14 Oct 2025
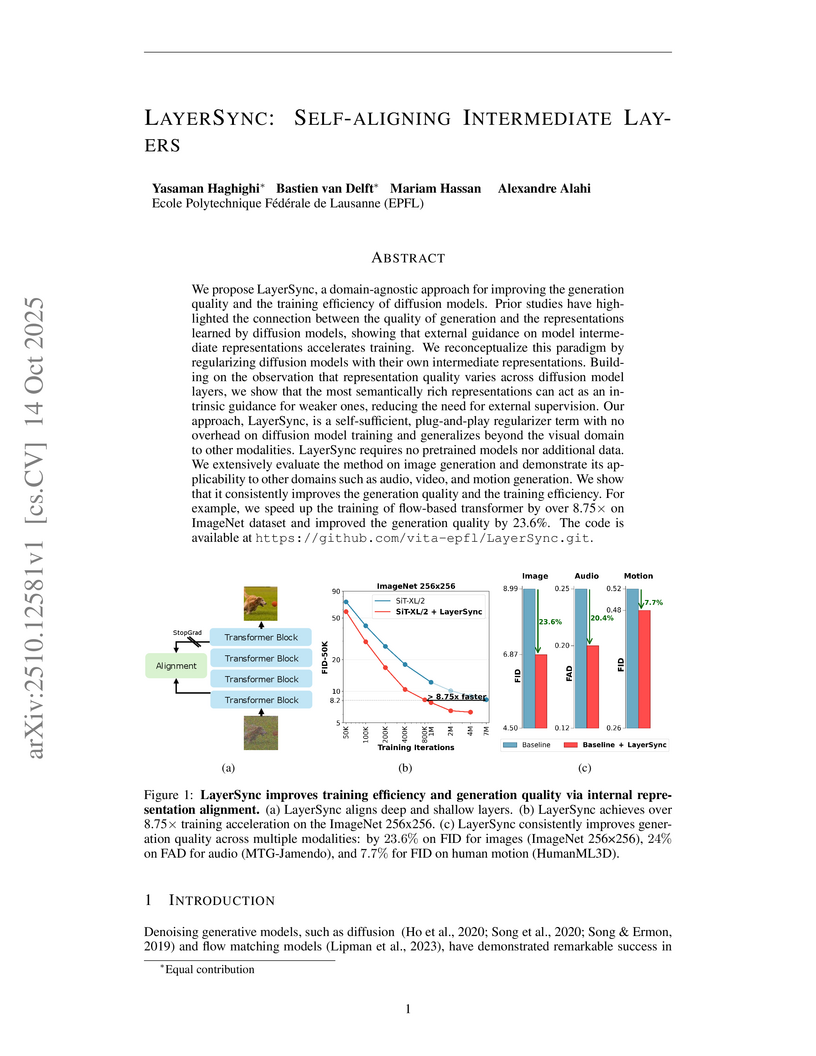
We propose LayerSync, a domain-agnostic approach for improving the generation quality and the training efficiency of diffusion models. Prior studies have highlighted the connection between the quality of generation and the representations learned by diffusion models, showing that external guidance on model intermediate representations accelerates training. We reconceptualize this paradigm by regularizing diffusion models with their own intermediate representations. Building on the observation that representation quality varies across diffusion model layers, we show that the most semantically rich representations can act as an intrinsic guidance for weaker ones, reducing the need for external supervision. Our approach, LayerSync, is a self-sufficient, plug-and-play regularizer term with no overhead on diffusion model training and generalizes beyond the visual domain to other modalities. LayerSync requires no pretrained models nor additional data. We extensively evaluate the method on image generation and demonstrate its applicability to other domains such as audio, video, and motion generation. We show that it consistently improves the generation quality and the training efficiency. For example, we speed up the training of flow-based transformer by over 8.75x on ImageNet dataset and improved the generation quality by 23.6%. The code is available at this https URL.

23 Oct 2025

Researchers from University College London, EPFL, Freie Universität Berlin, and The University of Tokyo introduce an adversarial framework for nonequilibrium thermodynamics, integrating an agent's risk tolerance into work extraction limits. This approach establishes that R
´enyi divergences operationally quantify the certainty equivalent work for a risk-sensitive agent in finite-size systems, unifying stochastic and resource-theoretic perspectives.

24 Jun 2025
 Chinese Academy of Sciences
Chinese Academy of Sciences Beijing Normal University
Beijing Normal University University College London
University College London University of CopenhagenUniversity of Edinburgh
University of CopenhagenUniversity of Edinburgh The University of Texas at Austin
The University of Texas at Austin Peking University
Peking University Texas A&M University
Texas A&M University NASA Goddard Space Flight Center
NASA Goddard Space Flight Center Space Telescope Science InstituteRochester Institute of TechnologyUniversity of Massachusetts AmherstEcole Polytechnique Federale de Lausanne (EPFL)University of ConnecticutNational Astronomical Observatories
Space Telescope Science InstituteRochester Institute of TechnologyUniversity of Massachusetts AmherstEcole Polytechnique Federale de Lausanne (EPFL)University of ConnecticutNational Astronomical Observatories Flatiron InstituteUniversity of SussexAix-Marseille UnivUniversity of CaliforniaMIT Kavli Institute for Astrophysics and Space ResearchUniversity of MaltaINAF – Osservatorio Astronomico di RomaCSIC-INTAColby CollegeNSF’s National Optical-Infrared Astronomy Research LaboratoryUniversity of the PacificUnversity of MichiganUniversita di Roma SapienzaInstituto de Astrof
sica de Andaluc
a
Flatiron InstituteUniversity of SussexAix-Marseille UnivUniversity of CaliforniaMIT Kavli Institute for Astrophysics and Space ResearchUniversity of MaltaINAF – Osservatorio Astronomico di RomaCSIC-INTAColby CollegeNSF’s National Optical-Infrared Astronomy Research LaboratoryUniversity of the PacificUnversity of MichiganUniversita di Roma SapienzaInstituto de Astrof
sica de Andaluc
aWe present CAPERS-LRD-z9, a little red dot (LRD) which we confirm to be a broad-line AGN (BLAGN). First identified as a high-redshift LRD candidate from PRIMER NIRCam photometry, follow-up NIRSpec/PRISM spectroscopy of CAPERS-LRD-z9 from the CANDELS-Area Prism Epoch of Reionization Survey (CAPERS) has revealed a broad km s H emission line and narrow [O III] lines, indicative of a BLAGN. Based on the broad H line, we compute a canonical black-hole mass of , although full consideration of systematic uncertainties yields a conservative range of 6.65<\log(M_{\textrm{BH}}/M_{\odot})<8.50. These observations suggest that either a massive black hole seed, or a lighter stellar remnant seed undergoing periods of super-Eddington accretion, is necessary to grow such a massive black hole in Myr of cosmic time. CAPERS-LRD-z9 exhibits a strong Balmer break, consistent with a central AGN surrounded by dense () neutral gas. We model CAPERS-LRD-z9 using CLOUDY to fit the emission red-ward of the Balmer break with a dense gas-enshrouded AGN, and bagpipes to fit the rest-ultraviolet emission as a host-galaxy stellar population. This upper limit on the stellar mass of the host galaxy (<10^9\,{\rm M_\odot}) implies that the black-hole to stellar mass ratio may be extremely large, possibly >5\% (although systematic uncertainties on the black-hole mass prevent strong conclusions). However, the shape of the UV continuum differs from typical high-redshift star-forming galaxies, indicating that this UV emission may also be of AGN origin, and hence the true stellar mass of the host may be still lower.

09 May 2025
Robust federated learning aims to maintain reliable performance despite the presence of adversarial or misbehaving workers. While state-of-the-art (SOTA) robust distributed gradient descent (Robust-DGD) methods were proven theoretically optimal, their empirical success has often relied on pre-aggregation gradient clipping. However, existing static clipping strategies yield inconsistent results: enhancing robustness against some attacks while being ineffective or even detrimental against others. To address this limitation, we propose a principled adaptive clipping strategy, Adaptive Robust Clipping (ARC), which dynamically adjusts clipping thresholds based on the input gradients. We prove that ARC not only preserves the theoretical robustness guarantees of SOTA Robust-DGD methods but also provably improves asymptotic convergence when the model is well-initialized. Extensive experiments on benchmark image classification tasks confirm these theoretical insights, demonstrating that ARC significantly enhances robustness, particularly in highly heterogeneous and adversarial settings.

11 Sep 2025

Turbulence influences the structure and dynamics of molecular clouds, and plays a key role in regulating star formation. We therefore need methods to accurately infer turbulence properties of molecular clouds from position-position-velocity (PPV) spectral observations. A previous method calibrated with simulation data exists to recover the 3D turbulent velocity dispersion from PPV data. However, that method relies on optically-thin conditions, ignoring any radiative transfer (RT) and chemical effects. In the present study we determine how opacity, RT, and chemical effects influence turbulence measurements with CO lines. We post-process a chemo-dynamical simulation of a turbulent collapsing cloud with a non-local thermodynamic equilibrium line RT code to generate PPV spectral cubes of the CO (1-0) and CO (2-1) lines, and obtain moment maps. We isolate the turbulence in the first-moment maps by using a Gaussian smoothing approach. We compare the CO results with the optically-thin scenario to explore how line excitation and RT impact the turbulence measurements. We find that the turbulent velocity dispersion (sigma_v) measured via CO requires a correction by a factor R_CO, with R_CO,1-0 = 0.88 (+0.09, -0.08) for the CO (1-0) line and R_CO,2-1 = 0.88 (+0.10, -0.08) for the CO (2-1) line. As a consequence, previous measurements of sigma_v were overestimated by about 10-15% on average, with potential overestimates as high as 40%, taking the 1-sigma uncertainty into account.

12 Sep 2025


This paper reports on technical aspects of Plasma Operational Simulation (POPSIM), a research framework for data-driven simulation and control built in the machine learning framework JAX. The objective of the project is to address the extremely challenging simulation and modeling requirements of tokamak operations and control by combining simple principles-based models with data-driven models, spanning everything from power laws to new neural network architectures. This paper reports on key software and operations problems that the framework addresses, with examples from ongoing modeling activities for illustration.

26 Sep 2025
 ETH Zurich
ETH Zurich Stockholm UniversityUniversité de GenèveEcole Polytechnique Federale de Lausanne (EPFL)
Stockholm UniversityUniversité de GenèveEcole Polytechnique Federale de Lausanne (EPFL) KTH Royal Institute of Technology
KTH Royal Institute of Technology Chalmers University of TechnologyNORDITAZHAW Z̈urich University of Applied SciencesHaute Ecole Arc IngnierieUniversity of Applied Sciences & Arts Western Switzerland (HES-SO)FHNW University of Applied Sciences & Arts Northwestern Switzerland
Chalmers University of TechnologyNORDITAZHAW Z̈urich University of Applied SciencesHaute Ecole Arc IngnierieUniversity of Applied Sciences & Arts Western Switzerland (HES-SO)FHNW University of Applied Sciences & Arts Northwestern SwitzerlandHydrogen is the most abundant element in our Universe. The first generation of stars and galaxies produced photons that ionized hydrogen gas, driving a cosmological event known as the Epoch of Reionization (EoR). The upcoming Square Kilometre Array Observatory (SKAO) will map the distribution of neutral hydrogen during this era, aiding in the study of the properties of these first-generation objects. Extracting astrophysical information will be challenging, as SKAO will produce a tremendous amount of data where the hydrogen signal will be contaminated with undesired foreground contamination and instrumental systematics. To address this, we develop the latest deep learning techniques to extract information from the 2D power spectra of the hydrogen signal expected from SKAO. We apply a series of neural network models to these measurements and quantify their ability to predict the history of cosmic hydrogen reionization, which is connected to the increasing number and efficiency of early photon sources. We show that the study of the early Universe benefits from modern deep learning technology. In particular, we demonstrate that dedicated machine learning algorithms can achieve more than a score on average in recovering the reionization history. This enables accurate and precise cosmological and astrophysical inference of structure formation in the early Universe.

06 Oct 2025
 CNRS
CNRS University of Cambridge
University of Cambridge University of Chicago
University of Chicago University of Oxford
University of Oxford Stanford UniversityYonsei University
Stanford UniversityYonsei University University of Wisconsin-MadisonUniversiteit GentENS de LyonEcole Polytechnique Federale de Lausanne (EPFL)University of BathLund UniversityKavli Institute for Cosmological PhysicsInstitut d'Astrophysique de ParisKavli Institute for Particle Astrophysics & Cosmology (KIPAC)Kavli Institute for CosmologySorbonne Universit´esTHOUGHTUniversit´e Claude Bernard (Lyon 1)1. **University of Bath**: Appears in affiliation 1.2. **University of Chicago**: Appears in affiliation 2 and 3 (Kavli Institute for Cosmological Physics is affiliated with UChicago).3. **Institut d’Astrophysique de Paris**: Appears in affiliation 4.4. **University of Oxford**: Appears in affiliation 5.5. **Lund University**: Appears in affiliation 6.6. **Universit´e Claude Bernard Lyon 1**: Appears in affiliation 7.7. **University of Cambridge**: Appears in affiliation 8 and 9 (Kavli Institute for Cosmology and Cavendish Laboratory are affiliated with UCambridge).8. **Yonsei University**: Appears in affiliation 10.9. **University of Wisconsin-Madison**: Appears in affiliation 11.10. **Stanford University**: Appears in affiliation 12 (Kavli Institute for Particle Astrophysics & Cosmology (KIPAC) is affiliated with Stanford).11. **Universiteit Gent**: Appears in affiliation 13.12. **´Ecole Polytechnique F´ed´erale de Lausanne (EPFL)**: Appears in affiliation 14.":
University of Wisconsin-MadisonUniversiteit GentENS de LyonEcole Polytechnique Federale de Lausanne (EPFL)University of BathLund UniversityKavli Institute for Cosmological PhysicsInstitut d'Astrophysique de ParisKavli Institute for Particle Astrophysics & Cosmology (KIPAC)Kavli Institute for CosmologySorbonne Universit´esTHOUGHTUniversit´e Claude Bernard (Lyon 1)1. **University of Bath**: Appears in affiliation 1.2. **University of Chicago**: Appears in affiliation 2 and 3 (Kavli Institute for Cosmological Physics is affiliated with UChicago).3. **Institut d’Astrophysique de Paris**: Appears in affiliation 4.4. **University of Oxford**: Appears in affiliation 5.5. **Lund University**: Appears in affiliation 6.6. **Universit´e Claude Bernard Lyon 1**: Appears in affiliation 7.7. **University of Cambridge**: Appears in affiliation 8 and 9 (Kavli Institute for Cosmology and Cavendish Laboratory are affiliated with UCambridge).8. **Yonsei University**: Appears in affiliation 10.9. **University of Wisconsin-Madison**: Appears in affiliation 11.10. **Stanford University**: Appears in affiliation 12 (Kavli Institute for Particle Astrophysics & Cosmology (KIPAC) is affiliated with Stanford).11. **Universiteit Gent**: Appears in affiliation 13.12. **´Ecole Polytechnique F´ed´erale de Lausanne (EPFL)**: Appears in affiliation 14.":We study the stellar mass-iron metallicity relation of dwarf galaxies in the new high-resolution MEGATRON cosmological radiation-hydrodynamics simulations. These simulations model galaxy formation up to in a region that will collapse into a Milky-Way-like galaxy at , while self-consistently tracking Population III and II (Pop.~III, Pop.~II) star formation, feedback and chemical enrichment. MEGATRON dwarf galaxies are in excellent agreement with the observed stellar mass-metallicity relation at , including an over-abundance of dwarfs along a flat plateau in metallicity () at low stellar masses (). We tie this feature to the chemical enrichment of dwarf galaxies by Pop.~III pair-instability supernova (PISN) explosions. The strong Lyman-Werner background (LW) from the protogalaxy ensures that PISNe occur in haloes massive enough () to retain their ejecta. We also predict a tail of of iron-deficient () dwarf galaxies. We show that both plateau and tail (i) are robust to large variations in Pop.~II feedback assumptions, and (ii) survive in bound satellites surrounding the central galaxy at .

01 Nov 2022
Researchers at EPFL's BioRobotics Laboratory developed CPG-RL, a framework that integrates Central Pattern Generators (CPGs) with Deep Reinforcement Learning for quadruped locomotion. This approach allows a DRL agent to modulate CPG parameters, resulting in robust and omnidirectional robot control that demonstrated exceptional sim-to-real transfer capabilities and tolerance to added loads of up to 115% of the robot's nominal mass on hardware.

04 Aug 2025
Sample-based quantum diagonalization (SQD) is a recently proposed algorithm to approximate the ground-state wave function of many-body quantum systems on near-term and early-fault-tolerant quantum devices. In SQD, the quantum computer acts as a sampling engine that generates the subspace in which the Hamiltonian is classically diagonalized. A recently proposed SQD variant, Sample-based Krylov Quantum Diagonalization (SKQD), uses quantum Krylov states as circuits from which samples are collected. Convergence guarantees can be derived for SKQD under similar assumptions to those of quantum phase estimation, provided that the ground-state wave function is concentrated, i.e., has support on a small subset of the full Hilbert space. Implementations of SKQD on current utility-scale quantum computers are limited by the depth of time-evolution circuits needed to generate Krylov vectors. For many complex many-body Hamiltonians of interest, such as the molecular electronic-structure Hamiltonian, this depth exceeds the capability of state-of-the-art quantum processors. In this work, we introduce a new SQD variant that combines SKQD with the qDRIFT randomized compilation of the Hamiltonian propagator. The resulting algorithm, termed SqDRIFT, enables SQD calculations at the utility scale on chemical Hamiltonians while preserving the convergence guarantees of SKQD. We apply SqDRIFT to calculate the electronic ground-state energy of several polycyclic aromatic hydrocarbons, up to system sizes beyond the reach of exact diagonalization.

24 Sep 2025

The symmetry structure of a quantum field theory is determined not only by the topological defects that implement the symmetry and their fusion rules, but also by the topological networks they can form, which is referred to as the higher structure of the symmetry. In this paper, we consider theories with non-invertible symmetries that have an explicit Lagrangian description, and use it to study their higher structure. Starting with the 2d free compact boson theory and its non-invertible duality defects, we will find Lagrangian descriptions of networks of defects and use them to recover all the -symbols of the familiar Tambara-Yamagami fusion category . We will then use the same approach in 4d Maxwell theory to compute -symbols associated with its non-invertible duality and triality defects, which are 2d topological field theories. In addition, we will also compute some of the -symbols using a different (group theoretical) approach that is not based on the Lagrangian description, and find that they take the expected form.

15 May 2023


Ultra-cold Fermi gases display diverse quantum mechanical properties, including the transition from a fermionic superfluid BCS state to a bosonic superfluid BEC state, which can be probed experimentally with high precision. However, the theoretical description of these properties is challenging due to the onset of strong pairing correlations and the non-perturbative nature of the interaction among the constituent particles. This work introduces a novel Pfaffian-Jastrow neural-network quantum state that includes backflow transformation based on message-passing architecture to efficiently encode pairing, and other quantum mechanical correlations. Our approach offers substantial improvements over comparable ansätze constructed within the Slater-Jastrow framework and outperforms state-of-the-art diffusion Monte Carlo methods, as indicated by our lower ground-state energies. We observe the emergence of strong pairing correlations through the opposite-spin pair distribution functions. Moreover, we demonstrate that transfer learning stabilizes and accelerates the training of the neural-network wave function, enabling the exploration of the BCS-BEC crossover region near unitarity. Our findings suggest that neural-network quantum states provide a promising strategy for studying ultra-cold Fermi gases.

08 Mar 2024
Researchers from EPFL's BioRobotics Laboratory developed a single locomotion policy that effectively controls 16 diverse quadruped robots, spanning variations in morphology, mass, and degrees of freedom. This policy, trained in under two hours, demonstrated robust sim-to-real transfer and enabled a Unitree A1 robot to carry 125% of its nominal mass on challenging terrain.

09 Sep 2025
Many robotic tasks, such as inverse kinematics, motion planning, and optimal control, can be formulated as optimization problems. Solving these problems involves addressing nonlinear kinematics, complex contact dynamics, long-horizon correlation, and multi-modal landscapes, each posing distinct challenges for state-of-the-art optimization methods. Monte Carlo Tree Search is a powerful approach that can strategically explore the solution space and can be applied to a wide range of tasks across varying scenarios. However, it typically suffers from combinatorial complexity when applied to robotics, resulting in slow convergence and high memory demands. To address this limitation, we propose \emph{Tensor Train Tree Search} (TTTS), which leverages tensor factorization to exploit correlations among decision variables arising from common kinematic structures, dynamic constraints, and environmental interactions in robot decision-making. This yields a compact, linear-complexity representation that significantly reduces both computation time and storage requirements. We prove that TTTS can efficiently reach the bounded global optimum within a finite time. Experimental results across inverse kinematics, motion planning around obstacles, legged robot manipulation, multi-stage motion planning, and bimanual whole-body manipulation demonstrate the efficiency of TTTS on a diverse set of robotic tasks.

02 Jul 2025


Researchers developed a scalable Variational Quantum Compilation framework that uses Pauli Propagation and machine learning-inspired cost functions to compress quantum circuits for two-dimensional systems. This approach achieves orders-of-magnitude higher accuracy than standard Trotterization and was experimentally validated on Quantinuum hardware.

28 Jun 2022
Safety is still the main issue of autonomous driving, and in order to be globally deployed, they need to predict pedestrians' motions sufficiently in advance. While there is a lot of research on coarse-grained (human center prediction) and fine-grained predictions (human body keypoints prediction), we focus on 3D bounding boxes, which are reasonable estimates of humans without modeling complex motion details for autonomous vehicles. This gives the flexibility to predict in longer horizons in real-world settings. We suggest this new problem and present a simple yet effective model for pedestrians' 3D bounding box prediction. This method follows an encoder-decoder architecture based on recurrent neural networks, and our experiments show its effectiveness in both the synthetic (JTA) and real-world (NuScenes) datasets. The learned representation has useful information to enhance the performance of other tasks, such as action anticipation. Our code is available online: this https URL

08 Aug 2025
Recent unsupervised domain adaptation (UDA) methods have shown great success in addressing classical domain shifts (e.g., synthetic-to-real), but they still suffer under complex shifts (e.g. geographical shift), where both the background and object appearances differ significantly across domains. Prior works showed that the language modality can help in the adaptation process, exhibiting more robustness to such complex shifts. In this paper, we introduce TRUST, a novel UDA approach that exploits the robustness of the language modality to guide the adaptation of a vision model. TRUST generates pseudo-labels for target samples from their captions and introduces a novel uncertainty estimation strategy that uses normalised CLIP similarity scores to estimate the uncertainty of the generated pseudo-labels. Such estimated uncertainty is then used to reweight the classification loss, mitigating the adverse effects of wrong pseudo-labels obtained from low-quality captions. To further increase the robustness of the vision model, we propose a multimodal soft-contrastive learning loss that aligns the vision and language feature spaces, by leveraging captions to guide the contrastive training of the vision model on target images. In our contrastive loss, each pair of images acts as both a positive and a negative pair and their feature representations are attracted and repulsed with a strength proportional to the similarity of their captions. This solution avoids the need for hardly determining positive and negative pairs, which is critical in the UDA setting. Our approach outperforms previous methods, setting the new state-of-the-art on classical (DomainNet) and complex (GeoNet) domain shifts. The code will be available upon acceptance.

14 Sep 2025
Classical simulations of quantum circuits play a vital role in the development of quantum computers and for taking the temperature of the field. Here, we classically simulate various physically-motivated circuits using 2D tensor network ansätze for the many-body wavefunction which match the geometry of the underlying quantum processor. We then employ a generalized version of the boundary Matrix Product State contraction algorithm to controllably generate samples from the resultant tensor network states. Our approach allows us to systematically converge both the quality of the final state and the samples drawn from it to the true distribution defined by the circuit, with GPU hardware providing us with significant speedups over CPU hardware. With these methods, we simulate the largest local unitary Jastrow ansatz circuit taken from recent IBM experiments to numerical precision. We also study a domain-wall quench in a two-dimensional discrete-time Heisenberg model on large heavy-hex and rotated square lattices, which reflect IBM's and Google's latest quantum processors respectively. We observe a rapid buildup of complex loop correlations on the Google Willow geometry which significantly impact the local properties of the system. Meanwhile, we find loop correlations build up extremely slowly on heavy-hex processors and have almost negligible impact on the local properties of the system, even at large circuit depths. Our results underscore the role the geometry of the quantum processor plays in classical simulability.

28 Nov 2024

Machine learning models have made significant progress in load forecasting,
but their forecast accuracy is limited in cases where historical load data is
scarce. Inspired by the outstanding performance of large language models (LLMs)
in computer vision and natural language processing, this paper aims to discuss
the potential of large time series models in load forecasting with scarce
historical data. Specifically, the large time series model is constructed as a
time series generative pre-trained transformer (TimeGPT), which is trained on
massive and diverse time series datasets consisting of 100 billion data points
(e.g., finance, transportation, banking, web traffic, weather, energy,
healthcare, etc.). Then, the scarce historical load data is used to fine-tune
the TimeGPT, which helps it to adapt to the data distribution and
characteristics associated with load forecasting. Simulation results show that
TimeGPT outperforms the benchmarks (e.g., popular machine learning models and
statistical models) for load forecasting on several real datasets with scarce
training samples, particularly for short look-ahead times. However, it cannot
be guaranteed that TimeGPT is always superior to benchmarks for load
forecasting with scarce data, since the performance of TimeGPT may be affected
by the distribution differences between the load data and the training data. In
practical applications, we can divide the historical data into a training set
and a validation set, and then use the validation set loss to decide whether
TimeGPT is the best choice for a specific dataset.

29 Sep 2025
Bayesian Optimization (BO) is a powerful framework for optimizing noisy, expensive-to-evaluate black-box functions. When the objective exhibits invariances under a group action, exploiting these symmetries can substantially improve BO efficiency. While using maximum similarity across group orbits has long been considered in other domains, the fact that the max kernel is not positive semidefinite (PSD) has prevented its use in BO. In this work, we revisit this idea by considering a PSD projection of the max kernel. Compared to existing invariant (and non-invariant) kernels, we show it achieves significantly lower regret on both synthetic and real-world BO benchmarks, without increasing computational complexity.
There are no more papers matching your filters at the moment.
