
20 Nov 2025



OpenAI researchers and collaborators evaluate GPT-5's utility in accelerating scientific research across diverse fields, demonstrating its capacity for contributing to known result rediscovery, literature search, collaborative problem-solving, and the generation of novel scientific findings. The model proved to compress research timelines from months to hours and provided verifiable new insights in mathematics, physics, and biology.
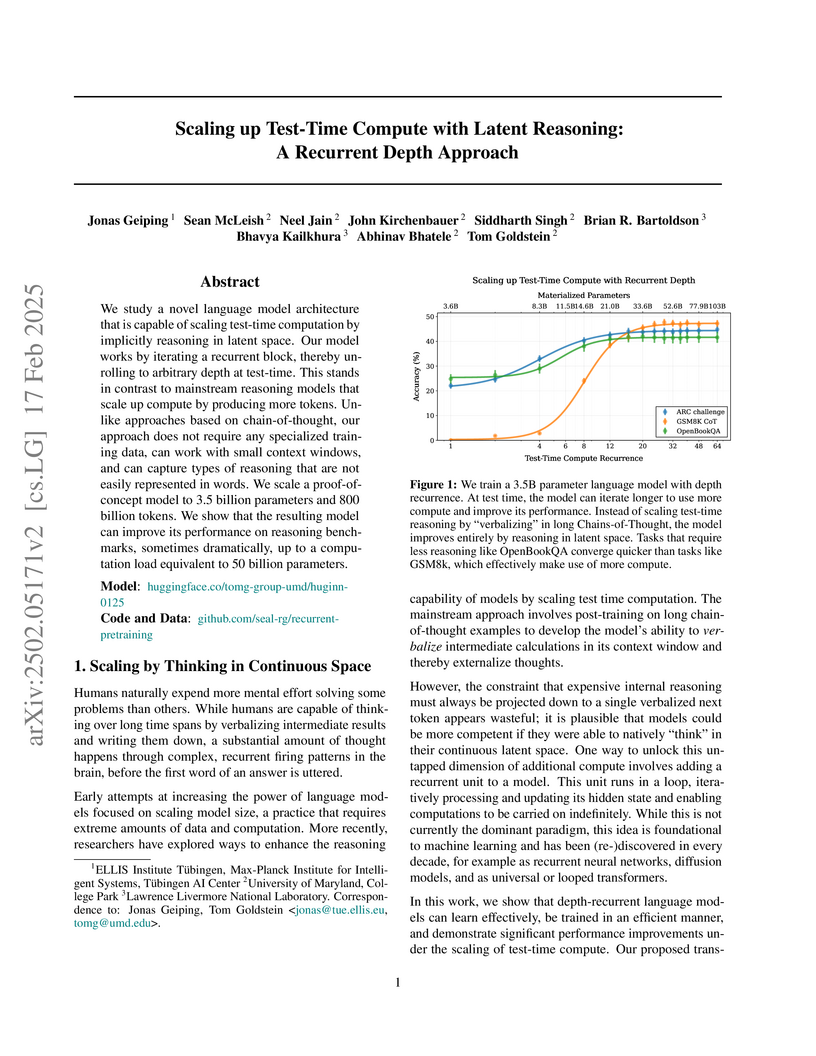
17 Feb 2025


Researchers from ELLIS Institute Tübingen, University of Maryland, and Lawrence Livermore National Laboratory introduce a recurrent depth transformer architecture that scales reasoning abilities by implicitly processing information in a continuous latent space. The 3.5 billion parameter model, Huginn-0125, trained on the Frontier supercomputer, demonstrates significant performance gains on reasoning benchmarks with increased test-time iterations, sometimes matching or exceeding larger models without requiring specialized Chain-of-Thought training data.

31 Jan 2024
The article introduces the stochastic N-k interdiction problem for power grid
operations and planning that aims to identify a subset of k components (out of
N components) that maximizes the expected damage, measured in terms of load
shed. Uncertainty is modeled through a fixed set of outage scenarios, where
each scenario represents a subset of components removed from the grid. We
formulate the stochastic N-k interdiction problem as a bi-level optimization
problem and propose two algorithmic solutions. The first approach reformulates
the bi-level stochastic optimization problem to a single level, mixed-integer
linear program (MILP) by dualizing the inner problem and solving the resulting
problem directly using a MILP solver to global optimality. The second is a
heuristic cutting-plane approach, which is exact under certain assumptions. We
compare these approaches in terms of computation time and solution quality
using the IEEE-Reliability Test System and present avenues for future research.

30 Sep 2024
 Michigan State University
Michigan State University University of Illinois at Urbana-Champaign
University of Illinois at Urbana-Champaign University of California, Santa Barbara
University of California, Santa Barbara Harvard University
Harvard University UCLA
UCLA Carnegie Mellon University
Carnegie Mellon University University of Notre Dame
University of Notre Dame University of Southern California
University of Southern California UC Berkeley
UC Berkeley Georgia Institute of Technology
Georgia Institute of Technology Stanford UniversityIllinois Institute of Technology
Stanford UniversityIllinois Institute of Technology Texas A&M University
Texas A&M University Yale University
Yale University Northwestern University
Northwestern University University of Georgia
University of Georgia Microsoft
Microsoft Columbia UniversityLehigh UniversityUniversity of Illinois Chicago
Columbia UniversityLehigh UniversityUniversity of Illinois Chicago Johns Hopkins University
Johns Hopkins University University of Maryland
University of Maryland University of Wisconsin-MadisonMassachusetts General Hospital
University of Wisconsin-MadisonMassachusetts General Hospital Mohamed bin Zayed University of Artificial IntelligenceSalesforce ResearchInstitut Polytechnique de Paris
Mohamed bin Zayed University of Artificial IntelligenceSalesforce ResearchInstitut Polytechnique de Paris Duke University
Duke University Virginia TechWilliam & MaryFlorida International UniversityUNC-Chapel HillCISPALawrence Livermore National LaboratorySamsungIBM Research AIDrexel UniversityUniversity of Tennessee, Knoxville
Virginia TechWilliam & MaryFlorida International UniversityUNC-Chapel HillCISPALawrence Livermore National LaboratorySamsungIBM Research AIDrexel UniversityUniversity of Tennessee, Knoxville
The TRUSTLLM framework and benchmark offer a comprehensive system for evaluating the trustworthiness of large language models across six key dimensions. This work reveals that while proprietary models generally exhibit higher trustworthiness, open-source models can also achieve strong performance in specific areas, highlighting challenges like 'over-alignment' and data leakage.
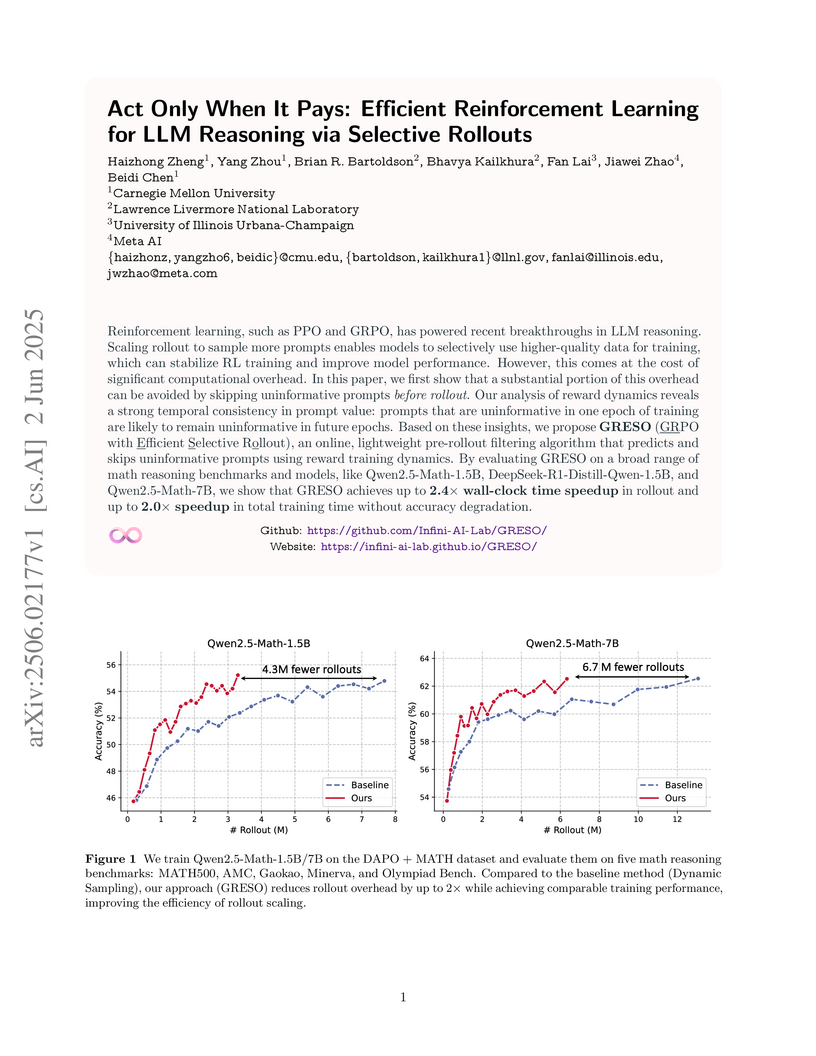
02 Jun 2025

GRESO efficiently trains large language models for reasoning by selectively filtering out uninformative prompts before costly rollouts, achieving comparable accuracy to state-of-the-art methods while reducing total training time by up to 2.0 times and rollouts by up to 3.35 times. This method addresses the major computational bottleneck in RL-based LLM fine-tuning.

10 Feb 2025


Speculative Diffusion Decoding (SpecDiff) accelerates Large Language Model inference by replacing the autoregressive drafter with a parallel discrete diffusion model, achieving up to 7.2x speedup over standard autoregressive decoding and 1.75x over existing speculative decoding while preserving output quality. This approach reduces computational overhead and enables the use of longer draft lengths.

22 Sep 2025

The Open Catalyst 2025 (OC25) dataset introduces the largest and most diverse collection of DFT calculations for solid-liquid interfaces, enabling machine learning models to accurately predict energies and forces in complex catalytic systems. This collaborative work from Meta FAIR, Lawrence Livermore National Laboratory, and Texas Tech University expands atomistic simulation capabilities beyond solid-gas interfaces, addressing critical challenges in sustainable energy and chemical production.

27 May 2025

Discrete diffusion models are a class of generative models that construct
sequences by progressively denoising samples from a categorical noise
distribution. Beyond their rapidly growing ability to generate coherent natural
language, these models present a new and important opportunity to enforce
sequence-level constraints, a capability that current autoregressive models
cannot natively provide. This paper capitalizes on this opportunity by
introducing Constrained Discrete Diffusion (CDD), a novel integration of
differentiable constraint optimization within the diffusion process to ensure
adherence to constraints, logic rules, or safety requirements for generated
sequences. Unlike conventional text generators that often rely on post-hoc
filtering or model retraining for controllable generation, CDD directly imposes
constraints into the discrete diffusion sampling process, resulting in a
training-free and effective approach. Experiments in toxicity-controlled text
generation, property-constrained molecule design, and instruction-constrained
text completion demonstrate that CDD achieves zero constraint violations in a
diverse array of tasks while preserving fluency, novelty, and coherence while
outperforming autoregressive and existing discrete diffusion approaches.

03 Dec 2025




Trajectory Balance with Asynchrony (TBA) introduces an asynchronous framework for Large Language Model (LLM) post-training, decoupling data generation from learning using the Trajectory Balance objective. This approach achieves up to 50x speedups in wall-clock time while improving performance on tasks such as mathematical reasoning, preference tuning, and automated red-teaming.

10 Jul 2024
Adversarial Robustness Limits via Scaling-Law and Human-Alignment Studies by Bartoldson et al. from Lawrence Livermore National Laboratory establishes empirical scaling laws and conducts human perception studies to redefine the practical limits of adversarial robustness in image classification. The research achieved a new state-of-the-art of 73.71% AutoAttack accuracy on CIFAR10 and demonstrated that a significant portion of adversarial examples are "invalid" and also confuse humans, suggesting a human-aligned robustness ceiling around 90%.

05 Jun 2025





This work introduces "The Common Pile v0.1," an 8TB dataset meticulously curated from public domain and strictly openly licensed text, aiming to provide a legally transparent foundation for large language model pretraining. It demonstrates that performant 7-billion parameter language models can be trained on this dataset, exhibiting competitive results compared to models trained on widely used but often unlicensed data sources, particularly excelling in coding and knowledge-based tasks.

03 Sep 2025

Dislocations are line defects in crystals that multiply and self-organize into a complex network during strain hardening. The length of dislocation links, connecting neighboring nodes within this network, contains crucial information about the evolving dislocation microstructure. By analyzing data from Discrete Dislocation Dynamics (DDD) simulations in face-centered cubic (fcc) Cu, we characterize the statistical distribution of link lengths of dislocation networks during strain hardening on individual slip systems. Our analysis reveals that link lengths on active slip systems follow a double-exponential distribution, while those on inactive slip systems conform to a single-exponential distribution. The distinctive long tail observed in the double-exponential distribution is attributed to the stress-induced bowing out of long links on active slip systems, a feature that disappears upon removal of the applied stress. We further demonstrate that both observed link length distributions can be explained by extending a one-dimensional Poisson process to include different growth functions. Specifically, the double-exponential distribution emerges when the growth rate for links exceeding a critical length becomes super-linear, which aligns with the physical phenomenon of long links bowing out under stress. This work advances our understanding of dislocation microstructure evolution during strain hardening and elucidates the underlying physical mechanisms governing its formation.

13 Jun 2025
We introduce AegisLLM, a cooperative multi-agent defense against adversarial attacks and information leakage. In AegisLLM, a structured workflow of autonomous agents - orchestrator, deflector, responder, and evaluator - collaborate to ensure safe and compliant LLM outputs, while self-improving over time through prompt optimization. We show that scaling agentic reasoning system at test-time - both by incorporating additional agent roles and by leveraging automated prompt optimization (such as DSPy)- substantially enhances robustness without compromising model utility. This test-time defense enables real-time adaptability to evolving attacks, without requiring model retraining. Comprehensive evaluations across key threat scenarios, including unlearning and jailbreaking, demonstrate the effectiveness of AegisLLM. On the WMDP unlearning benchmark, AegisLLM achieves near-perfect unlearning with only 20 training examples and fewer than 300 LM calls. For jailbreaking benchmarks, we achieve 51% improvement compared to the base model on StrongReject, with false refusal rates of only 7.9% on PHTest compared to 18-55% for comparable methods. Our results highlight the advantages of adaptive, agentic reasoning over static defenses, establishing AegisLLM as a strong runtime alternative to traditional approaches based on model modifications. Code is available at this https URL

28 May 2024
A new uncertainty quantification framework, Shifting Attention to Relevance (SAR), improves the reliability of Large Language Models by re-weighting uncertainty based on the semantic relevance of linguistic components. It yields an average of 7.1% AUROC improvement over prior methods in identifying incorrect free-form generations across various LLMs and datasets.

19 Mar 2024

OpenMC successfully demonstrates performance portability for Monte Carlo particle transport across Intel, NVIDIA, and AMD GPUs using a single OpenMP target offloading codebase. It achieved over 1 billion particles per second on complex reactor simulations and established Intel's Ponte Vecchio Max 1550 as a leading GPU architecture by outperforming NVIDIA A100, GH200, and AMD MI250X GPUs.

13 Nov 2025
Researchers from the University of Maryland and Lawrence Livermore National Laboratory investigated multi-node Large Language Model inference, identifying `all-reduce` communication as a key bottleneck in decode-heavy workloads. They developed NVRAR, an NVSHMEM-based `all-reduce` algorithm, which improved end-to-end inference performance by up to 1.86x on 32 GPUs for the Llama 3.1 70B model.

17 Oct 2025
Researchers at Lawrence Livermore National Laboratory devised three globalized strategies for the Carleman linear embedding method, enabling it to accurately model a broad spectrum of nonlinear dynamical systems, including those with multiple fixed points, limit cycles, and chaotic attractors. This advancement expands Carleman's utility for tasks like Koopman mode decomposition and positions it for future hybrid classical-quantum simulations.

17 Jul 2023


Spatial distributions of electrons ionized and scattered from ultra-low pressure gases are proposed and experimentally demonstrated as a method to directly measure the intensity of an ultra-high intensity laser pulse. Analytic models relating the peak scattered electron energy to the peak laser intensity are derived and compared to paraxial Runge-Kutta simulations highlighting two models suitable for describing electrons scattered from weakly paraxial beams () for intensities in the range of Wcm. Scattering energies are shown to be dependant on gas species emphasizing the need for specific gases for given intensity ranges. Direct measurements of the laser intensity at full power of two laser systems is demonstrated both showing a good agreement between indirect methods of intensity measurement and the proposed method. One experiment exhibited the role of spatial aberrations in the scattered electron distribution motivating a qualitative study on the effect. We propose the use of convolutional neural networks as a method for extracting quantitative information of the spatial structure of the laser at full power. We believe the presented technique to be a powerful tool that can be immediately implemented in many high-power laser facilities worldwide.

10 Oct 2023


NEFTune introduces random noise into the embedding vectors during instruction fine-tuning, consistently improving the conversational quality and instruction-following abilities of large language models. The method achieves substantial gains, such as a nearly 35 percentage point increase in AlpacaEval Win Rate for LLaMA-2-7B, by mitigating overfitting to instruction datasets without incurring additional computational cost.
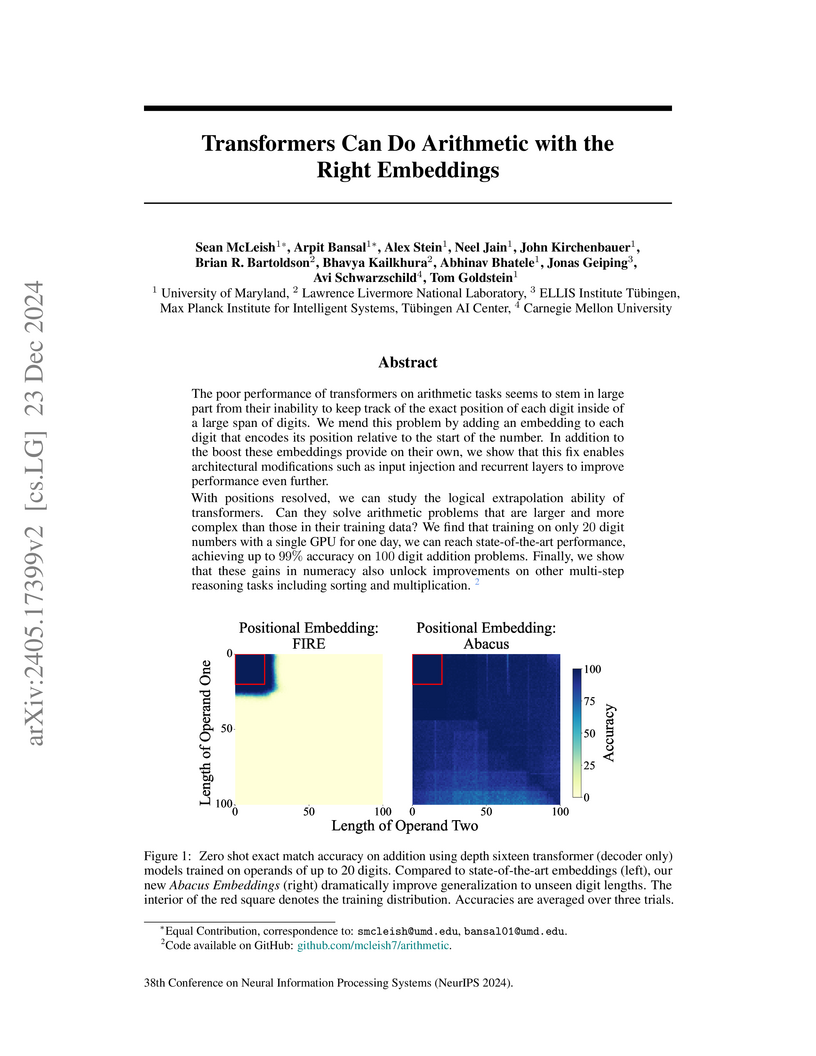
23 Dec 2024
Researchers at the University of Maryland and collaborators developed Abacus Embeddings and recurrent (Looped Transformer) architectures, enabling transformers to perform multi-digit arithmetic with a 6x generalization factor for addition, reaching over 99% accuracy on 100-digit problems after training on 20-digit examples. This approach effectively addresses the challenge of positional understanding in numerical sequences and transfers to other algorithmic tasks like multiplication and sorting.
There are no more papers matching your filters at the moment.
