
20 Feb 2019


Recently, graph neural networks (GNNs) have revolutionized the field of graph representation learning through effectively learned node embeddings, and achieved state-of-the-art results in tasks such as node classification and link prediction. However, current GNN methods are inherently flat and do not learn hierarchical representations of graphs---a limitation that is especially problematic for the task of graph classification, where the goal is to predict the label associated with an entire graph. Here we propose DiffPool, a differentiable graph pooling module that can generate hierarchical representations of graphs and can be combined with various graph neural network architectures in an end-to-end fashion. DiffPool learns a differentiable soft cluster assignment for nodes at each layer of a deep GNN, mapping nodes to a set of clusters, which then form the coarsened input for the next GNN layer. Our experimental results show that combining existing GNN methods with DiffPool yields an average improvement of 5-10% accuracy on graph classification benchmarks, compared to all existing pooling approaches, achieving a new state-of-the-art on four out of five benchmark data sets.

22 Aug 2023
This paper presents a comprehensive survey of self-supervised representation learning for image data, proposing a unified taxonomy that categorizes methods into five principal types and establishing consistent notation. The meta-study demonstrates that state-of-the-art self-supervised methods achieve competitive or superior performance compared to supervised approaches on various downstream computer vision tasks, highlighting their effectiveness in learning transferable representations from unlabeled data.

13 Mar 2023
A Transformer-based World Model (TWM) achieves state-of-the-art sample efficiency on the Atari 100k benchmark, demonstrating superior performance with a median human-normalized score of 0.505 and an Interquartile Mean (IQM) of 0.75. This work from the Technical University of Dortmund significantly reduces the environmental interactions required for reinforcement learning by leveraging a Transformer-XL architecture and explicit reward feedback for world modeling.

01 Oct 2025
Object-centric understanding is fundamental to human vision and required for complex reasoning. Traditional methods define slot-based bottlenecks to learn object properties explicitly, while recent self-supervised vision models like DINO have shown emergent object understanding. We investigate the effectiveness of self-supervised representations from models such as CLIP, DINOv2 and DINOv3, as well as slot-based approaches, for multi-object instance retrieval, where specific objects must be faithfully identified in a scene. This scenario is increasingly relevant as pre-trained representations are deployed in downstream tasks, e.g., retrieval, manipulation, and goal-conditioned policies that demand fine-grained object understanding. Our findings reveal that self-supervised vision models and slot-based representations excel at identifying edge-derived geometry (shape, size) but fail to preserve non-geometric surface-level cues (colour, material, texture), which are critical for disambiguating objects when reasoning about or selecting them in such tasks. We show that learning an auxiliary latent space over segmented patches, where VAE regularisation enforces compact, disentangled object-centric representations, recovers these missing attributes. Augmenting the self-supervised methods with such latents improves retrieval across all attributes, suggesting a promising direction for making self-supervised representations more reliable in downstream tasks that require precise object-level reasoning.

19 Nov 2024
A search for an eV-scale sterile neutrino using improved high-energy event reconstruction in IceCube
A search for an eV-scale sterile neutrino using improved high-energy event reconstruction in IceCube
University of CanterburyNational Central University UC Berkeley
UC Berkeley Georgia Institute of TechnologySungkyunkwan UniversityNational Taiwan University
Georgia Institute of TechnologySungkyunkwan UniversityNational Taiwan University University of California, Irvine
University of California, Irvine University of Maryland, College Park
University of Maryland, College Park University of California, San DiegoOhio State UniversityPennsylvania State UniversityLouisiana State University
University of California, San DiegoOhio State UniversityPennsylvania State UniversityLouisiana State University University of Pennsylvania
University of Pennsylvania University of Tokyo
University of Tokyo Lawrence Berkeley National Laboratory
Lawrence Berkeley National Laboratory University of AlbertaUppsala University
University of AlbertaUppsala University University of California, Davis
University of California, Davis Technical University of MunichDeutsches Elektronen-Synchrotron DESY
Technical University of MunichDeutsches Elektronen-Synchrotron DESY MITUniversity of SheffieldChiba UniversityUniversity of GenevaHumboldt-Universität zu BerlinUniversity of DelawareHelmholtz-Zentrum Dresden-Rossendorf (HZDR)University of New MexicoUniversity of AlabamaUniversität HamburgUniversity of Erlangen-NurembergTechnical University of DortmundRuhr-Universität BochumUniversity of AdelaideKarlsruhe Institute of Technology (KIT)University of Texas at ArlingtonUniversité de MonsAlbert-Ludwigs-Universität FreiburgUniversity of Kansas
MITUniversity of SheffieldChiba UniversityUniversity of GenevaHumboldt-Universität zu BerlinUniversity of DelawareHelmholtz-Zentrum Dresden-Rossendorf (HZDR)University of New MexicoUniversity of AlabamaUniversität HamburgUniversity of Erlangen-NurembergTechnical University of DortmundRuhr-Universität BochumUniversity of AdelaideKarlsruhe Institute of Technology (KIT)University of Texas at ArlingtonUniversité de MonsAlbert-Ludwigs-Universität FreiburgUniversity of Kansas University of California, Santa CruzDrexel UniversityUniversity of Hawai’iUniversity of WuppertalNiels Bohr Institute, University of CopenhagenKochi UniversityUniversity of MainzClark Atlanta UniversityUniversity of KlagenfurtUniversity of GhentNational Chiao Tung UniversityUniversity of StockholmUniversity of Wisconsin-River FallsUniversit
Libre de BruxellesRWTH Aachen UniversityUniversity of Wisconsin
Half-width em dash
–MadisonKavli Institute for the Physics and Mathematics of the Universe (IPMU), University of TokyoUniversity of Wisconsin
Half-width em dash
–MilwaukeeVrije Universiteit Brussel
University of California, Santa CruzDrexel UniversityUniversity of Hawai’iUniversity of WuppertalNiels Bohr Institute, University of CopenhagenKochi UniversityUniversity of MainzClark Atlanta UniversityUniversity of KlagenfurtUniversity of GhentNational Chiao Tung UniversityUniversity of StockholmUniversity of Wisconsin-River FallsUniversit
Libre de BruxellesRWTH Aachen UniversityUniversity of Wisconsin
Half-width em dash
–MadisonKavli Institute for the Physics and Mathematics of the Universe (IPMU), University of TokyoUniversity of Wisconsin
Half-width em dash
–MilwaukeeVrije Universiteit Brussel
UC BerkeleyGeorgia Institute of TechnologySungkyunkwan UniversityNational Taiwan UniversityUniversity of California, IrvineUniversity of Maryland, College ParkUniversity of California, San DiegoOhio State UniversityPennsylvania State UniversityLouisiana State UniversityUniversity of PennsylvaniaUniversity of TokyoLawrence Berkeley National LaboratoryUniversity of AlbertaUppsala UniversityUniversity of California, DavisTechnical University of MunichDeutsches Elektronen-Synchrotron DESYMITUniversity of SheffieldChiba UniversityUniversity of GenevaHumboldt-Universität zu BerlinUniversity of DelawareHelmholtz-Zentrum Dresden-Rossendorf (HZDR)University of New MexicoUniversity of AlabamaUniversität HamburgUniversity of Erlangen-NurembergTechnical University of DortmundRuhr-Universität BochumUniversity of AdelaideKarlsruhe Institute of Technology (KIT)University of Texas at ArlingtonUniversité de MonsAlbert-Ludwigs-Universität FreiburgUniversity of KansasUniversity of California, Santa CruzDrexel UniversityUniversity of Hawai’iUniversity of WuppertalNiels Bohr Institute, University of CopenhagenKochi UniversityUniversity of MainzClark Atlanta UniversityUniversity of KlagenfurtUniversity of GhentNational Chiao Tung UniversityUniversity of StockholmUniversity of Wisconsin-River FallsUniversit
Libre de BruxellesRWTH Aachen UniversityUniversity of Wisconsin
Half-width em dash
–MadisonKavli Institute for the Physics and Mathematics of the Universe (IPMU), University of TokyoUniversity of Wisconsin
Half-width em dash
–MilwaukeeVrije Universiteit BrusselThis Letter presents the result of a 3+1 sterile neutrino search using 10.7 years of IceCube data. We analyze atmospheric muon neutrinos that traverse the Earth with energies ranging from 0.5 to 100 TeV, incorporating significant improvements in modeling neutrino flux and detector response compared to earlier studies. Notably, for the first time, we categorize data into starting and through-going events, distinguishing neutrino interactions with vertices inside or outside the instrumented volume, to improve energy resolution. The best-fit point for a 3+1 model is found to be at and eV, which agrees with previous iterations of this study. The result is consistent with the null hypothesis of no sterile neutrinos with a p-value of 3.1\%.

06 Nov 2025

This paper is concerned with probabilistic techniques for forecasting dynamical systems described by partial differential equations (such as, for example, the Navier-Stokes equations). In particular, it is investigating and comparing various extensions to the flow matching paradigm that reduce the number of sampling steps. In this regard, it compares direct distillation, progressive distillation, adversarial diffusion distillation, Wasserstein GANs and rectified flows. Moreover, experiments are conducted on a set of challenging systems. In particular, we also address the challenge of directly predicting 2D slices of large-scale 3D simulations, paving the way for efficient inflow generation for solvers.
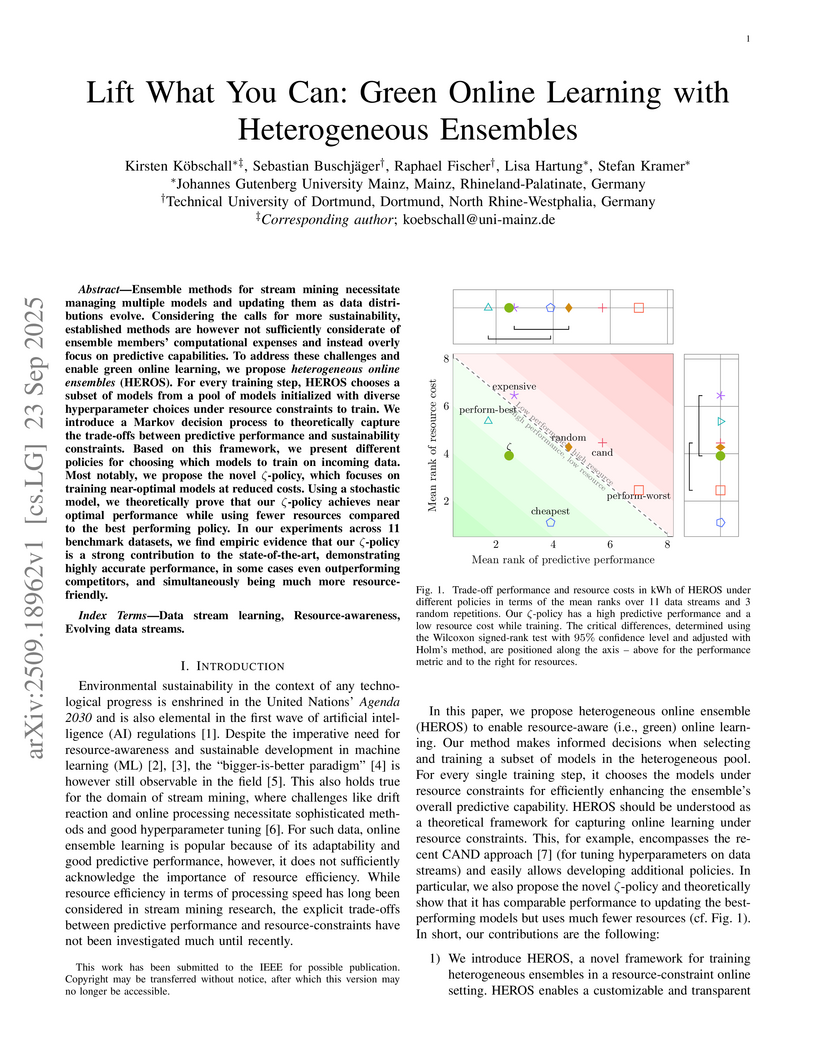
23 Sep 2025
Ensemble methods for stream mining necessitate managing multiple models and updating them as data distributions evolve. Considering the calls for more sustainability, established methods are however not sufficiently considerate of ensemble members' computational expenses and instead overly focus on predictive capabilities. To address these challenges and enable green online learning, we propose heterogeneous online ensembles (HEROS). For every training step, HEROS chooses a subset of models from a pool of models initialized with diverse hyperparameter choices under resource constraints to train. We introduce a Markov decision process to theoretically capture the trade-offs between predictive performance and sustainability constraints. Based on this framework, we present different policies for choosing which models to train on incoming data. Most notably, we propose the novel -policy, which focuses on training near-optimal models at reduced costs. Using a stochastic model, we theoretically prove that our -policy achieves near optimal performance while using fewer resources compared to the best performing policy. In our experiments across 11 benchmark datasets, we find empiric evidence that our -policy is a strong contribution to the state-of-the-art, demonstrating highly accurate performance, in some cases even outperforming competitors, and simultaneously being much more resource-friendly.

13 Jan 2023
Very large state spaces with a sparse reward signal are difficult to explore. The lack of a sophisticated guidance results in a poor performance for numerous reinforcement learning algorithms. In these cases, the commonly used random exploration is often not helpful. The literature shows that this kind of environments require enormous efforts to systematically explore large chunks of the state space. Learned state representations can help here to improve the search by providing semantic context and build a structure on top of the raw observations. In this work we introduce a novel time-myopic state representation that clusters temporal close states together while providing a time prediction capability between them. By adapting this model to the Go-Explore paradigm (Ecoffet et al., 2021b), we demonstrate the first learned state representation that reliably estimates novelty instead of using the hand-crafted representation heuristic. Our method shows an improved solution for the detachment problem which still remains an issue at the Go-Explore Exploration Phase. We provide evidence that our proposed method covers the entire state space with respect to all possible time trajectories without causing disadvantageous conflict-overlaps in the cell archive. Analogous to native Go-Explore, our approach is evaluated on the hard exploration environments MontezumaRevenge, Gravitar and Frostbite (Atari) in order to validate its capabilities on difficult tasks. Our experiments show that time-myopic Go-Explore is an effective alternative for the domain-engineered heuristic while also being more general. The source code of the method is available on GitHub.

30 May 2025
This paper addresses the challenge of neural state estimation in power distribution systems. We identified a research gap in the current state of the art, which lies in the inability of models to adapt to changes in the power grid, such as loss of sensors and branch switching, in a zero-shot fashion. Based on the literature, we identified graph neural networks as the most promising class of models for this use case. Our experiments confirm their robustness to some grid changes and also show that a deeper network does not always perform better. We propose data augmentations to improve performance and conduct a comprehensive grid search of different model configurations for common zero-shot learning scenarios.

28 May 2025

After the end of World War II, the commitment to confine scientific
activities in universities and research institutions to peaceful and civilian
purposes has entered, in the form of {\it Civil Clauses}, the charters of many
research institutions and universities. In the wake of recent world events, the
relevance and scope of such Civil Clauses has been questioned in reports issued
by some governments and by the EU Commission, a development that opens the door
to a possible blurring of the distinction between peaceful and military
research.
This paper documents the reflections stimulated by a panel discussion on this
issue recently organized by the Science4Peace Forum. We review the adoptions of
Civil Clauses in research organizations and institutions in various countries,
present evidence of the challenges that are emerging to such Civil Clauses, and
collect arguments in favour of maintaining the purely civilian and peaceful
focus of public (non-military) research.

07 Oct 2025



A fundamental problem in shape matching and geometric similarity is computing the maximum area overlap between two polygons under translation. For general simple polygons, the best-known algorithm runs in time [Mount, Silverman, Wu 96], where and are the complexities of the input polygons. In a recent breakthrough, Chan and Hair gave a linear-time algorithm for the special case when both polygons are convex. A key challenge in computational geometry is to design improved algorithms for other natural classes of polygons. We address this by presenting an -time algorithm for the case when both polygons are orthogonal. This is the first algorithm for polygon overlap on orthogonal polygons that is faster than the almost 30 years old algorithm for simple polygons.
Complementing our algorithmic contribution, we provide -SUM lower bounds for problems on simple polygons with only orthogonal and diagonal edges. First, we establish that there is no algorithm for polygon overlap with running time , where , unless the -SUM hypothesis fails. This matches the running time of our algorithm when . We use part of the above construction to also show a lower bound for the polygon containment problem, a popular special case of the overlap problem. Concretely, there is no algorithm for polygon containment with running time under the -SUM hypothesis, even when the polygon to be contained has vertices. Our lower bound shows that polygon containment for these types of polygons (i.e., with diagonal edges) is strictly harder than for orthogonal polygons, and also strengthens the previously known lower bounds for polygon containment. Furthermore, our lower bounds show tightness of the algorithm of [Mount, Silverman, Wu 96] when .

15 Apr 2024
Can we learn policies in reinforcement learning without rewards? Can we learn a policy just by trying to reach a goal state? We answer these questions positively by proposing a multi-step procedure that first learns a world model that goes backward in time, secondly generates goal-reaching backward trajectories, thirdly improves those sequences using shortest path finding algorithms, and finally trains a neural network policy by imitation learning. We evaluate our method on a deterministic maze environment where the observations are pixel bird's eye images and can show that it consistently reaches several goals.

31 Jul 2013
We describe ongoing work on a framework for automatic composition synthesis from a repository of software components. This work is based on combinatory logic with intersection types. The idea is that components are modeled as typed combinators, and an algorithm for inhabitation {\textemdash} is there a combinatory term e with type tau relative to an environment Gamma? {\textemdash} can be used to synthesize compositions. Here, Gamma represents the repository in the form of typed combinators, tau specifies the synthesis goal, and e is the synthesized program. We illustrate our approach by examples, including an application to synthesis from GUI-components.

11 Dec 2024
Given a point set in a metric space and a real number , an \emph{oriented -spanner} is an oriented graph , where for every pair of distinct points and in , the shortest oriented closed walk in that contains and is at most a factor longer than the perimeter of the smallest triangle in containing and . The \emph{oriented dilation} of a graph is the minimum for which is an oriented -spanner.
We present the first algorithm that computes, in Euclidean space, a sparse oriented spanner whose oriented dilation is bounded by a constant. More specifically, for any set of points in , where is a constant, we construct an oriented -spanner with edges in time and space. Our construction uses the well-separated pair decomposition and an algorithm that computes a -approximation of the minimum-perimeter triangle in containing two given query points in time.
While our algorithm is based on first computing a suitable undirected graph and then orienting it, we show that, in general, computing the orientation of an undirected graph that minimises its oriented dilation is NP-hard, even for point sets in the Euclidean plane.
We further prove that even if the orientation is already given, computing the oriented dilation is APSP-hard for points in a general metric space. We complement this result with an algorithm that approximates the oriented dilation of a given graph in subcubic time for point sets in , where is a constant.

11 Jun 2025
 University of WashingtonUniversity of CanterburyDESY
University of WashingtonUniversity of CanterburyDESY University of ChicagoGhent UniversityVictoria University of WellingtonSungkyunkwan UniversityUniversity of California, Irvine
University of ChicagoGhent UniversityVictoria University of WellingtonSungkyunkwan UniversityUniversity of California, Irvine Nagoya UniversityTU Dortmund UniversityPennsylvania State University
Nagoya UniversityTU Dortmund UniversityPennsylvania State University Yale UniversityLouisiana State University
Yale UniversityLouisiana State University University of Maryland
University of Maryland Stony Brook University
Stony Brook University Stockholm UniversityLawrence Berkeley National Laboratory
Stockholm UniversityLawrence Berkeley National Laboratory Purdue UniversityUniversity of AlbertaUppsala UniversityGeorgia TechHumboldt University of BerlinUniversity of RochesterCase Western Reserve UniversityUniversity of SheffieldUniversity of Geneva
Purdue UniversityUniversity of AlbertaUppsala UniversityGeorgia TechHumboldt University of BerlinUniversity of RochesterCase Western Reserve UniversityUniversity of SheffieldUniversity of Geneva Queen Mary University of London
Queen Mary University of London Karlsruhe Institute of TechnologyNiels Bohr InstituteКрымский федеральный университет имени В.И. ВернадскогоLund UniversityChulalongkorn UniversityUniversity of AlabamaTechnical University of DortmundUniversity of AdelaideUniversite Libre de BruxellesUniversity of Minnesota Twin CitiesUniversity of KansasUniversity of WuppertalUniversity of Nebraska–LincolnErlangen-Nuremberg UniversityUniversity of Alaska FairbanksUniversity of MuensterMarquette UniversityUniversity of AntwerpenRWTH Aachen UniversityRuhr-University-Bochum
Karlsruhe Institute of TechnologyNiels Bohr InstituteКрымский федеральный университет имени В.И. ВернадскогоLund UniversityChulalongkorn UniversityUniversity of AlabamaTechnical University of DortmundUniversity of AdelaideUniversite Libre de BruxellesUniversity of Minnesota Twin CitiesUniversity of KansasUniversity of WuppertalUniversity of Nebraska–LincolnErlangen-Nuremberg UniversityUniversity of Alaska FairbanksUniversity of MuensterMarquette UniversityUniversity of AntwerpenRWTH Aachen UniversityRuhr-University-BochumWe report a study of the inelasticity distribution in the scattering of neutrinos of energy GeV off nucleons. Using atmospheric muon neutrinos detected in IceCube's sub-array DeepCore during 2012-2021, we fit the observed inelasticity in the data to a parameterized expectation and extract the values that describe it best. Finally, we compare the results to predictions from various combinations of perturbative QCD calculations and atmospheric neutrino flux models.

26 Aug 2019
We introduce an approach that aims to combine the usage of satisfiability modulo theories (SMT) solvers with the Combinatory Logic Synthesizer (CL)S framework. (CL)S is a tool for the automatic composition of software components from a user-specified repository. The framework yields a tree grammar that contains all composed terms that comply with a target type. Type specifications for (CL)S are based on combinatory logic with intersection types. Our approach translates the tree grammar into SMT functions, which allows the consideration of additional domain-specific constraints. We demonstrate the usefulness of our approach in several experiments.
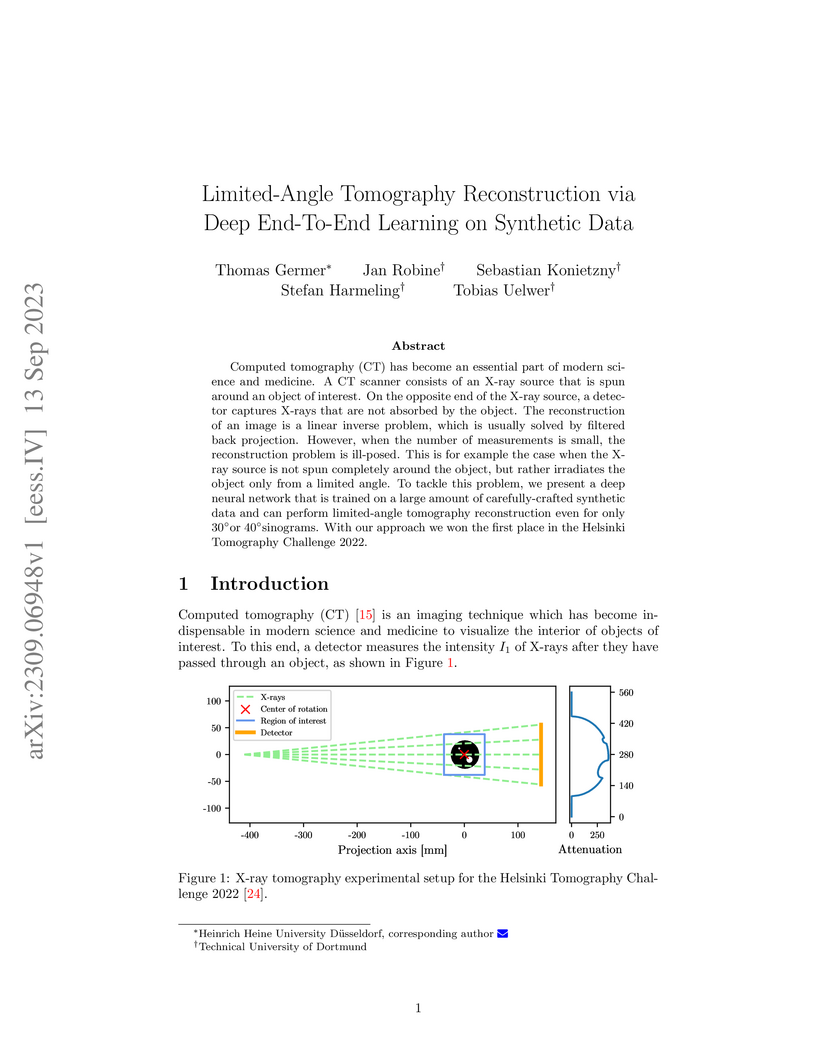
13 Sep 2023
Computed tomography (CT) has become an essential part of modern science and medicine. A CT scanner consists of an X-ray source that is spun around an object of interest. On the opposite end of the X-ray source, a detector captures X-rays that are not absorbed by the object. The reconstruction of an image is a linear inverse problem, which is usually solved by filtered back projection. However, when the number of measurements is small, the reconstruction problem is ill-posed. This is for example the case when the X-ray source is not spun completely around the object, but rather irradiates the object only from a limited angle. To tackle this problem, we present a deep neural network that is trained on a large amount of carefully-crafted synthetic data and can perform limited-angle tomography reconstruction even for only 30° or 40° sinograms. With our approach we won the first place in the Helsinki Tomography Challenge 2022.

24 Nov 2014
We present theoretical predictions in the framework of the ANP model for
single pion production () in and
scattering off mineral oil and plastic. Our results for the total cross
sections and flux averaged differential distributions are compared to all
available data of the MiniBooNE and MINERA experiments. While our
predictions slightly undershoot the MiniBooNE data they reproduce the
normalization of the MINERA data for the kinetic energy distribution. For
the dependence on the polar angle we reproduce the shape of the arbitrarily
normalized data.

31 Jan 2025
We develop a framework for derivative Gaussian process latent variable models (DGP-LVMs) that can handle multi-dimensional output data using modified derivative covariance functions. The modifications account for complexities in the underlying data generating process such as scaled derivatives, varying information across multiple output dimensions as well as interactions between outputs. Further, our framework provides uncertainty estimates for each latent variable samples using Bayesian inference. Through extensive simulations, we demonstrate that latent variable estimation accuracy can be drastically increased by including derivative information due to our proposed covariance function modifications. The developments are motivated by a concrete biological research problem involving the estimation of the unobserved cellular ordering from single-cell RNA (scRNA) sequencing data for gene expression and its corresponding derivative information known as RNA velocity. Since the RNA velocity is only an estimate of the exact derivative information, the derivative covariance functions need to account for potential scale differences. In a real-world case study, we illustrate the application of DGP-LVMs to such scRNA sequencing data. While motivated by this biological problem, our framework is generally applicable to all kinds of latent variable estimation problems involving derivative information irrespective of the field of study.

27 May 2025
The high numerical demands for simulating non-Markovian open quantum systems
motivate a line of research where short-time dynamical maps are extrapolated to
predict long-time behavior. The transfer tensor method (TTM) has emerged as a
powerful and versatile paradigm for such scenarios. It relies on a systematic
construction of a converging sequence of time-nonlocal corrections to a
time-constant local dynamical map. Here, we show that the same objective can be
achieved with time-local extrapolation based on the observation that
time-dependent time-local dynamical maps become stationary. Surprisingly, the
maps become stationary long before the open quantum system reaches its steady
state. Comparing both approaches numerically on examples of the canonical
spin-boson model with sub-ohmic, ohmic, and super-ohmic spectral density,
respectively, we find that, while both approaches eventually converge with
increasing length of short-time propagation, our simple time-local
extrapolation invariably converges at least as fast as time-nonlocal
extrapolation. These results suggest that, perhaps counter-intuitively,
time-nonlocality is not in fact a prerequiste for accurate and efficient
long-time extrapolation of non-Markovian quantum dynamics.
There are no more papers matching your filters at the moment.
