
07 Dec 2025
WisPaper introduces an AI-powered scholar search engine that unifies academic literature discovery, management, and continuous tracking within a single platform. Its core Deep Search component, powered by the WisModel agent, achieved 94.8% semantic similarity in query understanding and 93.70% overall accuracy in paper-criteria matching, demonstrating superior performance over leading commercial LLMs, especially in nuanced judgments.

08 Dec 2025

Researchers from Alibaba Group and Wuhan University developed MUSE, a multimodal search-based framework for lifelong user interest modeling that integrates rich semantic information across both retrieval and fine-grained modeling stages. Deployed in Taobao's display advertising system, MUSE achieved a +12.6% CTR, +5.1% RPM, and +11.4% ROI in online A/B tests.

08 Dec 2025


Inspired by the success of language models (LM), scaling up deep learning recommendation systems (DLRS) has become a recent trend in the community. All previous methods tend to scale up the model parameters during training time. However, how to efficiently utilize and scale up computational resources during test time remains underexplored, which can prove to be a scaling-efficient approach and bring orthogonal improvements in LM domains. The key point in applying test-time scaling to DLRS lies in effectively generating diverse yet meaningful outputs for the same instance. We propose two ways: One is to explore the heterogeneity of different model architectures. The other is to utilize the randomness of model initialization under a homogeneous architecture. The evaluation is conducted across eight models, including both classic and SOTA models, on three benchmarks. Sufficient evidence proves the effectiveness of both solutions. We further prove that under the same inference budget, test-time scaling can outperform parameter scaling. Our test-time scaling can also be seamlessly accelerated with the increase in parallel servers when deployed online, without affecting the inference time on the user side. Code is available.

30 Nov 2025
The ProcessRL-Reasoning framework optimizes generative ranking relevance in the Xiaohongshu search engine, integrating domain-specific criteria and utilizing Stepwise Advantage Masking for efficient process supervision. It achieves over 2.5% higher 5-class accuracy offline and improves online customer engagement by 0.72% and reduces irrelevant results by 0.36% compared to previous BERT-based models.

02 Dec 2025
The emergence of large language models (LLMs) has sparked much interest in creating LLM-based digital populations that can be applied to many applications such as social simulation, crowdsourcing, marketing, and recommendation systems. A digital population can reduce the cost of recruiting human participants and alleviate many concerns related to human subject study. However, research has found that most of the existing works rely solely on LLMs and could not sufficiently capture the accuracy and diversity of a real human population. To address this limitation, we propose CrowdLLM that integrates pretrained LLMs and generative models to enhance the diversity and fidelity of the digital population. We conduct theoretical analysis of CrowdLLM regarding its great potential in creating cost-effective, sufficiently representative, scalable digital populations that can match the quality of a real crowd. Comprehensive experiments are also conducted across multiple domains (e.g., crowdsourcing, voting, user rating) and simulation studies which demonstrate that CrowdLLM achieves promising performance in both accuracy and distributional fidelity to human data.

02 Dec 2025
Recommending matches in a text-rich, dynamic two-sided marketplace presents unique challenges due to evolving content and interaction graphs. We introduce GraphMatch, a new large-scale recommendation framework that fuses pre-trained language models with graph neural networks to overcome these challenges. Unlike prior approaches centered on standalone models, GraphMatch is a comprehensive recipe built on powerful text encoders and GNNs working in tandem. It employs adversarial negative sampling alongside point-in-time subgraph training to learn representations that capture both the fine-grained semantics of evolving text and the time-sensitive structure of the graph. We evaluated extensively on interaction data from Upwork, a leading labor marketplace, at large scale, and discuss our approach towards low-latency inference suitable for real-time use. In our experiments, GraphMatch outperforms language-only and graph-only baselines on matching tasks while being efficient at runtime. These results demonstrate that unifying language and graph representations yields a highly effective solution to text-rich, dynamic two-sided recommendations, bridging the gap between powerful pretrained LMs and large-scale graphs in practice.

27 Nov 2025
In web environments, user preferences are often refined progressively as users move from browsing broad categories to exploring specific items. However, existing generative recommenders overlook this natural refinement process. Generative recommendation formulates next-item prediction as autoregressive generation over tokenized user histories, where each item is represented as a sequence of discrete tokens. Prior models typically fuse heterogeneous attributes such as ID, category, title, and description into a single embedding before quantization, which flattens the inherent semantic hierarchy of items and fails to capture the gradual evolution of user intent during web interactions. To address this limitation, we propose CoFiRec, a novel generative recommendation framework that explicitly incorporates the Coarse-to-Fine nature of item semantics into the tokenization process. Instead of compressing all attributes into a single latent space, CoFiRec decomposes item information into multiple semantic levels, ranging from high-level categories to detailed descriptions and collaborative filtering signals. Based on this design, we introduce the CoFiRec Tokenizer, which tokenizes each level independently while preserving structural order. During autoregressive decoding, the language model is instructed to generate item tokens from coarse to fine, progressively modeling user intent from general interests to specific item-level interests. Experiments across multiple public benchmarks and backbones demonstrate that CoFiRec outperforms existing methods, offering a new perspective for generative recommendation. Theoretically, we prove that structured tokenization leads to lower dissimilarity between generated and ground truth items, supporting its effectiveness in generative recommendation. Our code is available at this https URL.

01 Dec 2025

Multimodal recommendation aims to integrate collaborative signals with heterogeneous content such as visual and textual information, but remains challenged by modality-specific noise, semantic inconsistency, and unstable propagation over user-item graphs. These issues are often exacerbated by naive fusion or shallow modeling strategies, leading to degraded generalization and poor robustness. While recent work has explored the frequency domain as a lens to separate stable from noisy signals, most methods rely on static filtering or reweighting, lacking the ability to reason over spectral structure or adapt to modality-specific reliability. To address these challenges, we propose a Structured Spectral Reasoning (SSR) framework for frequency-aware multimodal recommendation. Our method follows a four-stage pipeline: (i) Decompose graph-based multimodal signals into spectral bands via graph-guided transformations to isolate semantic granularity; (ii) Modulate band-level reliability with spectral band masking, a training-time masking with a prediction-consistency objective that suppresses brittle frequency components; (iii) Fuse complementary frequency cues using hyperspectral reasoning with low-rank cross-band interaction; and (iv) Align modality-specific spectral features via contrastive regularization to promote semantic and structural consistency. Experiments on three real-world benchmarks show consistent gains over strong baselines, particularly under sparse and cold-start settings. Additional analyses indicate that structured spectral modeling improves robustness and provides clearer diagnostics of how different bands contribute to performance.

29 Nov 2025
Modern recommender systems struggle to effectively utilize the rich, yet high-dimensional and noisy, multi-modal features generated by Large Language Models (LLMs). Treating these features as static inputs decouples them from the core recommendation task. We address this limitation with a novel framework built on a key insight: deeply fusing multi-modal and collaborative knowledge for representation denoising. Our unified architecture introduces two primary technical innovations. First, we integrate dimensionality reduction directly into the recommendation model, enabling end-to-end co-training that makes the reduction process aware of the final ranking objective. Second, we introduce a contrastive learning objective that explicitly incorporates the collaborative filtering signal into the latent space. This synergistic process refines raw LLM embeddings, filtering noise while amplifying task-relevant signals. Extensive experiments confirm our method's superior discriminative power, proving that this integrated fusion and denoising strategy is critical for achieving state-of-the-art performance. Our work provides a foundational paradigm for effectively harnessing LLMs in recommender systems.
28 Nov 2025

ByteDance introduces ShoppingComp, a challenging real-world benchmark designed to evaluate large language models (LLMs) as shopping agents. The evaluation reveals a substantial performance gap between state-of-the-art LLMs and human experts, particularly in product retrieval and safety-critical decision-making.

27 Nov 2025
Nowadays, recommendation systems have become crucial to online platforms, shaping user exposure by accurate preference modeling. However, such an exposure strategy can also reinforce users' existing preferences, leading to a notorious phenomenon named filter bubbles. Given its negative effects, such as group polarization, increasing attention has been paid to exploring reasonable measures to filter bubbles. However, most existing evaluation metrics simply measure the diversity of user exposure, failing to distinguish between algorithmic preference modeling and actual information confinement. In view of this, we introduce Bubble Escape Potential (BEP), a behavior-aware measure that quantifies how easily users can escape from filter bubbles. Specifically, BEP leverages a contrastive simulation framework that assigns different behavioral tendencies (e.g., positive vs. negative) to synthetic users and compares the induced exposure patterns. This design enables decoupling the effect of filter bubbles and preference modeling, allowing for more precise diagnosis of bubble severity. We conduct extensive experiments across multiple recommendation models to examine the relationship between predictive accuracy and bubble escape potential across different groups. To the best of our knowledge, our empirical results are the first to quantitatively validate the dilemma between preference modeling and filter bubbles. What's more, we observe a counter-intuitive phenomenon that mild random recommendations are ineffective in alleviating filter bubbles, which can offer a principled foundation for further work in this direction.

25 Nov 2025

Cross-domain Sequential Recommendation (CDSR) has been proposed to enrich user-item interactions by incorporating information from various domains. Despite current progress, the imbalance issue and transition issue hinder further development of CDSR. The former one presents a phenomenon that the interactions in one domain dominate the entire behavior, leading to difficulty in capturing the domain-specific features in the other domain. The latter points to the difficulty in capturing users' cross-domain preferences within the mixed interaction sequence, resulting in poor next-item prediction performance for specific domains. With world knowledge and powerful reasoning ability, Large Language Models (LLMs) partially alleviate the above issues by performing as a generator and an encoder. However, current LLMs-enhanced CDSR methods are still under exploration, which fail to recognize the irrelevant noise and rough profiling problems. Thus, to make peace with the aforementioned challenges, we proposed an LLMs Enhanced Cross-domain Sequential Recommendation with Dual-phase Training ({LLM-EDT}). To address the imbalance issue while introducing less irrelevant noise, we first propose the transferable item augmenter to adaptively generate possible cross-domain behaviors for users. Then, to alleviate the transition issue, we introduce a dual-phase training strategy to empower the domain-specific thread with a domain-shared background. As for the rough profiling problem, we devise a domain-aware profiling module to summarize the user's preference in each domain and adaptively aggregate them to generate comprehensive user profiles. The experiments on three public datasets validate the effectiveness of our proposed LLM-EDT. To ease reproducibility, we have released the detailed code online at {this https URL}.

18 Nov 2025
The LGSID framework introduces a method to imbue Large Language Models (LLMs) with real-world geographic awareness for local-life recommendation systems. It combines reinforcement learning-based LLM alignment with hierarchical geographic item tokenization, demonstrating substantial performance improvements across discriminative and generative recommendation tasks on a Kuaishou industry dataset.

23 Nov 2025
Researchers from The University of Texas at Austin and Netflix developed LLM-based reasoning strategies and fine-tuning methods to address cold-start item recommendations. Their approach achieved significant improvements in content discovery, with the SFT+GRPO hybrid model outperforming Netflix's production ranking system by an additional 8% on the Discovery metric in warm-start scenarios.

21 Nov 2025
RASTP (Representation-Aware Semantic Token Pruning) enhances the training efficiency of generative recommendation systems that use Semantic Identifiers (SIDs) by dynamically pruning less informative semantic tokens. This method achieves a 26.7% reduction in training time while maintaining or slightly improving recommendation performance on real-world Amazon datasets.
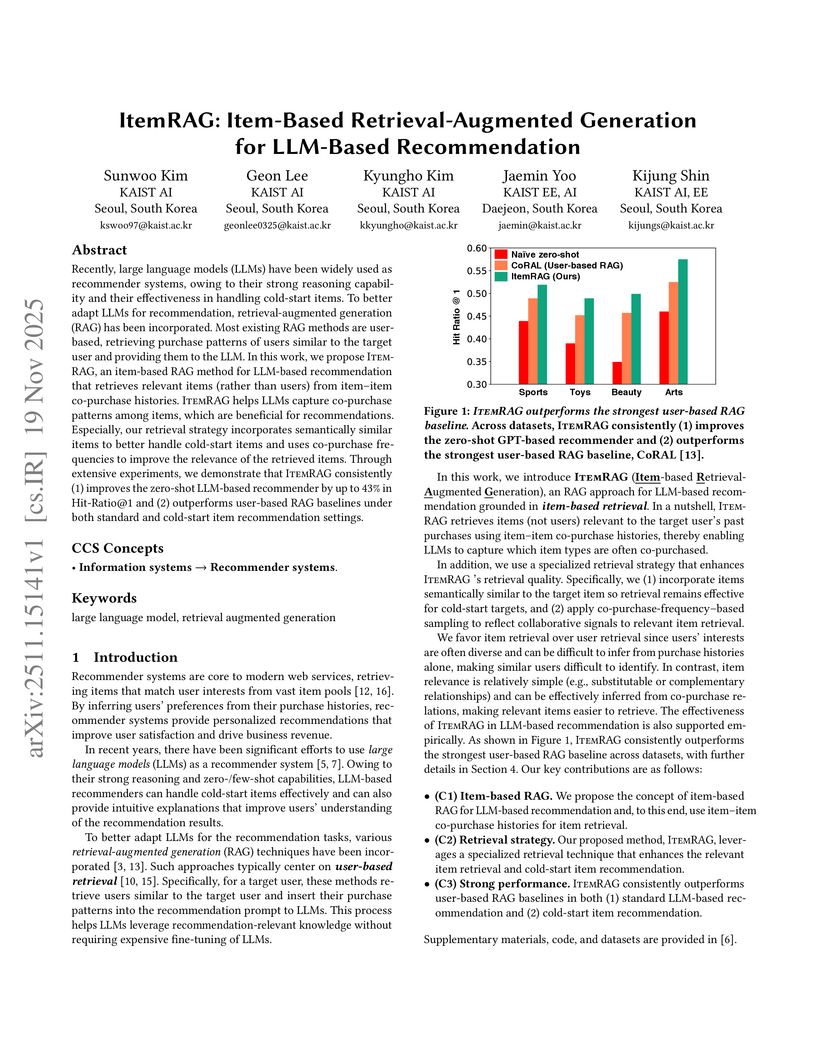
19 Nov 2025
Researchers at KAIST developed ItemRAG, an item-based Retrieval-Augmented Generation framework that enhances LLM-based recommender systems by summarizing co-purchase patterns. The system surpasses existing user-based RAG methods and demonstrates robust performance in cold-start item scenarios, achieving up to a 43% boost in Hit-Ratio@1 over zero-shot LLMs.

18 Nov 2025
Alimama's MOON framework enhances e-commerce search advertising by developing high-quality multimodal representations through a decoupled, three-stage training paradigm utilizing a domain-adapted Multimodal Large Language Model. Deployed across Taobao, it delivered a +20.00% overall online Click-Through Rate improvement, with specific uplifts of +34.80% for new products and +35.74% in the fashion category.

15 Nov 2025
The Field-Aware Transformer (FAT) from Alibaba Group reengineers Transformer architectures for Click-Through Rate prediction by integrating field-specific inductive biases into the attention mechanism. This system achieves up to +0.51% AUC improvement over leading models and demonstrates significant online gains of +2.33% in CTR and +0.66% in RPM during A/B testing on Taobao's sponsored search system.

15 Nov 2025
Generative recommendation has recently emerged as a powerful paradigm that unifies retrieval and generation, representing items as discrete semantic tokens and enabling flexible sequence modeling with autoregressive models. Despite its success, existing approaches rely on a single, uniform codebook to encode all items, overlooking the inherent imbalance between popular items rich in collaborative signals and long-tail items that depend on semantic understanding. We argue that this uniform treatment limits representational efficiency and hinders generalization. To address this, we introduce FlexCode, a popularity-aware framework that adaptively allocates a fixed token budget between a collaborative filtering (CF) codebook and a semantic codebook. A lightweight MoE dynamically balances CF-specific precision and semantic generalization, while an alignment and smoothness objective maintains coherence across the popularity spectrum. We perform experiments on both public and industrial-scale datasets, showing that FlexCode consistently outperform strong baselines. FlexCode provides a new mechanism for token representation in generative recommenders, achieving stronger accuracy and tail robustness, and offering a new perspective on balancing memorization and generalization in token-based recommendation models.

12 Nov 2025
People have different creative writing preferences, and large language models (LLMs) for these tasks can benefit from adapting to each user's preferences. However, these models are often trained over a dataset that considers varying personal tastes as a monolith. To facilitate developing personalized creative writing LLMs, we introduce LiteraryTaste, a dataset of reading preferences from 60 people, where each person: 1) self-reported their reading habits and tastes (stated preference), and 2) annotated their preferences over 100 pairs of short creative writing texts (revealed preference). With our dataset, we found that: 1) people diverge on creative writing preferences, 2) finetuning a transformer encoder could achieve 75.8% and 67.7% accuracy when modeling personal and collective revealed preferences, and 3) stated preferences had limited utility in modeling revealed preferences. With an LLM-driven interpretability pipeline, we analyzed how people's preferences vary. We hope our work serves as a cornerstone for personalizing creative writing technologies.
There are no more papers matching your filters at the moment.
