
22 Dec 2022
Digital Humanities and Computational Literary Studies apply text mining
methods to investigate literature. Such automated approaches enable
quantitative studies on large corpora which would not be feasible by manual
inspection alone. However, due to copyright restrictions, the availability of
relevant digitized literary works is limited. Derived Text Formats (DTFs) have
been proposed as a solution. Here, textual materials are transformed in such a
way that copyright-critical features are removed, but that the use of certain
analytical methods remains possible. Contextualized word embeddings produced by
transformer-encoders (like BERT) are promising candidates for DTFs because they
allow for state-of-the-art performance on various analytical tasks and, at
first sight, do not disclose the original text. However, in this paper we
demonstrate that under certain conditions the reconstruction of the original
copyrighted text becomes feasible and its publication in the form of
contextualized token representations is not safe. Our attempts to invert BERT
suggest, that publishing the encoder as a black box together with the
contextualized embeddings is critical, since it allows to generate data to
train a decoder with a reconstruction accuracy sufficient to violate copyright
laws.

21 Oct 2025
Large language models have become the latest trend in natural language processing, heavily featuring in the digital tools we use every day. However, their replies often reflect a narrow cultural viewpoint that overlooks the diversity of global users. This missing capability could be referred to as cultural reasoning, which we define here as the capacity of a model to recognise culture-specific knowledge values and social norms, and to adjust its output so that it aligns with the expectations of individual users. Because culture shapes interpretation, emotional resonance, and acceptable behaviour, cultural reasoning is essential for identity-aware AI. When this capacity is limited or absent, models can sustain stereotypes, ignore minority perspectives, erode trust, and perpetuate hate. Recent empirical studies strongly suggest that current models default to Western norms when judging moral dilemmas, interpreting idioms, or offering advice, and that fine-tuning on survey data only partly reduces this tendency. The present evaluation methods mainly report static accuracy scores and thus fail to capture adaptive reasoning in context. Although broader datasets can help, they cannot alone ensure genuine cultural competence. Therefore, we argue that cultural reasoning must be treated as a foundational capability alongside factual accuracy and linguistic coherence. By clarifying the concept and outlining initial directions for its assessment, a foundation is laid for future systems to be able to respond with greater sensitivity to the complex fabric of human culture.

27 Jun 2025
The ability of Large Language Models (LLMs) to mimic human behavior triggered a plethora of computational social science research, assuming that empirical studies of humans can be conducted with AI agents instead. Since there have been conflicting research findings on whether and when this hypothesis holds, there is a need to better understand the differences in their experimental designs. We focus on replicating the behavior of social network users with the use of LLMs for the analysis of communication on social networks. First, we provide a formal framework for the simulation of social networks, before focusing on the sub-task of imitating user communication. We empirically test different approaches to imitate user behavior on X in English and German. Our findings suggest that social simulations should be validated by their empirical realism measured in the setting in which the simulation components were fitted. With this paper, we argue for more rigor when applying generative-agent-based modeling for social simulation.

25 Sep 2024
TU Dortmund University KU LeuvenGerman Research Center for Artificial Intelligence (DFKI)Gran Sasso Science InstituteUniversity of CamerinoUniversity of BayreuthUniversitat Politécnica de ValénciaUniversity of St.GallenTrier UniversityTUM School of Computation, Information and TechnologyMercadona TechFraunhofer Institute for Applied Information TechnologyOST - Eastern Switzerland University of Applied SciencesRWTH Aachen UniversitySapienza Universit
di Roma
KU LeuvenGerman Research Center for Artificial Intelligence (DFKI)Gran Sasso Science InstituteUniversity of CamerinoUniversity of BayreuthUniversitat Politécnica de ValénciaUniversity of St.GallenTrier UniversityTUM School of Computation, Information and TechnologyMercadona TechFraunhofer Institute for Applied Information TechnologyOST - Eastern Switzerland University of Applied SciencesRWTH Aachen UniversitySapienza Universit
di Roma
KU LeuvenGerman Research Center for Artificial Intelligence (DFKI)Gran Sasso Science InstituteUniversity of CamerinoUniversity of BayreuthUniversitat Politécnica de ValénciaUniversity of St.GallenTrier UniversityTUM School of Computation, Information and TechnologyMercadona TechFraunhofer Institute for Applied Information TechnologyOST - Eastern Switzerland University of Applied SciencesRWTH Aachen UniversitySapienza Universit
di RomaA collaborative research manifesto clarifies the concept of Business Process Digital Twins (BPDTs) as virtual replicas of business processes enabling real-time monitoring, simulation, prediction, and optimization. It outlines a conceptual model for BPDTs and identifies twelve key challenges along with proposed research directions for the field.

28 Sep 2020
This paper targets the automated extraction of components of argumentative information and their relations from natural language text. Moreover, we address a current lack of systems to provide complete argumentative structure from arbitrary natural language text for general usage. We present an argument mining pipeline as a universally applicable approach for transforming German and English language texts to graph-based argument representations. We also introduce new methods for evaluating the results based on existing benchmark argument structures. Our results show that the generated argument graphs can be beneficial to detect new connections between different statements of an argumentative text. Our pipeline implementation is publicly available on GitHub.
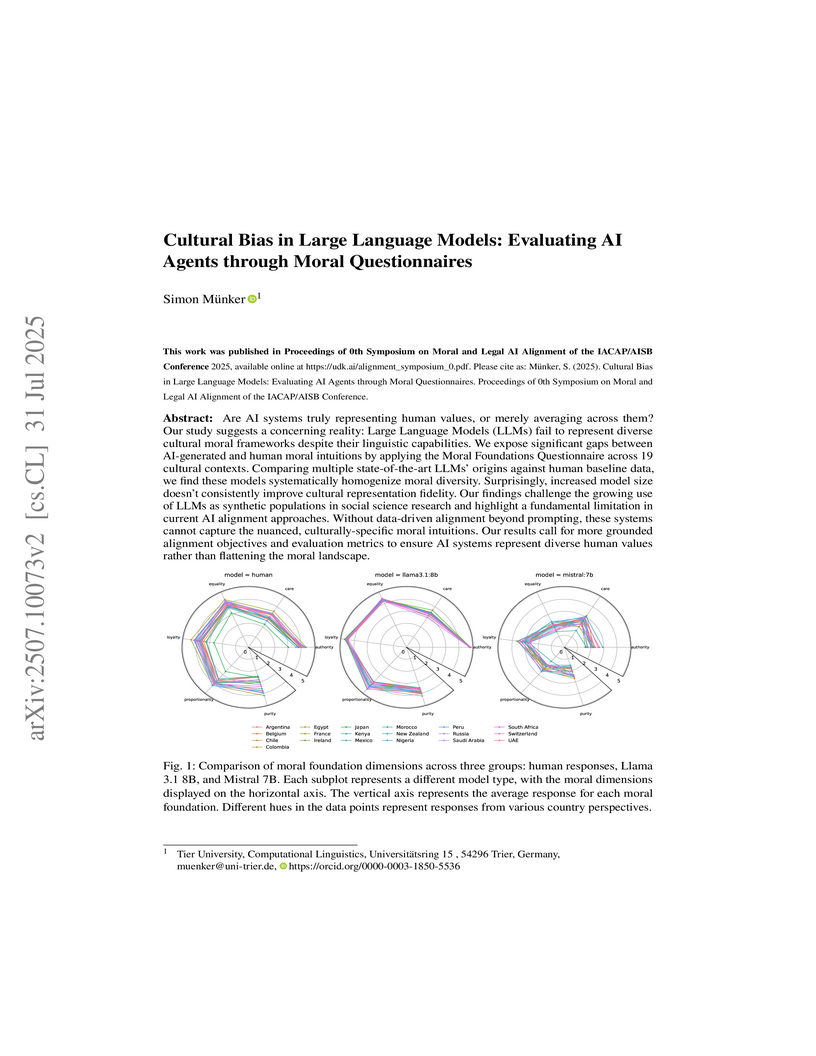
31 Jul 2025
Are AI systems truly representing human values, or merely averaging across them? Our study suggests a concerning reality: Large Language Models (LLMs) fail to represent diverse cultural moral frameworks despite their linguistic capabilities. We expose significant gaps between AI-generated and human moral intuitions by applying the Moral Foundations Questionnaire across 19 cultural contexts. Comparing multiple state-of-the-art LLMs' origins against human baseline data, we find these models systematically homogenize moral diversity. Surprisingly, increased model size doesn't consistently improve cultural representation fidelity. Our findings challenge the growing use of LLMs as synthetic populations in social science research and highlight a fundamental limitation in current AI alignment approaches. Without data-driven alignment beyond prompting, these systems cannot capture the nuanced, culturally-specific moral intuitions. Our results call for more grounded alignment objectives and evaluation metrics to ensure AI systems represent diverse human values rather than flattening the moral landscape.

20 Jun 2025
Aligning machine learning systems with human expectations is mostly attempted by training with manually vetted human behavioral samples, typically explicit feedback. This is done on a population level since the context that is capturing the subjective Point-Of-View (POV) of a concrete person in a specific situational context is not retained in the data. However, we argue that alignment on an individual level can boost the subjective predictive performance for the individual user interacting with the system considerably. Since perception differs for each person, the same situation is observed differently. Consequently, the basis for decision making and the subsequent reasoning processes and observable reactions differ. We hypothesize that individual perception patterns can be used for improving the alignment on an individual level. We test this, by integrating perception information into machine learning systems and measuring their predictive performance wrt.~individual subjective assessments. For our empirical study, we collect a novel data set of multimodal stimuli and corresponding eye tracking sequences for the novel task of Perception-Guided Crossmodal Entailment and tackle it with our Perception-Guided Multimodal Transformer. Our findings suggest that exploiting individual perception signals for the machine learning of subjective human assessments provides a valuable cue for individual alignment. It does not only improve the overall predictive performance from the point-of-view of the individual user but might also contribute to steering AI systems towards every person's individual expectations and values.

07 Sep 2022
Scientific writing builds upon already published papers. Manual identification of publications to read, cite or consider as related papers relies on a researcher's ability to identify fitting keywords or initial papers from which a literature search can be started. The rapidly increasing amount of papers has called for automatic measures to find the desired relevant publications, so-called paper recommendation systems.
As the number of publications increases so does the amount of paper recommendation systems. Former literature reviews focused on discussing the general landscape of approaches throughout the years and highlight the main directions. We refrain from this perspective, instead we only consider a comparatively small time frame but analyse it fully.
In this literature review we discuss used methods, datasets, evaluations and open challenges encountered in all works first released between January 2019 and October 2021. The goal of this survey is to provide a comprehensive and complete overview of current paper recommendation systems.

24 Nov 2022
Representing relevant information of a traffic scene and understanding its environment is crucial for the success of autonomous driving. Modeling the surrounding of an autonomous car using semantic relations, i.e., how different traffic participants relate in the context of traffic rule based behaviors, is hardly been considered in previous work. This stems from the fact that these relations are hard to extract from real-world traffic scenes. In this work, we model traffic scenes in a form of spatial semantic scene graphs for various different predictions about the traffic participants, e.g., acceleration and deceleration. Our learning and inference approach uses Graph Neural Networks (GNNs) and shows that incorporating explicit information about the spatial semantic relations between traffic participants improves the predicdtion results. Specifically, the acceleration prediction of traffic participants is improved by up to 12% compared to the baselines, which do not exploit this explicit information. Furthermore, by including additional information about previous scenes, we achieve 73% improvements.

13 Jun 2025
Extended exposure to virtual reality environments can induce motion sickness,
often referred to as cybersickness, which may lead to physiological stress
responses and impaired cognitive performance. This study investigates the
aftereffects of VR-induced motion sickness with a focus on physiological stress
markers and working memory performance. Using a carousel simulation to elicit
cybersickness, we assessed subjective discomfort (SSQ, FMS), physiological
stress (salivary cortisol, alpha-amylase, electrodermal activity, heart rate),
and cognitive performance (n-Back task) over a 90-minute post-exposure period.
Our findings demonstrate a significant increase in both subjective and
physiological stress indicators following VR exposure, accompanied by a decline
in working memory performance. Notably, delayed symptom progression was
observed in a substantial proportion of participants, with some reporting peak
symptoms up to 90 minutes post-stimulation. Salivary cortisol levels remained
elevated throughout the observation period, indicating prolonged stress
recovery. These results highlight the need for longer washout phases in XR
research and raise safety concerns for professional applications involving
post-exposure task performance.

28 Jun 2024
We say that a (multi)graph has geometric thickness if there
exists a straight-line drawing and a
-coloring of its edges where no two edges sharing a point in their relative
interior have the same color. The \textsc{Geometric Thickness} problem asks
whether a given multigraph has geometric thickness at most . This problem
was shown to be NP-hard for [Durocher, Gethner, and Mondal, CG 2016]. In
this paper, we settle the computational complexity of \textsc{Geometric
Thickness} by showing that it is -complete already for
thickness . Moreover, our reduction shows that the problem is $\exists
\mathbb{R}4392k$-planar if
it admits a topological drawing with at most crossings per edge. In the
course of our paper, we answer previous questions on geometric thickness and on
other related problems, in particular that simultaneous graph embeddings of
edge-disjoint graphs and pseudo-segment stretchability with chromatic
number are -complete.

12 Mar 2025

We provide a correction to the sufficient conditions under which closed-form
expressions for the optimal Lagrange multiplier are provided in
arXiv:2112.13138 [math.OC]. We first present a simple counterexample where the
original conditions are insufficient, highlight where the original proof fails,
and then provide modified conditions along with a correct proof of their
validity. Finally, although the original paper discusses modifications to their
method for problems that may not satisfy any sufficient conditions, we
substantiate that discussion along two directions. We first show that computing
an optimal Lagrange multiplier can still be done in polynomial time. We then
provide complete and correct versions of the corresponding Benders and
column-and-constraint generation algorithms in which the original method is
used. We also discuss the implications of our findings on computational
performance.

15 Jan 2021
The paper motivates high dimensional smoothing with penalized splines and its numerical calculation in an efficient way. If smoothing is carried out over three or more covariates the classical tensor product spline bases explode in their dimension bringing the estimation to its numerical limits. A recent approach by Siebenborn and Wagner(2019) circumvents storage expensive implementations by proposing matrix-free calculations which allows to smooth over several covariates. We extend their approach here by linking penalized smoothing and its Bayesian formulation as mixed model which provides a matrix-free calculation of the smoothing parameter to avoid the use of high-computational cross validation. Further, we show how to extend the ideas towards generalized regression models. The extended approach is applied to remote sensing satellite data in combination with spatial smoothing.

04 Sep 2019
This paper provides a first contribution to port-Hamiltonian modeling of
district heating networks. By introducing a model hierarchy of flow equations
on the network, this work aims at a thermodynamically consistent
port-Hamiltonian embedding of the partial differential-algebraic systems. We
show that a spatially discretized network model describing the advection of the
internal energy density with respect to an underlying incompressible stationary
Euler-type hydrodynamics can be considered as a parameter-dependent
finite-dimensional port-Hamiltonian system. Moreover, we present an
infinite-dimensional port-Hamiltonian formulation for a compressible
instationary thermodynamic fluid flow in a pipe. Based on these first promising
results, we raise open questions and point out research perspectives concerning
structure-preserving discretization, model reduction, and optimization.

20 Oct 2022
Current deep learning methods for object recognition are purely data-driven
and require a large number of training samples to achieve good results. Due to
their sole dependence on image data, these methods tend to fail when confronted
with new environments where even small deviations occur. Human perception,
however, has proven to be significantly more robust to such distribution
shifts. It is assumed that their ability to deal with unknown scenarios is
based on extensive incorporation of contextual knowledge. Context can be based
either on object co-occurrences in a scene or on memory of experience. In
accordance with the human visual cortex which uses context to form different
object representations for a seen image, we propose an approach that enhances
deep learning methods by using external contextual knowledge encoded in a
knowledge graph. Therefore, we extract different contextual views from a
generic knowledge graph, transform the views into vector space and infuse it
into a DNN. We conduct a series of experiments to investigate the impact of
different contextual views on the learned object representations for the same
image dataset. The experimental results provide evidence that the contextual
views influence the image representations in the DNN differently and therefore
lead to different predictions for the same images. We also show that context
helps to strengthen the robustness of object recognition models for
out-of-distribution images, usually occurring in transfer learning tasks or
real-world scenarios.

14 Nov 2024
In this work we propose a general nonmonotone line-search method for nonconvex multi\-objective optimization problems with convex constraints. At the th iteration, the degree of nonmonotonicity is controlled by a vector with nonnegative components. Different choices for lead to different nonmonotone step-size rules. Assuming that the sequence is summable, and that the th objective function has Hölder continuous gradient with smoothness parameter , we show that the proposed method takes no more than iterations to find a -approximate Pareto critical point for a problem with objectives and . In particular, this complexity bound applies to the methods proposed by Drummond and Iusem (Comput. Optim. Appl. 28: 5--29, 2004), by Fazzio and Schuverdt (Optim. Lett. 13: 1365--1379, 2019), and by Mita, Fukuda and Yamashita (J. Glob. Optim. 75: 63--90, 2019). The generality of our approach also allows the development of new methods for multiobjective optimization. As an example, we propose a new nonmonotone step-size rule inspired by the Metropolis criterion. Preliminary numerical results illustrate the benefit of nonmonotone line searches and suggest that our new rule is particularly suitable for multiobjective problems in which at least one of the objectives has many non-global local minimizers.

28 Jun 2018

Contemporary web pages with increasingly sophisticated interfaces rival
traditional desktop applications for interface complexity and are often called
web applications or RIA (Rich Internet Applications). They often require the
execution of JavaScript in a web browser and can call AJAX requests to
dynamically generate the content, reacting to user interaction. From the
automatic data acquisition point of view, thus, it is essential to be able to
correctly render web pages and mimic user actions to obtain relevant data from
the web page content. Briefly, to obtain data through existing Web interfaces
and transform it into structured form, contemporary wrappers should be able to:
1) interact with sophisticated interfaces of web applications; 2) precisely
acquire relevant data; 3) scale with the number of crawled web pages or states
of web application; 4) have an embeddable programming API for integration with
existing web technologies. OXPath is a state-of-the-art technology, which is
compliant with these requirements and demonstrated its efficiency in
comprehensive experiments. OXPath integrates Firefox for correct rendering of
web pages and extends XPath 1.0 for the DOM node selection, interaction, and
extraction. It provides means for converting extracted data into different
formats, such as XML, JSON, CSV, and saving data into relational databases.
This tutorial explains main features of the OXPath language and the setup of
a suitable working environment. The guidelines for using OXPath are provided in
the form of prototypical examples.

18 Feb 2025
We analyze an irreversible investment decision for a project which yields a
flow of future operating profits given by a geometric Brownian motion with
unknown drift. In contrast to similar optimal stopping problems with incomplete
information, the agent's payoff now depends directly on the unknown drift and
not only indirectly through the underlying dynamics. Hence, many standard
arguments are not applicable. Nonetheless, we show that it is optimal to invest
in the project if the current profit level exceeds a threshold depending on the
current belief for the true state of the unknown drift. These thresholds are
described by a boundary function, for which we establish structural properties
like monotonicity and continuity. To prove these, we identify a central class
of stopping times with useful features. Moreover, we characterize the boundary
function as the unique solution of a nonlinear integral equation. Building on
this characterization we compute the boundary function numerically and
investigate the value of information.

05 Mar 2025

We investigate saturated geometric drawings of graphs with geometric
thickness , where no edge can be added without increasing . We establish
lower and upper bounds on the number of edges in such drawings if the vertices
lie in convex position. We also study the more restricted version where edges
are precolored, and for the case for vertices in non-convex position.

10 Mar 2025

A dichotomous ordinal graph consists of an undirected graph with a partition
of the edges into short and long edges. A geometric realization of a
dichotomous ordinal graph in a metric space is a drawing of in
in which every long edge is strictly longer than every short edge. We call a
graph pandichotomous in if admits a geometric realization in
for every partition of its edge set into short and long edges. We exhibit a
very close relationship between the degeneracy of a graph and its
pandichotomic Euclidean or spherical dimension, that is, the smallest dimension
such that is pandichotomous in or the sphere
, respectively. First, every -degenerate graph is
pandichotomous in and and these bounds are
tight for the sphere and for and almost tight for
, for . Second, every -vertex graph that is
pandichotomous in has at most edges, for some absolute
constant \mu<7.23. This shows that the pandichotomic Euclidean dimension of
any graph is linearly tied to its degeneracy and in the special cases $k\in
\{1,2\}$ resolves open problems posed by Alam, Kobourov, Pupyrev, and
Toeniskoetter. Further, we characterize which complete bipartite graphs are
pandichotomous in : These are exactly the with
or and . For general bipartite graphs, we can guarantee
realizations in if the short or the long subgraph is
constrained: namely if the short subgraph is outerplanar or a subgraph of a
rectangular grid, or if the long subgraph forms a caterpillar.
There are no more papers matching your filters at the moment.
