
22 Aug 2024

Development of new materials in hard drive designs requires characterization of nanoscale materials through grain segmentation. The high-throughput quickly changing research environment makes zero-shot generalization an incredibly desirable feature. For this reason, we explore the application of Meta's Segment Anything Model (SAM) to this problem. We first analyze the out-of-the-box use of SAM. Then we discuss opportunities and strategies for improvement under the assumption of minimal labeled data availability. Out-of-the-box SAM shows promising accuracy at property distribution extraction. We are able to identify four potential areas for improvement and show preliminary gains in two of the four areas.

10 Nov 2021


With the rapid development of AI technology in recent years, there have been
many studies with deep learning models in soft sensing area. However, the
models have become more complex, yet, the data sets remain limited: researchers
are fitting million-parameter models with hundreds of data samples, which is
insufficient to exercise the effectiveness of their models and thus often fail
to perform when implemented in industrial applications. To solve this
long-lasting problem, we are providing large scale, high dimensional time
series manufacturing sensor data from Seagate Technology to the public. We
demonstrate the challenges and effectiveness of modeling industrial big data by
a Soft Sensing Transformer model on these data sets. Transformer is used
because, it has outperformed state-of-the-art techniques in Natural Language
Processing, and since then has also performed well in the direct application to
computer vision without introduction of image-specific inductive biases. We
observe the similarity of a sentence structure to the sensor readings and
process the multi-variable sensor readings in a time series in a similar manner
of sentences in natural language. The high-dimensional time-series data is
formatted into the same shape of embedded sentences and fed into the
transformer model. The results show that transformer model outperforms the
benchmark models in soft sensing field based on auto-encoder and long
short-term memory (LSTM) models. To the best of our knowledge, we are the first
team in academia or industry to benchmark the performance of original
transformer model with large-scale numerical soft sensing data.

12 Nov 2021
In the era of big data, data-driven based classification has become an essential method in smart manufacturing to guide production and optimize inspection. The industrial data obtained in practice is usually time-series data collected by soft sensors, which are highly nonlinear, nonstationary, imbalanced, and noisy. Most existing soft-sensing machine learning models focus on capturing either intra-series temporal dependencies or pre-defined inter-series correlations, while ignoring the correlation between labels as each instance is associated with multiple labels simultaneously. In this paper, we propose a novel graph based soft-sensing neural network (GraSSNet) for multivariate time-series classification of noisy and highly-imbalanced soft-sensing data. The proposed GraSSNet is able to 1) capture the inter-series and intra-series dependencies jointly in the spectral domain; 2) exploit the label correlations by superimposing label graph that built from statistical co-occurrence information; 3) learn features with attention mechanism from both textual and numerical domain; and 4) leverage unlabeled data and mitigate data imbalance by semi-supervised learning. Comparative studies with other commonly used classifiers are carried out on Seagate soft sensing data, and the experimental results validate the competitive performance of our proposed method.

18 Oct 2025
Striking a balance between protecting data privacy and enabling collaborative computation is a critical challenge for distributed machine learning. While privacy-preserving techniques for federated learning have been extensively developed, methods for scenarios involving bitwise operations, such as tree-based vertical federated learning (VFL), are still underexplored. Traditional mechanisms, including Shamir's secret sharing and multi-party computation (MPC), are not optimized for bitwise operations over binary data, particularly in settings where each participant holds a different part of the binary vector. This paper addresses the limitations of existing methods by proposing a novel binary multi-party computation (BiMPC) framework. The BiMPC mechanism facilitates privacy-preserving bitwise operations, with a particular focus on dot product computations of binary vectors, ensuring the privacy of each individual bit. The core of BiMPC is a novel approach called Dot Product via Modular Addition (DoMA), which uses regular and modular additions for efficient binary dot product calculation. To ensure privacy, BiMPC uses random masking in a higher field for linear computations and a three-party oblivious transfer (triot) protocol for non-linear binary operations. The privacy guarantees of the BiMPC framework are rigorously analyzed, demonstrating its efficiency and scalability in distributed settings.

05 Jan 2018


NAND flash memory is ubiquitous in everyday life today because its capacity
has continuously increased and cost has continuously decreased over decades.
This positive growth is a result of two key trends: (1) effective process
technology scaling; and (2) multi-level (e.g., MLC, TLC) cell data coding.
Unfortunately, the reliability of raw data stored in flash memory has also
continued to become more difficult to ensure, because these two trends lead to
(1) fewer electrons in the flash memory cell floating gate to represent the
data; and (2) larger cell-to-cell interference and disturbance effects. Without
mitigation, worsening reliability can reduce the lifetime of NAND flash memory.
As a result, flash memory controllers in solid-state drives (SSDs) have become
much more sophisticated: they incorporate many effective techniques to ensure
the correct interpretation of noisy data stored in flash memory cells.
In this chapter, we review recent advances in SSD error characterization,
mitigation, and data recovery techniques for reliability and lifetime
improvement. We provide rigorous experimental data from state-of-the-art MLC
and TLC NAND flash devices on various types of flash memory errors, to motivate
the need for such techniques. Based on the understanding developed by the
experimental characterization, we describe several mitigation and recovery
techniques, including (1) cell-tocell interference mitigation; (2) optimal
multi-level cell sensing; (3) error correction using state-of-the-art
algorithms and methods; and (4) data recovery when error correction fails. We
quantify the reliability improvement provided by each of these techniques.
Looking forward, we briefly discuss how flash memory and these techniques could
evolve into the future.

18 Apr 2016
In this paper, we propose a new approach to construct a class of check-hybrid generalized low-density parity-check (CH-GLDPC) codes which are free of small trapping sets. The approach is based on converting some selected check nodes involving a trapping set into super checks corresponding to a 2-error correcting component code. Specifically, we follow two main purposes to construct the check-hybrid codes; first, based on the knowledge of the trapping sets of the global LDPC code, single parity checks are replaced by super checks to disable the trapping sets. We show that by converting specified single check nodes, denoted as critical checks, to super checks in a trapping set, the parallel bit flipping (PBF) decoder corrects the errors on a trapping set and hence eliminates the trapping set. The second purpose is to minimize the rate loss caused by replacing the super checks through finding the minimum number of such critical checks. We also present an algorithm to find critical checks in a trapping set of column-weight 3 LDPC code and then provide upper bounds on the minimum number of such critical checks such that the decoder corrects all error patterns on elementary trapping sets. Moreover, we provide a fixed set for a class of constructed check-hybrid codes. The guaranteed error correction capability of the CH-GLDPC codes is also studied. We show that a CH-GLDPC code in which each variable node is connected to 2 super checks corresponding to a 2-error correcting component code corrects up to 5 errors. The results are also extended to column-weight 4 LDPC codes. Finally, we investigate the eliminating of trapping sets of a column-weight 3 LDPC code using the Gallager B decoding algorithm and generalize the results obtained for the PBF for the Gallager B decoding algorithm.

14 Jun 2024
Depth resolved study of structural and magnetic profiles of
antiferromagnetic/ferromagnetic (AFM/FM) system upon annealing was performed in
this work. We studied systems comprising of AFM IrMn and FM (Co, Fe,
CoFe) structures using polarized neutron and soft X-ray
scattering, secondary neutral spectrometry, and magnetometry. Structural depth
profiles obtained from neutron reflectometry indicate non-homogeneity of the
AFM layer even before annealing, which is associated with the migration of
manganese to the surface of the sample. Annealing of samples with CoFe and Co
layers leads to a slight increase ( 5 %) in the migration of manganese,
which, however, does not lead to significant degradation of the exchange
coupling at the AFM/FM interface. A significantly different picture was
observed in the Fe/IrMn systems where a strong migration of iron into the AFM
layer was observed upon annealing of the sample, leading to erosion of the
magnetic profile, the formation of a non-magnetic alloy and degradation of the
pinning strength. This study can be useful in the design of AF/FM systems in
different spintronics devices, including HDD read heads, where thermal
annealing is applied at different stages of the device manufacturing process.

15 Sep 2024
This paper focuses on designing a privacy-preserving Machine Learning (ML)
inference protocol for a hierarchical setup, where clients own/generate data,
model owners (cloud servers) have a pre-trained ML model, and edge servers
perform ML inference on clients' data using the cloud server's ML model. Our
goal is to speed up ML inference while providing privacy to both data and the
ML model. Our approach (i) uses model-distributed inference (model
parallelization) at the edge servers and (ii) reduces the amount of
communication to/from the cloud server. Our privacy-preserving hierarchical
model-distributed inference, privateMDI design uses additive secret sharing and
linearly homomorphic encryption to handle linear calculations in the ML
inference, and garbled circuit and a novel three-party oblivious transfer are
used to handle non-linear functions. privateMDI consists of offline and online
phases. We designed these phases in a way that most of the data exchange is
done in the offline phase while the communication overhead of the online phase
is reduced. In particular, there is no communication to/from the cloud server
in the online phase, and the amount of communication between the client and
edge servers is minimized. The experimental results demonstrate that privateMDI
significantly reduces the ML inference time as compared to the baselines.

25 Jan 2016
We have used a plane-wave expansion method to theoretically study the
far-field head-media optical interaction in HAMR. For the ASTC media stack
specifically, we notice the outstanding sensitivity related to interlayer's
optical thickness for media reflection and magnetic layer's light absorption.
With 10-nm interlayer thickness change, the recording layer absorption can be
changed by more than 25%. The 2-D results are found to correlate well with full
3-D model and magnetic recording tests on flyable disc with different
interlayer thickness.

28 Mar 2019
The development of permanent magnets containing less or no rare-earth elements is linked to profound knowledge of the coercivity mechanism. Prerequisites for a promising permanent magnet material are a high spontaneous magnetization and a sufficiently high magnetic anisotropy. In addition to the intrinsic magnetic properties the microstructure of the magnet plays a significant role in establishing coercivity. The influence of the microstructure on coercivity, remanence, and energy density product can be understood by {using} micromagnetic simulations. With advances in computer hardware and numerical methods, hysteresis curves of magnets can be computed quickly so that the simulations can readily provide guidance for the development of permanent magnets. The potential of rare-earth reduced and free permanent magnets is investigated using micromagnetic simulations. The results show excellent hard magnetic properties can be achieved in grain boundary engineered NdFeB, rare-earth magnets with a ThMn12 structure, Co-based nano-wires, and L10-FeNi provided that the magnet's microstructure is optimized.

11 Nov 2018
Compared to planar (i.e., two-dimensional) NAND flash memory, 3D NAND flash
memory uses a new flash cell design, and vertically stacks dozens of silicon
layers in a single chip. This allows 3D NAND flash memory to increase storage
density using a much less aggressive manufacturing process technology than
planar NAND flash memory. The circuit-level and structural changes in 3D NAND
flash memory significantly alter how different error sources affect the
reliability of the memory.
In this paper, through experimental characterization of real,
state-of-the-art 3D NAND flash memory chips, we find that 3D NAND flash memory
exhibits three new error sources that were not previously observed in planar
NAND flash memory: (1) layer-to-layer process variation, where the average
error rate of each 3D-stacked layer in a chip is significantly different; (2)
early retention loss, a new phenomenon where the number of errors due to charge
leakage increases quickly within several hours after programming; and (3)
retention interference, a new phenomenon where the rate at which charge leaks
from a flash cell is dependent on the data value stored in the neighboring
cell.
Based on our experimental results, we develop new analytical models of
layer-to-layer process variation and retention loss in 3D NAND flash memory.
Motivated by our new findings and models, we develop four new techniques to
mitigate process variation and early retention loss in 3D NAND flash memory.
These four techniques are complementary, and can be combined together to
significantly improve flash memory reliability. Compared to a state-of-the-art
baseline, our techniques, when combined, improve flash memory lifetime by
1.85x. Alternatively, if a NAND flash vendor wants to keep the lifetime of the
3D NAND flash memory device constant, our techniques reduce the storage
overhead required to hold error correction information by 78.9%.

11 Mar 2019
Recent research on CoPd alloys with perpendicular magnetic anisotropy (PMA)
has suggested that they might be useful as the pinning layer in CoFeB/MgO-based
perpendicular magnetic tunnel junctions (pMTJ's) for various spintronic
applications such as spin-torque transfer random access memory (STT-RAM). We
have previously studied the effect of seed layer and composition on the
structure (by XRD, SEM, AFM and TEM) and performance (coercivity) of these CoPd
films. These films do not switch coherently, so the coercivity is determined by
the details of the switching mechanism, which was not studied in our previous
paper. In the present paper, we show that information can be obtained about the
switching mechanism from magnetic force microscopy (MFM) together with first
order reversal curves (FORC), despite the fact that MFM can only be used at
zero field. We find that these films switch by a mechanism of domain nucleation
and dendritic growth into a labyrinthine structure, after which the unreversed
domains gradually shrink to small dots and then disappear.

27 Jun 2017
In this paper we apply an extended Landau-Lifschitz equation, as introduced
by Ba\v{n}as et al. for the simulation of heat-assisted magnetic recording.
This equation has similarities with the Landau-Lifshitz-Bloch equation. The
Ba\v{n}as equation is supposed to be used in a continuum setting with sub-grain
discretization by the finite-element method. Thus, local geometric features and
nonuniform magnetic states during switching are taken into account. We
implement the Ba\v{n}as model and test its capability for predicting the
recording performance in a realistic recording scenario. By performing
recording simulations on 100 media slabs with randomized granular structure and
consecutive read back calculation, the write position shift and transition
jitter for bit lengths of 10nm, 12nm, and 20nm are calculated.

18 Jan 2023
Over the years, hardware trends have introduced various heterogeneous compute
units while also bringing network and storage bandwidths within an order of
magnitude of memory subsystems. In response, developers have used increasingly
exotic solutions to extract more performance from hardware; typically relying
on static, design-time partitioning of their programs which cannot keep pace
with storage systems that are layering compute units throughout deepening
hierarchies of storage devices.
We argue that dynamic, just-in-time partitioning of computation offers a
solution for emerging data-intensive systems to overcome ever-growing data
sizes in the face of stalled CPU performance and memory bandwidth. In this
paper, we describe our prototype computational storage system (CSS), Skytether,
that adopts a database perspective to utilize computational storage drives
(CSDs). We also present MSG Express, a data management system for single-cell
gene expression data that sits on top of Skytether. We discuss four design
principles that guide the design of our CSS: support scientific applications;
maximize utilization of storage, network, and memory bandwidth; minimize data
movement; and enable flexible program execution on autonomous CSDs. Skytether
is designed for the extra layer of indirection that CSDs introduce to a storage
system, using decomposable queries to take a new approach to computational
storage that has been imagined but not yet explored.
In this paper, we evaluate: partition strategies, the overhead of function
execution, and the performance of selection and projection. We expected ~3-4x
performance slowdown on the CSDs compared to a consumer-grade client CPU but we
observe an unexpected slowdown of ~15x, however, our evaluation results help us
set anchor points in the design space for developing a cost model for
decomposable queries and partitioning data across many CSDs.

12 Apr 2023



Magnetic droplets are nanoscale, non-topological, magnetodynamical solitons
that can be nucleated in spin torque nano-oscillators (STNOs) or spin Hall
nano-oscillators (SHNOs). All theoretical, numerical, and experimental droplet
studies have so far focused on the free layer (FL), and any additional dynamics
in the reference layer (RL) have been entirely ignored. Here we show, using
all-perpendicular STNOs, that there is not only significant magnetodynamics in
the RL, but the reference layer itself can host a droplet coexisting with the
FL droplet. Both droplets are observed experimentally as stepwise changes and
sharp peaks in the dc and differential resistance, respectively. Whereas the
single FL droplet is highly stable, the coexistence state exhibits high-power
broadband microwave noise. Micromagnetic simulations corroborate the
experimental results and reveal a strong interaction between the droplets. Our
demonstration of strongly interacting and closely spaced droplets offers a
unique platform for fundamental studies of highly non-linear soliton pair
dynamics.

05 Jul 2023
Multi-level magnetic recording is a new concept for increasing the data
storage capacity of hard disk drives. However, its implementation has been
limited by a lack of suitable media capable of storing information at multiple
levels. Herein, we overcome this problem by developing dual FePt-C nanogranular
films separated by a Ru-C breaking layer with a cubic crystal structure. The
FePt grains in the bottom and top layers of the developed media exhibited
different effective magnetocrystalline anisotropies and Curie temperatures. The
former is realized by different degrees of ordering in the L10-FePt grains,
whereas the latter was attributed to the diffusion of Ru, thereby enabling
separate magnetic recordings at each layer under different magnetic fields and
temperatures. Furthermore, the magnetic measurements and heat-assisted magnetic
recording simulations showed that these media enabled 3-level recording and
could potentially be extended to 4-level recording, as the up-down and down-up
states exhibited non-zero magnetization.

04 Feb 2025
A multiscale framework for Heat-Assisted Magnetic Recording (HAMR) simulations integrates atomistic spin dynamics for high-temperature regions with micromagnetic modeling for lower temperatures. This approach provides a computationally efficient and accurate method to capture thermal effects during data writing, including for parallel tracks, and was demonstrated on FePt media.

12 Nov 2021
Over the last few decades, modern industrial processes have investigated several cost-effective methodologies to improve the productivity and yield of semiconductor manufacturing. While playing an essential role in facilitating real-time monitoring and control, the data-driven soft-sensors in industries have provided a competitive edge when augmented with deep learning approaches for wafer fault-diagnostics. Despite the success of deep learning methods across various domains, they tend to suffer from bad performance on multi-variate soft-sensing data domains. To mitigate this, we propose a soft-sensing ConFormer (CONvolutional transFORMER) for wafer fault-diagnostic classification task which primarily consists of multi-head convolution modules that reap the benefits of fast and light-weight operations of convolutions, and also the ability to learn the robust representations through multi-head design alike transformers. Another key issue is that traditional learning paradigms tend to suffer from low performance on noisy and highly-imbalanced soft-sensing data. To address this, we augment our soft-sensing ConFormer model with a curriculum learning-based loss function, which effectively learns easy samples in the early phase of training and difficult ones later. To further demonstrate the utility of our proposed architecture, we performed extensive experiments on various toolsets of Seagate Technology's wafer manufacturing process which are shared openly along with this work. To the best of our knowledge, this is the first time that curriculum learning-based soft-sensing ConFormer architecture has been proposed for soft-sensing data and our results show strong promise for future use in soft-sensing research domain.

18 Aug 2007

Four different ways of obtaining low-density parity-check codes from expander graphs are considered. For each case, lower bounds on the minimum stopping set size and the minimum pseudocodeword weight of expander (LDPC) codes are derived. These bounds are compared with the known eigenvalue-based lower bounds on the minimum distance of expander codes. Furthermore, Tanner's parity-oriented eigenvalue lower bound on the minimum distance is generalized to yield a new lower bound on the minimum pseudocodeword weight. These bounds are useful in predicting the performance of LDPC codes under graph-based iterative decoding and linear programming decoding.
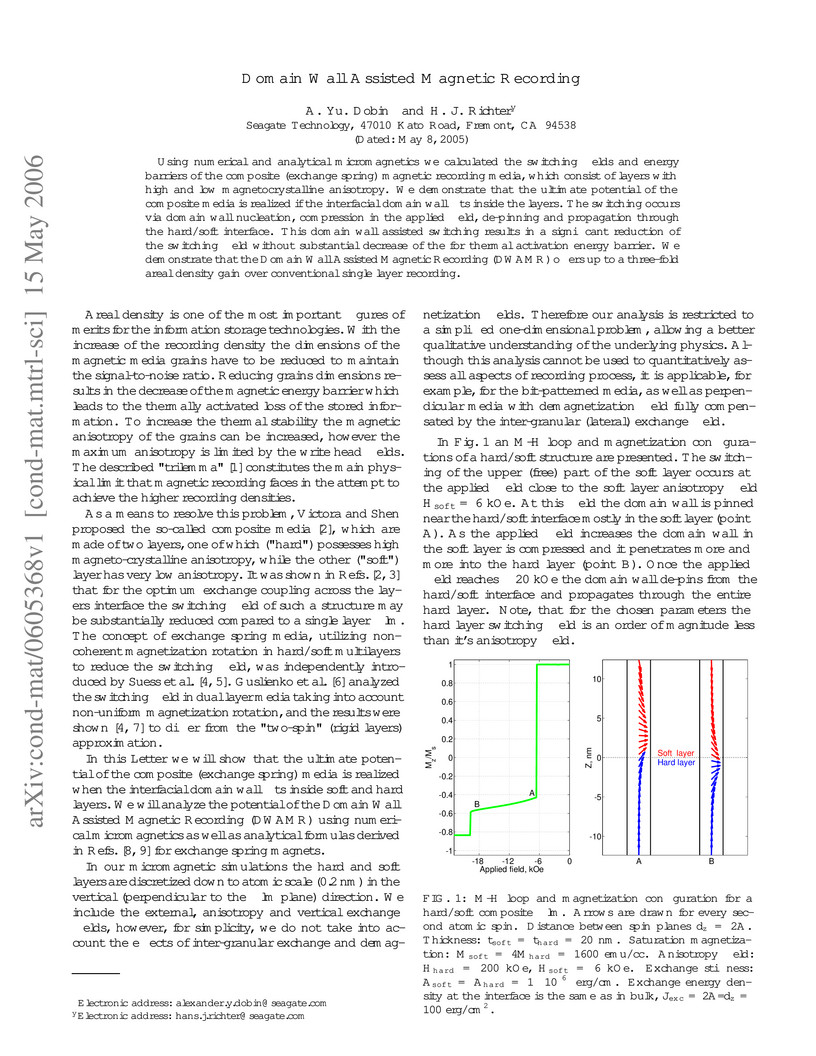
15 May 2006
Using numerical and analytical micromagnetics we calculated the switching
fields and energy barriers of the composite (exchange spring) magnetic
recording media, which consist of layers with high and low magnetocrystalline
anisotropy. We demonstrate that the ultimate potential of the composite media
is realized if the interfacial domain wall fits inside the layers. The
switching occurs via domain wall nucleation, compression in the applied field,
de-pinning and propagation through the hard/soft interface. This domain wall
assisted switching results in a significant reduction of the switching field
without substantial decrease of the for thermal activation energy barrier. We
demonstrate that the Domain Wall Assisted Magnetic Recording (DWAMR) offers up
to a three-fold areal density gain over conventional single layer recording.
There are no more papers matching your filters at the moment.
