Ask or search anything...
 Virginia Tech
Virginia Tech Huazhong University of Science and Technology
Huazhong University of Science and TechnologyRaptor, developed by researchers from Virginia Tech and the University of California, Berkeley, provides a system for efficient cybersecurity attack investigation by leveraging a Domain-Specific Language (ProvQL) and an optimized execution engine. This system allows security analysts to precisely query large-scale system provenance data, achieving an average graph reduction of 58,991x and an F1-score of 0.8766 in revealing attack sequences, while also speeding up query execution by up to 56 times compared to general-purpose query languages.
View blog
 University of Illinois at Urbana-Champaign
University of Illinois at Urbana-Champaign

 University of Washington
University of Washington New York University
New York UniversitySalesforce Research and collaborators introduce BLIP3-o, a family of unified multimodal models excelling in both image understanding and generation, by systematically investigating hybrid autoregressive-diffusion architectures. The models achieve superior performance on image understanding benchmarks, such as 83.1 on VQAv2 and 83.5 on MMBench, and demonstrate high visual quality and prompt alignment in human evaluations for image generation.
View blog
Salesforce Research, in collaboration with academic institutions, introduced BLIP3o-NEXT, an open-source autoregressive and diffusion model that unifies text-to-image generation and image editing. The model achieved superior performance on GenEval benchmarks and enhanced image editing consistency, notably improving text rendering and instruction following through reinforcement learning on discrete visual tokens.
View blog

 California Institute of Technology
California Institute of TechnologyA comprehensive survey by researchers from Shanghai AI Lab and various global institutions outlines the intricate relationship between scientific large language models (Sci-LLMs) and their data foundations, tracing their evolution towards autonomous agents for scientific discovery. The paper establishes a taxonomy for scientific data and knowledge, meticulously reviews over 270 datasets and 190 benchmarks, and identifies critical data challenges alongside future paradigms.
View blog
FAIR at Meta researchers systematically investigated synthetic data in LLM pre-training, discovering that mixing approximately 30% high-quality rephrased synthetic data with natural web text can accelerate pre-training convergence by 5-10x to reach the same validation loss. This approach also projects a lower irreducible loss compared to training solely on natural data, offering practical guidelines for data mixture ratios and generator model selection.
View blog

 Carnegie Mellon University
Carnegie Mellon University Allen Institute for AI
Allen Institute for AIResearchers from Virginia Tech, Carnegie Mellon University, and the Allen Institute for AI developed LLM-SR, a framework integrating large language models with evolutionary search and numerical optimization to discover scientific equations as Python programs. This approach achieves superior accuracy and out-of-domain generalization compared to state-of-the-art symbolic regression baselines, while requiring substantially fewer iterations on novel scientific benchmarks.
View blog
StructCoder introduces a Transformer model for code generation that uniquely integrates Abstract Syntax Tree (AST) paths and Data Flow Graph (DFG) predictions directly into the decoder to guide the generation of structured code. This approach consistently achieves state-of-the-art performance on code translation and text-to-code generation benchmarks, including higher strict accuracy on APPS Python problems, by ensuring the generated code is both syntactically correct and semantically sound.
View blog

Grad-CAM, developed at Georgia Tech and FAIR, introduces a technique for generating visual explanations from Convolutional Neural Networks by leveraging gradients flowing into the final convolutional layer. This method provides class-discriminative localization maps without requiring architectural changes or re-training of the network, making it broadly applicable to various CNN models and tasks.
View blog

Virginia Tech researchers introduced SEALQA, a challenging benchmark for search-augmented language models, designed to evaluate reasoning and robustness in scenarios with conflicting or unhelpful search results. Evaluations on SEALQA reveal that even frontier models struggle significantly with real-world information retrieval challenges, often performing poorly or being misled by noisy data.
View blog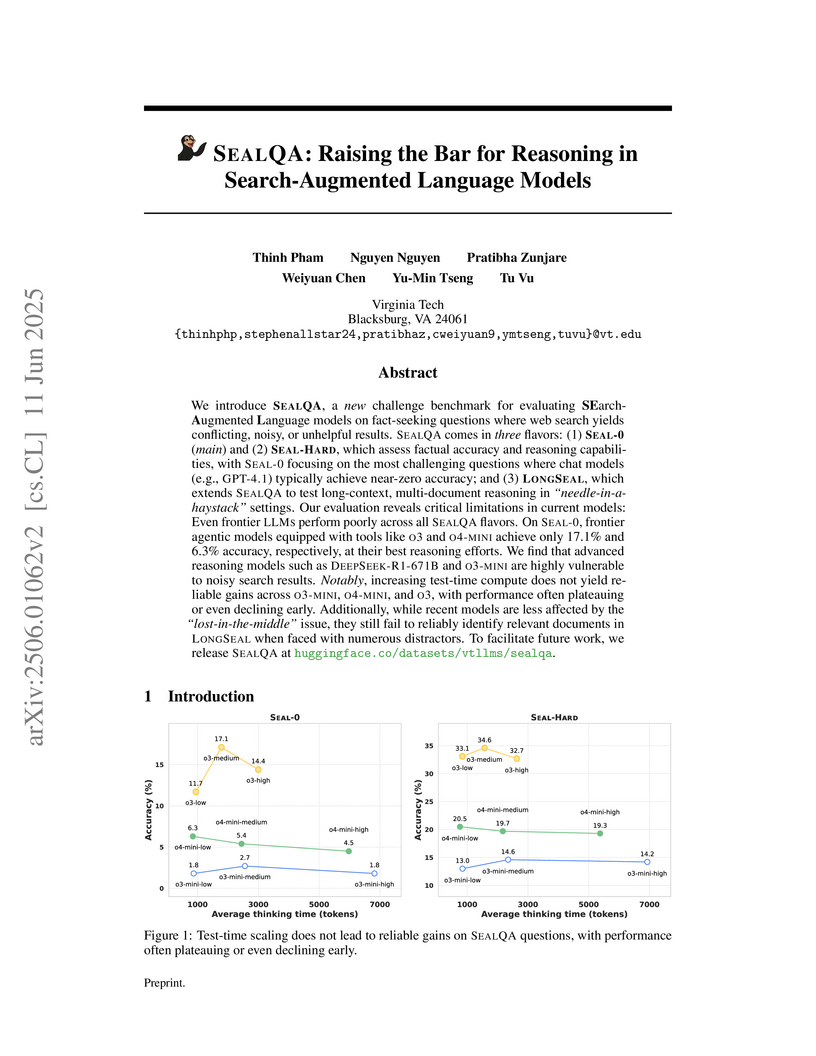

 Michigan State University
Michigan State UniversityThe TRUSTLLM framework and benchmark offer a comprehensive system for evaluating the trustworthiness of large language models across six key dimensions. This work reveals that while proprietary models generally exhibit higher trustworthiness, open-source models can also achieve strong performance in specific areas, highlighting challenges like 'over-alignment' and data leakage.
View blog
Researchers from Virginia Tech and fal developed Infinity-RoPE, a training-free inference framework that transforms short-horizon autoregressive Diffusion Transformers into models capable of infinite-length, action-controllable, and multi-cut video generation. This framework achieves superior temporal coherence and control in long videos, demonstrating state-of-the-art performance on benchmarks and in user studies.
View blog

LLM-SRBench is a new benchmark for scientific equation discovery with Large Language Models, meticulously designed to prevent memorization and rigorously assess true data-driven discovery and reasoning. The benchmark's evaluation, using four state-of-the-art LLM-based methods, reveals that current systems achieve a maximum of 31.5% symbolic accuracy, highlighting substantial room for improvement in LLMs' scientific reasoning and generalization capabilities.
View blog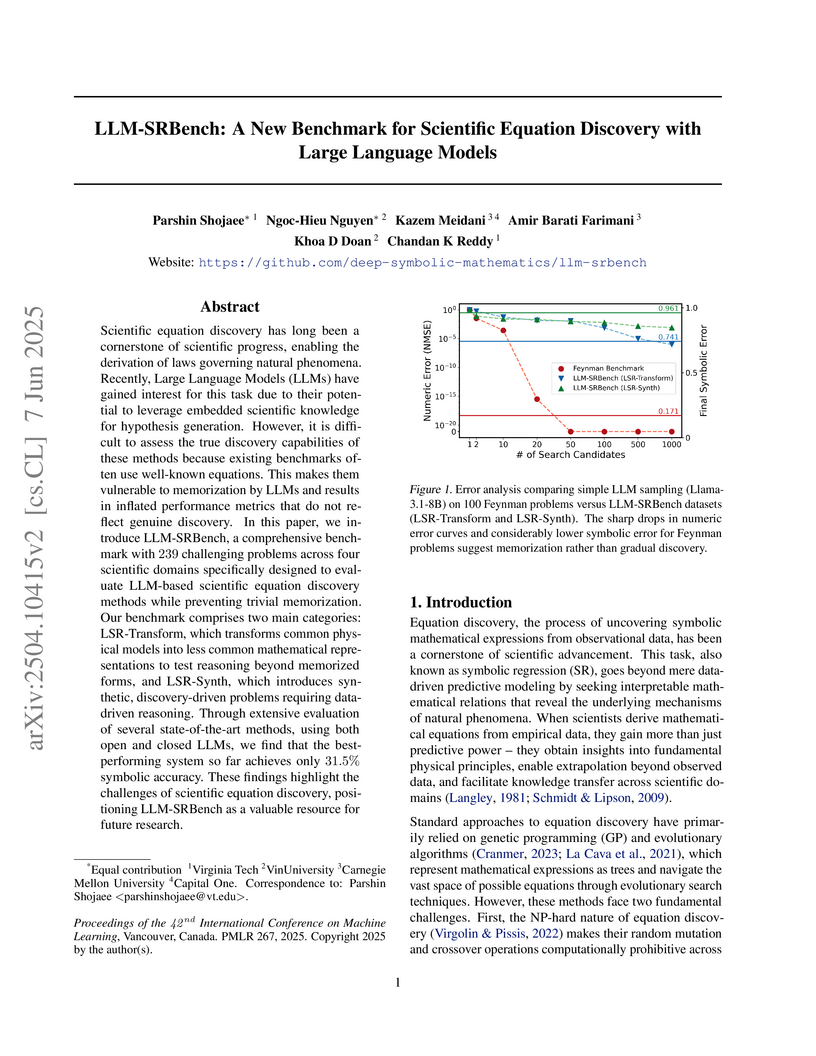

ConceptAttention introduces a training-free method to interpret multi-modal Diffusion Transformers by leveraging the attention output space to generate high-quality saliency maps for textual concepts. This approach sets new state-of-the-art results for zero-shot image segmentation on benchmarks like ImageNet-Segmentation (e.g., 83.07% Accuracy) and PascalVOC, and generalizes to video generation.
View blog
 Google DeepMind
Google DeepMind
 UC Berkeley
UC Berkeley University College London
University College LondonResearchers from a consortium of global institutions articulate a vision for the 'Agentic Web,' an internet ecosystem driven by autonomous AI agents that persistently plan, coordinate, and execute goal-directed tasks. They present a comprehensive framework for this emerging paradigm, detailing necessary algorithmic and systemic transitions, potential applications, and critical considerations for safety, security, and governance.
View blog
 Stanford University
Stanford UniversityResearchers at Princeton, Virginia Tech, IBM Research, and Stanford University reveal that fine-tuning Large Language Models (LLMs) such as Llama-2-7b-Chat and GPT-3.5 Turbo, even with benign datasets, can significantly degrade their safety mechanisms. Their findings show that harmfulness rates can increase from near-zero to up to 90% with malicious fine-tuning and to 10-35% with commonly used benign datasets.
View blog
 Princeton University
Princeton UniversityThis paper presents In-Run Data Shapley, a framework for efficiently quantifying data contributions to a specific machine learning model during its training process. It makes Data Shapley practical for large foundation models by integrating attribution calculations directly into the training loop with minimal overhead, revealing insights into data quality, training dynamics, and the nature of data influence on generative AI outputs.
View blog
 Sun Yat-Sen University
Sun Yat-Sen UniversityThis survey provides a comprehensive review of mechanistic interpretability methods for Multimodal Foundation Models (MMFMs), presenting a new taxonomy to organize current research. The work highlights that while some interpretability techniques from LLMs can be adapted, novel methods are required to understand unique multimodal processing, and identifies key research gaps in areas such as unified benchmarks and scalable causal understanding.
View blog

 Microsoft
Microsoft University of Pennsylvania
University of PennsylvaniaThis paper introduces REFOCUS, a framework that enhances multimodal LLMs' structured image understanding through iterative visual editing and reasoning
View blog