Ask or search anything...
 Fudan University
Fudan UniversityResearchers from Harbin Institute of Technology and collaborating institutions provide a systematic survey of Long Chain-of-Thought (Long CoT) in Large Language Models, establishing a formal distinction from Short CoT. The survey proposes a novel taxonomy based on deep reasoning, extensive exploration, and feasible reflection, and analyzes key phenomena observed in advanced reasoning models.
View blog
 Northeastern University
Northeastern University Sun Yat-Sen University
Sun Yat-Sen UniversityRoboTwin 2.0 introduces a scalable simulation framework and benchmark designed to generate high-quality, domain-randomized data for robust bimanual robotic manipulation, addressing limitations in existing synthetic datasets. Policies trained with RoboTwin 2.0 data achieved a 24.4% improvement in real-world success rates for few-shot learning and 21.0% for zero-shot generalization on unseen backgrounds.
View blog

Researchers from Harbin Institute of Technology and collaborators present a systematic survey of Artificial Intelligence for Scientific Research (AI4Research), defining its scope, proposing a comprehensive taxonomy across the entire research lifecycle, and identifying critical future directions. The study clarifies the distinction between AI4Research and AI4Science, demonstrating AI's growing capabilities from scientific comprehension to peer review, while highlighting significant challenges in achieving ethical, explainable, and fully autonomous systems.
View blog
 Google DeepMind
Google DeepMind University of Cambridge
University of Cambridge
MUSE, an agent framework from the Shanghai Artificial Intelligence Laboratory and collaborators, enables Large Language Models to learn continuously from experience and self-evolve for complex, long-horizon real-world tasks. It achieved a new state-of-the-art performance of 51.78% partial completion score on the challenging TheAgentCompany (TAC) benchmark, surpassing previous methods by nearly 20%.
View blog


 ByteDance
ByteDance
SEETOK proposes a vision-centric tokenization method that converts text into images for Large Language Models (LLMs), enabling them to "read" text visually. This approach reduces token counts by 4.43x and FLOPs by 70.5%, demonstrating improved multilingual fairness, translation quality, and robustness to text perturbations, while maintaining or exceeding performance on language understanding tasks.
View blog
 National University of Singapore
National University of Singapore
 University of Oxford
University of Oxford University of Science and Technology of China
University of Science and Technology of ChinaThe VCode project introduces a multimodal coding benchmark that requires Vision-Language Models to translate natural images into Scalable Vector Graphics (SVG) code, providing a symbolic and executable visual representation. The proposed VCoder framework, which employs iterative revision and external visual tools, improves state-of-the-art VLMs by 12.3 CodeVQA points on this challenging task.
View blog
Glance introduces a phase-aware acceleration framework for diffusion models, achieving up to 5x faster inference, enabling high-quality image generation in 8-10 steps compared to 50. This acceleration is accomplished with remarkably low training costs, utilizing only a single training sample and less than one GPU-hour of training while preserving visual quality and generalization.
View blog
 Chinese Academy of Sciences
Chinese Academy of Sciences Shanghai Jiao Tong University
Shanghai Jiao Tong UniversityThis survey provides a comprehensive review of advancements in embodied artificial intelligence (AI) from 2018 to 2025, focusing on the synergistic integration of physical simulators and world models. It proposes a five-level grading standard for intelligent robots (IR-L0 to IR-L4) and analyzes how these technologies collectively bridge the simulation-to-reality gap and enhance robot autonomy, adaptability, and generalization in complex tasks.
View blog
 CUHK
CUHK Beihang University
Beihang UniversityVideoEspresso is a large-scale dataset featuring over 200,000 question-answer pairs with detailed Chain-of-Thought annotations for fine-grained video reasoning. It enables Large Vision Language Models to better understand temporal dynamics and specific spatial-temporal relationships through a novel core frame selection strategy, outperforming existing methods in various video reasoning tasks.
View blog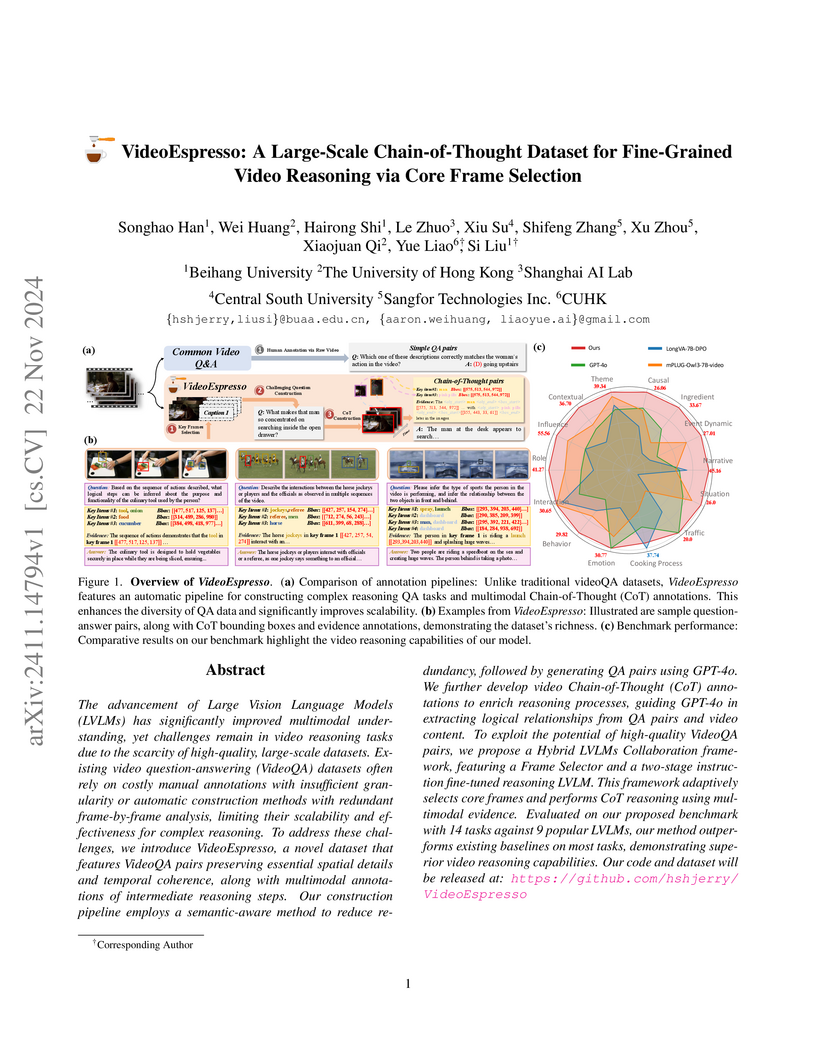
SlowFast Sampling accelerates diffusion-based Large Language Models (dLLMs) through a dynamic two-stage strategy guided by principles of token certainty and convergence. The method achieves up to 15.63x inference speedup for LLaDA on GPQA, which extends to 34.22x when combined with dLLM-Cache, enabling dLLMs to surpass LLaMA3 8B's throughput while preserving generation quality.
View blog
EVOLVER enables large language model agents to autonomously learn and improve from their own experiences by distilling raw interaction trajectories into strategic principles. This framework achieves an average Exact Match score of 0.382 across seven complex question-answering benchmarks, surpassing various state-of-the-art baselines.
View blog
Researchers from Shanghai Jiao Tong University and Central South University provide the first systematic survey of LLM-based deep search agents, classifying existing work by search paradigms, optimization methods, application areas, and evaluation strategies. This work consolidates understanding of the rapidly evolving field, identifies current limitations, and outlines future research directions for autonomous information seeking systems.
View blog

 Zhejiang University
Zhejiang University
RE-Searcher is an agentic search framework for large language models that integrates goal-oriented planning and self-reflection to enhance robustness in complex information environments. The method consistently achieves state-of-the-art performance on various question-answering datasets and substantially reduces performance degradation caused by noisy external search queries.
View blog
This survey systematically reviews and categorizes generative models in computer vision that produce physically plausible outputs, establishing a taxonomy of explicit and implicit physics-aware generation methods. It details six paradigms for integrating physical simulation, revealing a trend towards functional realism, and identifies current challenges in evaluation metrics.
View blog
Researchers from Harbin Institute of Technology formalize the Parallel–Sequential Contradiction (PSC), demonstrating that Diffusion Large Language Models (DLLMs) primarily exhibit superficial parallel reasoning and revert to autoregressive-like behavior when tackling complex Long Chain-of-Thought tasks. The study introduces parallel-encouraging prompting and diffusion early stopping, which effectively enhance DLLM reasoning capabilities.
View blog