
09 Oct 2025

OpenRLHF presents an open-source framework for efficient Reinforcement Learning from Human Feedback (RLHF) and Reinforcement Learning with Verifiable Rewards (RLVR) fine-tuning of Large Language Models. It achieves up to a 3.6x speedup over existing frameworks like DeepSpeed-Chat and TRL, and 1.68x over 'verl' in long Chain-of-Thought scenarios, while featuring a significantly more concise codebase.

13 Mar 2024

Researchers from Shanghai Jiao Tong University and Netease Fuxi AI Lab developed "Say Anything with Any Style" (SAAS), a framework that generates highly realistic and expressive talking face videos. It achieves this by employing discrete style representation learning and dynamic network modulation to produce diverse stylized expressions and head poses, outperforming prior methods in realism and style accuracy.
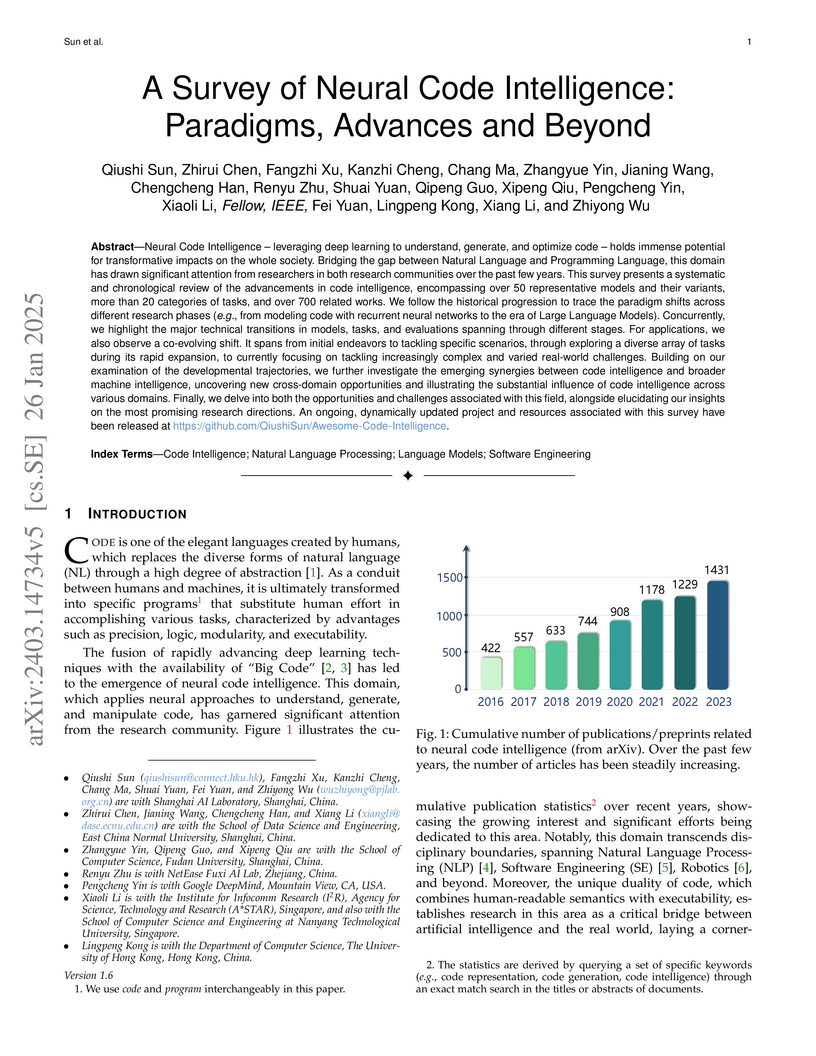
26 Jan 2025






A comprehensive survey maps the evolution of neural code intelligence, tracing its development from initial deep learning applications for code to the transformative impact of Large Language Models (LLMs). It reviews over 700 related works, 50 models, and 20 task categories, identifying key paradigm shifts and outlining future research directions.

17 Sep 2025

CrowdAgent introduces a multi-agent system that provides end-to-end process control for data annotation, dynamically managing Large Language Models, Small Language Models, and human experts. This system achieves superior annotation accuracy and substantial cost reductions across various multimodal classification tasks compared to existing hybrid and active learning methods.

04 Jun 2025

Researchers from Zhejiang University, University of Wisconsin Madison, William & Mary, and NetEase Fuxi AI Lab developed CanDist, a teacher-student framework that prompts Large Language Models to generate candidate annotations for uncertain data samples before a Small Language Model distills these into specific labels. This approach consistently outperforms existing LLM-based and SLM-based annotation baselines, showing a 5.47% improvement on the TREC dataset.

11 Sep 2024

Generating human-object interactions (HOIs) is critical with the tremendous advances of digital avatars. Existing datasets are typically limited to humans interacting with a single object while neglecting the ubiquitous manipulation of multiple objects. Thus, we propose HIMO, a large-scale MoCap dataset of full-body human interacting with multiple objects, containing 3.3K 4D HOI sequences and 4.08M 3D HOI frames. We also annotate HIMO with detailed textual descriptions and temporal segments, benchmarking two novel tasks of HOI synthesis conditioned on either the whole text prompt or the segmented text prompts as fine-grained timeline control. To address these novel tasks, we propose a dual-branch conditional diffusion model with a mutual interaction module for HOI synthesis. Besides, an auto-regressive generation pipeline is also designed to obtain smooth transitions between HOI segments. Experimental results demonstrate the generalization ability to unseen object geometries and temporal compositions.

22 Aug 2023
In this paper, we investigate the problem of learning with noisy labels in real-world annotation scenarios, where noise can be categorized into two types: factual noise and ambiguity noise. To better distinguish these noise types and utilize their semantics, we propose a novel sample selection-based approach for noisy label learning, called Proto-semi. Proto-semi initially divides all samples into the confident and unconfident datasets via warm-up. By leveraging the confident dataset, prototype vectors are constructed to capture class characteristics. Subsequently, the distances between the unconfident samples and the prototype vectors are calculated to facilitate noise classification. Based on these distances, the labels are either corrected or retained, resulting in the refinement of the confident and unconfident datasets. Finally, we introduce a semi-supervised learning method to enhance training. Empirical evaluations on a real-world annotated dataset substantiate the robustness of Proto-semi in handling the problem of learning from noisy labels. Meanwhile, the prototype-based repartitioning strategy is shown to be effective in mitigating the adverse impact of label noise. Our code and data are available at this https URL.

08 Oct 2024
In practice, reinforcement learning (RL) agents are often trained with a possibly imperfect proxy reward function, which may lead to a human-agent alignment issue (i.e., the learned policy either converges to non-optimal performance with low cumulative rewards, or achieves high cumulative rewards but in undesired manner). To tackle this issue, we consider a framework where a human labeler can provide additional feedback in the form of corrective actions, which expresses the labeler's action preferences although this feedback may possibly be imperfect as well. In this setting, to obtain a better-aligned policy guided by both learning signals, we propose a novel value-based deep RL algorithm called Iterative learning from Corrective actions and Proxy rewards (ICoPro), which cycles through three phases: (1) Solicit sparse corrective actions from a human labeler on the agent's demonstrated trajectories; (2) Incorporate these corrective actions into the Q-function using a margin loss to enforce adherence to labeler's preferences; (3) Train the agent with standard RL losses regularized with a margin loss to learn from proxy rewards and propagate the Q-values learned from human feedback. Moreover, another novel design in our approach is to integrate pseudo-labels from the target Q-network to reduce human labor and further stabilize training. We experimentally validate our proposition on a variety of tasks (Atari games and autonomous driving on highway). On the one hand, using proxy rewards with different levels of imperfection, our method can better align with human preferences and is more sample-efficient than baseline methods. On the other hand, facing corrective actions with different types of imperfection, our method can overcome the non-optimality of this feedback thanks to the guidance from proxy reward.

18 Feb 2023

Many real-world applications require an agent to make robust and deliberate decisions with multimodal information (e.g., robots with multi-sensory inputs). However, it is very challenging to train the agent via reinforcement learning (RL) due to the heterogeneity and dynamic importance of different modalities. Specifically, we observe that these issues make conventional RL methods difficult to learn a useful state representation in the end-to-end training with multimodal information. To address this, we propose a novel multimodal RL approach that can do multimodal alignment and importance enhancement according to their similarity and importance in terms of RL tasks respectively. By doing so, we are able to learn an effective state representation and consequentially improve the RL training process. We test our approach on several multimodal RL domains, showing that it outperforms state-of-the-art methods in terms of learning speed and policy quality.

14 Sep 2023
Inverse rendering methods aim to estimate geometry, materials and
illumination from multi-view RGB images. In order to achieve better
decomposition, recent approaches attempt to model indirect illuminations
reflected from different materials via Spherical Gaussians (SG), which,
however, tends to blur the high-frequency reflection details. In this paper, we
propose an end-to-end inverse rendering pipeline that decomposes materials and
illumination from multi-view images, while considering near-field indirect
illumination. In a nutshell, we introduce the Monte Carlo sampling based path
tracing and cache the indirect illumination as neural radiance, enabling a
physics-faithful and easy-to-optimize inverse rendering method. To enhance
efficiency and practicality, we leverage SG to represent the smooth environment
illuminations and apply importance sampling techniques. To supervise indirect
illuminations from unobserved directions, we develop a novel radiance
consistency constraint between implicit neural radiance and path tracing
results of unobserved rays along with the joint optimization of materials and
illuminations, thus significantly improving the decomposition performance.
Extensive experiments demonstrate that our method outperforms the
state-of-the-art on multiple synthetic and real datasets, especially in terms
of inter-reflection decomposition.Our code and data are available at
this https URL

26 Sep 2025
Testing MMORPGs (Massively Multiplayer Online Role-Playing Games) is a critical yet labor-intensive task in game development due to their complexity and frequent updating nature. Traditional automated game testing approaches struggle to achieve high state coverage and efficiency in these rich, open-ended environments, while existing LLM-based game-playing approaches are limited to shallow reasoning ability in understanding complex game state-action spaces and long-complex tasks. To address these challenges, we propose TITAN, an effective LLM-driven agent framework for intelligent MMORPG testing. TITAN incorporates four key components to: (1) perceive and abstract high-dimensional game states, (2) proactively optimize and prioritize available actions, (3) enable long-horizon reasoning with action trace memory and reflective self-correction, and (4) employ LLM-based oracles to detect potential functional and logic bugs with diagnostic reports.
We implement the prototype of TITAN and evaluate it on two large-scale commercial MMORPGs spanning both PC and mobile platforms. In our experiments, TITAN achieves significantly higher task completion rates (95%) and bug detection performance compared to existing automated game testing approaches. An ablation study further demonstrates that each core component of TITAN contributes substantially to its overall performance. Notably, TITAN detects four previously unknown bugs that prior testing approaches fail to identify. We provide an in-depth discussion of these results, which offer guidance for new avenues of advancing intelligent, general-purpose testing systems. Moreover, TITAN has been deployed in eight real-world game QA pipelines, underscoring its practical impact as an LLM-driven game testing framework.

17 Mar 2025
Accurately localizing audible objects based on audio-visual cues is the core
objective of audio-visual segmentation. Most previous methods emphasize spatial
or temporal multi-modal modeling, yet overlook challenges from ambiguous
audio-visual correspondences such as nearby visually similar but acoustically
different objects and frequent shifts in objects' sounding status.
Consequently, they may struggle to reliably correlate audio and visual cues,
leading to over- or under-segmentation. To address these limitations, we
propose a novel framework with two primary components: an audio-guided modality
alignment (AMA) module and an uncertainty estimation (UE) module. Instead of
indiscriminately correlating audio-visual cues through a global attention
mechanism, AMA performs audio-visual interactions within multiple groups and
consolidates group features into compact representations based on their
responsiveness to audio cues, effectively directing the model's attention to
audio-relevant areas. Leveraging contrastive learning, AMA further
distinguishes sounding regions from silent areas by treating features with
strong audio responses as positive samples and weaker responses as negatives.
Additionally, UE integrates spatial and temporal information to identify
high-uncertainty regions caused by frequent changes in sound state, reducing
prediction errors by lowering confidence in these areas. Experimental results
demonstrate that our approach achieves superior accuracy compared to existing
state-of-the-art methods, particularly in challenging scenarios where
traditional approaches struggle to maintain reliable segmentation.

03 Jan 2024
EmotionGesture introduces a framework for audio-driven generation of vivid and diverse emotional 3D co-speech gestures, achieving state-of-the-art performance with significantly improved realism, emotional accuracy, and temporal smoothness, while also presenting the new, larger TED Emotion dataset.

27 Mar 2023


Gait recognition is a biometric technology that recognizes the identity of humans through their walking patterns. Compared with other biometric technologies, gait recognition is more difficult to disguise and can be applied to the condition of long-distance without the cooperation of subjects. Thus, it has unique potential and wide application for crime prevention and social security. At present, most gait recognition methods directly extract features from the video frames to establish representations. However, these architectures learn representations from different features equally but do not pay enough attention to dynamic features, which refers to a representation of dynamic parts of silhouettes over time (e.g. legs). Since dynamic parts of the human body are more informative than other parts (e.g. bags) during walking, in this paper, we propose a novel and high-performance framework named DyGait. This is the first framework on gait recognition that is designed to focus on the extraction of dynamic features. Specifically, to take full advantage of the dynamic information, we propose a Dynamic Augmentation Module (DAM), which can automatically establish spatial-temporal feature representations of the dynamic parts of the human body. The experimental results show that our DyGait network outperforms other state-of-the-art gait recognition methods. It achieves an average Rank-1 accuracy of 71.4% on the GREW dataset, 66.3% on the Gait3D dataset, 98.4% on the CASIA-B dataset and 98.3% on the OU-MVLP dataset.

21 May 2025
Confidence estimation is crucial for reflecting the reliability of large
language models (LLMs), particularly in the widely used closed-source models.
Utilizing data augmentation for confidence estimation is viable, but
discussions focus on specific augmentation techniques, limiting its potential.
We study the impact of different data augmentation methods on confidence
estimation. Our findings indicate that data augmentation strategies can achieve
better performance and mitigate the impact of overconfidence. We investigate
the influential factors related to this and discover that, while preserving
semantic information, greater data diversity enhances the effectiveness of
augmentation. Furthermore, the impact of different augmentation strategies
varies across different range of application. Considering parameter
transferability and usability, the random combination of augmentations is a
promising choice.

07 Apr 2024
In human-centric content generation, the pre-trained text-to-image models struggle to produce user-wanted portrait images, which retain the identity of individuals while exhibiting diverse expressions. This paper introduces our efforts towards personalized face generation. To this end, we propose a novel multi-modal face generation framework, capable of simultaneous identity-expression control and more fine-grained expression synthesis. Our expression control is so sophisticated that it can be specialized by the fine-grained emotional vocabulary. We devise a novel diffusion model that can undertake the task of simultaneously face swapping and reenactment. Due to the entanglement of identity and expression, it's nontrivial to separately and precisely control them in one framework, thus has not been explored yet. To overcome this, we propose several innovative designs in the conditional diffusion model, including balancing identity and expression encoder, improved midpoint sampling, and explicitly background conditioning. Extensive experiments have demonstrated the controllability and scalability of the proposed framework, in comparison with state-of-the-art text-to-image, face swapping, and face reenactment methods.

10 Jun 2021

This paper unifies behavioral and response diversity within a comprehensive framework for open-ended learning in zero-sum games, incorporating it into the PSRO training objective. The approach generates policy populations with lower exploitability and higher robustness, validated across various game environments including the complex Google Research Football, and introduces Population Effectivity as a more suitable evaluation metric for diverse policy sets.

17 Mar 2025
Sound-guided object segmentation has drawn considerable attention for its
potential to enhance multimodal perception. Previous methods primarily focus on
developing advanced architectures to facilitate effective audio-visual
interactions, without fully addressing the inherent challenges posed by audio
natures, \emph{\ie}, (1) feature confusion due to the overlapping nature of
audio signals, and (2) audio-visual matching difficulty from the varied sounds
produced by the same object. To address these challenges, we propose Dynamic
Derivation and Elimination (DDESeg): a novel audio-visual segmentation
framework. Specifically, to mitigate feature confusion, DDESeg reconstructs the
semantic content of the mixed audio signal by enriching the distinct semantic
information of each individual source, deriving representations that preserve
the unique characteristics of each sound. To reduce the matching difficulty, we
introduce a discriminative feature learning module, which enhances the semantic
distinctiveness of generated audio representations. Considering that not all
derived audio representations directly correspond to visual features (e.g.,
off-screen sounds), we propose a dynamic elimination module to filter out
non-matching elements. This module facilitates targeted interaction between
sounding regions and relevant audio semantics. By scoring the interacted
features, we identify and filter out irrelevant audio information, ensuring
accurate audio-visual alignment. Comprehensive experiments demonstrate that our
framework achieves superior performance in AVS datasets.

01 Aug 2023
The audio-visual segmentation (AVS) task aims to segment sounding objects from a given video. Existing works mainly focus on fusing audio and visual features of a given video to achieve sounding object masks. However, we observed that prior arts are prone to segment a certain salient object in a video regardless of the audio information. This is because sounding objects are often the most salient ones in the AVS dataset. Thus, current AVS methods might fail to localize genuine sounding objects due to the dataset bias. In this work, we present an audio-visual instance-aware segmentation approach to overcome the dataset bias. In a nutshell, our method first localizes potential sounding objects in a video by an object segmentation network, and then associates the sounding object candidates with the given audio. We notice that an object could be a sounding object in one video but a silent one in another video. This would bring ambiguity in training our object segmentation network as only sounding objects have corresponding segmentation masks. We thus propose a silent object-aware segmentation objective to alleviate the ambiguity. Moreover, since the category information of audio is unknown, especially for multiple sounding sources, we propose to explore the audio-visual semantic correlation and then associate audio with potential objects. Specifically, we attend predicted audio category scores to potential instance masks and these scores will highlight corresponding sounding instances while suppressing inaudible ones. When we enforce the attended instance masks to resemble the ground-truth mask, we are able to establish audio-visual semantics correlation. Experimental results on the AVS benchmarks demonstrate that our method can effectively segment sounding objects without being biased to salient objects.

07 Mar 2023
For few-shot learning, it is still a critical challenge to realize photo-realistic face visually dubbing on high-resolution videos. Previous works fail to generate high-fidelity dubbing results. To address the above problem, this paper proposes a Deformation Inpainting Network (DINet) for high-resolution face visually dubbing. Different from previous works relying on multiple up-sample layers to directly generate pixels from latent embeddings, DINet performs spatial deformation on feature maps of reference images to better preserve high-frequency textural details. Specifically, DINet consists of one deformation part and one inpainting part. In the first part, five reference facial images adaptively perform spatial deformation to create deformed feature maps encoding mouth shapes at each frame, in order to align with the input driving audio and also the head poses of the input source images. In the second part, to produce face visually dubbing, a feature decoder is responsible for adaptively incorporating mouth movements from the deformed feature maps and other attributes (i.e., head pose and upper facial expression) from the source feature maps together. Finally, DINet achieves face visually dubbing with rich textural details. We conduct qualitative and quantitative comparisons to validate our DINet on high-resolution videos. The experimental results show that our method outperforms state-of-the-art works.
There are no more papers matching your filters at the moment.
