
22 Oct 2025


Researchers introduced Video-R1, the first framework to apply a rule-based reinforcement learning paradigm for enhancing temporal reasoning capabilities in Multimodal Large Language Models (MLLMs) for video. Video-R1, leveraging a new temporal-aware RL algorithm and dedicated video reasoning datasets, consistently outperforms previous state-of-the-art models, achieving 37.1% accuracy on VSI-Bench, surpassing GPT-4o's 34.0%.
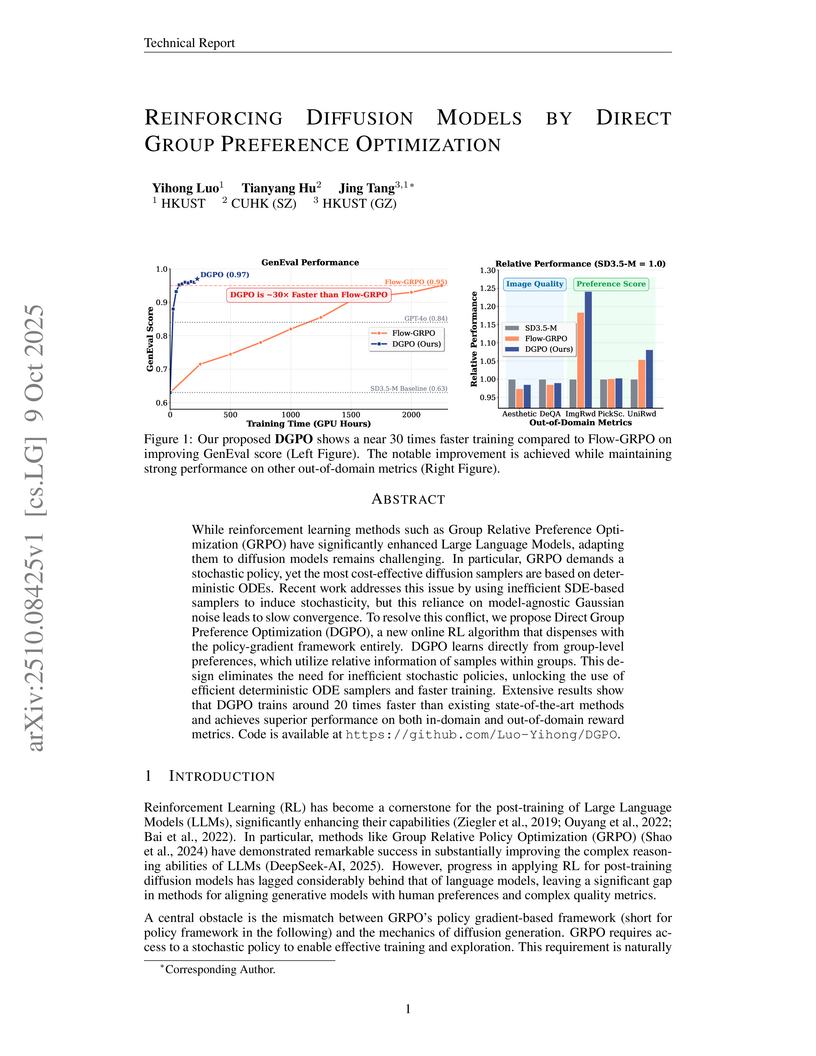
09 Oct 2025

Introducing Direct Group Preference Optimization (DGPO), a novel online reinforcement learning algorithm, enables diffusion models to learn from group-level preferences without requiring a stochastic policy. This method achieves up to 30 times faster training and sets new state-of-the-art performance in compositional image generation, visual text rendering, and human preference alignment, while preserving high visual quality.

01 Oct 2025


The Stepwise Guided Policy Optimization (SGPO) framework enhances large language model (LLM) reasoning by enabling Group Relative Policy Optimization (GRPO) to learn from previously discarded incorrect responses. SGPO, utilizing a step-wise judge model and a Reasoning Trajectory Score, consistently improves performance over GRPO across nine mathematical benchmarks and various LLM sizes, accelerating learning particularly on difficult problems.

06 Oct 2024


MIGU, a novel method for language models, mitigates catastrophic forgetting during continual learning by leveraging the L1-normalized output magnitude distribution of linear layers to selectively update gradients. This approach is rehearsal-free and task-label-free, achieving substantial performance improvements on various benchmarks and LM architectures, including a 15.2% accuracy increase on a challenging 15-task benchmark for T5-large.

03 Dec 2024



Researchers introduce AV-Odyssey Bench, a comprehensive benchmark, and DeafTest, a diagnostic tool, to rigorously evaluate multimodal LLMs' (MLLMs) audio-visual understanding. Evaluations reveal that leading MLLMs struggle with fundamental auditory perception, such as loudness and pitch comparison, and demonstrate limited audio-visual integration, with top models like GPT-4o reaching only 34.5% accuracy on the new benchmark.

28 Mar 2025

Recent advancements in video autoencoders (Video AEs) have significantly
improved the quality and efficiency of video generation. In this paper, we
propose a novel and compact video autoencoder, VidTwin, that decouples video
into two distinct latent spaces: Structure latent vectors, which capture
overall content and global movement, and Dynamics latent vectors, which
represent fine-grained details and rapid movements. Specifically, our approach
leverages an Encoder-Decoder backbone, augmented with two submodules for
extracting these latent spaces, respectively. The first submodule employs a
Q-Former to extract low-frequency motion trends, followed by downsampling
blocks to remove redundant content details. The second averages the latent
vectors along the spatial dimension to capture rapid motion. Extensive
experiments show that VidTwin achieves a high compression rate of 0.20% with
high reconstruction quality (PSNR of 28.14 on the MCL-JCV dataset), and
performs efficiently and effectively in downstream generative tasks. Moreover,
our model demonstrates explainability and scalability, paving the way for
future research in video latent representation and generation. Check our
project page for more details: this https URL

09 Jun 2024


Federated Learning (FL) is a machine learning paradigm that safeguards privacy by retaining client data on edge devices. However, optimizing FL in practice can be challenging due to the diverse and heterogeneous nature of the learning system. Though recent research has focused on improving the optimization of FL when distribution shifts occur among clients, ensuring global performance when multiple types of distribution shifts occur simultaneously among clients -- such as feature distribution shift, label distribution shift, and concept shift -- remain under-explored. In this paper, we identify the learning challenges posed by the simultaneous occurrence of diverse distribution shifts and propose a clustering principle to overcome these challenges. Through our research, we find that existing methods fail to address the clustering principle. Therefore, we propose a novel clustering algorithm framework, dubbed as FedRC, which adheres to our proposed clustering principle by incorporating a bi-level optimization problem and a novel objective function. Extensive experiments demonstrate that FedRC significantly outperforms other SOTA cluster-based FL methods. Our code is available at \url{this https URL}.

01 May 2024



Recently, 3D Gaussian Splatting, as a novel 3D representation, has garnered
attention for its fast rendering speed and high rendering quality. However,
this comes with high memory consumption, e.g., a well-trained Gaussian field
may utilize three million Gaussian primitives and over 700 MB of memory. We
credit this high memory footprint to the lack of consideration for the
relationship between primitives. In this paper, we propose a memory-efficient
Gaussian field named SUNDAE with spectral pruning and neural compensation. On
one hand, we construct a graph on the set of Gaussian primitives to model their
relationship and design a spectral down-sampling module to prune out primitives
while preserving desired signals. On the other hand, to compensate for the
quality loss of pruning Gaussians, we exploit a lightweight neural network head
to mix splatted features, which effectively compensates for quality losses
while capturing the relationship between primitives in its weights. We
demonstrate the performance of SUNDAE with extensive results. For example,
SUNDAE can achieve 26.80 PSNR at 145 FPS using 104 MB memory while the vanilla
Gaussian splatting algorithm achieves 25.60 PSNR at 160 FPS using 523 MB
memory, on the Mip-NeRF360 dataset. Codes are publicly available at
https://runyiyang.github.io/projects/SUNDAE/.

25 Jun 2022


In this paper, we consider a new Multi-Armed Bandit (MAB) problem where arms are nodes in an unknown and possibly changing graph, and the agent (i) initiates random walks over the graph by pulling arms, (ii) observes the random walk trajectories, and (iii) receives rewards equal to the lengths of the walks. We provide a comprehensive understanding of this problem by studying both the stochastic and the adversarial setting. We show that this problem is not easier than a standard MAB in an information theoretical sense, although additional information is available through random walk trajectories. Behaviors of bandit algorithms on this problem are also studied.

31 May 2023

Federated Learning (FL) is a way for machines to learn from data that is kept locally, in order to protect the privacy of clients. This is typically done using local SGD, which helps to improve communication efficiency. However, such a scheme is currently constrained by slow and unstable convergence due to the variety of data on different clients' devices. In this work, we identify three under-explored phenomena of biased local learning that may explain these challenges caused by local updates in supervised FL. As a remedy, we propose FedBR, a novel unified algorithm that reduces the local learning bias on features and classifiers to tackle these challenges. FedBR has two components. The first component helps to reduce bias in local classifiers by balancing the output of the models. The second component helps to learn local features that are similar to global features, but different from those learned from other data sources. We conducted several experiments to test \algopt and found that it consistently outperforms other SOTA FL methods. Both of its components also individually show performance gains. Our code is available at this https URL.
There are no more papers matching your filters at the moment.
