
08 Dec 2025
This study explores contagion in the Chinese stock market using Hawkes processes to analyze autocorrelation and cross-correlation in multivariate time series data. We examine whether market indices exhibit trending behavior and whether sector indices influence one another. By fitting self-exciting and inhibitory Hawkes processes to daily returns of indices like the Shanghai Composite, Shenzhen Component, and ChiNext, as well as sector indices (CSI Consumer, Healthcare, and Financial), we identify long- term dependencies and trending patterns, including upward, downward, and over- sold rebound trends. Results show that during high trading activity, sector indices tend to sustain their trends, while low activity periods exhibit strong sector rotation. This research models stock price movements using spatiotemporal Hawkes processes, leveraging conditional intensity functions to explain sector rotation, advancing the understanding of financial contagion.

06 Dec 2025
Correlations in complex systems are often obscured by nonstationarity, long-range memory, and heavy-tailed fluctuations, which limit the usefulness of traditional covariance-based analyses. To address these challenges, we construct scale and fluctuation-dependent correlation matrices using the multifractal detrended cross-correlation coefficient that selectively emphasizes fluctuations of different amplitudes. We examine the spectral properties of these detrended correlation matrices and compare them to the spectral properties of the matrices calculated in the same way from synthetic Gaussian and Gaussian signals. Our results show that detrending, heavy tails, and the fluctuation-order parameter jointly produce spectra, which substantially depart from the random case even under absence of cross-correlations in time series. Applying this framework to one-minute returns of 140 major cryptocurrencies from 2021-2024 reveals robust collective modes, including a dominant market factor and several sectoral components whose strength depends on the analyzed scale and fluctuation order. After filtering out the market mode, the empirical eigenvalue bulk aligns closely with the limit of random detrended cross-correlations, enabling clear identification of structurally significant outliers. Overall, the study provides a refined spectral baseline for detrended cross-correlations and offers a promising tool for distinguishing genuine interdependencies from noise in complex, nonstationary, heavy-tailed systems.

02 Dec 2025
This paper develops a comprehensive theoretical framework that imports concepts from stochastic thermodynamics to model price impact and characterize the feasibility of round-trip arbitrage in financial markets. A trading cycle is treated as a non-equilibrium thermodynamic process, where price impact represents dissipative work and market noise plays the role of thermal fluctuations. The paper proves a Financial Second Law: under general convex impact functionals, any round-trip trading strategy yields non-positive expected profit. This structural constraint is complemented by a fluctuation theorem that bounds the probability of profitable cycles in terms of dissipated work and market volatility. The framework introduces a statistical ensemble of trading strategies governed by a Gibbs measure, leading to a free energy decomposition that connects expected cost, strategy entropy, and a market temperature parameter. The framework provides rigorous, testable inequalities linking microstructural impact to macroscopic no-arbitrage conditions, offering a novel physics-inspired perspective on market efficiency. The paper derives explicit analytical results for prototypical trading strategies and discusses empirical validation protocols.

01 Dec 2025
This paper investigates both short and long-run interaction between BIST-100 index and CDS prices over January 2008 to May 2015 using ARDL technique. The paper documents several findings. First, ARDL analysis shows that 1 TL increase in CDS shrinks BIST-100 index by 22.5 TL in short-run and 85.5 TL in long-run. Second, 1000 TL increase in BIST index price causes 25 TL and 44 TL reducation in Turkey's CDS prices in short- and long-run respectively. Third, a percentage increase in interest rate shrinks BIST index by 359 TL and a percentage increase in inflation rate scales CDS prices up to 13.34 TL both in long-run. In case of short-run, these impacts are limited with 231 TL and 5.73 TL respectively. Fourth, a kurush increase in TL/USD exchange rate leads 24.5 TL (short-run) and 78 TL (long-run) reductions in BIST, while it augments CDS prices by 2.5 TL (short-run) and 3 TL (long-run) respectively. Fifth, each negative political events decreases BIST by 237 TL in short-run and 538 TL in long-run, while it increases CDS prices by 33 TL in short-run and 89 TL in long-run. These findings imply the highly dollar indebted capital structure of Turkish firms, and overly sensitivity of financial markets to the uncertainties in political sphere. Finally, the paper provides evidence for that BIST and CDS with control variables drift too far apart, and converge to a long-run equilibrium at a moderate monthly speed.

30 Nov 2025
Bitcoin operates as a macroeconomic paradox: it combines a strictly predetermined, inelastic monetary issuance schedule with a stochastic, highly elastic demand for scarce block space. This paper empirically validates the Endogenous Constraint Hypothesis, positing that protocol-level throughput limits generate a non-linear negative feedback loop between network friction and base-layer monetary velocity. Using a verified Transaction Cost Index (TCI) derived from this http URL on-chain data and Hansen's (2000) threshold regression, we identify a definitive structural break at the 90th percentile of friction (TCI ~ 1.63). The analysis reveals a bifurcation in network utility: while the network exhibits robust velocity growth of +15.44% during normal regimes, this collapses to +6.06% during shock regimes, yielding a statistically significant Net Utility Contraction of -9.39% (p = 0.012). Crucially, Instrumental Variable (IV) tests utilizing Hashrate Variation as a supply-side instrument fail to detect a significant relationship in a linear specification (p=0.196), confirming that the velocity constraint is strictly a regime-switching phenomenon rather than a continuous linear function. Furthermore, we document a "Crypto Multiplier" inversion: high friction correlates with a +8.03% increase in capital concentration per entity, suggesting that congestion forces a substitution from active velocity to speculative hoarding.

22 Nov 2025
Forecasting cryptocurrency prices is hindered by extreme volatility and a methodological dilemma between information-scarce univariate models and noise-prone full-multivariate models. This paper investigates a partial-multivariate approach to balance this trade-off, hypothesizing that a strategic subset of features offers superior predictive power. We apply the Partial-Multivariate Transformer (PMformer) to forecast daily returns for BTCUSDT and ETHUSDT, benchmarking it against eleven classical and deep learning models. Our empirical results yield two primary contributions. First, we demonstrate that the partial-multivariate strategy achieves significant statistical accuracy, effectively balancing informative signals with noise. Second, we experiment and discuss an observable disconnect between this statistical performance and practical trading utility; lower prediction error did not consistently translate to higher financial returns in simulations. This finding challenges the reliance on traditional error metrics and highlights the need to develop evaluation criteria more aligned with real-world financial objectives.

19 Nov 2025
Crypto enthusiasts claim that buying and holding crypto assets yields high returns, often citing Bitcoin's past performance to promote other tokens and fuel fear of missing out. However, understanding the real risk-return trade-off and what factors affect future crypto returns is crucial as crypto becomes increasingly accessible to retail investors through major brokerages. We examine the HODL strategy through two independent analyses. First, we implement 480 million Monte Carlo simulations across 378 non-stablecoin crypto assets, net of trading fees and the opportunity cost of 1-month Treasury bills, and find strong evidence of survivorship bias and extreme downside concentration. At the 2-3 year horizon, the median excess return is -28.4 percent, the 1 percent conditional value at risk indicates that tail scenarios wipe out principal after all costs, and only the top quartile achieves very large gains, with a mean excess return of 1,326.7 percent. These results challenge the HODL narrative: across a broad set of assets, simple buy-and-hold loads extreme downside risk onto most investors, and the miracles mostly belong to the luckiest quarter. Second, using a Bayesian multi-horizon local projection framework, we find that endogenous predictors based on realized risk-return metrics have economically negligible and unstable effects, while macro-finance factors, especially the 24-week exponential moving average of the Fear and Greed Index, display persistent long-horizon impacts and high cross-basket stability. Where significant, a one-standard-deviation sentiment shock reduces forward top-quartile mean excess returns by 15-22 percentage points and median returns by 6-10 percentage points over 1-3 year horizons, suggesting that macro-sentiment conditions, rather than realized return histories, are the dominant indicators for future outcomes.

07 Oct 2025
We develop a statistical framework for risk estimation, inspired by the axiomatic theory of risk measures. Coherent risk estimators -- functionals of P&L samples inheriting the economic properties of risk measures -- are defined and characterized through robust representations linked to -estimators. The framework provides a canonical methodology for constructing estimators with sound financial and statistical properties, unifying risk measure theory, principles for capital adequacy, and practical statistical challenges in market risk. A numerical study illustrates the approach, focusing on expected shortfall estimation under both i.i.d. and overlapping samples relevant for regulatory FRTB model applications.

10 Aug 2025

Researchers from the University of Cambridge developed a framework that uses Large Language Models to extract interpretable, multi-label event factors from financial tweets, moving beyond simple sentiment scores. This method identified "thematic alphas," with categories like "Speculation/Rumor" consistently acting as contrarian indicators predicting negative stock returns, exhibiting Sharpe ratios as low as -0.700.
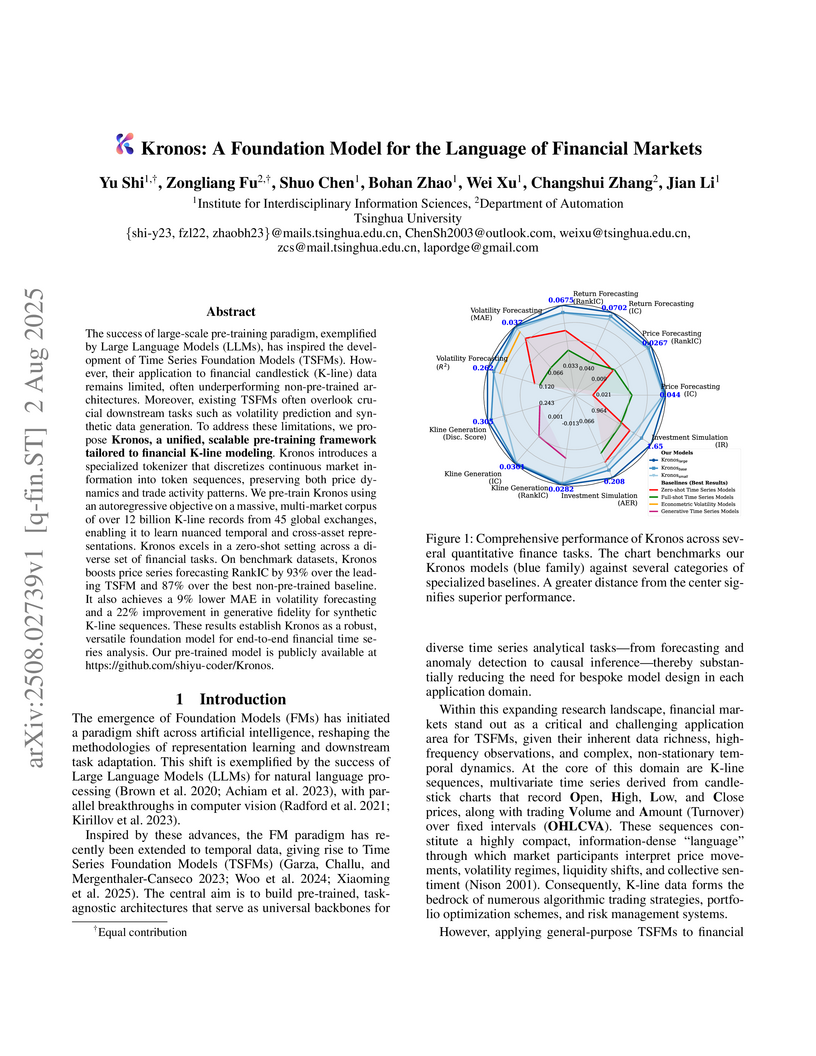
02 Aug 2025

Tsinghua University's Kronos model introduces a specialized foundation model designed for the distinct "language" of financial K-line data. It leverages a custom tokenizer and hierarchical autoregressive pre-training on a massive, exclusive financial corpus to achieve state-of-the-art results across various quantitative finance tasks.

08 Jul 2025
Quoting algorithms are fundamental to electronic trading systems, enabling participants to post limit orders in a systematic and adaptive manner. In multi-asset or multi-contract settings, selecting the appropriate reference instrument for pricing quotes is essential to managing execution risk and minimizing trading costs. This work presents a framework for reference selection based on predictive modeling of short-term price stability. We employ multivariate Hawkes processes to model the temporal clustering and cross-excitation of order flow events, capturing the dynamics of activity at the top of the limit order book. To complement this, we introduce a Composite Liquidity Factor (CLF) that provides instantaneous estimates of slippage based on structural features of the book, such as price discontinuities and depth variation across levels. Unlike Hawkes processes, which capture temporal dependencies but not the absolute price structure of the book, the CLF offers a static snapshot of liquidity. A rolling voting mechanism is used to convert these signals into real-time reference decisions. Empirical evaluation on high-frequency market data demonstrates that forecasts derived from the Hawkes process align more closely with market-optimal quoting choices than those based on CLF. These findings highlight the complementary roles of dynamic event modeling and structural liquidity metrics in guiding quoting behavior under execution constraints.

25 Jun 2025

Fraudulent activity in the financial industry costs billions annually. Detecting fraud, therefore, is an essential yet technically challenging task that requires carefully analyzing large volumes of data. While machine learning (ML) approaches seem like a viable solution, applying them successfully is not so easy due to two main challenges: (1) the sparsely labeled data, which makes the training of such approaches challenging (with inherent labeling costs), and (2) lack of explainability for the flagged items posed by the opacity of ML models, that is often required by business regulations. This article proposes SAGE-FIN, a semi-supervised graph neural network (GNN) based approach with Granger causal explanations for Financial Interaction Networks. SAGE-FIN learns to flag fraudulent items based on weakly labeled (or unlabelled) data points. To adhere to regulatory requirements, the flagged items are explained by highlighting related items in the network using Granger causality. We empirically validate the favorable performance of SAGE-FIN on a real-world dataset, Bipartite Edge-And-Node Attributed financial network (Elliptic++), with Granger-causal explanations for the identified fraudulent items without any prior assumption on the network structure.

23 Jul 2025
In this work, we aim to reconcile several apparently contradictory observations in market microstructure: is the famous "square-root law" of metaorder impact, which decays with time, compatible with the random-walk nature of prices and the linear impact of order imbalances? Can one entirely explain the volatility of prices as resulting from the flow of uninformed metaorders that mechanically impact them? We introduce a new theoretical framework to describe metaorders with different signs, sizes and durations, which all impact prices as a square-root of volume but with a subsequent time decay. We show that, as in the original propagator model, price diffusion is ensured by the long memory of cross-correlations between metaorders. In order to account for the effect of strongly fluctuating volumes q of individual trades, we further introduce two q-dependent exponents, which allow us to describe how the moments of generalized volume imbalance and the correlation between price changes and generalized order flow imbalance scale with T. We predict in particular that the corresponding power-laws depend in a non-monotonic fashion on a parameter a, which allows one to put the same weight on all child orders or to overweight large ones, a behaviour that is clearly borne out by empirical data. We also predict that the correlation between price changes and volume imbalances should display a maximum as a function of a, which again matches observations. Such noteworthy agreement between theory and data suggests that our framework correctly captures the basic mechanism at the heart of price formation, namely the average impact of metaorders. We argue that our results support the "Order-Driven" theory of excess volatility, and are at odds with the idea that a "Fundamental" component accounts for a large share of the volatility of financial markets.

12 May 2025
Delphyne, a pre-trained model developed by Carnegie Mellon University and Bloomberg, integrates proprietary financial data and a specialized transformer architecture to address challenges in general and financial time series. It achieves competitive performance across diverse time-series tasks and demonstrates superior results in financial applications after fine-tuning.

18 Aug 2025


In an environment of increasingly volatile financial markets, the accurate estimation of risk remains a major challenge. Traditional econometric models, such as GARCH and its variants, are based on assumptions that are often too rigid to adapt to the complexity of the current market dynamics. To overcome these limitations, we propose a hybrid framework for Value-at-Risk (VaR) estimation, combining GARCH volatility models with deep reinforcement learning. Our approach incorporates directional market forecasting using the Double Deep Q-Network (DDQN) model, treating the task as an imbalanced classification problem. This architecture enables the dynamic adjustment of risk-level forecasts according to market conditions. Empirical validation on daily Eurostoxx 50 data covering periods of crisis and high volatility shows a significant improvement in the accuracy of VaR estimates, as well as a reduction in the number of breaches and also in capital requirements, while respecting regulatory risk thresholds. The ability of the model to adjust risk levels in real time reinforces its relevance to modern and proactive risk management.

20 Apr 2025

This research systematically evaluates GPT-4o's memorization of economic and financial data, revealing that its apparent forecasting ability for historical periods often stems from recalling training data rather than genuine prediction. The model achieved near-perfect accuracy for pre-knowledge cutoff data, but its performance declined significantly to random levels for post-cutoff information, demonstrating the ineffectiveness of common mitigation strategies like explicit instructions or data masking.

18 Apr 2025
The paper presents a unified theoretical framework for optimizing target search under a novel threshold resetting (TR) mechanism, where all searchers reset collectively when any agent hits a boundary. This framework, applied to ballistic searchers, demonstrates that while a single searcher's mean search time diverges, multiple searchers achieve finite, optimizable search times, with global efficiency observed when resets are very frequent.

27 Mar 2025


A comprehensive survey examines the evolution of AI in quantitative investment across three distinct phases - from traditional statistical models to deep learning approaches and emerging LLM-based methods - mapping out technical approaches, practical challenges, and future directions while connecting isolated research efforts into a unified framework for alpha strategy development.

05 Nov 2025

Financial analysis relies heavily on the interpretation of earnings reports to assess company performance and guide decision-making. Traditional methods for generating such analyses demand significant financial expertise and are often time-consuming. With the rapid advancement of Large Language Models (LLMs), domain-specific adaptations have emerged for financial tasks such as sentiment analysis and entity recognition. This paper introduces RAG-IT (Retrieval-Augmented Instruction Tuning), a novel framework designed to automate the generation of earnings report analyses through an LLM fine-tuned specifically for the financial domain. Our approach integrates retrieval augmentation with instruction-based fine-tuning to enhance factual accuracy, contextual relevance, and domain adaptability. We construct a comprehensive financial instruction dataset derived from extensive financial documents and earnings reports to guide the LLM's adaptation to specialized financial reasoning. Experimental results demonstrate that RAG-IT outperforms general-purpose open-source models and achieves performance comparable to commercial systems like GPT-3.5 on financial report generation tasks. This research highlights the potential of retrieval-augmented instruction tuning to streamline and elevate financial analysis automation, advancing the broader field of intelligent financial reporting.

17 Nov 2024
A comprehensive review organizes Graph Neural Networks (GNNs) applied to financial fraud detection, presenting a unified framework, detailing design considerations, and charting future research. This work synthesizes over 100 studies to illustrate GNNs' capability in uncovering intricate relational fraud patterns.
There are no more papers matching your filters at the moment.
