Ask or search anything...
 California Institute of TechnologyJet Propulsion Laboratory
California Institute of TechnologyJet Propulsion Laboratory Northwestern University
Northwestern University

 Tohoku University
Tohoku University
 CNRS
CNRS
 University College London
University College London

 Northeastern University
Northeastern UniversityKolmogorov–Arnold Networks (KANs) are introduced as a novel neural network architecture, leveraging the Kolmogorov–Arnold Representation Theorem by placing learnable univariate activation functions on network edges. This design achieves superior accuracy and parameter efficiency compared to Multi-Layer Perceptrons on various function approximation and scientific tasks, while providing intrinsic interpretability for discovering underlying mathematical laws.
View blog



 University of Toronto
University of Toronto
 Nanjing University
Nanjing UniversitySegFormer presents an efficient and robust Transformer-based framework for semantic segmentation, outperforming prior methods in accuracy while significantly reducing model size and computational cost. The model achieves state-of-the-art results on ADE20K, Cityscapes, and COCO-Stuff, showcasing superior efficiency and robustness to common corruptions.
View blog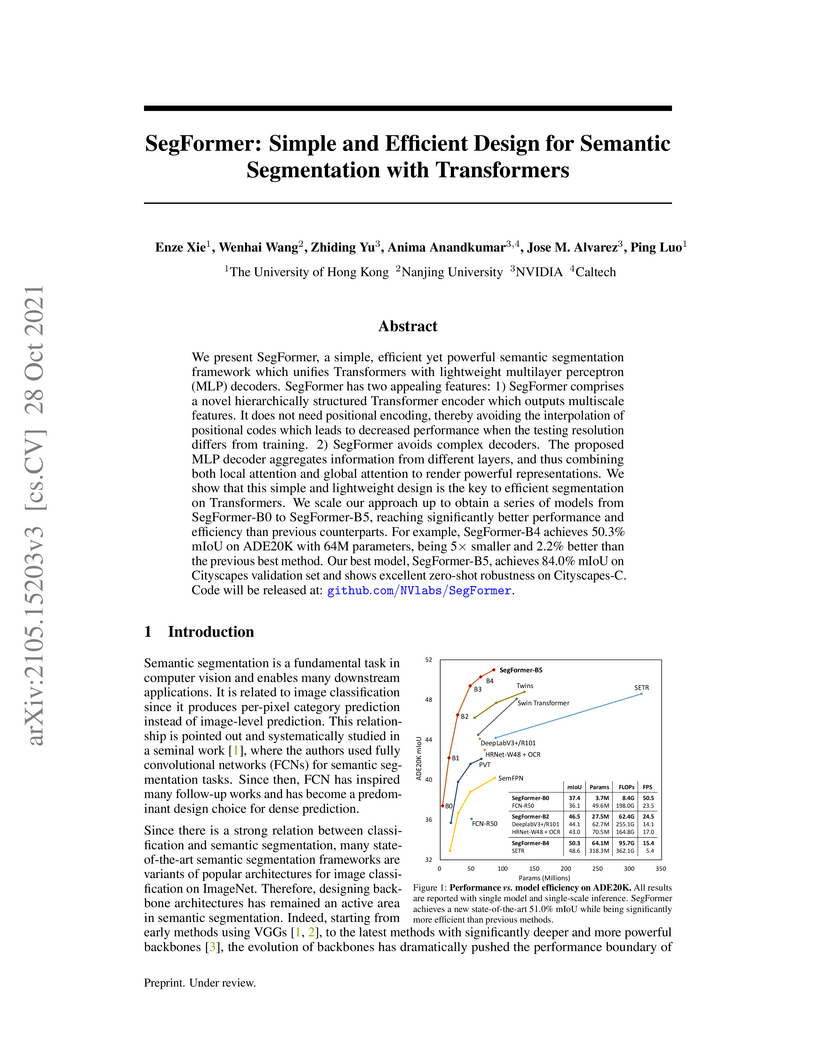

A comprehensive survey by researchers from Shanghai AI Lab and various global institutions outlines the intricate relationship between scientific large language models (Sci-LLMs) and their data foundations, tracing their evolution towards autonomous agents for scientific discovery. The paper establishes a taxonomy for scientific data and knowledge, meticulously reviews over 270 datasets and 190 benchmarks, and identifies critical data challenges alongside future paradigms.
View blog
 KAIST
KAIST University of Washington
University of WashingtonDREAMGEN introduces a pipeline that repurposes video world models as scalable synthetic data generators for robot learning, effectively mitigating the reliance on extensive human teleoperation. This approach allows robot policies to generalize to 22 novel behaviors and operate successfully in 10 previously unseen environments, starting from a minimal initial real-world dataset.
View blog
 Cornell University
Cornell UniversityThe Microsoft COCO dataset introduces a large-scale collection of images featuring common objects in diverse, cluttered contexts, precisely annotated with per-instance segmentation masks. This resource was designed to advance object recognition, contextual reasoning, and fine-grained localization beyond previous benchmarks, driving the development of more robust computer vision models.
View blog
 University of Cambridge
University of CambridgeA comprehensive survey systematically reviews advancements in feed-forward 3D reconstruction and view synthesis since 2020, categorizing methods by underlying scene representations such as NeRF, pointmaps, and 3D Gaussian Splatting. It details how deep learning has enabled significantly faster and more generalizable 3D vision, highlighting diverse applications and critical open research challenges.
View blog
Researchers from Texas A&M University, Stanford University, and others developed 4KAgent, a multi-agent AI system that universally upscales any image to 4K resolution, adapting to diverse degradations and domains without retraining. The agentic framework achieved state-of-the-art perceptual and fidelity metrics across 26 distinct benchmarks, including natural, AI-generated, and various scientific imaging types.
View blog
 Google DeepMind
Google DeepMindA research team at Stanford University's Hazy Research developed "Cartridges," a method to create lightweight, general-purpose representations of long text corpora for Large Language Models. This approach significantly reduces memory usage by 38.6x and boosts inference throughput by 26.4x compared to standard in-context learning, while maintaining or improving performance on long-context tasks.
View blog
 Alibaba Group
Alibaba GroupA collaboration between AMAP, Alibaba Group, NVIDIA, and Caltech presents EPG, a self-supervised pre-training framework that advances end-to-end pixel-space generative modeling to achieve high image quality and efficiency, outperforming prior pixel-space methods and rivaling latent-space models while enabling the first VAE-free consistency model training on high-resolution images.
View blog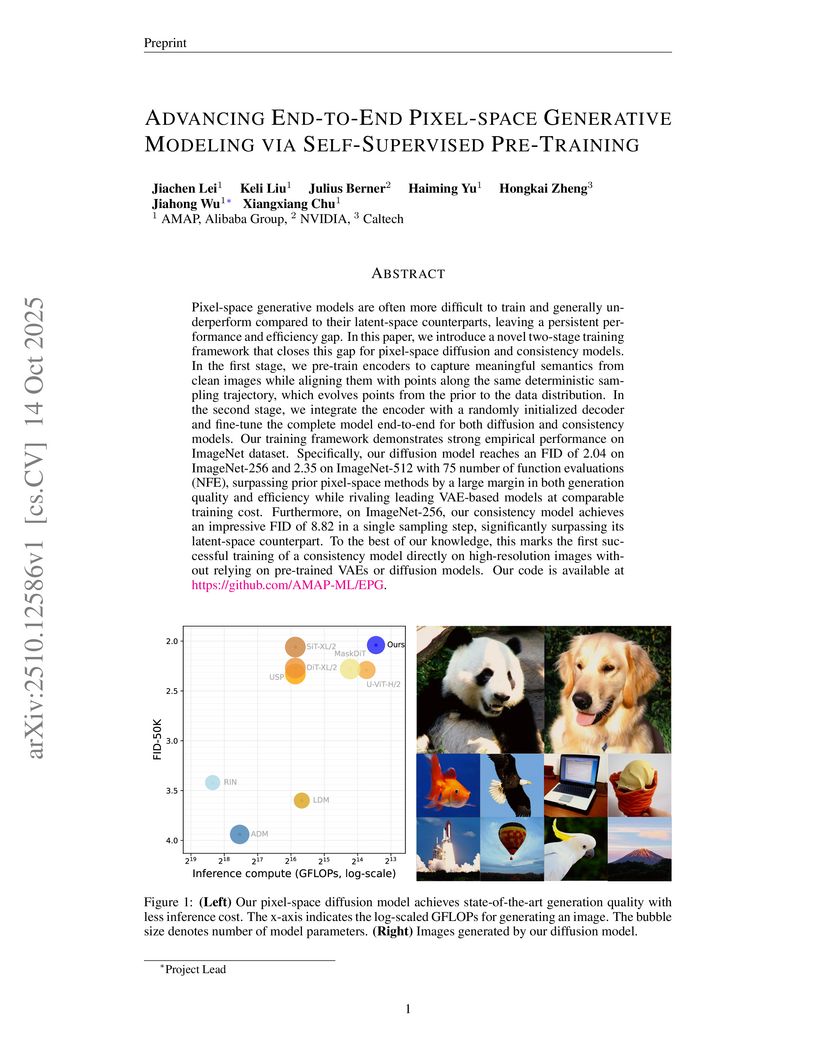
EUREKA, developed by NVIDIA and academic partners, is an algorithm that leverages Large Language Models to automatically design executable reward functions for reinforcement learning agents. It successfully generates human-level reward code that outperforms manually engineered rewards across various robotic tasks, including complex dexterous manipulation like pen spinning, significantly reducing the bottleneck of reward engineering.
View blog

 UC Berkeley
UC BerkeleyVLASH introduces a future-state-aware asynchronous inference framework that enables Vision-Language-Action (VLA) models to achieve real-time, smooth, and fast-reaction control in robotics. It allows VLAs to successfully perform dynamic tasks like playing ping-pong with a human, providing significant speedups and improved accuracy without modifying existing model architectures.
View blog