22 Aug 2025



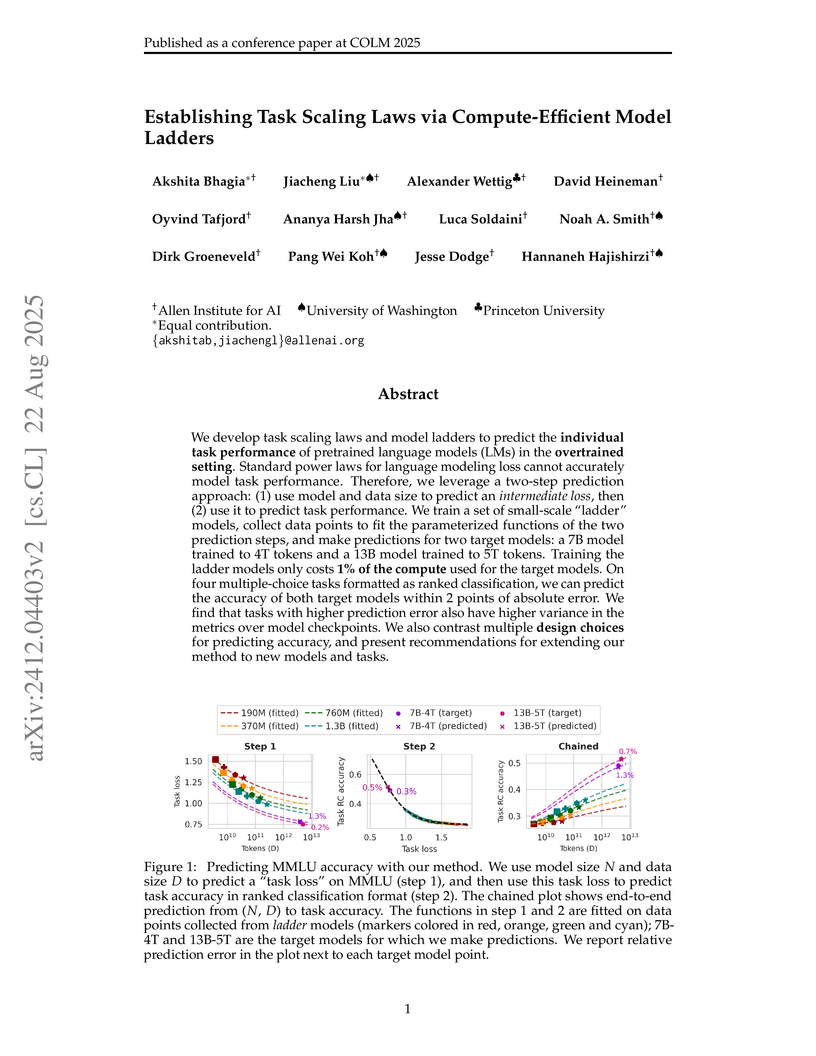
Researchers from the Allen Institute for AI, University of Washington, and Princeton University developed a compute-efficient method to predict the individual downstream task performance of large language models, specifically in the overtrained setting. Their two-step approach, using a small set of 'ladder models' and predicting intermediate task loss, accurately forecasted the accuracy of 7B and 13B models within 2 points of absolute error on four out of eight tasks while using less than 1% of the target models' compute.

09 May 2016


YOLO introduced a unified convolutional neural network that directly predicts bounding boxes and class probabilities from full images in a single evaluation. This approach achieved real-time object detection at speeds up to 155 FPS, enabling live video processing.

27 Oct 2025


Researchers from the University of Washington and collaborators characterized an "Artificial Hivemind" effect in large language models, where models exhibit significant intra-model repetition and inter-model homogeneity across open-ended queries. The study, utilizing a new `INFINITY-CHAT` dataset, also found that current AI evaluation systems are poorly calibrated to capture diverse human preferences for such nuanced, open-ended content.

25 May 2023




SELF-REFINE enables a single large language model to iteratively refine its own outputs by generating self-feedback and then using that feedback to improve the generation. This approach led to an average absolute performance improvement of approximately 20% across seven diverse generative tasks, consistently outperforming one-step generation and a multiple-sample baseline.
02 Dec 2020
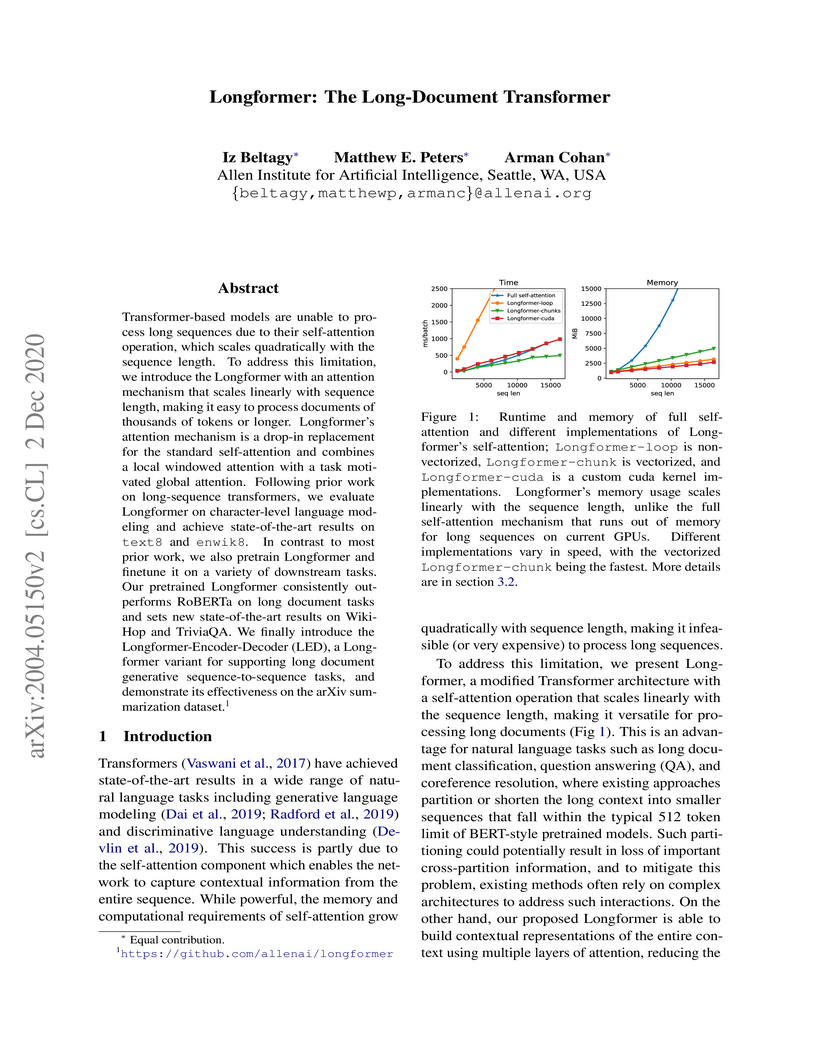
Longformer introduces an efficient, sparse attention mechanism that scales linearly with sequence length, allowing Transformer models to process documents up to 16,000 tokens long. This approach, developed by researchers at the Allen Institute for Artificial Intelligence, establishes new state-of-the-art results across various long-document NLP tasks like question answering and summarization.

12 Jun 2025

This study demonstrates that Reinforcement Learning with Verifiable Rewards (RLVR) can significantly improve mathematical reasoning in Qwen models even when using "spurious" reward signals, challenging the necessity of high-quality, task-specific rewards. It further reveals that these gains are highly dependent on the base model's pretraining and do not generalize to other LLM architectures.

11 Nov 2025
Large Language Models frequently overfit existing instruction-following benchmarks, struggling to generalize to new, verifiable constraints. Researchers from AI2 and the University of Washington developed IFBENCH, a new out-of-domain benchmark, and IF-RLVR, a reinforcement learning method, which collectively enhance generalization for precise instruction following by 17-26 percentage points on the new benchmark.

29 Apr 2025


Researchers from Meta FAIR and multiple universities introduce ReasonIR, a retrieval system trained on synthetically generated reasoning-intensive queries that achieves state-of-the-art performance on the BRIGHT benchmark while demonstrating superior scaling with query length and improved RAG performance on MMLU and GPQA tasks.

08 Jun 2024

RewardBench introduces a comprehensive benchmark and toolkit for evaluating reward models, which are central to aligning large language models via Reinforcement Learning from Human Feedback (RLHF). The benchmark reveals top-performing models like RLHFlow/ArmoRM-Llama3-8B-v0.1 (89.0% accuracy) and highlights critical limitations in current RM generalization and safety behaviors.

19 May 2019
HellaSwag introduces a challenging new benchmark dataset for commonsense natural language inference, designed to re-evaluate the true capabilities of large pre-trained language models. While humans achieve 95.6% accuracy, state-of-the-art models like BERT-Large score only 47.3%, revealing a significant gap between current AI and human-level commonsense reasoning.

02 Jun 2025

Researchers from Allen Institute for AI, University of Washington, and Cohere develop REWARDBENCH2, a challenging 1,865-prompt benchmark for evaluating reward models using unseen human queries from WildChat, achieving stronger downstream correlation (0.87 Pearson with Best-of-N sampling) while revealing that models score 20+ points lower than on previous benchmarks, with a novel best-of-4 format across six domains including new "Ties" and "Precise Instruction Following" categories that expose critical gaps in current reward models, while discovering that policy-reward model alignment matters more than raw benchmark scores for RLHF success and that multi-epoch training can improve performance contrary to established practices.

27 Aug 2025

A survey charts the recent trajectory of Compositional Visual Reasoning (CVR) from 2023 to 2025, introducing a five-stage taxonomy to explain its evolution and distinct advantages over monolithic approaches. The work systematically reviews over 260 papers, identifying key benefits such as enhanced interpretability and robustness, while also outlining persistent open challenges and future research directions for the field.

23 May 2024


The Allen Institute for AI, University of Waterloo, University of Washington, and Harvard University introduce Stepwise Internalization, a training method that enables language models to solve complex reasoning tasks like multi-digit multiplication and grade-school math problems without generating explicit intermediate steps. This approach internalizes reasoning, achieving high accuracy with improved computational efficiency and offering a configurable balance between speed and performance.

14 Feb 2020
Researchers from the University of Washington and AI2 identified the causes of text degeneration in neural language models, attributing issues to both maximization-based decoding and pure sampling. They developed Nucleus Sampling, a dynamic decoding strategy shown to produce text with perplexity, diversity, and repetition rates closely aligned with human language, outperforming prior methods on combined human-statistical evaluations.

02 May 2024


WILDCHAT introduces a comprehensive dataset of over 1 million real-world user conversations with ChatGPT, collected from public interfaces. This dataset provides diverse, authentic interactions across multiple languages and use cases, enabling research into user behavior, model alignment, and toxicity detection in large language models.

07 Jun 2024


The Allen Institute for Artificial Intelligence (AI2) developed OLMo, a competitive open-source language model released with its complete training data, code, intermediate checkpoints, and logs. This initiative aims to foster transparency and reproducibility in LLM research, with the 7B parameter model achieving an average accuracy of 69.3% on commonsense reasoning tasks, comparable to Llama 2 7B.

12 May 2025


Researchers critically examine Chatbot Arena, revealing systemic biases in its ranking system that stem from undisclosed private testing, unequal data access for proprietary models, and inconsistent deprecation policies. Their analysis shows these issues inflate scores and hinder generalizable progress, with findings supported by simulations and real-world experiments on the platform.

13 Jul 2025
Researchers from the University of Washington, NVIDIA, and AI2 developed SAM2Act, a robotic manipulation policy integrating the SAM2 visual encoder with a multi-view transformer, achieving 86.8% success on RLBench tasks and demonstrating robust generalization. An extension, SAM2Act+, introduces a novel memory architecture, enabling 94.3% success on new memory-dependent benchmarks and outperforming prior methods by 39.3%.

08 Oct 2025



Researchers from UIUC, CMU, Stanford, MIT, and others developed SOTOPIA-RL, a two-stage reinforcement learning framework for large language models that designs utterance-level, multi-dimensional rewards to improve social intelligence. The method demonstrated improved social goal completion on the SOTOPIA benchmark, outperforming existing baselines and even GPT-4o.

31 Oct 2023


Research from AI2 and the University of Washington explored the fundamental limits of transformer language models on compositional tasks, demonstrating that model performance decays exponentially with increasing complexity as they primarily rely on linearized subgraph matching and exhibit rapid error propagation, rather than systematic rule application.
There are no more papers matching your filters at the moment.
