
05 Jun 2024

Researchers from a collaborative network across Singapore and Taiwan introduced the first application of dataset distillation to speech processing for Speech Emotion Recognition. Their generative model condenses large speech datasets, reducing storage by up to 97% and downstream training time by 95%, while achieving comparable or superior performance, particularly by mitigating data-label imbalance and implicitly enhancing privacy.
15 Apr 2025

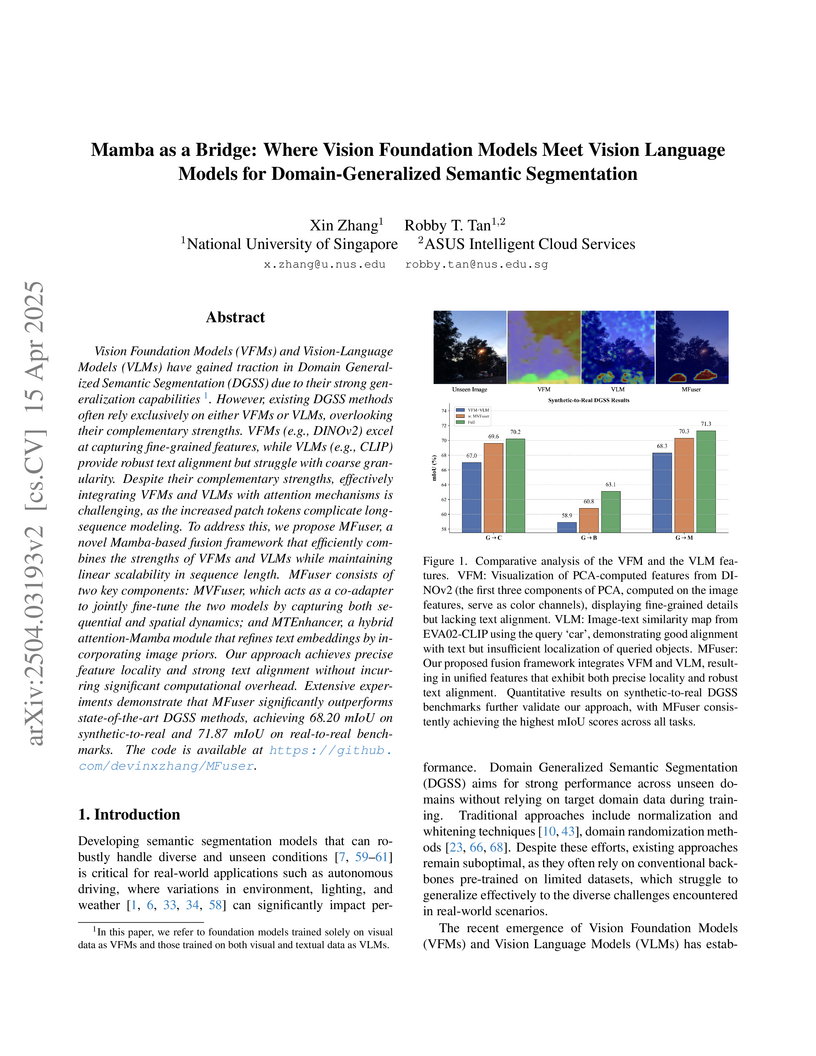
This research from the Robby Tan Vision Group at NUS introduces MFuser, a Mamba-based architecture that integrates Vision Foundation Models and Vision-Language Models to improve domain generalization in semantic segmentation. The framework efficiently fuses complementary features from these large pre-trained models using novel Mamba-based components, achieving improvements of over 2 mIoU on synthetic-to-real benchmarks and demonstrating superior efficiency compared to attention-based fusion methods.

06 Nov 2024
Various audio-LLMs (ALLMs) have been explored recently for tackling different audio tasks simultaneously using a single, unified model. While existing evaluations of ALLMs primarily focus on single-audio tasks, real-world applications often involve processing multiple audio streams simultaneously. To bridge this gap, we propose the first multi-audio evaluation (MAE) benchmark that consists of 20 datasets from 11 multi-audio tasks encompassing both speech and sound scenarios. Comprehensive experiments on MAE demonstrate that the existing ALLMs, while being powerful in comprehending primary audio elements in individual audio inputs, struggling to handle multi-audio scenarios. To this end, we propose a novel multi-audio-LLM (MALLM) to capture audio context among multiple similar audios using discriminative learning on our proposed synthetic data. The results demonstrate that the proposed MALLM outperforms all baselines and achieves high data efficiency using synthetic data without requiring human annotations. The proposed MALLM opens the door for ALLMs towards multi-audio processing era and brings us closer to replicating human auditory capabilities in machines.

27 Aug 2024
Vision-language models (VLMs) have shown impressive zero- and few-shot performance on real-world visual question answering (VQA) benchmarks, alluding to their capabilities as visual reasoning engines. However, the benchmarks being used conflate "pure" visual reasoning with world knowledge, and also have questions that involve a limited number of reasoning steps. Thus, it remains unclear whether a VLM's apparent visual reasoning performance is due to its world knowledge, or due to actual visual reasoning capabilities.
To clarify this ambiguity, we systematically benchmark and dissect the zero-shot visual reasoning capabilities of VLMs through synthetic datasets that require minimal world knowledge, and allow for analysis over a broad range of reasoning steps. We focus on two novel aspects of zero-shot visual reasoning: i) evaluating the impact of conveying scene information as either visual embeddings or purely textual scene descriptions to the underlying large language model (LLM) of the VLM, and ii) comparing the effectiveness of chain-of-thought prompting to standard prompting for zero-shot visual reasoning.
We find that the underlying LLMs, when provided textual scene descriptions, consistently perform better compared to being provided visual embeddings. In particular, 18% higher accuracy is achieved on the PTR dataset. We also find that CoT prompting performs marginally better than standard prompting only for the comparatively large GPT-3.5-Turbo (175B) model, and does worse for smaller-scale models. This suggests the emergence of CoT abilities for visual reasoning in LLMs at larger scales even when world knowledge is limited. Overall, we find limitations in the abilities of VLMs and LLMs for more complex visual reasoning, and highlight the important role that LLMs can play in visual reasoning.

07 Jun 2024
Self-supervised learning (SSL) speech models have achieved remarkable performance in various tasks, yet the biased outcomes, especially affecting marginalized groups, raise significant concerns. Social bias refers to the phenomenon where algorithms potentially amplify disparate properties between social groups present in the data used for training. Bias in SSL models can perpetuate injustice by automating discriminatory patterns and reinforcing inequitable systems. This work reveals that prevalent SSL models inadvertently acquire biased associations. We probe how various factors, such as model architecture, size, and training methodologies, influence the propagation of social bias within these models. Finally, we explore the efficacy of debiasing SSL models through regularization techniques, specifically via model compression. Our findings reveal that employing techniques such as row-pruning and training wider, shallower models can effectively mitigate social bias within SSL model.

28 Mar 2024
Domain adaptive object detection aims to adapt detection models to domains where annotated data is unavailable. Existing methods have been proposed to address the domain gap using the semi-supervised student-teacher framework. However, a fundamental issue arises from the class imbalance in the labelled training set, which can result in inaccurate pseudo-labels. The relationship between classes, especially where one class is a majority and the other minority, has a large impact on class bias. We propose Class-Aware Teacher (CAT) to address the class bias issue in the domain adaptation setting. In our work, we approximate the class relationships with our Inter-Class Relation module (ICRm) and exploit it to reduce the bias within the model. In this way, we are able to apply augmentations to highly related classes, both inter- and intra-domain, to boost the performance of minority classes while having minimal impact on majority classes. We further reduce the bias by implementing a class-relation weight to our classification loss. Experiments conducted on various datasets and ablation studies show that our method is able to address the class bias in the domain adaptation setting. On the Cityscapes to Foggy Cityscapes dataset, we attained a 52.5 mAP, a substantial improvement over the 51.2 mAP achieved by the state-of-the-art method.
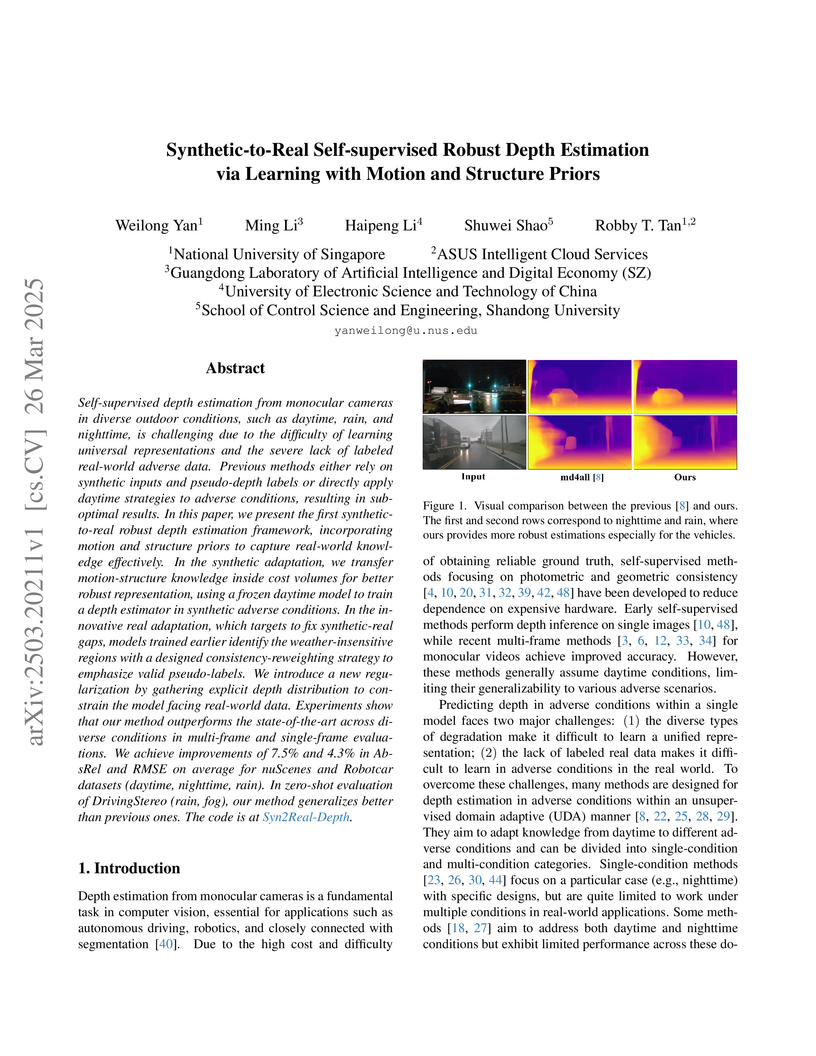
26 Mar 2025

Self-supervised depth estimation from monocular cameras in diverse outdoor
conditions, such as daytime, rain, and nighttime, is challenging due to the
difficulty of learning universal representations and the severe lack of labeled
real-world adverse data. Previous methods either rely on synthetic inputs and
pseudo-depth labels or directly apply daytime strategies to adverse conditions,
resulting in suboptimal results. In this paper, we present the first
synthetic-to-real robust depth estimation framework, incorporating motion and
structure priors to capture real-world knowledge effectively. In the synthetic
adaptation, we transfer motion-structure knowledge inside cost volumes for
better robust representation, using a frozen daytime model to train a depth
estimator in synthetic adverse conditions. In the innovative real adaptation,
which targets to fix synthetic-real gaps, models trained earlier identify the
weather-insensitive regions with a designed consistency-reweighting strategy to
emphasize valid pseudo-labels. We introduce a new regularization by gathering
explicit depth distributions to constrain the model when facing real-world
data. Experiments show that our method outperforms the state-of-the-art across
diverse conditions in multi-frame and single-frame evaluations. We achieve
improvements of 7.5% and 4.3% in AbsRel and RMSE on average for nuScenes and
Robotcar datasets (daytime, nighttime, rain). In zero-shot evaluation of
DrivingStereo (rain, fog), our method generalizes better than the previous
ones.

02 Oct 2024
The automatic evaluation of natural language generation (NLG) systems
presents a long-lasting challenge. Recent studies have highlighted various
neural metrics that align well with human evaluations. Yet, the robustness of
these evaluators against adversarial perturbations remains largely
under-explored due to the unique challenges in obtaining adversarial data for
different NLG evaluation tasks. To address the problem, we introduce AdvEval, a
novel black-box adversarial framework against NLG evaluators. AdvEval is
specially tailored to generate data that yield strong disagreements between
human and victim evaluators. Specifically, inspired by the recent success of
large language models (LLMs) in text generation and evaluation, we adopt strong
LLMs as both the data generator and gold evaluator. Adversarial data are
automatically optimized with feedback from the gold and victim evaluator. We
conduct experiments on 12 victim evaluators and 11 NLG datasets, spanning tasks
including dialogue, summarization, and question evaluation. The results show
that AdvEval can lead to significant performance degradation of various victim
metrics, thereby validating its efficacy.

12 Jun 2023

Large-scale pre-trained language models such as BERT are popular solutions
for text classification. Due to the superior performance of these advanced
methods, nowadays, people often directly train them for a few epochs and deploy
the obtained model. In this opinion paper, we point out that this way may only
sometimes get satisfactory results. We argue the importance of running a simple
baseline like linear classifiers on bag-of-words features along with advanced
methods. First, for many text data, linear methods show competitive
performance, high efficiency, and robustness. Second, advanced models such as
BERT may only achieve the best results if properly applied. Simple baselines
help to confirm whether the results of advanced models are acceptable. Our
experimental results fully support these points.

16 Sep 2024

This research explores how the information of prompts interacts with the
high-performing speech recognition model, Whisper. We compare its performances
when prompted by prompts with correct information and those corrupted with
incorrect information. Our results unexpectedly show that Whisper may not
understand the textual prompts in a human-expected way. Additionally, we find
that performance improvement is not guaranteed even with stronger adherence to
the topic information in textual prompts. It is also noted that English prompts
generally outperform Mandarin ones on datasets of both languages, likely due to
differences in training data distributions for these languages despite the
mismatch with pre-training scenarios. Conversely, we discover that Whisper
exhibits awareness of misleading information in language tokens by ignoring
incorrect language tokens and focusing on the correct ones. In sum, We raise
insightful questions about Whisper's prompt understanding and reveal its
counter-intuitive behaviors. We encourage further studies.

18 Mar 2024

We introduce a new zero resource code-switched speech benchmark designed to directly assess the code-switching capabilities of self-supervised speech encoders. We showcase a baseline system of language modeling on discrete units to demonstrate how the code-switching abilities of speech encoders can be assessed in a zero-resource manner. Our experiments encompass a variety of well-known speech encoders, including Wav2vec 2.0, HuBERT, XLSR, etc. We examine the impact of pre-training languages and model size on benchmark performance. Notably, though our results demonstrate that speech encoders with multilingual pre-training, exemplified by XLSR, outperform monolingual variants (Wav2vec 2.0, HuBERT) in code-switching scenarios, there is still substantial room for improvement in their code-switching linguistic abilities.

29 May 2023
There are significant challenges for speaker adaptation in text-to-speech for languages that are not widely spoken or for speakers with accents or dialects that are not well-represented in the training data. To address this issue, we propose the use of the "mixture of adapters" method. This approach involves adding multiple adapters within a backbone-model layer to learn the unique characteristics of different speakers. Our approach outperforms the baseline, with a noticeable improvement of 5% observed in speaker preference tests when using only one minute of data for each new speaker. Moreover, following the adapter paradigm, we fine-tune only the adapter parameters (11% of the total model parameters). This is a significant achievement in parameter-efficient speaker adaptation, and one of the first models of its kind. Overall, our proposed approach offers a promising solution to the speech synthesis techniques, particularly for adapting to speakers from diverse backgrounds.

16 Aug 2019
Person re-identification (re-ID) aims at matching images of the same identity
across camera views. Due to varying distances between cameras and persons of
interest, resolution mismatch can be expected, which would degrade person re-ID
performance in real-world scenarios. To overcome this problem, we propose a
novel generative adversarial network to address cross-resolution person re-ID,
allowing query images with varying resolutions. By advancing adversarial
learning techniques, our proposed model learns resolution-invariant image
representations while being able to recover the missing details in
low-resolution input images. The resulting features can be jointly applied for
improving person re-ID performance due to preserving resolution invariance and
recovering re-ID oriented discriminative details. Our experiments on five
benchmark datasets confirm the effectiveness of our approach and its
superiority over the state-of-the-art methods, especially when the input
resolutions are unseen during training.

20 Sep 2019
Person re-identification (re-ID) aims at recognizing the same person from
images taken across different cameras. To address this challenging task,
existing re-ID models typically rely on a large amount of labeled training
data, which is not practical for real-world applications. To alleviate this
limitation, researchers now targets at cross-dataset re-ID which focuses on
generalizing the discriminative ability to the unlabeled target domain when
given a labeled source domain dataset. To achieve this goal, our proposed Pose
Disentanglement and Adaptation Network (PDA-Net) aims at learning deep image
representation with pose and domain information properly disentangled. With the
learned cross-domain pose invariant feature space, our proposed PDA-Net is able
to perform pose disentanglement across domains without supervision in
identities, and the resulting features can be applied to cross-dataset re-ID.
Both of our qualitative and quantitative results on two benchmark datasets
confirm the effectiveness of our approach and its superiority over the
state-of-the-art cross-dataset Re-ID approaches.

31 Mar 2020

Single image dehazing is the ill-posed two-dimensional signal reconstruction
problem. Recently, deep convolutional neural networks (CNN) have been
successfully used in many computer vision problems. In this paper, we propose a
Y-net that is named for its structure. This network reconstructs clear images
by aggregating multi-scale features maps. Additionally, we propose a Wavelet
Structure SIMilarity (W-SSIM) loss function in the training step. In the
proposed loss function, discrete wavelet transforms are applied repeatedly to
divide the image into differently sized patches with different frequencies and
scales. The proposed loss function is the accumulation of SSIM loss of various
patches with respective ratios. Extensive experimental results demonstrate that
the proposed Y-net with the W-SSIM loss function restores high-quality clear
images and outperforms state-of-the-art algorithms. Code and models are
available at this https URL

17 Jul 2020
Single image deraining is a crucial problem because rain severely degenerates
the visibility of images and affects the performance of computer vision tasks
like outdoor surveillance systems and intelligent vehicles. In this paper, we
propose the new convolutional neural network (CNN) called the wavelet channel
attention module with a fusion network. Wavelet transform and the inverse
wavelet transform are substituted for down-sampling and up-sampling so feature
maps from the wavelet transform and convolutions contain different frequencies
and scales. Furthermore, feature maps are integrated by channel attention. Our
proposed network learns confidence maps of four sub-band images derived from
the wavelet transform of the original images. Finally, the clear image can be
well restored via the wavelet reconstruction and fusion of the low-frequency
part and high-frequency parts. Several experimental results on synthetic and
real images present that the proposed algorithm outperforms state-of-the-art
methods.

25 Aug 2020
To address semi-supervised learning from both labeled and unlabeled data, we
present a novel meta-learning scheme. We particularly consider that labeled and
unlabeled data share disjoint ground truth label sets, which can be seen tasks
like in person re-identification or image retrieval. Our learning scheme
exploits the idea of leveraging information from labeled to unlabeled data.
Instead of fitting the associated class-wise similarity scores as most
meta-learning algorithms do, we propose to derive semantics-oriented similarity
representations from labeled data, and transfer such representation to
unlabeled ones. Thus, our strategy can be viewed as a self-supervised learning
scheme, which can be applied to fully supervised learning tasks for improved
performance. Our experiments on various tasks and settings confirm the
effectiveness of our proposed approach and its superiority over the
state-of-the-art methods.

25 Feb 2023
Distilled self-supervised models have shown competitive performance and efficiency in recent years. However, there is a lack of experience in jointly distilling multiple self-supervised speech models. In our work, we performed Ensemble Knowledge Distillation (EKD) on various self-supervised speech models such as HuBERT, RobustHuBERT, and WavLM. We tried two different aggregation techniques, layerwise-average and layerwise-concatenation, to the representations of different teacher models and found that the former was more effective. On top of that, we proposed a multiple prediction head method for student models to predict different layer outputs of multiple teacher models simultaneously. The experimental results show that our method improves the performance of the distilled models on four downstream speech processing tasks, Phoneme Recognition, Speaker Identification, Emotion Recognition, and Automatic Speech Recognition in the hidden-set track of the SUPERB benchmark.

06 Jun 2024

There is vivid research on adapting Large Language Models (LLMs) to perform a variety of tasks in high-stakes domains such as healthcare. Despite their popularity, there is a lack of understanding of the extent and contributing factors that allow LLMs to recall relevant knowledge and combine it with presented information in the clinical and biomedical domain: a fundamental pre-requisite for success on down-stream tasks. Addressing this gap, we use Multiple Choice and Abstractive Question Answering to conduct a large-scale empirical study on 22 datasets in three generalist and three specialist biomedical sub-domains. Our multifaceted analysis of the performance of 15 LLMs, further broken down by sub-domain, source of knowledge and model architecture, uncovers success factors such as instruction tuning that lead to improved recall and comprehension. We further show that while recently proposed domain-adapted models may lack adequate knowledge, directly fine-tuning on our collected medical knowledge datasets shows encouraging results, even generalising to unseen specialist sub-domains. We complement the quantitative results with a skill-oriented manual error analysis, which reveals a significant gap between the models' capabilities to simply recall necessary knowledge and to integrate it with the presented context. To foster research and collaboration in this field we share M-QALM, our resources, standardised methodology, and evaluation results, with the research community to facilitate further advancements in clinical knowledge representation learning within language models.

24 Dec 2023
Computerised clinical coding approaches aim to automate the process of assigning a set of codes to medical records. While there is active research pushing the state of the art on clinical coding for hospitalized patients, the outpatient setting -- where doctors tend to non-hospitalised patients -- is overlooked. Although both settings can be formalised as a multi-label classification task, they present unique and distinct challenges, which raises the question of whether the success of inpatient clinical coding approaches translates to the outpatient setting. This paper is the first to investigate how well state-of-the-art deep learning-based clinical coding approaches work in the outpatient setting at hospital scale. To this end, we collect a large outpatient dataset comprising over 7 million notes documenting over half a million patients. We adapt four state-of-the-art clinical coding approaches to this setting and evaluate their potential to assist coders. We find evidence that clinical coding in outpatient settings can benefit from more innovations in popular inpatient coding benchmarks. A deeper analysis of the factors contributing to the success -- amount and form of data and choice of document representation -- reveals the presence of easy-to-solve examples, the coding of which can be completely automated with a low error rate.
There are no more papers matching your filters at the moment.
