
08 Dec 2025
This research disentangles the causal effects of pre-training, mid-training, and reinforcement learning (RL) on language model reasoning using a controlled synthetic task framework. It establishes that RL extends reasoning capabilities only under specific conditions of pre-training exposure and data calibration, with mid-training playing a crucial role in bridging training stages and improving generalization.

08 Dec 2025
The Native Parallel Reasoner (NPR) framework allows Large Language Models to autonomously acquire and deploy genuine parallel reasoning capabilities, without relying on external teacher models. Experiments show NPR improves accuracy by up to 24.5% over baselines and delivers up to 4.6 times faster inference, maintaining 100% parallel execution across various benchmarks.

08 Dec 2025
Researchers at OpenAI developed a method to train large language models (LLMs) to self-report their non-compliance or shortcomings through a structured "confession" output. This approach uses a disentangled reward system to incentivize honesty, demonstrating that models confess to undesired behaviors in 74.3% of cases and are more likely to be truthful in confessions than in their primary answers, with minimal impact on main task performance.

09 Dec 2025
TreeGRPO introduces a reinforcement learning framework that reinterprets diffusion model denoising as a sparse search tree, enabling both sample efficiency and precise credit assignment for post-training. This method achieves 2.4 times faster training convergence and enhances alignment quality with human preferences compared to prior approaches.

10 Dec 2025



Researchers from Columbia University and NYU introduced Online World Modeling (OWM) and Adversarial World Modeling (AWM) to mitigate the train-test gap in world models for gradient-based planning (GBP). These methods enabled GBP to achieve performance comparable to or better than search-based planning algorithms like CEM, while simultaneously reducing computation time by an order of magnitude across various robotic tasks.

07 Dec 2025



This research introduces PersonaMem-v2, a dataset designed for implicit user persona learning, and an agentic memory framework, enabling smaller LLMs to achieve state-of-the-art personalization performance. The agentic memory system processes long conversational histories into a compact 2k-token memory, resulting in a 16x efficiency improvement while outperforming frontier models like GPT-5 variants.

09 Dec 2025
OSMO is an open-source tactile glove platform designed to capture both shear and normal forces from human demonstrations, facilitating direct transfer of these skills to robots. Policies trained using OSMO achieved 71.69% success in a wiping task, outperforming vision-only baselines (55.75%) by eliminating contact-related failures.

09 Dec 2025

VALOR, developed at Caltech, presents an annotation-free framework that trains visual reasoners by employing multimodal verifiers to jointly tune an LLM for reasoning and specialized vision tools for visual grounding. This approach achieves superior performance on various visual reasoning benchmarks, including a 6.5% average improvement over direct-answer VLMs on OMNI3D-BENCH.

05 Dec 2025


The EditThinker framework enhances instruction-following in any image editor by introducing an iterative reasoning process. It leverages a Multimodal Large Language Model to critique, reflect, and refine editing instructions, leading to consistent performance gains across diverse benchmarks and excelling in complex reasoning tasks.

07 Dec 2025
Researchers at Southern Methodist University systematically compared various memory encoding and injection methods for transformer-based world models, finding that State-Space Models (SSMs) combined with attention-based injection offer a scalable approach for enhancing long-term recall. This hybrid strategy significantly improved consistency over extended imagination horizons compared to a vanilla Vision Transformer, effectively mitigating perceptual drift.

07 Dec 2025
The Khalasi framework implements an end-to-end reinforcement learning pipeline, enabling autonomous surface vehicles (ASVs) to navigate energy-efficiently in complex, vortical flow fields using only local sensor data. This approach achieves a 43.37% energy saving over baselines and demonstrates robust generalization to unseen synthetic and real-world ocean currents.

09 Dec 2025
Researchers at ETH Zürich used a reinforcement learning agent to investigate how feedback influences skill acquisition in a complex physical fluid system. Their work demonstrated that learning high-performance skills, particularly those involving non-minimum phase dynamics, can require substantially richer sensory information during training than is necessary for their execution.

08 Dec 2025
Despite impressive advances in agent systems, multi-turn tool-use scenarios remain challenging. It is mainly because intent is clarified progressively and the environment evolves with each tool call. While reusing past experience is natural, current LLM agents either treat entire trajectories or pre-defined subtasks as indivisible units, or solely exploit tool-to-tool dependencies, hindering adaptation as states and information evolve across turns. In this paper, we propose a State Integrated Tool Graph (SIT-Graph), which enhances multi-turn tool use by exploiting partially overlapping experience. Inspired by human decision-making that integrates episodic and procedural memory, SIT-Graph captures both compact state representations (episodic-like fragments) and tool-to-tool dependencies (procedural-like routines) from historical trajectories. Specifically, we first build a tool graph from accumulated tool-use sequences, and then augment each edge with a compact state summary of the dialog and tool history that may shape the next action. At inference time, SIT-Graph enables a human-like balance between episodic recall and procedural execution: when the next decision requires recalling prior context, the agent retrieves the state summaries stored on relevant edges and uses them to guide its next action; when the step is routine, it follows high-confidence tool dependencies without explicit recall. Experiments across multiple stateful multi-turn tool-use benchmarks show that SIT-Graph consistently outperforms strong memory- and graph-based baselines, delivering more robust tool selection and more effective experience transfer.

09 Dec 2025
rSIM introduces a multi-agent reinforcement learning framework that enables smaller large language models to acquire advanced reasoning skills by coupling them with a dedicated, learnable planner agent. This method allows models as small as 0.5B parameters to achieve reasoning performance comparable to much larger models across diverse tasks.
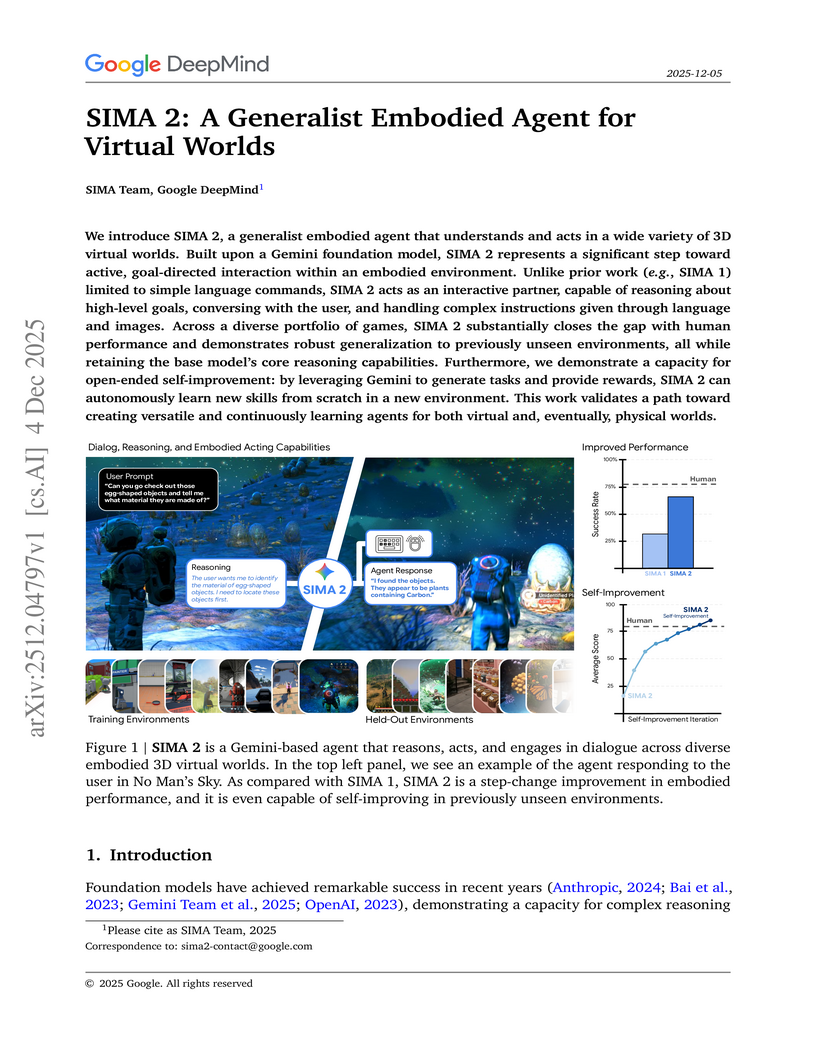
04 Dec 2025

Google DeepMind developed SIMA 2, a generalist embodied agent powered by a Gemini Flash-Lite model, capable of understanding and acting in diverse 3D virtual worlds. It substantially doubles the task success rate of its predecessor SIMA 1, generalizes to unseen commercial games and photorealistic environments, and demonstrates autonomous skill acquisition through a Gemini-based self-improvement mechanism.

10 Dec 2025
Time awareness is a fundamental ability of omni large language models, especially for understanding long videos and answering complex questions. Previous approaches mainly target vision-language scenarios and focus on the explicit temporal grounding questions, such as identifying when a visual event occurs or determining what event happens at aspecific time. However, they often make insufficient use of the audio modality, and overlook implicit temporal grounding across modalities--for example, identifying what is visually present when a character speaks, or determining what is said when a visual event occurs--despite such cross-modal temporal relations being prevalent in real-world scenarios. In this paper, we propose ChronusOmni, an omni large language model designed to enhance temporal awareness for both explicit and implicit audiovisual temporal grounding. First, we interleave text-based timestamp tokens with visual and audio representations at each time unit, enabling unified temporal modeling across modalities. Second, to enforce correct temporal ordering and strengthen fine-grained temporal reasoning, we incorporate reinforcement learning with specially designed reward functions. Moreover, we construct ChronusAV, a temporally-accurate, modality-complete, and cross-modal-aligned dataset to support the training and evaluation on audiovisual temporal grounding task. Experimental results demonstrate that ChronusOmni achieves state-of-the-art performance on ChronusAV with more than 30% improvement and top results on most metrics upon other temporal grounding benchmarks. This highlights the strong temporal awareness of our model across modalities, while preserving general video and audio understanding capabilities.

09 Dec 2025


Large language model (LLM) agents often rely on external demonstrations or retrieval-augmented planning, leading to brittleness, poor generalization, and high computational overhead. Inspired by human problem-solving, we propose DuSAR (Dual-Strategy Agent with Reflecting) - a demonstration-free framework that enables a single frozen LLM to perform co-adaptive reasoning via two complementary strategies: a high-level holistic plan and a context-grounded local policy. These strategies interact through a lightweight reflection mechanism, where the agent continuously assesses progress via a Strategy Fitness Score and dynamically revises its global plan when stuck or refines it upon meaningful advancement, mimicking human metacognitive behavior. On ALFWorld and Mind2Web, DuSAR achieves state-of-the-art performance with open-source LLMs (7B-70B), reaching 37.1% success on ALFWorld (Llama3.1-70B) - more than doubling the best prior result (13.0%) - and 4.02% on Mind2Web, also more than doubling the strongest baseline. Remarkably, it reduces per-step token consumption by 3-9X while maintaining strong performance. Ablation studies confirm the necessity of dual-strategy coordination. Moreover, optional integration of expert demonstrations further boosts results, highlighting DuSAR's flexibility and compatibility with external knowledge.

08 Dec 2025
MAC introduces a model-based offline reinforcement learning approach that uses action chunks and flow-based generative policies to tackle complex, long-horizon tasks. It achieves state-of-the-art performance on challenging manipulation benchmarks, outperforming prior model-based methods and many model-free algorithms.

09 Dec 2025



Mimic2DM is a framework that learns to control physically simulated 3D characters from abundant 2D video data, bypassing explicit 3D reconstruction by formulating motion imitation as a physics-based 2D motion tracking problem. The system enables characters to perform complex human-object interactions and animal locomotion, outperforming two-stage methods and exhibiting implicit 3D understanding from diverse 2D viewpoints.

09 Dec 2025
LLM agents are widely deployed in complex interactive tasks, yet privacy constraints often preclude centralized optimization and co-evolution across dynamic environments. While Federated Learning (FL) has proven effective on static datasets, its extension to the open-ended self-evolution of agents remains underexplored. Directly applying standard FL is challenging: heterogeneous tasks and sparse, trajectory-level rewards introduce severe gradient conflicts, destabilizing the global optimization process. To bridge this gap, we propose Fed-SE, a Federated Self-Evolution framework for LLM agents. Fed-SE establishes a local evolution-global aggregation paradigm. Locally, agents employ parameter-efficient fine-tuning on filtered, high-return trajectories to achieve stable gradient updates. Globally, Fed-SE aggregates updates within a low-rank subspace that disentangles environment-specific dynamics, effectively reducing negative transfer across clients. Experiments across five heterogeneous environments demonstrate that Fed-SE improves average task success rates by approximately 18% over federated baselines, validating its effectiveness in robust cross-environment knowledge transfer in privacy-constrained deployments.
There are no more papers matching your filters at the moment.
