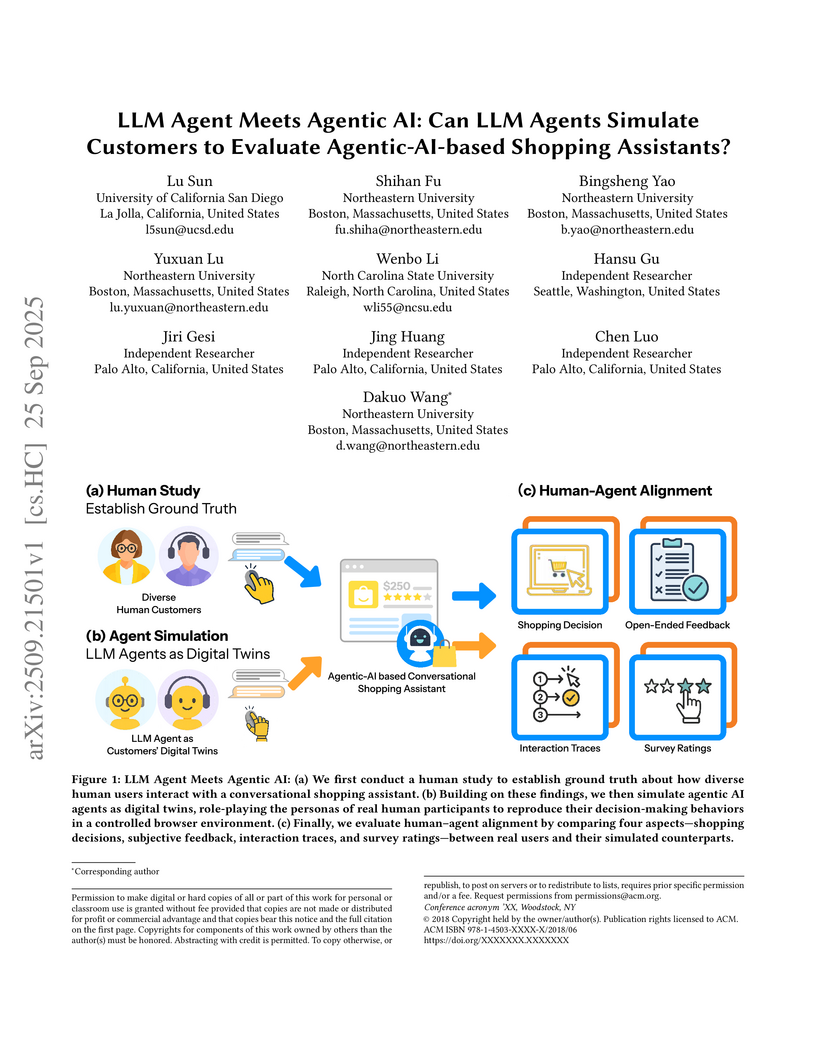
25 Sep 2025


Agentic AI is emerging, capable of executing tasks through natural language, such as Copilot for coding or Amazon Rufus for shopping. Evaluating these systems is challenging, as their rapid evolution outpaces traditional human evaluation. Researchers have proposed LLM Agents to simulate participants as digital twins, but it remains unclear to what extent a digital twin can represent a specific customer in multi-turn interaction with an agentic AI system. In this paper, we recruited 40 human participants to shop with Amazon Rufus, collected their personas, interaction traces, and UX feedback, and then created digital twins to repeat the task. Pairwise comparison of human and digital-twin traces shows that while agents often explored more diverse choices, their action patterns aligned with humans and yielded similar design feedback. This study is the first to quantify how closely LLM agents can mirror human multi-turn interaction with an agentic AI system, highlighting their potential for scalable evaluation.
There are no more papers matching your filters at the moment.
