
10 Dec 2025



Researchers from Columbia University and NYU introduced Online World Modeling (OWM) and Adversarial World Modeling (AWM) to mitigate the train-test gap in world models for gradient-based planning (GBP). These methods enabled GBP to achieve performance comparable to or better than search-based planning algorithms like CEM, while simultaneously reducing computation time by an order of magnitude across various robotic tasks.

07 Dec 2025


OXTAL introduces an all-atom diffusion transformer model that generates organic crystal structures directly from a 2D molecular graph, learning both molecular conformations and periodic packing from over 600,000 experimental structures. The method demonstrates competitive accuracy against traditional DFT-based approaches in CCDC blind tests while offering significantly reduced computational inference costs.

08 Dec 2025


WorldReel develops a unified, feed-forward 4D generator that integrates geometry, motion, and appearance directly into a latent diffusion model, yielding videos with explicit 4D scene representations. The model achieves state-of-the-art photorealism and significantly improves geometric consistency and dynamic range, particularly for complex scenes with moving cameras.

10 Dec 2025
The DirectSwap framework and HeadSwapBench dataset were developed for mask-free, expression-consistent video head swapping, achieving state-of-the-art performance in identity fidelity and temporal coherence.

07 Dec 2025



MIND-V introduces a hierarchical video generation framework for long-horizon robotic manipulation, autonomously synthesizing physically plausible and logically coherent operation videos. It employs a multi-stage architecture with reinforcement learning for physical alignment, providing a scalable method for generating robot training data.

10 Dec 2025
OpenSubject introduces a large-scale, video-derived dataset and benchmark for subject-driven image generation and manipulation, designed to provide identity-consistent and diverse visual priors. Fine-tuning models with OpenSubject leads to substantial performance gains, with an open-source baseline model achieving a +1.91 increase in its overall score for multi-subject manipulation tasks on the new OSBench benchmark.

08 Dec 2025

Verifying closed-loop vision-based control systems remains a fundamental challenge due to the high dimensionality of images and the difficulty of modeling visual environments. While generative models are increasingly used as camera surrogates in verification, their reliance on stochastic latent variables introduces unnecessary overapproximation error. To address this bottleneck, we propose a Deterministic World Model (DWM) that maps system states directly to generative images, effectively eliminating uninterpretable latent variables to ensure precise input bounds. The DWM is trained with a dual-objective loss function that combines pixel-level reconstruction accuracy with a control difference loss to maintain behavioral consistency with the real system. We integrate DWM into a verification pipeline utilizing Star-based reachability analysis (StarV) and employ conformal prediction to derive rigorous statistical bounds on the trajectory deviation between the world model and the actual vision-based system. Experiments on standard benchmarks show that our approach yields significantly tighter reachable sets and better verification performance than a latent-variable baseline.

10 Dec 2025
This thesis examines self-attention training through the lens of Optimal Transport (OT) and develops an OT-based alternative for tabular classification. The study tracks intermediate projections of the self-attention layer during training and evaluates their evolution using discrete OT metrics, including Wasserstein distance, Monge gap, optimality, and efficiency. Experiments are conducted on classification tasks with two and three classes, as well as on a biomedical dataset.
Results indicate that the final self-attention mapping often approximates the OT optimal coupling, yet the training trajectory remains inefficient. Pretraining the MLP section on synthetic data partially improves convergence but is sensitive to their initialization. To address these limitations, an OT-based algorithm is introduced: it generates class-specific dummy Gaussian distributions, computes an OT alignment with the data, and trains an MLP to generalize this mapping. The method achieves accuracy comparable to Transformers while reducing computational cost and scaling more efficiently under standardized inputs, though its performance depends on careful dummy-geometry design. All experiments and implementations are conducted in R.
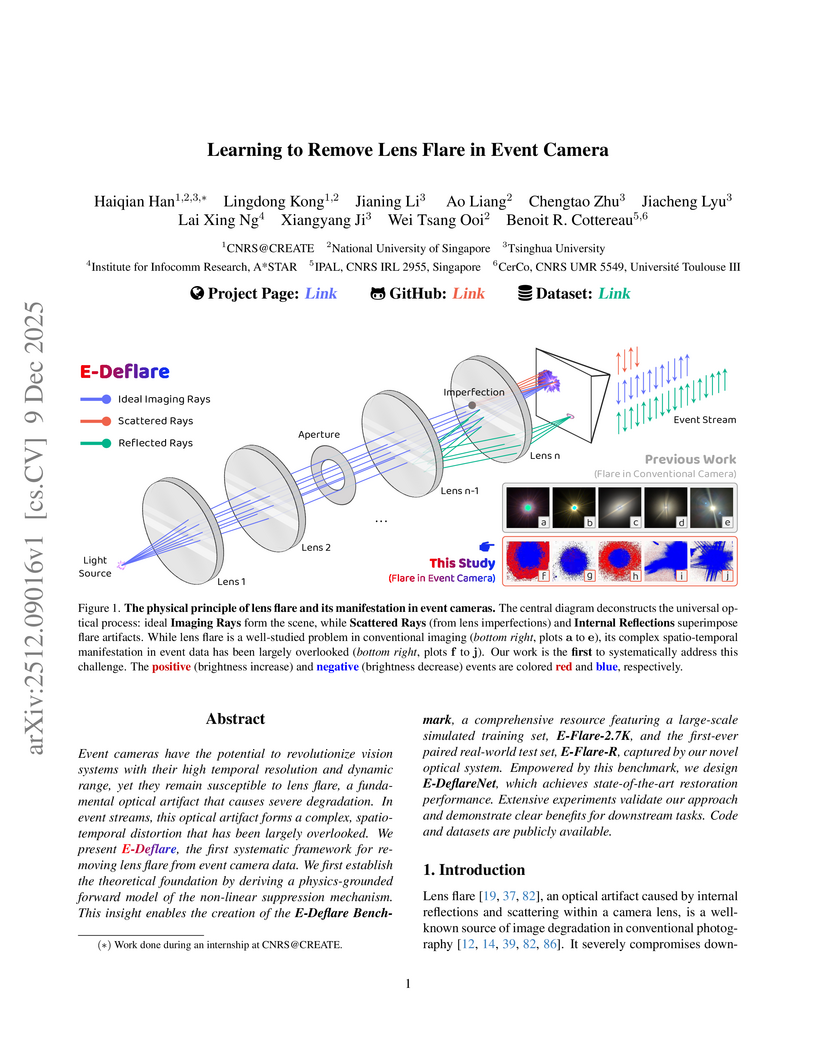
09 Dec 2025


Event cameras have the potential to revolutionize vision systems with their high temporal resolution and dynamic range, yet they remain susceptible to lens flare, a fundamental optical artifact that causes severe degradation. In event streams, this optical artifact forms a complex, spatio-temporal distortion that has been largely overlooked. We present E-Deflare, the first systematic framework for removing lens flare from event camera data. We first establish the theoretical foundation by deriving a physics-grounded forward model of the non-linear suppression mechanism. This insight enables the creation of the E-Deflare Benchmark, a comprehensive resource featuring a large-scale simulated training set, E-Flare-2.7K, and the first-ever paired real-world test set, E-Flare-R, captured by our novel optical system. Empowered by this benchmark, we design E-DeflareNet, which achieves state-of-the-art restoration performance. Extensive experiments validate our approach and demonstrate clear benefits for downstream tasks. Code and datasets are publicly available.

05 Dec 2025

IMAgent introduces an open-source vision agent trained entirely through end-to-end reinforcement learning to excel at complex multi-image tasks. This agent, developed by MeiTuan and USTC, integrates specialized visual tools and achieves state-of-the-art performance by dynamically managing visual attention across multiple images during multi-step reasoning.

09 Dec 2025


Embodied Tree of Thoughts (EToT) integrates Vision-Language Models with a physics-based embodied world model and a tree-structured search to enable deliberative robot manipulation planning. The framework achieves an 88.8% average success rate on complex manipulation tasks by enabling pre-execution failure diagnosis and physically motivated plan revisions within a simulator.

10 Dec 2025
Occlusions in robotic bin picking compromise accurate and reliable grasp planning. We present ViTA-Seg, a class-agnostic Vision Transformer framework for real-time amodal segmentation that leverages global attention to recover complete object masks, including hidden regions. We proposte two architectures: a) Single-Head for amodal mask prediction; b) Dual-Head for amodal and occluded mask prediction. We also introduce ViTA-SimData, a photo-realistic synthetic dataset tailored to industrial bin-picking scenario. Extensive experiments on two amodal benchmarks, COOCA and KINS, demonstrate that ViTA-Seg Dual Head achieves strong amodal and occlusion segmentation accuracy with computational efficiency, enabling robust, real-time robotic manipulation.

09 Dec 2025
We present SDialog, an MIT-licensed open-source Python toolkit that unifies dialog generation, evaluation and mechanistic interpretability into a single end-to-end framework for building and analyzing LLM-based conversational agents. Built around a standardized \texttt{Dialog} representation, SDialog provides: (1) persona-driven multi-agent simulation with composable orchestration for controlled, synthetic dialog generation, (2) comprehensive evaluation combining linguistic metrics, LLM-as-a-judge and functional correctness validators, (3) mechanistic interpretability tools for activation inspection and steering via feature ablation and induction, and (4) audio generation with full acoustic simulation including 3D room modeling and microphone effects. The toolkit integrates with all major LLM backends, enabling mixed-backend experiments under a unified API. By coupling generation, evaluation, and interpretability in a dialog-centric architecture, SDialog enables researchers to build, benchmark and understand conversational systems more systematically.

08 Dec 2025
In controllable image generation, synthesizing coherent and consistent images from multiple reference inputs, i.e., Multi-Image Composition (MICo), remains a challenging problem, partly hindered by the lack of high-quality training data. To bridge this gap, we conduct a systematic study of MICo, categorizing it into 7 representative tasks and curate a large-scale collection of high-quality source images and construct diverse MICo prompts. Leveraging powerful proprietary models, we synthesize a rich amount of balanced composite images, followed by human-in-the-loop filtering and refinement, resulting in MICo-150K, a comprehensive dataset for MICo with identity consistency. We further build a Decomposition-and-Recomposition (De&Re) subset, where 11K real-world complex images are decomposed into components and recomposed, enabling both real and synthetic compositions. To enable comprehensive evaluation, we construct MICo-Bench with 100 cases per task and 300 challenging De&Re cases, and further introduce a new metric, Weighted-Ref-VIEScore, specifically tailored for MICo evaluation. Finally, we fine-tune multiple models on MICo-150K and evaluate them on MICo-Bench. The results show that MICo-150K effectively equips models without MICo capability and further enhances those with existing skills. Notably, our baseline model, Qwen-MICo, fine-tuned from Qwen-Image-Edit, matches Qwen-Image-2509 in 3-image composition while supporting arbitrary multi-image inputs beyond the latter's limitation. Our dataset, benchmark, and baseline collectively offer valuable resources for further research on Multi-Image Composition.

08 Dec 2025
The OMEGA framework introduces a training-free method to enhance diffusion models for multi-agent driving scene generation, significantly boosting scenario realism, structural consistency, and controllability. It achieves a 72.27% valid scene rate on nuPlan, a 39.92 percentage point increase over baselines, and generates 5 times more near-collision frames for adversarial testing while maintaining plausibility.

08 Dec 2025

PrivORL, developed at the University of Virginia, introduces the first method for generating differentially private synthetic datasets for offline reinforcement learning. This framework, utilizing advanced generative models with DP-SGD and a curiosity module, produces synthetic data that enables RL agents to achieve comparable performance to those trained on real data while robustly resisting membership inference attacks, for example, showing normalized returns of 69.3 in Maze2D at "epsilon"=10, close to 78.6 from real data.

09 Dec 2025
Bridging the sim-to-real gap remains a fundamental challenge in robotics, as accurate dynamic parameter estimation is essential for reliable model-based control, realistic simulation, and safe deployment of manipulators. Traditional analytical approaches often fall short when faced with complex robot structures and interactions. Data-driven methods offer a promising alternative, yet conventional neural networks such as recurrent models struggle to capture long-range dependencies critical for accurate estimation. In this study, we propose a Transformer-based approach for dynamic parameter estimation, supported by an automated pipeline that generates diverse robot models and enriched trajectory data using Jacobian-derived features. The dataset consists of 8,192 robots with varied inertial and frictional properties. Leveraging attention mechanisms, our model effectively captures both temporal and spatial dependencies. Experimental results highlight the influence of sequence length, sampling rate, and architecture, with the best configuration (sequence length 64, 64 Hz, four layers, 32 heads) achieving a validation R2 of 0.8633. Mass and inertia are estimated with near-perfect accuracy, Coulomb friction with moderate-to-high accuracy, while viscous friction and distal link center-of-mass remain more challenging. These results demonstrate that combining Transformers with automated dataset generation and kinematic enrichment enables scalable, accurate dynamic parameter estimation, contributing to improved sim-to-real transfer in robotic systems

09 Dec 2025

The growing prevalence of artificial intelligence (AI) in various applications underscores the need for agents that can successfully navigate and adapt to an ever-changing, open-ended world. A key challenge is ensuring these AI agents are robust, excelling not only in familiar settings observed during training but also effectively generalising to previously unseen and varied scenarios. In this thesis, we harness methodologies from open-endedness and multi-agent learning to train and evaluate robust AI agents capable of generalising to novel environments, out-of-distribution inputs, and interactions with other co-player agents. We begin by introducing MiniHack, a sandbox framework for creating diverse environments through procedural content generation. Based on the game of NetHack, MiniHack enables the construction of new tasks for reinforcement learning (RL) agents with a focus on generalisation. We then present Maestro, a novel approach for generating adversarial curricula that progressively enhance the robustness and generality of RL agents in two-player zero-sum games. We further probe robustness in multi-agent domains, utilising quality-diversity methods to systematically identify vulnerabilities in state-of-the-art, pre-trained RL policies within the complex video game football domain, characterised by intertwined cooperative and competitive dynamics. Finally, we extend our exploration of robustness to the domain of LLMs. Here, our focus is on diagnosing and enhancing the robustness of LLMs against adversarial prompts, employing evolutionary search to generate a diverse range of effective inputs that aim to elicit undesirable outputs from an LLM. This work collectively paves the way for future advancements in AI robustness, enabling the development of agents that not only adapt to an ever-evolving world but also thrive in the face of unforeseen challenges and interactions.

10 Dec 2025
Class-agnostic 3D instance segmentation tackles the challenging task of segmenting all object instances, including previously unseen ones, without semantic class reliance. Current methods struggle with generalization due to the scarce annotated 3D scene data or noisy 2D segmentations. While synthetic data generation offers a promising solution, existing 3D scene synthesis methods fail to simultaneously satisfy geometry diversity, context complexity, and layout reasonability, each essential for this task. To address these needs, we propose an Adapted 3D Scene Synthesis pipeline for class-agnostic 3D Instance SegmenTation, termed as ASSIST-3D, to synthesize proper data for model generalization enhancement. Specifically, ASSIST-3D features three key innovations, including 1) Heterogeneous Object Selection from extensive 3D CAD asset collections, incorporating randomness in object sampling to maximize geometric and contextual diversity; 2) Scene Layout Generation through LLM-guided spatial reasoning combined with depth-first search for reasonable object placements; and 3) Realistic Point Cloud Construction via multi-view RGB-D image rendering and fusion from the synthetic scenes, closely mimicking real-world sensor data acquisition. Experiments on ScanNetV2, ScanNet++, and S3DIS benchmarks demonstrate that models trained with ASSIST-3D-generated data significantly outperform existing methods. Further comparisons underscore the superiority of our purpose-built pipeline over existing 3D scene synthesis approaches.

10 Dec 2025
We describe SynthPix, a synthetic image generator for Particle Image Velocimetry (PIV) with a focus on performance and parallelism on accelerators, implemented in JAX. SynthPix supports the same configuration parameters as existing tools but achieves a throughput several orders of magnitude higher in image-pair generation per second. SynthPix was developed to enable the training of data-hungry reinforcement learning methods for flow estimation and for reducing the iteration times during the development of fast flow estimation methods used in recent active fluids control studies with real-time PIV feedback. We believe SynthPix to be useful for the fluid dynamics community, and in this paper we describe the main ideas behind this software package.
There are no more papers matching your filters at the moment.
