01 Nov 2025


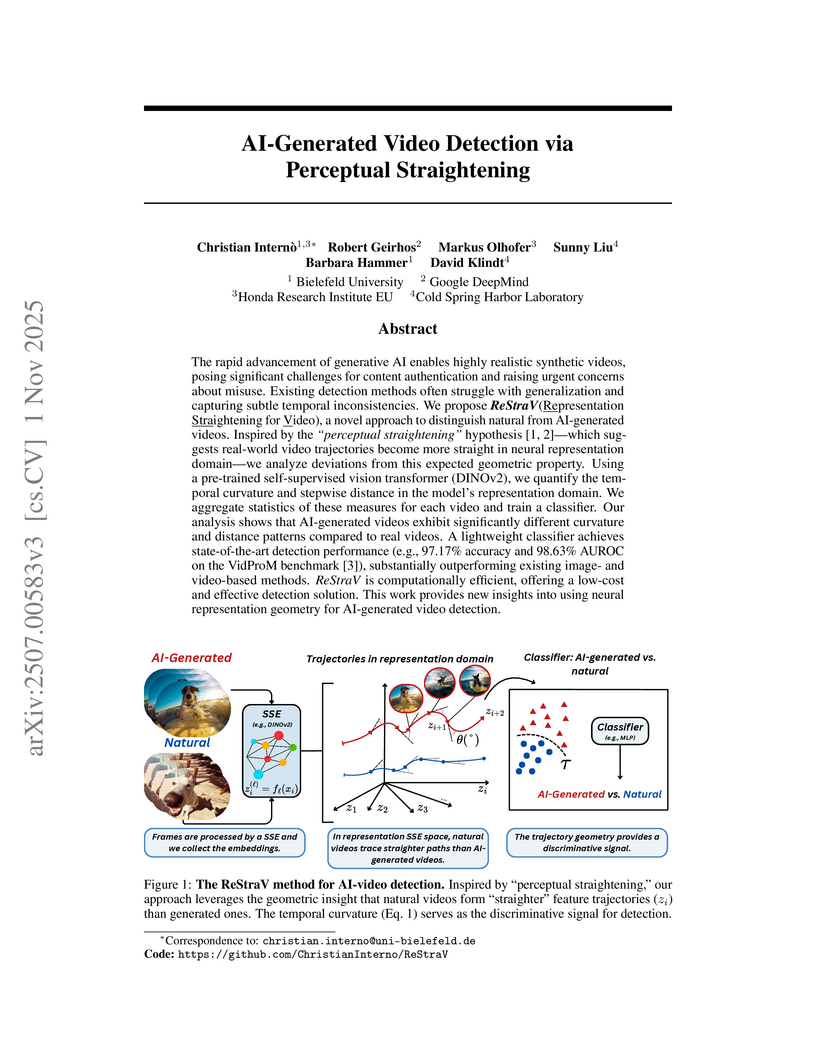
ReStraV, a method inspired by the 'perceptual straightening' hypothesis from biological vision, distinguishes AI-generated videos from natural ones by quantifying geometric properties of video trajectories in a frozen neural representation space. It achieves high accuracy and robust generalization to diverse and unseen generative models, providing an efficient and model-agnostic detection solution.

13 Nov 2025

The superposition hypothesis states that single neurons may participate in representing multiple features in order for the neural network to represent more features than it has neurons. In neuroscience and AI, representational alignment metrics measure the extent to which different deep neural networks (DNNs) or brains represent similar information. In this work, we explore a critical question: does superposition interact with alignment metrics in any undesirable way? We hypothesize that models which represent the same features in different superposition arrangements, i.e., their neurons have different linear combinations of the features, will interfere with predictive mapping metrics (semi-matching, soft-matching, linear regression), producing lower alignment than expected. We develop a theory for how permutation metrics are dependent on superposition arrangements. This is tested by training sparse autoencoders (SAEs) to disentangle superposition in toy models, where alignment scores are shown to typically increase when a model's base neurons are replaced with its sparse overcomplete latent codes. We find similar increases for DNN-DNN and DNN-brain linear regression alignment in the visual domain. Our results suggest that superposition disentanglement is necessary for mapping metrics to uncover the true representational alignment between neural networks.

01 Jul 2025

As deep learning continues to be driven by ever-larger datasets, understanding which examples are most important for generalization has become a critical question. While progress in data selection continues, emerging applications require studying this problem in dynamic contexts. To bridge this gap, we pose the Incremental Data Selection (IDS) problem, where examples arrive as a continuous stream, and need to be selected without access to the full data source. In this setting, the learner must incrementally build a training dataset of predefined size while simultaneously learning the underlying task. We find that in IDS, the impact of a new sample on the model state depends fundamentally on both its geometric relationship in the feature space and its prediction error. Leveraging this insight, we propose PEAKS (Prediction Error Anchored by Kernel Similarity), an efficient data selection method tailored for IDS. Our comprehensive evaluations demonstrate that PEAKS consistently outperforms existing selection strategies. Furthermore, PEAKS yields increasingly better performance returns than random selection as training data size grows on real-world datasets. The code is available at this https URL.

12 Oct 2024
Get rich quick: exact solutions reveal how unbalanced initializations promote rapid feature learning
Get rich quick: exact solutions reveal how unbalanced initializations promote rapid feature learning


While the impressive performance of modern neural networks is often attributed to their capacity to efficiently extract task-relevant features from data, the mechanisms underlying this rich feature learning regime remain elusive, with much of our theoretical understanding stemming from the opposing lazy regime. In this work, we derive exact solutions to a minimal model that transitions between lazy and rich learning, precisely elucidating how unbalanced layer-specific initialization variances and learning rates determine the degree of feature learning. Our analysis reveals that they conspire to influence the learning regime through a set of conserved quantities that constrain and modify the geometry of learning trajectories in parameter and function space. We extend our analysis to more complex linear models with multiple neurons, outputs, and layers and to shallow nonlinear networks with piecewise linear activation functions. In linear networks, rapid feature learning only occurs from balanced initializations, where all layers learn at similar speeds. While in nonlinear networks, unbalanced initializations that promote faster learning in earlier layers can accelerate rich learning. Through a series of experiments, we provide evidence that this unbalanced rich regime drives feature learning in deep finite-width networks, promotes interpretability of early layers in CNNs, reduces the sample complexity of learning hierarchical data, and decreases the time to grokking in modular arithmetic. Our theory motivates further exploration of unbalanced initializations to enhance efficient feature learning.

03 Mar 2025


A collaborative team from leading institutions presents a unified theoretical framework that bridges superposition and sparse coding in neural networks, providing both mathematical foundations and practical methods for extracting interpretable features from complex neural representations while drawing important parallels between artificial and biological neural systems.

15 Jun 2024



Deep Learning is often depicted as a trio of data-architecture-loss. Yet, recent Self Supervised Learning (SSL) solutions have introduced numerous additional design choices, e.g., a projector network, positive views, or teacher-student networks. These additions pose two challenges. First, they limit the impact of theoretical studies that often fail to incorporate all those intertwined designs. Second, they slow-down the deployment of SSL methods to new domains as numerous hyper-parameters need to be carefully tuned. In this study, we bring forward the surprising observation that--at least for pretraining datasets of up to a few hundred thousands samples--the additional designs introduced by SSL do not contribute to the quality of the learned representations. That finding not only provides legitimacy to existing theoretical studies, but also simplifies the practitioner's path to SSL deployment in numerous small and medium scale settings. Our finding answers a long-lasting question: the often-experienced sensitivity to training settings and hyper-parameters encountered in SSL come from their design, rather than the absence of supervised guidance.

25 Feb 2025

Supervised learning has become a cornerstone of modern machine learning, yet
a comprehensive theory explaining its effectiveness remains elusive. Empirical
phenomena, such as neural analogy-making and the linear representation
hypothesis, suggest that supervised models can learn interpretable factors of
variation in a linear fashion. Recent advances in self-supervised learning,
particularly nonlinear Independent Component Analysis, have shown that these
methods can recover latent structures by inverting the data generating process.
We extend these identifiability results to parametric instance discrimination,
then show how insights transfer to the ubiquitous setting of supervised
learning with cross-entropy minimization. We prove that even in standard
classification tasks, models learn representations of ground-truth factors of
variation up to a linear transformation. We corroborate our theoretical
contribution with a series of empirical studies. First, using simulated data
matching our theoretical assumptions, we demonstrate successful disentanglement
of latent factors. Second, we show that on DisLib, a widely-used
disentanglement benchmark, simple classification tasks recover latent
structures up to linear transformations. Finally, we reveal that models trained
on ImageNet encode representations that permit linear decoding of proxy factors
of variation. Together, our theoretical findings and experiments offer a
compelling explanation for recent observations of linear representations, such
as superposition in neural networks. This work takes a significant step toward
a cohesive theory that accounts for the unreasonable effectiveness of
supervised deep learning.

15 Mar 2025
Researchers at Cold Spring Harbor Laboratory developed a post-training objective for language models that leverages token-level uncertainty to improve adaptation and generalization. This approach identifies tokens with high epistemic uncertainty via their predictive loss, focusing training on these informative tokens while using self-distillation for low-uncertainty tokens. The method demonstrates improved performance on both in-distribution and out-of-distribution tasks, for example, achieving 7.5% higher accuracy on IF-Eval for Gemma-2-2b.

24 Jul 2025
Self-Supervised Learning (SSL) powers many current AI systems. As research interest and investment grow, the SSL design space continues to expand. The Platonic view of SSL, following the Platonic Representation Hypothesis (PRH), suggests that despite different methods and engineering approaches, all representations converge to the same Platonic ideal. However, this phenomenon lacks precise theoretical explanation. By synthesizing evidence from Identifiability Theory (IT), we show that the PRH can emerge in SSL. However, current IT cannot explain SSL's empirical success. To bridge the gap between theory and practice, we propose expanding IT into what we term Singular Identifiability Theory (SITh), a broader theoretical framework encompassing the entire SSL pipeline. SITh would allow deeper insights into the implicit data assumptions in SSL and advance the field towards learning more interpretable and generalizable representations. We highlight three critical directions for future research: 1) training dynamics and convergence properties of SSL; 2) the impact of finite samples, batch size, and data diversity; and 3) the role of inductive biases in architecture, augmentations, initialization schemes, and optimizers.

30 Jan 2025
A recent line of work has shown promise in using sparse autoencoders (SAEs) to uncover interpretable features in neural network representations. However, the simple linear-nonlinear encoding mechanism in SAEs limits their ability to perform accurate sparse inference. Using compressed sensing theory, we prove that an SAE encoder is inherently insufficient for accurate sparse inference, even in solvable cases. We then decouple encoding and decoding processes to empirically explore conditions where more sophisticated sparse inference methods outperform traditional SAE encoders. Our results reveal substantial performance gains with minimal compute increases in correct inference of sparse codes. We demonstrate this generalises to SAEs applied to large language models, where more expressive encoders achieve greater interpretability. This work opens new avenues for understanding neural network representations and analysing large language model activations.

16 Aug 2025

Transcriptomic assays such as the PAM50-based ROR-P score guide recurrence risk stratification in non-metastatic, ER-positive, HER2-negative breast cancer but are not universally accessible. Histopathology is routinely available and may offer a scalable alternative. We introduce MAKO, a benchmarking framework evaluating 12 pathology foundation models and two non-pathology baselines for predicting ROR-P scores from H&E-stained whole slide images using attention-based multiple instance learning. Models were trained and validated on the Carolina Breast Cancer Study and externally tested on TCGA BRCA. Several foundation models outperformed baselines across classification, regression, and survival tasks. CONCH achieved the highest ROC AUC, while H-optimus-0 and Virchow2 showed top correlation with continuous ROR-P scores. All pathology models stratified CBCS participants by recurrence similarly to transcriptomic ROR-P. Tumor regions were necessary and sufficient for high-risk predictions, and we identified candidate tissue biomarkers of recurrence. These results highlight the promise of interpretable, histology-based risk models in precision oncology.

24 Nov 2025
One frequently wishes to learn a range of similar tasks as efficiently as possible, re-using knowledge across tasks. In artificial neural networks, this is typically accomplished by conditioning a network upon task context by injecting context as input. Brains have a different strategy: the parameters themselves are modulated as a function of various neuromodulators such as serotonin. Here, we take inspiration from neuromodulation and propose to learn weights which are smoothly parameterized functions of task context variables. Rather than optimize a weight vector, i.e. a single point in weight space, we optimize a smooth manifold in weight space with a predefined topology. To accomplish this, we derive a formal treatment of optimization of manifolds as the minimization of a loss functional subject to a constraint on volumetric movement, analogous to gradient descent. During inference, conditioning selects a single point on this manifold which serves as the effective weight matrix for a particular sub-task. This strategy for conditioning has two main advantages. First, the topology of the manifold (whether a line, circle, or torus) is a convenient lever for inductive biases about the relationship between tasks. Second, learning in one state smoothly affects the entire manifold, encouraging generalization across states. To verify this, we train manifolds with several topologies, including straight lines in weight space (for conditioning on e.g. noise level in input data) and ellipses (for rotated images). Despite their simplicity, these parameterizations outperform conditioning identical networks by input concatenation and better generalize to out-of-distribution samples. These results suggest that modulating weights over low-dimensional manifolds offers a principled and effective alternative to traditional conditioning.

22 Nov 2024


We introduce ElastiFormer, a post-training technique that adapts pretrained Transformer models into an elastic counterpart with variable inference time compute. ElastiFormer introduces small routing modules (as low as .00006% additional trainable parameters) to dynamically selects subsets of network parameters and input tokens to be processed by each layer of the pretrained network in an inputdependent manner. The routing modules are trained using self-distillation losses to minimize the differences between the output of the pretrained-model and their elastic counterparts. As ElastiFormer makes no assumption regarding the modality of the pretrained Transformer model, it can be readily applied to all modalities covering causal language modeling, image modeling as well as visual-language modeling tasks. We show that 20% to 50% compute saving could be achieved for different components of the transformer layer, which could be further reduced by adding very low rank LoRA weights (rank 1) trained via the same distillation objective. Finally, by comparing routing trained on different subsets of ImageNet, we show that ElastiFormer is robust against the training domain.

20 Feb 2025



This research from Stanford University and collaborators develops a mathematical framework explaining how neural populations achieve stable computation through Latent Processing Units (LPUs), low-dimensional dynamical systems embedded in high-dimensional neural activity. It demonstrates that these LPUs can universally approximate computations and maintain stability despite representational drift, and that linear readouts can suffice for decoding computational variables.

25 Dec 2024
Authorship disambiguation is crucial for advancing studies in science of science. However, assessing the quality of authorship disambiguation in large-scale databases remains challenging since it is difficult to manually curate a gold-standard dataset that contains disambiguated authors. Through estimating the timing of when 5.8 million biomedical researchers became independent Principal Investigators (PIs) with authorship metadata extracted from the OpenAlex -- the largest open-source bibliometric database -- we unexpectedly discovered an anomaly: over 60% of researchers appeared as the last authors in their first career year. We hypothesized that this improbable finding results from poor name disambiguation, suggesting that such an anomaly may serve as an indicator of low-quality authorship disambiguation. Our findings indicated that authors who lack affiliation information, which makes it more difficult to disambiguate, were far more likely to exhibit this anomaly compared to those who included their affiliation information. In contrast, authors with Open Researcher and Contributor ID (ORCID) -- expected to have higher quality disambiguation -- showed significantly lower anomaly rates. We further applied this approach to examine the authorship disambiguation quality by gender over time, and we found that the quality of disambiguation for female authors was lower than that for male authors before 2010, suggesting that gender disparity findings based on pre-2010 data may require careful reexamination. Our results provide a framework for systematically evaluating authorship disambiguation quality in various contexts, facilitating future improvements in efforts to authorship disambiguation.

18 Nov 2024
Introduction: Deep learning models hold great promise for digital pathology,
but their opaque decision-making processes undermine trust and hinder clinical
adoption. Explainable AI methods are essential to enhance model transparency
and reliability. Methods: We developed HIPPO, an explainable AI framework that
systematically modifies tissue regions in whole slide images to generate image
counterfactuals, enabling quantitative hypothesis testing, bias detection, and
model evaluation beyond traditional performance metrics. HIPPO was applied to a
variety of clinically important tasks, including breast metastasis detection in
axillary lymph nodes, prognostication in breast cancer and melanoma, and IDH
mutation classification in gliomas. In computational experiments, HIPPO was
compared against traditional metrics and attention-based approaches to assess
its ability to identify key tissue elements driving model predictions. Results:
In metastasis detection, HIPPO uncovered critical model limitations that were
undetectable by standard performance metrics or attention-based methods. For
prognostic prediction, HIPPO outperformed attention by providing more nuanced
insights into tissue elements influencing outcomes. In a proof-of-concept
study, HIPPO facilitated hypothesis generation for identifying melanoma
patients who may benefit from immunotherapy. In IDH mutation classification,
HIPPO more robustly identified the pathology regions responsible for false
negatives compared to attention, suggesting its potential to outperform
attention in explaining model decisions. Conclusions: HIPPO expands the
explainable AI toolkit for computational pathology by enabling deeper insights
into model behavior. This framework supports the trustworthy development,
deployment, and regulation of weakly-supervised models in clinical and research
settings, promoting their broader adoption in digital pathology.

17 Nov 2025
Sparse autoencoders (SAEs) have emerged as a promising approach for learning interpretable features from neural network activations. However, the optimization landscape for SAE training can be challenging due to correlations in the input data. We demonstrate that applying PCA Whitening to input activations -- a standard preprocessing technique in classical sparse coding -- improves SAE performance across multiple metrics. Through theoretical analysis and simulation, we show that whitening transforms the optimization landscape, making it more convex and easier to navigate. We evaluate both ReLU and Top-K SAEs across diverse model architectures, widths, and sparsity regimes. Empirical evaluation on SAEBench, a comprehensive benchmark for sparse autoencoders, reveals that whitening consistently improves interpretability metrics, including sparse probing accuracy and feature disentanglement, despite minor drops in reconstruction quality. Our results challenge the assumption that interpretability aligns with an optimal sparsity--fidelity trade-off and suggest that whitening should be considered as a default preprocessing step for SAE training, particularly when interpretability is prioritized over perfect reconstruction.

27 Feb 2025
A natural strategy for continual learning is to weigh a Bayesian ensemble of
fixed functions. This suggests that if a (single) neural network could be
interpreted as an ensemble, one could design effective algorithms that learn
without forgetting. To realize this possibility, we observe that a neural
network classifier with N parameters can be interpreted as a weighted ensemble
of N classifiers, and that in the lazy regime limit these classifiers are fixed
throughout learning. We call these classifiers the neural tangent experts and
show they output valid probability distributions over the labels. We then
derive the likelihood and posterior probability of each expert given past data.
Surprisingly, the posterior updates for these experts are equivalent to a
scaled and projected form of stochastic gradient descent (SGD) over the network
weights. Away from the lazy regime, networks can be seen as ensembles of
adaptive experts which improve over time. These results offer a new
interpretation of neural networks as Bayesian ensembles of experts, providing a
principled framework for understanding and mitigating catastrophic forgetting
in continual learning settings.

06 Jun 2024

Contemporary Artificial Intelligence (AI) stands on two legs: large training data corpora and many-parameter artificial neural networks (ANNs). The data corpora are needed to represent the complexity and heterogeneity of the world. The role of the networks is less transparent due to the obscure dependence of the network parameters and outputs on the training data and inputs. This raises problems, ranging from technical-scientific to legal-ethical. We hypothesize that a transparent approach to machine learning is possible without using networks at all. By generalizing a parameter-free, statistically consistent data interpolation method, which we analyze theoretically in detail, we develop a network-free framework for AI incorporating generative modeling. We demonstrate this framework with examples from three different disciplines - ethology, control theory, and mathematics. Our generative Hilbert framework applied to the trajectories of small groups of swimming fish outperformed state-of-the-art traditional mathematical behavioral models and current ANN-based models. We demonstrate pure data interpolation based control by stabilizing an inverted pendulum and a driven logistic map around unstable fixed points. Finally, we present a mathematical application by predicting zeros of the Riemann Zeta function, achieving comparable performance as a transformer network. We do not suggest that the proposed framework will always outperform networks as over-parameterized networks can interpolate. However, our framework is theoretically sound, transparent, deterministic, and parameter free: remarkably, it does not require any compute-expensive training, does not involve optimization, has no model selection, and is easily reproduced and ported. We also propose an easily computed method of credit assignment based on this framework, to help address ethical-legal challenges raised by generative AI.

22 Mar 2017
We analyzed the performance of a biologically inspired algorithm called the
Corrected Projections Algorithm (CPA) when a sparseness constraint is required
to unambiguously reconstruct an observed signal using atoms from an
overcomplete dictionary. By changing the geometry of the estimation problem,
CPA gives an analytical expression for a binary variable that indicates the
presence or absence of a dictionary atom using an L2 regularizer. The
regularized solution can be implemented using an efficient real-time
Kalman-filter type of algorithm. The smoother L2 regularization of CPA makes it
very robust to noise, and CPA outperforms other methods in identifying known
atoms in the presence of strong novel atoms in the signal.
There are no more papers matching your filters at the moment.
