
05 Dec 2024

We present an experimental study on the drag reduction by polymers in Taylor-Couette turbulence at Reynolds numbers () ranging from to . In this regime, the Taylor vortex is present and accounts for more than 50\% of the total angular velocity flux. Polyacrylamide polymers with two different average molecular weights are used. It is found that the drag reduction rate increases with polymer concentration and approaches the maximum drag reduction (MDR) limit. At MDR, the friction factor follows the scaling, i.e., , similar to channel/pipe flows. However, the drag reduction rate is about at MDR, which is much lower than that in channel/pipe flows at comparable . We also find that the Reynolds shear stress does not vanish and the slope of the mean azimuthal velocity profile in the logarithmic layer remains unchanged at MDR. These behaviours are reminiscent of the low drag reduction regime reported in channel flow (Warholic et al., Exp. Fluids, vol. 27, issue 5, 1999, p. 461-472). We reveal that the lower drag reduction rate originates from the fact that polymers strongly suppress the turbulent flow while only slightly weaken the mean Taylor vortex. We further show that polymers steady the velocity boundary layer and suppress the small-scale Görtler vortices in the near-wall region. The former effect reduces the emission rate of both intense fast and slow plumes detached from the boundary layer, resulting in less flux transport from the inner cylinder to the outer one and reduces energy input into the bulk turbulent flow. Our results suggest that in turbulent flows, where secondary flow structures are statistically persistent and dominate the global transport properties of the system, the drag reduction efficiency of polymer additives is significantly diminished.

15 Oct 2025

The EO-Robotics Team developed EO-1, a 3B parameter embodied foundation model, employing a unified architecture and interleaved vision-text-action pretraining for general robot control. The model achieved state-of-the-art performance, surpassing GPT-4o and Gemini 1.5 Flash in overall embodied reasoning, and demonstrated an 86.0% completion rate across 28 diverse real-world manipulation tasks.

31 Oct 2025


IGGT introduces an end-to-end unified transformer that jointly learns 3D geometric reconstruction and instance-level semantics, leveraging a new InsScene-15K dataset with 3D-consistent instance annotations. The framework achieves state-of-the-art instance spatial tracking, superior open-vocabulary semantic segmentation, and maintains high geometric accuracy, while offering flexible integration with various Vision-Language Models.

15 Nov 2025

The MIRROR framework introduces a multi-modal self-supervised learning approach for computational pathology, integrating histopathology and transcriptomics by balancing modality alignment with modality-specific information retention and mitigating redundancy through a novel style clustering module. It demonstrates superior performance in cancer subtyping and survival prediction on TCGA cohorts, outperforming existing baselines in various diagnostic tasks.

22 Feb 2025

Llasa introduces a unified, Llama-based architecture for speech synthesis that simplifies the text-to-speech pipeline to a single Transformer and a novel speech tokenizer. The work systematically investigates train-time and inference-time scaling, showing consistent quality improvements and strong performance on both speech generation and understanding tasks.

03 Mar 2025

A collaborative team from HKUST and partners introduces Spark-TTS, a groundbreaking single-stream text-to-speech framework that achieves state-of-the-art voice synthesis while enabling precise attribute control through an innovative BiCodec tokenization system, demonstrating superior performance in zero-shot voice cloning and establishing new benchmarks with the comprehensive VoxBox dataset.

05 Sep 2025
A framework called "Align-Then-stEer (ATE)" enables pre-trained Vision-Language-Action (VLA) models to adapt to new robotic embodiments and diverse tasks using limited data. This is achieved through a two-stage process that establishes a unified latent space for action representation and then steers the generative VLA policies, yielding notable success rate improvements and enhanced robustness in both simulated and real-world robotic manipulation.

18 Jun 2025


Proprietary giants are increasingly dominating the race for ever-larger
language models. Can open-source, smaller models remain competitive across a
broad range of tasks? In this paper, we present the Avengers -- a simple recipe
that leverages the collective intelligence of these smaller models. The
Avengers builds upon four lightweight operations: (i) embedding: encode queries
using a text embedding model; (ii) clustering: group queries based on their
semantic similarity; (iii) scoring: scores each model's performance within each
cluster; and (iv) voting: improve outputs via repeated sampling and voting. At
inference time, each query is embedded and assigned to its nearest cluster. The
top-performing model(s) within that cluster are selected to generate the
response with repeated sampling. Remarkably, with 10 open-source models (~7B
parameters each), the Avengers surpasses GPT-4o, 4.1, and 4.5 in average
performance across 15 diverse datasets spanning mathematics, coding, logical
reasoning, general knowledge, and affective tasks. In particular, it surpasses
GPT-4.1 on mathematics tasks by 18.21% and on code tasks by 7.46%. Furthermore,
the Avengers delivers superior out-of-distribution generalization, and remains
robust across various embedding models, clustering algorithms, ensemble
strategies, and values of its sole parameter -- the number of clusters.

29 Sep 2025


Vision-language-action (VLA) models have shown strong generalization across tasks and embodiments; however, their reliance on large-scale human demonstrations limits their scalability owing to the cost and effort of manual data collection. Reinforcement learning (RL) offers a potential alternative to generate demonstrations autonomously, yet conventional RL algorithms often struggle on long-horizon manipulation tasks with sparse rewards. In this paper, we propose a modified diffusion policy optimization algorithm to generate high-quality and low-variance trajectories, which contributes to a diffusion RL-powered VLA training pipeline. Our algorithm benefits from not only the high expressiveness of diffusion models to explore complex and diverse behaviors but also the implicit regularization of the iterative denoising process to yield smooth and consistent demonstrations. We evaluate our approach on the LIBERO benchmark, which includes 130 long-horizon manipulation tasks, and show that the generated trajectories are smoother and more consistent than both human demonstrations and those from standard Gaussian RL policies. Further, training a VLA model exclusively on the diffusion RL-generated data achieves an average success rate of 81.9%, which outperforms the model trained on human data by +5.3% and that on Gaussian RL-generated data by +12.6%. The results highlight our diffusion RL as an effective alternative for generating abundant, high-quality, and low-variance demonstrations for VLA models.

28 Feb 2025
A new Horizontal/Vertical-Intensity (HVI) color space is introduced to address color distortion and noise in low-light image enhancement by decoupling brightness from color while mitigating red discontinuity and black plane noise. Paired with a Color and Intensity Decoupling Network (CIDNet), the approach achieves superior quantitative performance on multiple benchmarks with high efficiency, and the HVI space demonstrates generalizability when integrated into other state-of-the-art methods.

29 Mar 2025

CityGS-X, developed by Northwestern Polytechnical University and Shanghai AI Lab, presents a scalable architecture for efficient and geometrically accurate large-scale 3D scene reconstruction using 3D Gaussian Splatting. The method achieves state-of-the-art rendering quality and significantly faster training times on urban datasets by utilizing a parallelized hybrid hierarchical 3D representation, batch-level multi-task rendering, and a consistent progressive training scheme with enhanced depth priors.

28 Oct 2025
SoulX-Podcast introduces an LLM-driven generative framework for creating realistic, long-form, multi-speaker podcasts, incorporating diverse Chinese dialects and controllable paralinguistic cues. The system achieves state-of-the-art performance in multi-turn dialogue synthesis, exhibiting the lowest Character Error Rate (2.20) and highest cross-speaker consistency (0.599) on the Chinese ZipVoice-Dia benchmark, alongside strong zero-shot monologue capabilities.

03 Sep 2025

The OSUM-EChat system developed by the Audio, Speech and Language Processing Group at Northwestern Polytechnical University enhances end-to-end empathetic spoken chatbots by integrating an understanding-driven training strategy and a linguistic-paralinguistic dual think mechanism. It achieved a GPT-4 score of 72.0 on a new EChat-eval benchmark for multi-label empathy, demonstrating improved empathetic responsiveness and efficient speech understanding without relying on massive, proprietary datasets.

01 Feb 2025

FastUMI, developed by Shanghai AI Lab, redesigns the Universal Manipulation Interface to enable scalable and hardware-independent collection of high-quality, real-world robotic manipulation data. It achieves this through decoupled hardware, a streamlined software framework, and algorithmic enhancements tailored for first-person data, providing over 10,000 demonstration trajectories across 22 tasks.

28 Oct 2025



General world models represent a crucial pathway toward achieving Artificial General Intelligence (AGI), serving as the cornerstone for various applications ranging from virtual environments to decision-making systems. Recently, the emergence of the Sora model has attained significant attention due to its remarkable simulation capabilities, which exhibits an incipient comprehension of physical laws. In this survey, we embark on a comprehensive exploration of the latest advancements in world models. Our analysis navigates through the forefront of generative methodologies in video generation, where world models stand as pivotal constructs facilitating the synthesis of highly realistic visual content. Additionally, we scrutinize the burgeoning field of autonomous-driving world models, meticulously delineating their indispensable role in reshaping transportation and urban mobility. Furthermore, we delve into the intricacies inherent in world models deployed within autonomous agents, shedding light on their profound significance in enabling intelligent interactions within dynamic environmental contexts. At last, we examine challenges and limitations of world models, and discuss their potential future directions. We hope this survey can serve as a foundational reference for the research community and inspire continued innovation. This survey will be regularly updated at: this https URL.

17 May 2025
A method called Self-Representation Alignment (SRA) allows Diffusion Transformers (DiTs) to enhance their training and image generation quality by leveraging their intrinsic discriminative properties for self-guidance. This approach avoids reliance on external representation models or complex auxiliary training frameworks.

29 Mar 2025
COHERENT, developed by researchers including those at Shanghai AI Laboratory, introduces a centralized hierarchical framework that leverages Large Language Models for complex task planning in heterogeneous multi-robot systems. The framework achieves high success rates (0.975 in simulation) and demonstrates robust collaboration among diverse robot types, including quadrotors, robotic dogs, and robotic arms, in both simulated and real-world environments.
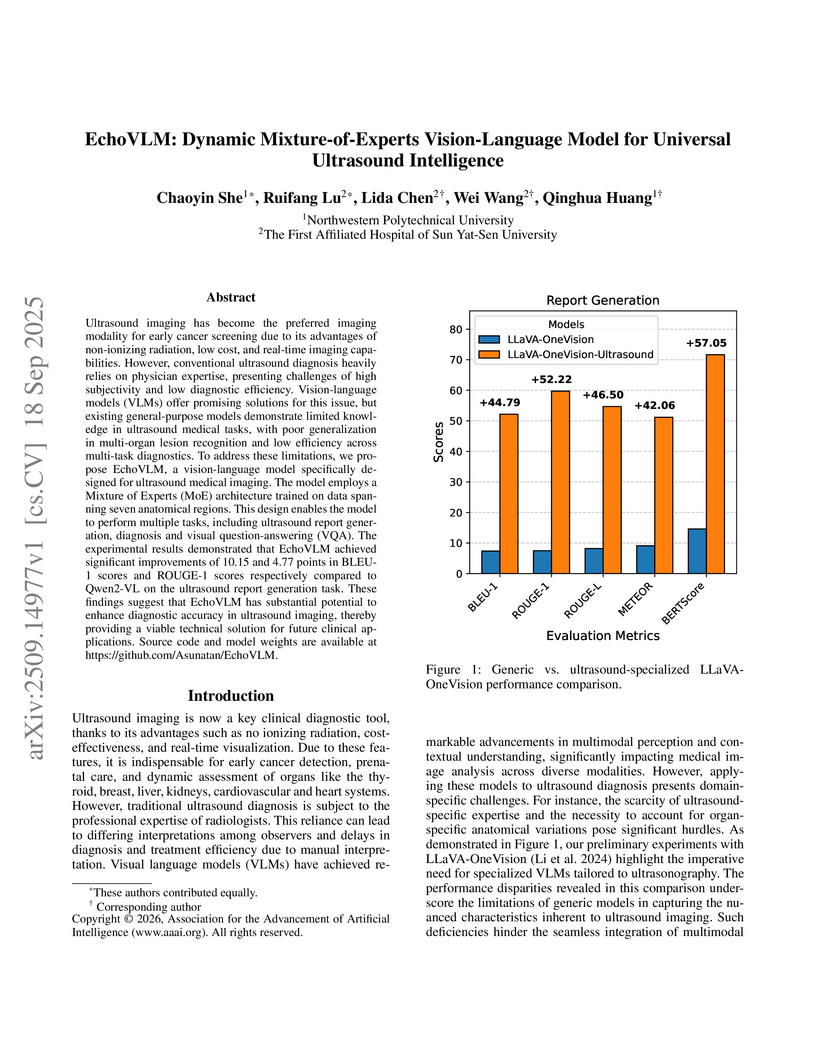
18 Sep 2025
Ultrasound imaging has become the preferred imaging modality for early cancer screening due to its advantages of non-ionizing radiation, low cost, and real-time imaging capabilities. However, conventional ultrasound diagnosis heavily relies on physician expertise, presenting challenges of high subjectivity and low diagnostic efficiency. Vision-language models (VLMs) offer promising solutions for this issue, but existing general-purpose models demonstrate limited knowledge in ultrasound medical tasks, with poor generalization in multi-organ lesion recognition and low efficiency across multi-task diagnostics. To address these limitations, we propose EchoVLM, a vision-language model specifically designed for ultrasound medical imaging. The model employs a Mixture of Experts (MoE) architecture trained on data spanning seven anatomical regions. This design enables the model to perform multiple tasks, including ultrasound report generation, diagnosis and visual question-answering (VQA). The experimental results demonstrated that EchoVLM achieved significant improvements of 10.15 and 4.77 points in BLEU-1 scores and ROUGE-1 scores respectively compared to Qwen2-VL on the ultrasound report generation task. These findings suggest that EchoVLM has substantial potential to enhance diagnostic accuracy in ultrasound imaging, thereby providing a viable technical solution for future clinical applications. Source code and model weights are available at this https URL.

05 Feb 2025
GenSE, developed by researchers from Northwestern Polytechnical University and Nanyang Technological University, introduces a generative speech enhancement framework that utilizes language models and a hierarchical processing structure. The system, which includes a novel single-quantizer neural codec called SimCodec, treats speech enhancement as a conditional language modeling task. It achieved superior DNSMOS, SECS, and Word Error Rate scores compared to existing state-of-the-art methods on standard datasets, demonstrating improved speech quality, speaker similarity, and generalization to unseen noise conditions.

05 Sep 2024


Large Language Models (LLMs) may suffer from hallucinations in real-world applications due to the lack of relevant knowledge. In contrast, knowledge graphs encompass extensive, multi-relational structures that store a vast array of symbolic facts. Consequently, integrating LLMs with knowledge graphs has been extensively explored, with Knowledge Graph Question Answering (KGQA) serving as a critical touchstone for the integration. This task requires LLMs to answer natural language questions by retrieving relevant triples from knowledge graphs. However, existing methods face two significant challenges: \textit{excessively long reasoning paths distracting from the answer generation}, and \textit{false-positive relations hindering the path refinement}. In this paper, we propose an iterative interactive KGQA framework that leverages the interactive learning capabilities of LLMs to perform reasoning and Debating over Graphs (DoG). Specifically, DoG employs a subgraph-focusing mechanism, allowing LLMs to perform answer trying after each reasoning step, thereby mitigating the impact of lengthy reasoning paths. On the other hand, DoG utilizes a multi-role debate team to gradually simplify complex questions, reducing the influence of false-positive relations. This debate mechanism ensures the reliability of the reasoning process. Experimental results on five public datasets demonstrate the effectiveness and superiority of our architecture. Notably, DoG outperforms the state-of-the-art method ToG by 23.7\% and 9.1\% in accuracy on WebQuestions and GrailQA, respectively. Furthermore, the integration experiments with various LLMs on the mentioned datasets highlight the flexibility of DoG. Code is available at \url{this https URL}.
There are no more papers matching your filters at the moment.
