
12 Mar 2025
SimLingo unifies high-performance vision-only closed-loop autonomous driving with advanced vision-language understanding and language-action alignment. It achieved state-of-the-art driving performance on the CARLA Leaderboard 2.0 (Sensor track) and significantly improved language-action alignment through a novel 'Action Dreaming' data generation approach.

16 Apr 2025
Researchers at the University of Tübingen and Max Planck Institute for Intelligent Systems introduced AnInfoNCE, a generalized contrastive loss that provably identifies latent factors in an anisotropic setting, addressing the mismatch between theoretical assumptions and practical data augmentations in Contrastive Learning. The framework demonstrates increased recovery of "style" information, but revealed an "accuracy-identifiability trade-off" where enhanced latent factor recovery can lead to lower downstream task accuracy on real-world datasets.

05 May 2022
PatchCore introduces a method for cold-start industrial anomaly detection that leverages locally aware patch features and a coreset-reduced memory bank, achieving state-of-the-art image-level AUROC of 99.6% and efficient pixel-wise anomaly localization on the MVTec AD benchmark.

09 Nov 2022
ImageNet-trained Convolutional Neural Networks (CNNs) classify objects primarily by texture, contrasting with human vision's reliance on shape. Training CNNs on a new stylized dataset shifts their bias towards shape, yielding improved classification accuracy, enhanced object detection performance, and increased robustness against various image corruptions.

21 Nov 2023

Deep neural networks often learn superficial decision rules, termed "shortcut learning," which perform well on standard benchmarks but fail in more challenging, real-world scenarios. This work unifies various observed limitations, from adversarial examples to poor out-of-distribution generalization, by framing them as manifestations of models exploiting unintended statistical regularities in training data, analogous to phenomena in biological learning.

12 Dec 2024



Feat2GS presents a framework to evaluate the 3D awareness of Visual Foundation Models (VFMs) using novel view synthesis without 3D labels, revealing that VFMs trained with 3D data exhibit better geometric understanding while generally struggling with fine-grained texture details.

29 Mar 2025


GenFusion introduces a framework that bridges 3D reconstruction and generative models by leveraging video diffusion priors to achieve artifact-free 3D scene reconstruction and content expansion from sparse video inputs. The method significantly improves novel view synthesis from sparse views and enables robust view extrapolation, outperforming existing Gaussian Splatting methods across various benchmarks.

26 Mar 2025

Novel view synthesis of urban scenes is essential for autonomous
driving-related applications.Existing NeRF and 3DGS-based methods show
promising results in achieving photorealistic renderings but require slow,
per-scene optimization. We introduce EVolSplat, an efficient 3D Gaussian
Splatting model for urban scenes that works in a feed-forward manner. Unlike
existing feed-forward, pixel-aligned 3DGS methods, which often suffer from
issues like multi-view inconsistencies and duplicated content, our approach
predicts 3D Gaussians across multiple frames within a unified volume using a 3D
convolutional network. This is achieved by initializing 3D Gaussians with noisy
depth predictions, and then refining their geometric properties in 3D space and
predicting color based on 2D textures. Our model also handles distant views and
the sky with a flexible hemisphere background model. This enables us to perform
fast, feed-forward reconstruction while achieving real-time rendering.
Experimental evaluations on the KITTI-360 and Waymo datasets show that our
method achieves state-of-the-art quality compared to existing feed-forward
3DGS- and NeRF-based methods.

31 Mar 2025

Zhejiang University and ETH Zurich researchers develop Free360, a framework for 360-degree view synthesis from just 3-4 unposed input views, combining layered Gaussian splatting with video diffusion models to achieve high-quality novel view generation through uncertainty-aware training and iterative refinement.

07 Jun 2024


Researchers at the University of Tübingen and University of Amsterdam developed Geometric Transform Attention (GTA), an attention mechanism that explicitly integrates 3D geometric transformations into Vision Transformers. This approach enhances performance and learning efficiency across Novel View Synthesis tasks by enabling a more principled understanding of scene geometry.
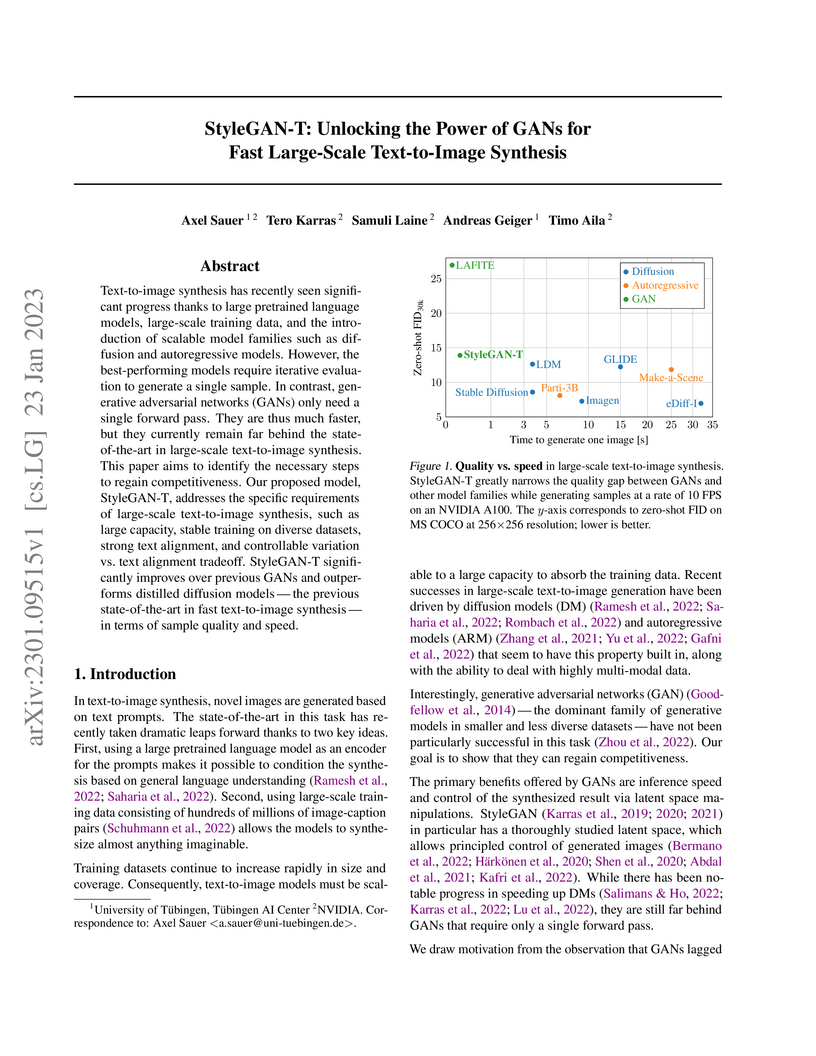
23 Jan 2023


Researchers at NVIDIA and the University of Tübingen developed StyleGAN-T, a Generative Adversarial Network that produces text-to-image outputs in a single forward pass, achieving image generation times of 0.06-0.10 seconds per image. The model demonstrates competitive image quality, particularly at 64x64 resolution where it outperforms leading diffusion models with a zero-shot MS COCO FID of 7.30.

14 Mar 2025
NVIDIA and university researchers develop Centaur, a test-time training framework that improves autonomous driving safety through continuous model adaptation and uncertainty estimation using a novel Cluster Entropy measure, achieving state-of-the-art performance on the navsafe benchmark while operating asynchronously for real-time deployment.

10 Jun 2024


GraphDreamer introduces a framework for generating compositional 3D scenes directly from scene graphs, which explicitly define objects, their attributes, and relationships. This approach enables the synthesis of disentangled 3D objects with high semantic fidelity, achieving a mean CLIP score of 0.3326 and a 62.26% user preference for prompt adherence, surpassing prior methods.

19 Mar 2024
Holistic understanding of urban scenes based on RGB images is a challenging
yet important problem. It encompasses understanding both the geometry and
appearance to enable novel view synthesis, parsing semantic labels, and
tracking moving objects. Despite considerable progress, existing approaches
often focus on specific aspects of this task and require additional inputs such
as LiDAR scans or manually annotated 3D bounding boxes. In this paper, we
introduce a novel pipeline that utilizes 3D Gaussian Splatting for holistic
urban scene understanding. Our main idea involves the joint optimization of
geometry, appearance, semantics, and motion using a combination of static and
dynamic 3D Gaussians, where moving object poses are regularized via physical
constraints. Our approach offers the ability to render new viewpoints in
real-time, yielding 2D and 3D semantic information with high accuracy, and
reconstruct dynamic scenes, even in scenarios where 3D bounding box detection
are highly noisy. Experimental results on KITTI, KITTI-360, and Virtual KITTI 2
demonstrate the effectiveness of our approach.

12 Jun 2025


As Language Model (LM) capabilities advance, evaluating and supervising them
at scale is getting harder for humans. There is hope that other language models
can automate both these tasks, which we refer to as ''AI Oversight''. We study
how model similarity affects both aspects of AI oversight by proposing Chance
Adjusted Probabilistic Agreement (CAPA): a metric for LM similarity based on
overlap in model mistakes. Using CAPA, we first show that LLM-as-a-judge scores
favor models similar to the judge, generalizing recent self-preference results.
Then, we study training on LM annotations, and find complementary knowledge
between the weak supervisor and strong student model plays a crucial role in
gains from ''weak-to-strong generalization''. As model capabilities increase,
it becomes harder to find their mistakes, and we might defer more to AI
oversight. However, we observe a concerning trend -- model mistakes are
becoming more similar with increasing capabilities, pointing to risks from
correlated failures. Our work underscores the importance of reporting and
correcting for model similarity, especially in the emerging paradigm of AI
oversight.

04 Apr 2025
Query denoising has become a standard training strategy for DETR-based
detectors by addressing the slow convergence issue. Besides that, query
denoising can be used to increase the diversity of training samples for
modeling complex scenarios which is critical for Multi-Object Tracking (MOT),
showing its potential in MOT application. Existing approaches integrate query
denoising within the tracking-by-attention paradigm. However, as the denoising
process only happens within the single frame, it cannot benefit the tracker to
learn temporal-related information. In addition, the attention mask in query
denoising prevents information exchange between denoising and object queries,
limiting its potential in improving association using self-attention. To
address these issues, we propose TQD-Track, which introduces Temporal Query
Denoising (TQD) tailored for MOT, enabling denoising queries to carry temporal
information and instance-specific feature representation. We introduce diverse
noise types onto denoising queries that simulate real-world challenges in MOT.
We analyze our proposed TQD for different tracking paradigms, and find out the
paradigm with explicit learned data association module, e.g.
tracking-by-detection or alternating detection and association, benefit from
TQD by a larger margin. For these paradigms, we further design an association
mask in the association module to ensure the consistent interaction between
track and detection queries as during inference. Extensive experiments on the
nuScenes dataset demonstrate that our approach consistently enhances different
tracking methods by only changing the training process, especially the
paradigms with explicit association module.
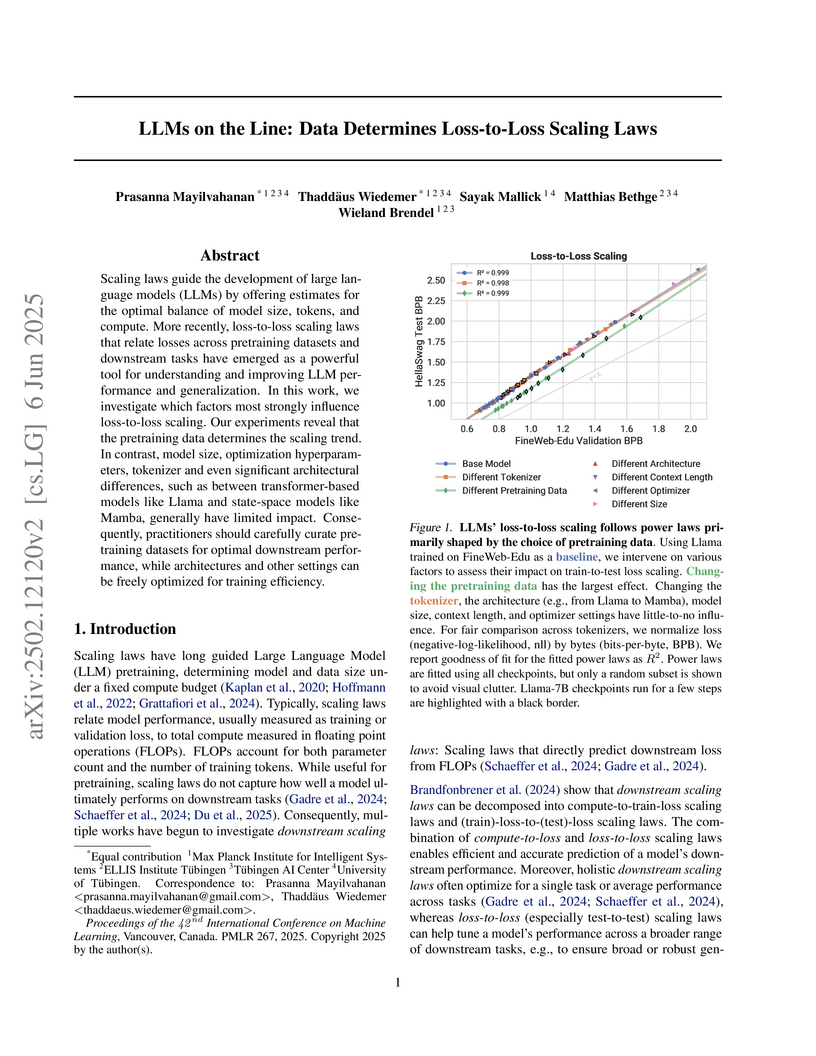
06 Jun 2025
Scaling laws guide the development of large language models (LLMs) by
offering estimates for the optimal balance of model size, tokens, and compute.
More recently, loss-to-loss scaling laws that relate losses across pretraining
datasets and downstream tasks have emerged as a powerful tool for understanding
and improving LLM performance. In this work, we investigate which factors most
strongly influence loss-to-loss scaling. Our experiments reveal that the
pretraining data and tokenizer determine the scaling trend. In contrast, model
size, optimization hyperparameters, and even significant architectural
differences, such as between transformer-based models like Llama and
state-space models like Mamba, have limited impact. Consequently, practitioners
should carefully curate suitable pretraining datasets for optimal downstream
performance, while architectures and other settings can be freely optimized for
training efficiency.

18 Sep 2023
Identification of cracks is essential to assess the structural integrity of
concrete infrastructure. However, robust crack segmentation remains a
challenging task for computer vision systems due to the diverse appearance of
concrete surfaces, variable lighting and weather conditions, and the
overlapping of different defects. In particular recent data-driven methods
struggle with the limited availability of data, the fine-grained and
time-consuming nature of crack annotation, and face subsequent difficulty in
generalizing to out-of-distribution samples. In this work, we move past these
challenges in a two-fold way. We introduce a high-fidelity crack graphics
simulator based on fractals and a corresponding fully-annotated crack dataset.
We then complement the latter with a system that learns generalizable
representations from simulation, by leveraging both a pointwise mutual
information estimate along with adaptive instance normalization as inductive
biases. Finally, we empirically highlight how different design choices are
symbiotic in bridging the simulation to real gap, and ultimately demonstrate
that our introduced system can effectively handle real-world crack
segmentation.

15 Sep 2025

It is commonly recognized that the primordial scalar spectral index is approximately , depending on the dataset. However, this view is being completely altered by the early dark energy (EDE) resolutions of the Hubble tension, known as the most prominent tension the standard CDM model is suffering from. In corresponding models with pre-recombination EDE, resolving the Hubble tension (i.e., achieving km/s/Mpc) must be accompanied by a shift of towards unity to maintain consistency with the cosmological data, which thus implies a scale invariant Harrison-Zel'dovich spectrum with . In this work, we strengthen and reconfirm this result with the latest ground-based CMB data from ACT DR6 and SPT-3G D1, the precise measurements at high multipoles beyond the Planck angular resolution and sensitivity. Our work again highlights the importance of re-examining our understanding on the very early Universe within the broader context of cosmological tensions.

04 Dec 2024
While many have shown how Large Language Models (LLMs) can be applied to a
diverse set of tasks, the critical issues of data contamination and
memorization are often glossed over. In this work, we address this concern for
tabular data. Specifically, we introduce a variety of different techniques to
assess whether a language model has seen a tabular dataset during training.
This investigation reveals that LLMs have memorized many popular tabular
datasets verbatim. We then compare the few-shot learning performance of LLMs on
datasets that were seen during training to the performance on datasets released
after training. We find that LLMs perform better on datasets seen during
training, indicating that memorization leads to overfitting. At the same time,
LLMs show non-trivial performance on novel datasets and are surprisingly robust
to data transformations. We then investigate the in-context statistical
learning abilities of LLMs. While LLMs are significantly better than random at
solving statistical classification problems, the sample efficiency of few-shot
learning lags behind traditional statistical learning algorithms, especially as
the dimension of the problem increases. This suggests that much of the observed
few-shot performance on novel real-world datasets is due to the LLM's world
knowledge. Overall, our results highlight the importance of testing whether an
LLM has seen an evaluation dataset during pre-training. We release the
this https URL Python package
to test LLMs for memorization of tabular datasets.
There are no more papers matching your filters at the moment.
