05 Apr 2025


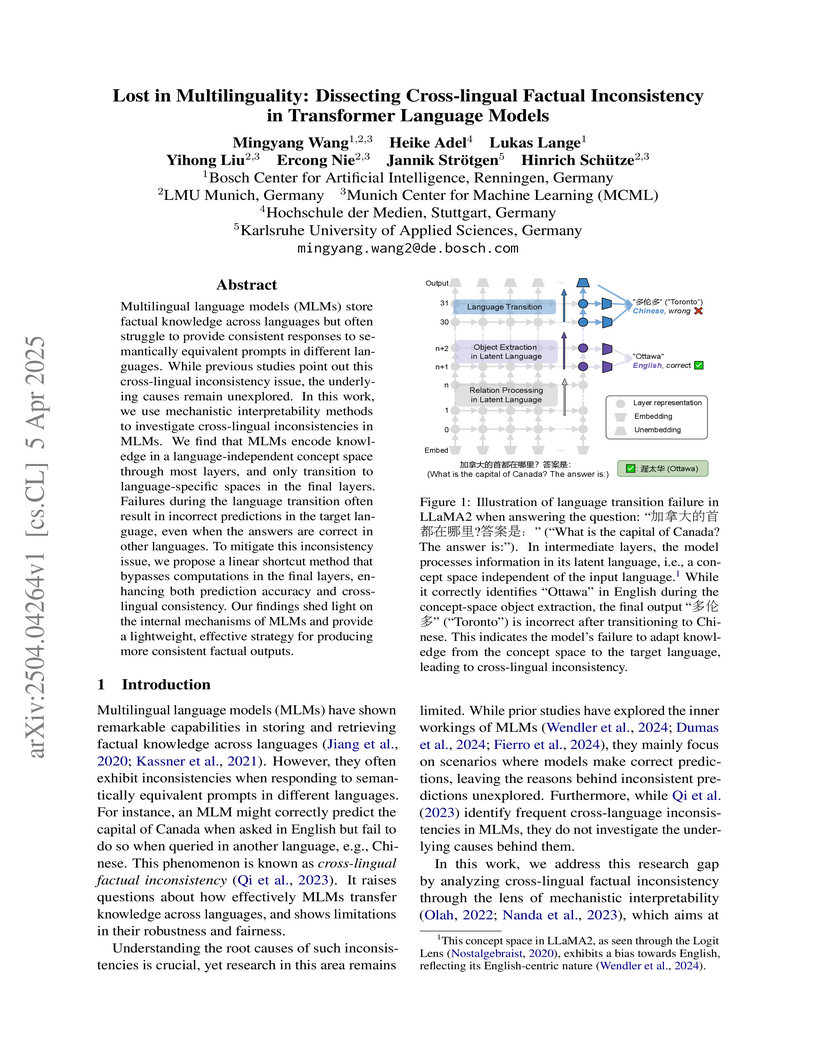
Researchers at the University of Bonn, Bosch Center for AI, and LMU Munich applied mechanistic interpretability to diagnose cross-lingual factual inconsistencies in transformer language models. They identified that errors primarily arise during the language transition in the final layers, where models fail to convert an internally known fact into the correct target language. A linear shortcut method was developed to bypass these error-prone layers, significantly improving both prediction accuracy and cross-lingual consistency over translation-based baselines.

29 Apr 2025


Researchers from the University of Stuttgart and TU Munich developed HI-SLAM2, a monocular geometry-aware Gaussian SLAM system that achieves both high rendering quality and geometric accuracy for fast scene reconstruction using only RGB input. The system consistently outperforms state-of-the-art RGB-only and many RGB-D methods across diverse indoor and outdoor datasets.

19 Oct 2025

This paper presents ETA-IK, a novel Execution-Time-Aware Inverse Kinematics method tailored for dual-arm robotic systems. The primary goal is to optimize motion execution time by leveraging the redundancy of both arms, specifically in tasks where only the relative pose of the robots is constrained, such as dual-arm scanning of unknown objects. Unlike traditional inverse kinematics methods that use surrogate metrics such as joint configuration distance, our method incorporates direct motion execution time and implicit collisions into the optimization process, thereby finding target joints that allow subsequent trajectory generation to get more efficient and collision-free motion. A neural network based execution time approximator is employed to predict time-efficient joint configurations while accounting for potential collisions. Through experimental evaluation on a system composed of a UR5 and a KUKA iiwa robot, we demonstrate significant reductions in execution time. The proposed method outperforms conventional approaches, showing improved motion efficiency without sacrificing positioning accuracy. These results highlight the potential of ETA-IK to improve the performance of dual-arm systems in applications, where efficiency and safety are paramount.

19 Sep 2025
Reasoning language models (RLMs) excel at complex tasks by leveraging a chain-of-thought process to generate structured intermediate steps. However, language mixing, i.e., reasoning steps containing tokens from languages other than the prompt, has been observed in their outputs and shown to affect performance, though its impact remains debated. We present the first systematic study of language mixing in RLMs, examining its patterns, impact, and internal causes across 15 languages, 7 task difficulty levels, and 18 subject areas, and show how all three factors influence language mixing. Moreover, we demonstrate that the choice of reasoning language significantly affects performance: forcing models to reason in Latin or Han scripts via constrained decoding notably improves accuracy. Finally, we show that the script composition of reasoning traces closely aligns with that of the model's internal representations, indicating that language mixing reflects latent processing preferences in RLMs. Our findings provide actionable insights for optimizing multilingual reasoning and open new directions for controlling reasoning languages to build more interpretable and adaptable RLMs.

02 Mar 2022
In this paper, we present a complete pipeline for 3D semantic mapping solely
based on a stereo camera system. The pipeline comprises a direct sparse visual
odometry front-end as well as a back-end for global optimization including GNSS
integration, and semantic 3D point cloud labeling. We propose a simple but
effective temporal voting scheme which improves the quality and consistency of
the 3D point labels. Qualitative and quantitative evaluations of our pipeline
are performed on the KITTI-360 dataset. The results show the effectiveness of
our proposed voting scheme and the capability of our pipeline for efficient
large-scale 3D semantic mapping. The large-scale mapping capabilities of our
pipeline is furthermore demonstrated by presenting a very large-scale semantic
map covering 8000 km of roads generated from data collected by a fleet of
vehicles.

19 Oct 2025
We propose MoRe-ERL, a framework that combines Episodic Reinforcement Learning (ERL) and residual learning, which refines preplanned reference trajectories into safe, feasible, and efficient task-specific trajectories. This framework is general enough to incorporate into arbitrary ERL methods and motion generators seamlessly. MoRe-ERL identifies trajectory segments requiring modification while preserving critical task-related maneuvers. Then it generates smooth residual adjustments using B-Spline-based movement primitives to ensure adaptability to dynamic task contexts and smoothness in trajectory refinement. Experimental results demonstrate that residual learning significantly outperforms training from scratch using ERL methods, achieving superior sample efficiency and task performance. Hardware evaluations further validate the framework, showing that policies trained in simulation can be directly deployed in real-world systems, exhibiting a minimal sim-to-real gap.
18 Feb 2025
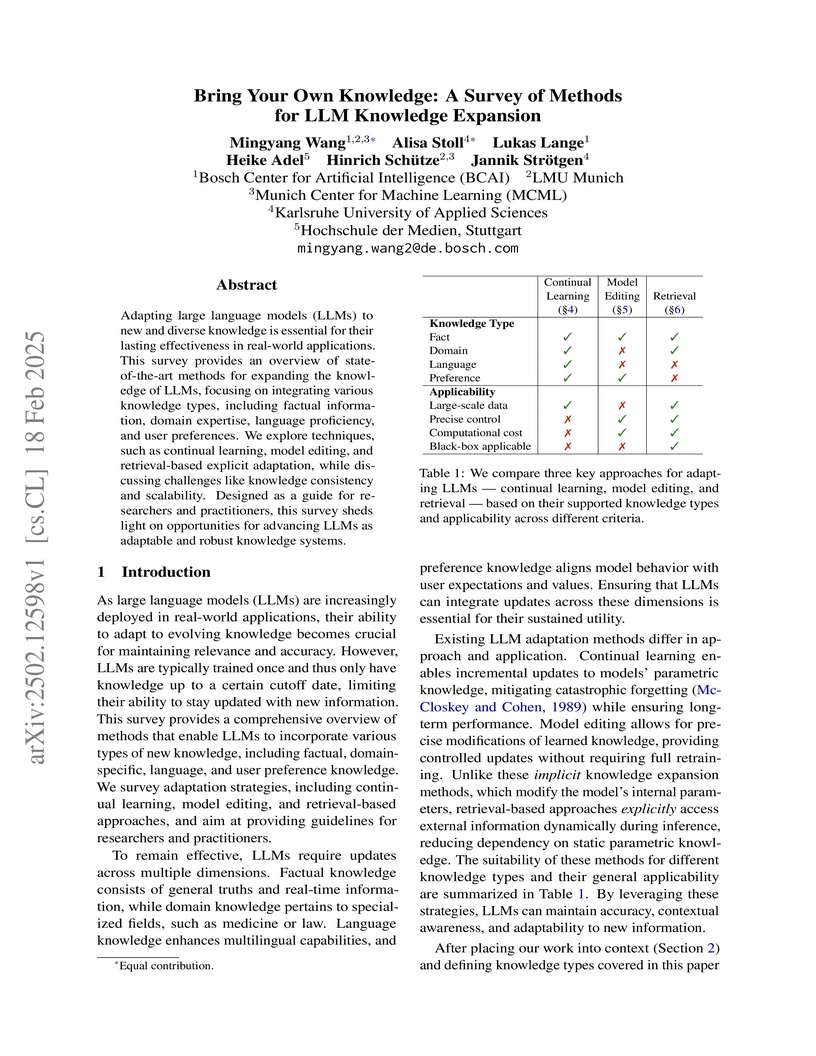
Wang et al. (2025) survey methods for Large Language Model (LLM) knowledge expansion, categorizing diverse knowledge types and three primary adaptation strategies. The work analyzes their applicability to enhance LLM dynamism and robustness, outlining current challenges and offering practical guidance.

07 Jul 2021
A major goal of materials design is to find material structures with desired properties and in a second step to find a processing path to reach one of these structures. In this paper, we propose and investigate a deep reinforcement learning approach for the optimization of processing paths. The goal is to find optimal processing paths in the material structure space that lead to target-structures, which have been identified beforehand to result in desired material properties. There exists a target set containing one or multiple different structures. Our proposed methods can find an optimal path from a start structure to a single target structure, or optimize the processing paths to one of the equivalent target-structures in the set. In the latter case, the algorithm learns during processing to simultaneously identify the best reachable target structure and the optimal path to it. The proposed methods belong to the family of model-free deep reinforcement learning algorithms. They are guided by structure representations as features of the process state and by a reward signal, which is formulated based on a distance function in the structure space. Model-free reinforcement learning algorithms learn through trial and error while interacting with the process. Thereby, they are not restricted to information from a priori sampled processing data and are able to adapt to the specific process. The optimization itself is model-free and does not require any prior knowledge about the process itself. We instantiate and evaluate the proposed methods by optimizing paths of a generic metal forming process. We show the ability of both methods to find processing paths leading close to target structures and the ability of the extended method to identify target-structures that can be reached effectively and efficiently and to focus on these targets for sample efficient processing path optimization.

20 Oct 2025
For the water-air system, the bulk density ratio is as high as about 1000; no model can fully tackle such a high density ratio system. In the Navier-Stokes and Euler equations, the density within the water-air interface is assumed to be a constant based on the Boussinesq approximation namely , which does not account for the true momentum evolution (-fluid velocity). Here, we present an alternative theory for the density evolution equations of immiscible fluids in computational fluid dynamics, differing from the concept of Navier-Stokes and Euler equations. Our derivation is built upon the physical principle of energy minimization from the aspect of thermodynamics. The present results provide a generalization of Bernoulli's principle for energy conservation and a general formulation for the sound speed. The present model can be applied for immiscible fluids with arbitrarily high density ratios, thereby, opening a new window for computational fluid dynamics both for compressible and incompressible fluids.

22 May 2023
Intermediate training of pre-trained transformer-based language models on
domain-specific data leads to substantial gains for downstream tasks. To
increase efficiency and prevent catastrophic forgetting alleviated from full
domain-adaptive pre-training, approaches such as adapters have been developed.
However, these require additional parameters for each layer, and are criticized
for their limited expressiveness. In this work, we introduce TADA, a novel
task-agnostic domain adaptation method which is modular, parameter-efficient,
and thus, data-efficient. Within TADA, we retrain the embeddings to learn
domain-aware input representations and tokenizers for the transformer encoder,
while freezing all other parameters of the model. Then, task-specific
fine-tuning is performed. We further conduct experiments with meta-embeddings
and newly introduced meta-tokenizers, resulting in one model per task in
multi-domain use cases. Our broad evaluation in 4 downstream tasks for 14
domains across single- and multi-domain setups and high- and low-resource
scenarios reveals that TADA is an effective and efficient alternative to full
domain-adaptive pre-training and adapters for domain adaptation, while not
introducing additional parameters or complex training steps.

15 Oct 2025
We present LiFMCR, a novel dataset for the registration of multiple micro lens array (MLA)-based light field cameras. While existing light field datasets are limited to single-camera setups and typically lack external ground truth, LiFMCR provides synchronized image sequences from two high-resolution Raytrix R32 plenoptic cameras, together with high-precision 6-degrees of freedom (DoF) poses recorded by a Vicon motion capture system. This unique combination enables rigorous evaluation of multi-camera light field registration methods.
As a baseline, we provide two complementary registration approaches: a robust 3D transformation estimation via a RANSAC-based method using cross-view point clouds, and a plenoptic PnP algorithm estimating extrinsic 6-DoF poses from single light field images. Both explicitly integrate the plenoptic camera model, enabling accurate and scalable multi-camera registration. Experiments show strong alignment with the ground truth, supporting reliable multi-view light field processing.
Project page: this https URL

11 Mar 2025
Accurate tool wear prediction is essential for maintaining productivity and
minimizing costs in machining. However, the complex nature of the tool wear
process poses significant challenges to achieving reliable predictions. This
study explores data-driven methods, in particular deep learning, for tool wear
prediction. Traditional data-driven approaches often focus on a single process,
relying on multi-sensor setups and extensive data generation, which limits
generalization to new settings. Moreover, multi-sensor integration is often
impractical in industrial environments. To address these limitations, this
research investigates the transferability of predictive models using minimal
training data, validated across two processes. Furthermore, it uses a simple
setup with a single acceleration sensor to establish a low-cost data generation
approach that facilitates the generalization of models to other processes via
transfer learning. The study evaluates several machine learning models,
including transformer-inspired convolutional neural networks (CNN), long
short-term memory networks (LSTM), support vector machines (SVM), and decision
trees, trained on different input formats such as feature vectors and
short-time Fourier transform (STFT). The performance of the models is evaluated
on two machines and on different amounts of training data, including scenarios
with significantly reduced datasets, providing insight into their effectiveness
under constrained data conditions. The results demonstrate the potential of
specific models and configurations for effective tool wear prediction,
contributing to the development of more adaptable and efficient predictive
maintenance strategies in machining. Notably, the ConvNeXt model has an
exceptional performance, achieving 99.1\% accuracy in identifying tool wear
using data from only four milling tools operated until they are worn.

03 Oct 2024
To ensure large language models contain up-to-date knowledge, they need to be
updated regularly. However, model editing is challenging as it might also
affect knowledge that is unrelated to the new data. State-of-the-art methods
identify parameters associated with specific knowledge and then modify them via
direct weight updates. However, these locate-and-edit methods suffer from heavy
computational overhead and lack theoretical validation. In contrast, directly
fine-tuning the model on requested edits affects the model's behavior on
unrelated knowledge, and significantly damages the model's generation fluency
and consistency. To address these challenges, we propose SAUL, a streamlined
model editing method that uses sentence concatenation with augmented random
facts for generation regularization. Evaluations on three model editing
benchmarks show that SAUL is a practical and reliable solution for model
editing outperforming state-of-the-art methods while maintaining generation
quality and reducing computational overhead.

26 Oct 2024
With the goal of efficiently computing collision-free robot motion trajectories in dynamically changing environments, we present results of a novel method for Heuristics Informed Robot Online Path Planning (HIRO). Dividing robot environments into static and dynamic elements, we use the static part for initializing a deterministic roadmap, which provides a lower bound of the final path cost as informed heuristics for fast path-finding. These heuristics guide a search tree to explore the roadmap during runtime. The search tree examines the edges using a fuzzy collision checking concerning the dynamic environment. Finally, the heuristics tree exploits knowledge fed back from the fuzzy collision checking module and updates the lower bound for the path cost. As we demonstrate in real-world experiments, the closed-loop formed by these three components significantly accelerates the planning procedure. An additional backtracking step ensures the feasibility of the resulting paths. Experiments in simulation and the real world show that HIRO can find collision-free paths considerably faster than baseline methods with and without prior knowledge of the environment.

07 Dec 2024



We consider the problem of designing typed concurrent calculi with
non-deterministic choice in which types leverage linearity for controlling
resources, thereby ensuring strong correctness properties for processes. This
problem is constrained by the delicate tension between non-determinism and
linearity. Prior work developed a session-typed {\pi}-calculus with standard
non-deterministic choice; well-typed processes enjoy type preservation and
deadlock-freedom. Central to this typed calculus is a lazy semantics that
gradually discards branches in choices. This lazy semantics, however, is
complex: various technical elements are needed to describe the
non-deterministic behavior of typed processes. This paper develops an entirely
new approach, based on an eager semantics, which more directly represents
choices and commitment. We present a {\pi}-calculus in which non-deterministic
choices are governed by this eager semantics and session types. We establish
its key correctness properties, including deadlock-freedom, and demonstrate its
expressivity by correctly translating a typed resource {\lambda}-calculus.

01 Dec 2020
Price-based demand response (PBDR) has recently been attributed great
economic but also environmental potential. However, the determination of its
short-term effects on carbon emissions requires the knowledge of marginal
emission factors (MEFs), which compared to grid mix emission factors (XEFs),
are cumbersome to calculate due to the complex characteristics of national
electricity markets. This study, therefore, proposes two merit order-based
methods to approximate hourly MEFs and applies it to readily available datasets
from 20 European countries for the years 2017-2019. Based on the resulting
electricity prices, MEFs, and XEFs, standardized daily load shifts were
simulated to quantify their effects on marginal costs and carbon emissions.
Finally, by repeating the load shift simulations for different carbon price
levels, the impact of the carbon price on the resulting carbon emissions was
analyzed. Interestingly, the simulated price-based load shifts led to increases
in operational carbon emissions for 8 of the 20 countries and to an average
increase of 2.1% across all 20 countries. Switching from price-based to
MEF-based load shifts reduced the corresponding carbon emissions to a decrease
of 35%, albeit with 56% lower monetary cost savings compared to the price-based
load shifts. Under specific circumstances, PBDR leads to an increase in carbon
emissions, mainly due to the economic advantage fuel sources such as lignite
and coal have in the merit order. However, as the price of carbon is increased,
the correlation between the carbon intensity and the marginal cost of the fuels
substantially increases. Therefore, with adequate carbon prices, PBDR can be an
effective tool for both economical and environmental improvement.

26 Jun 2024
In real-world environments, continual learning is essential for machine learning models, as they need to acquire new knowledge incrementally without forgetting what they have already learned. While pretrained language models have shown impressive capabilities on various static tasks, applying them to continual learning poses significant challenges, including avoiding catastrophic forgetting, facilitating knowledge transfer, and maintaining parameter efficiency. In this paper, we introduce MoCL-P, a novel lightweight continual learning method that addresses these challenges simultaneously. Unlike traditional approaches that continuously expand parameters for newly arriving tasks, MoCL-P integrates task representation-guided module composition with adaptive pruning, effectively balancing knowledge integration and computational overhead. Our evaluation across three continual learning benchmarks with up to 176 tasks shows that MoCL-P achieves state-of-the-art performance and improves parameter efficiency by up to three times, demonstrating its potential for practical applications where resource requirements are constrained.

18 Oct 2017
Linear Temporal Logic (LTL) is a widely used specification framework for
linear time properties of systems. The standard approach for verifying such
properties is by transforming LTL formulae to suitable -automata and
then applying model checking.
We revisit Vardi's transformation of an LTL formula to an alternating
-automaton and Wolper's LTL tableau method for satisfiability checking.
We observe that both constructions effectively rely on a decomposition of
formulae into linear factors.
Linear factors have been introduced previously by Antimirov in the context of
regular expressions.
We establish the notion of linear factors for LTL and verify essential
properties such as expansion and finiteness.
Our results shed new insights on the connection between the construction of
alternating -automata and semantic tableaux.

21 Feb 2020
Analytical treatments, formulated to predict the rate of the bainite transformation, define autocatalysis as the growth of the subunits at the bainite-austenite interface. Furthermore, the role of the stress-free transformation strain is often translated to a thermodynamic criterion that needs to be fulfilled for the growth of the subunits. In the present work, an elastic phase-field model, which elegantly recovers the sharp-interface relations, is employed to comprehensively explicate the effect of the elastic energy on the evolution of the subunits. The primary finding of the current analysis is that the role of eigenstrains in the bainite transformation is apparently complicated to be directly quantified as the thermodynamic constraint. It is realized that the inhomogeneous stress state, induced by the growth of the primary subunit, renders a spatially dependent ill- and well-favored condition for the growth of the secondary subunits. A favorability contour, which encloses the sections that facilitate the elastically preferred growth, is postulated based on the elastic interaction. Through the numerical analyses, the enhanced growth of the subunits within the favorability-contour is verified. Current investigations show that the morphology and size of the elastically preferred region respectively changes and increases with the progressive growth of the subunits.

02 Sep 2016
We consider the problem of static deadlock detection for programs in the Go
programming language which make use of synchronous channel communications. In
our analysis, regular expressions extended with a fork operator capture the
communication behavior of a program. Starting from a simple criterion that
characterizes traces of deadlock-free programs, we develop automata-based
methods to check for deadlock-freedom. The approach is implemented and
evaluated with a series of examples.
There are no more papers matching your filters at the moment.
