
21 Mar 2024



AdaIR presents an adaptive all-in-one image restoration network that leverages frequency mining and modulation to handle various degradation types using a single model. The approach consistently outperforms previous state-of-the-art all-in-one methods, achieving an average gain of 0.63 dB PSNR over PromptIR across multiple degradation tasks.

22 Oct 2024
Researchers from the University of Electronic Science and Technology of China (UESTC) and G42 developed a framework for real zero-shot Camouflaged Object Segmentation (COS) that eliminates the need for any camouflaged annotations by leveraging salient object segmentation data and an efficient learned codebook. This approach achieved state-of-the-art performance on major COS benchmarks and demonstrated robust applicability to medical image segmentation.

22 Oct 2022


In the pursuit of achieving ever-increasing accuracy, large and complex neural networks are usually developed. Such models demand high computational resources and therefore cannot be deployed on edge devices. It is of great interest to build resource-efficient general purpose networks due to their usefulness in several application areas. In this work, we strive to effectively combine the strengths of both CNN and Transformer models and propose a new efficient hybrid architecture EdgeNeXt. Specifically in EdgeNeXt, we introduce split depth-wise transpose attention (STDA) encoder that splits input tensors into multiple channel groups and utilizes depth-wise convolution along with self-attention across channel dimensions to implicitly increase the receptive field and encode multi-scale features. Our extensive experiments on classification, detection and segmentation tasks, reveal the merits of the proposed approach, outperforming state-of-the-art methods with comparatively lower compute requirements. Our EdgeNeXt model with 1.3M parameters achieves 71.2% top-1 accuracy on ImageNet-1K, outperforming MobileViT with an absolute gain of 2.2% with 28% reduction in FLOPs. Further, our EdgeNeXt model with 5.6M parameters achieves 79.4% top-1 accuracy on ImageNet-1K. The code and models are available at this https URL.

19 Jan 2022

This survey provides a comprehensive overview of Transformer models in computer vision, systematically organizing the rapidly expanding literature by architectural design and task applications. It synthesizes findings on how these models, originating from NLP, have been successfully adapted to achieve competitive performance across various vision tasks, including classification, detection, and segmentation.

14 Jul 2024
Researchers from Dalian University of Technology and Inception Institute of Artificial Intelligence introduce ZoomNeXt, a unified collaborative pyramid network for camouflaged object detection. The model leverages multi-scale processing and a novel uncertainty awareness loss to achieve state-of-the-art performance across both static image and dynamic video benchmarks.

05 Mar 2022
The recently proposed camouflaged object detection (COD) attempts to segment
objects that are visually blended into their surroundings, which is extremely
complex and difficult in real-world scenarios. Apart from high intrinsic
similarity between the camouflaged objects and their background, the objects
are usually diverse in scale, fuzzy in appearance, and even severely occluded.
To deal with these problems, we propose a mixed-scale triplet network,
\textbf{ZoomNet}, which mimics the behavior of humans when observing vague
images, i.e., zooming in and out. Specifically, our ZoomNet employs the zoom
strategy to learn the discriminative mixed-scale semantics by the designed
scale integration unit and hierarchical mixed-scale unit, which fully explores
imperceptible clues between the candidate objects and background surroundings.
Moreover, considering the uncertainty and ambiguity derived from
indistinguishable textures, we construct a simple yet effective regularization
constraint, uncertainty-aware loss, to promote the model to accurately produce
predictions with higher confidence in candidate regions. Without bells and
whistles, our proposed highly task-friendly model consistently surpasses the
existing 23 state-of-the-art methods on four public datasets. Besides, the
superior performance over the recent cutting-edge models on the SOD task also
verifies the effectiveness and generality of our model. The code will be
available at \url{this https URL}.

16 Jun 2025

Modern image classifiers perform well on populated classes, while degrading considerably on tail classes with only a few instances. Humans, by contrast, effortlessly handle the long-tailed recognition challenge, since they can learn the tail representation based on different levels of semantic abstraction, making the learned tail features more discriminative. This phenomenon motivated us to propose SuperDisco, an algorithm that discovers super-class representations for long-tailed recognition using a graph model. We learn to construct the super-class graph to guide the representation learning to deal with long-tailed distributions. Through message passing on the super-class graph, image representations are rectified and refined by attending to the most relevant entities based on the semantic similarity among their super-classes. Moreover, we propose to meta-learn the super-class graph under the supervision of a prototype graph constructed from a small amount of imbalanced data. By doing so, we obtain a more robust super-class graph that further improves the long-tailed recognition performance. The consistent state-of-the-art experiments on the long-tailed CIFAR-100, ImageNet, Places and iNaturalist demonstrate the benefit of the discovered super-class graph for dealing with long-tailed distributions.

04 Apr 2022

OW-DETR introduces an end-to-end Detection Transformer framework for Open-World Object Detection, leveraging multi-scale context encoding and dedicated components to detect unknown objects and incrementally learn new categories. It achieves superior unknown recall and known class mean Average Precision compared to prior state-of-the-art methods on MS-COCO and PASCAL VOC.

18 Mar 2020


This survey comprehensively reviews deep learning techniques for Named Entity Recognition (NER), presenting a novel three-axis taxonomy for model architectures and compiling essential resources. It concludes that deep learning models, especially those using contextualized embeddings and Transformer-based encoders, consistently achieve state-of-the-art performance while highlighting persistent challenges in informal text and data annotation.

10 Sep 2021
Anomaly detection in video is a challenging computer vision problem. Due to the lack of anomalous events at training time, anomaly detection requires the design of learning methods without full supervision. In this paper, we approach anomalous event detection in video through self-supervised and multi-task learning at the object level. We first utilize a pre-trained detector to detect objects. Then, we train a 3D convolutional neural network to produce discriminative anomaly-specific information by jointly learning multiple proxy tasks: three self-supervised and one based on knowledge distillation. The self-supervised tasks are: (i) discrimination of forward/backward moving objects (arrow of time), (ii) discrimination of objects in consecutive/intermittent frames (motion irregularity) and (iii) reconstruction of object-specific appearance information. The knowledge distillation task takes into account both classification and detection information, generating large prediction discrepancies between teacher and student models when anomalies occur. To the best of our knowledge, we are the first to approach anomalous event detection in video as a multi-task learning problem, integrating multiple self-supervised and knowledge distillation proxy tasks in a single architecture. Our lightweight architecture outperforms the state-of-the-art methods on three benchmarks: Avenue, ShanghaiTech and UCSD Ped2. Additionally, we perform an ablation study demonstrating the importance of integrating self-supervised learning and normality-specific distillation in a multi-task learning setting.

09 Dec 2020

Pedestrian detection is used in many vision based applications ranging from
video surveillance to autonomous driving. Despite achieving high performance,
it is still largely unknown how well existing detectors generalize to unseen
data. This is important because a practical detector should be ready to use in
various scenarios in applications. To this end, we conduct a comprehensive
study in this paper, using a general principle of direct cross-dataset
evaluation. Through this study, we find that existing state-of-the-art
pedestrian detectors, though perform quite well when trained and tested on the
same dataset, generalize poorly in cross dataset evaluation. We demonstrate
that there are two reasons for this trend. Firstly, their designs (e.g. anchor
settings) may be biased towards popular benchmarks in the traditional
single-dataset training and test pipeline, but as a result largely limit their
generalization capability. Secondly, the training source is generally not dense
in pedestrians and diverse in scenarios. Under direct cross-dataset evaluation,
surprisingly, we find that a general purpose object detector, without
pedestrian-tailored adaptation in design, generalizes much better compared to
existing state-of-the-art pedestrian detectors. Furthermore, we illustrate that
diverse and dense datasets, collected by crawling the web, serve to be an
efficient source of pre-training for pedestrian detection. Accordingly, we
propose a progressive training pipeline and find that it works well for
autonomous-driving oriented pedestrian detection. Consequently, the study
conducted in this paper suggests that more emphasis should be put on
cross-dataset evaluation for the future design of generalizable pedestrian
detectors. Code and models can be accessed at
this https URL

10 Jun 2021
We present the first systematic study on concealed object detection (COD), which aims to identify objects that are "perfectly" embedded in their background. The high intrinsic similarities between the concealed objects and their background make COD far more challenging than traditional object detection/segmentation. To better understand this task, we collect a large-scale dataset, called COD10K, which consists of 10,000 images covering concealed objects in diverse real-world scenarios from 78 object categories. Further, we provide rich annotations including object categories, object boundaries, challenging attributes, object-level labels, and instance-level annotations. Our COD10K is the largest COD dataset to date, with the richest annotations, which enables comprehensive concealed object understanding and can even be used to help progress several other vision tasks, such as detection, segmentation, classification, etc. Motivated by how animals hunt in the wild, we also design a simple but strong baseline for COD, termed the Search Identification Network (SINet). Without any bells and whistles, SINet outperforms 12 cutting-edge baselines on all datasets tested, making them robust, general architectures that could serve as catalysts for future research in COD. Finally, we provide some interesting findings and highlight several potential applications and future directions. To spark research in this new field, our code, dataset, and online demo are available on our project page: this http URL.

18 Jul 2020
Visible-infrared person re-identification (VI-ReID) is a challenging
cross-modality pedestrian retrieval problem. Due to the large intra-class
variations and cross-modality discrepancy with large amount of sample noise, it
is difficult to learn discriminative part features. Existing VI-ReID methods
instead tend to learn global representations, which have limited
discriminability and weak robustness to noisy images. In this paper, we propose
a novel dynamic dual-attentive aggregation (DDAG) learning method by mining
both intra-modality part-level and cross-modality graph-level contextual cues
for VI-ReID. We propose an intra-modality weighted-part attention module to
extract discriminative part-aggregated features, by imposing the domain
knowledge on the part relationship mining. To enhance robustness against noisy
samples, we introduce cross-modality graph structured attention to reinforce
the representation with the contextual relations across the two modalities. We
also develop a parameter-free dynamic dual aggregation learning strategy to
adaptively integrate the two components in a progressive joint training manner.
Extensive experiments demonstrate that DDAG outperforms the state-of-the-art
methods under various settings.

22 Oct 2024
Large-scale generative models have demonstrated impressive capabilities in producing visually compelling images, with increasing applications in medical imaging. However, they continue to grapple with hallucination challenges and the generation of anatomically inaccurate outputs. These limitations are mainly due to the reliance on textual inputs and lack of spatial control over the generated images, hindering the potential usefulness of such models in real-life settings. In this work, we present XReal, a novel controllable diffusion model for generating realistic chest X-ray images through precise anatomy and pathology location control. Our lightweight method comprises an Anatomy Controller and a Pathology Controller to introduce spatial control over anatomy and pathology in a pre-trained Text-to-Image Diffusion Model, respectively, without fine-tuning the model. XReal outperforms state-of-the-art X-ray diffusion models in quantitative metrics and radiologists' ratings, showing significant gains in anatomy and pathology realism. Our model holds promise for advancing generative models in medical imaging, offering greater precision and adaptability while inviting further exploration in this evolving field. The code and pre-trained model weights are publicly available at this https URL.
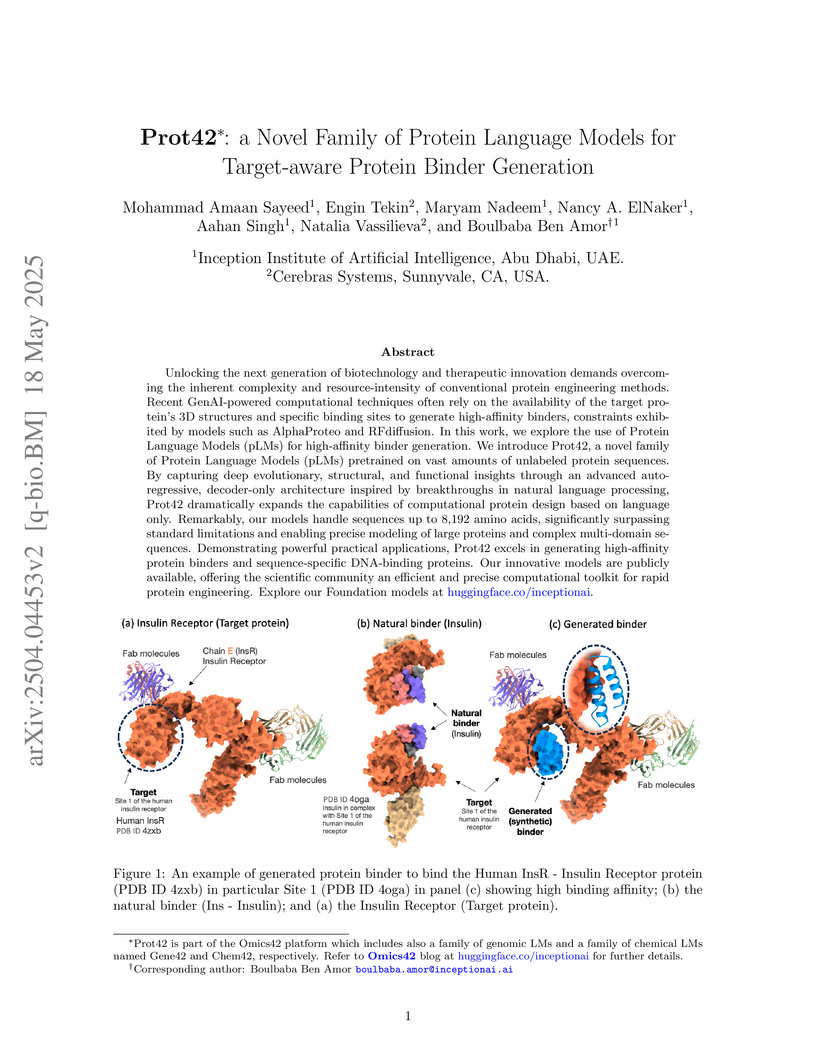
18 May 2025
Unlocking the next generation of biotechnology and therapeutic innovation
demands overcoming the inherent complexity and resource-intensity of
conventional protein engineering methods. Recent GenAI-powered computational
techniques often rely on the availability of the target protein's 3D structures
and specific binding sites to generate high-affinity binders, constraints
exhibited by models such as AlphaProteo and RFdiffusion. In this work, we
explore the use of Protein Language Models (pLMs) for high-affinity binder
generation. We introduce Prot42, a novel family of Protein Language Models
(pLMs) pretrained on vast amounts of unlabeled protein sequences. By capturing
deep evolutionary, structural, and functional insights through an advanced
auto-regressive, decoder-only architecture inspired by breakthroughs in natural
language processing, Prot42 dramatically expands the capabilities of
computational protein design based on language only. Remarkably, our models
handle sequences up to 8,192 amino acids, significantly surpassing standard
limitations and enabling precise modeling of large proteins and complex
multi-domain sequences. Demonstrating powerful practical applications, Prot42
excels in generating high-affinity protein binders and sequence-specific
DNA-binding proteins. Our innovative models are publicly available, offering
the scientific community an efficient and precise computational toolkit for
rapid protein engineering.

27 Mar 2024
Explaining Deep Learning models is becoming increasingly important in the face of daily emerging multimodal models, particularly in safety-critical domains like medical imaging. However, the lack of detailed investigations into the performance of explainability methods on these models is widening the gap between their development and safe deployment. In this work, we analyze the performance of various explainable AI methods on a vision-language model, MedCLIP, to demystify its inner workings. We also provide a simple methodology to overcome the shortcomings of these methods. Our work offers a different new perspective on the explainability of a recent well-known VLM in the medical domain and our assessment method is generalizable to other current and possible future VLMs.

24 Jan 2022
Following unprecedented success on the natural language tasks, Transformers have been successfully applied to several computer vision problems, achieving state-of-the-art results and prompting researchers to reconsider the supremacy of convolutional neural networks (CNNs) as {de facto} operators. Capitalizing on these advances in computer vision, the medical imaging field has also witnessed growing interest for Transformers that can capture global context compared to CNNs with local receptive fields. Inspired from this transition, in this survey, we attempt to provide a comprehensive review of the applications of Transformers in medical imaging covering various aspects, ranging from recently proposed architectural designs to unsolved issues. Specifically, we survey the use of Transformers in medical image segmentation, detection, classification, reconstruction, synthesis, registration, clinical report generation, and other tasks. In particular, for each of these applications, we develop taxonomy, identify application-specific challenges as well as provide insights to solve them, and highlight recent trends. Further, we provide a critical discussion of the field's current state as a whole, including the identification of key challenges, open problems, and outlining promising future directions. We hope this survey will ignite further interest in the community and provide researchers with an up-to-date reference regarding applications of Transformer models in medical imaging. Finally, to cope with the rapid development in this field, we intend to regularly update the relevant latest papers and their open-source implementations at \url{this https URL}.

19 Feb 2024


Most polyp segmentation methods use CNNs as their backbone, leading to two key issues when exchanging information between the encoder and decoder: 1) taking into account the differences in contribution between different-level features and 2) designing an effective mechanism for fusing these features. Unlike existing CNN-based methods, we adopt a transformer encoder, which learns more powerful and robust representations. In addition, considering the image acquisition influence and elusive properties of polyps, we introduce three standard modules, including a cascaded fusion module (CFM), a camouflage identification module (CIM), and a similarity aggregation module (SAM). Among these, the CFM is used to collect the semantic and location information of polyps from high-level features; the CIM is applied to capture polyp information disguised in low-level features, and the SAM extends the pixel features of the polyp area with high-level semantic position information to the entire polyp area, thereby effectively fusing cross-level features. The proposed model, named Polyp-PVT, effectively suppresses noises in the features and significantly improves their expressive capabilities. Extensive experiments on five widely adopted datasets show that the proposed model is more robust to various challenging situations (e.g., appearance changes, small objects, rotation) than existing representative methods. The proposed model is available at this https URL.

28 Dec 2024
ConsistentID introduces a method for high-fidelity, identity-consistent portrait generation using a single reference image and multimodal prompts, achieving superior preservation of fine-grained facial details through a novel facial attention localization strategy. The model demonstrates enhanced quality and flexibility in diverse scenarios while maintaining rapid inference speed.

21 Sep 2024


Camouflaged object detection (COD) aims to identify the objects that seamlessly blend into the surrounding backgrounds. Due to the intrinsic similarity between the camouflaged objects and the background region, it is extremely challenging to precisely distinguish the camouflaged objects by existing approaches. In this paper, we propose a hierarchical graph interaction network termed HGINet for camouflaged object detection, which is capable of discovering imperceptible objects via effective graph interaction among the hierarchical tokenized features. Specifically, we first design a region-aware token focusing attention (RTFA) with dynamic token clustering to excavate the potentially distinguishable tokens in the local region. Afterwards, a hierarchical graph interaction transformer (HGIT) is proposed to construct bi-directional aligned communication between hierarchical features in the latent interaction space for visual semantics enhancement. Furthermore, we propose a decoder network with confidence aggregated feature fusion (CAFF) modules, which progressively fuses the hierarchical interacted features to refine the local detail in ambiguous regions. Extensive experiments conducted on the prevalent datasets, i.e. COD10K, CAMO, NC4K and CHAMELEON demonstrate the superior performance of HGINet compared to existing state-of-the-art methods. Our code is available at this https URL.
There are no more papers matching your filters at the moment.
