
02 Oct 2025


Diagonal linear networks (DLNs) are a tractable model that captures several nontrivial behaviors in neural network training, such as initialization-dependent solutions and incremental learning. These phenomena are typically studied in isolation, leaving the overall dynamics insufficiently understood. In this work, we present a unified analysis of various phenomena in the gradient flow dynamics of DLNs. Using Dynamical Mean-Field Theory (DMFT), we derive a low-dimensional effective process that captures the asymptotic gradient flow dynamics in high dimensions. Analyzing this effective process yields new insights into DLN dynamics, including loss convergence rates and their trade-off with generalization, and systematically reproduces many of the previously observed phenomena. These findings deepen our understanding of DLNs and demonstrate the effectiveness of the DMFT approach in analyzing high-dimensional learning dynamics of neural networks.

26 Mar 2025

NLPrompt introduces a robust prompt learning framework for Vision-Language Models (VLMs) that addresses label noise by integrating Mean Absolute Error (MAE) loss with an optimal transport-based data purification method leveraging VLM text features. This framework achieves state-of-the-art accuracy across various synthetic and real-world noisy datasets, showing improved resilience over existing baselines.

17 Aug 2025


Mean-field Langevin dynamics (MFLD) is an optimization method derived by taking the mean-field limit of noisy gradient descent for two-layer neural networks in the mean-field regime. Recently, the propagation of chaos (PoC) for MFLD has gained attention as it provides a quantitative characterization of the optimization complexity in terms of the number of particles and iterations. A remarkable progress by Chen et al. (2022) showed that the approximation error due to finite particles remains uniform in time and diminishes as the number of particles increases. In this paper, by refining the defective log-Sobolev inequality -- a key result from that earlier work -- under the neural network training setting, we establish an improved PoC result for MFLD, which removes the exponential dependence on the regularization coefficient from the particle approximation term of the optimization complexity. As an application, we propose a PoC-based model ensemble strategy with theoretical guarantees.
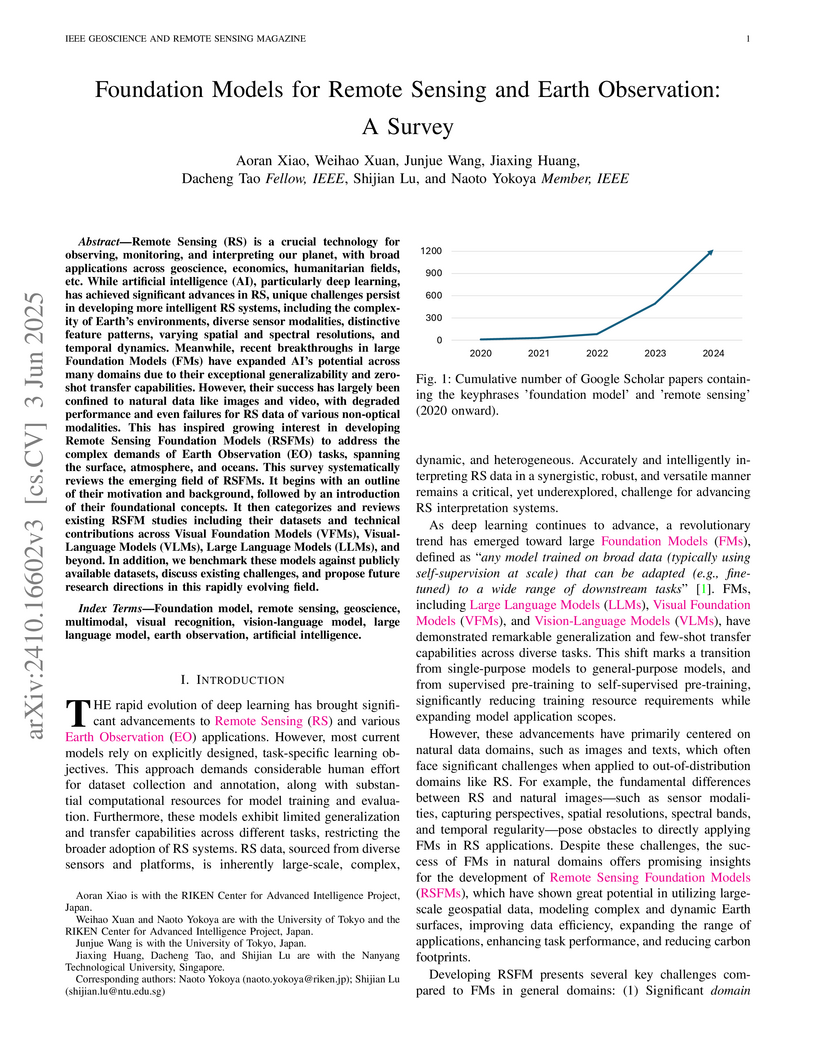
03 Jun 2025

This comprehensive survey maps the emerging landscape of Remote Sensing Foundation Models (RSFMs), systematically reviewing current advancements, categorizing models, and analyzing their performance to address the unique challenges of Earth observation data. It identifies the critical role of domain-specific pre-training and self-supervised learning while highlighting challenges in multimodal integration and data scale.

11 Aug 2025
Asymptotically unbiased priors, introduced by Hartigan (1965), are designed to achieve second-order unbiasedness of Bayes estimators. This paper extends Hartigan's framework to non-i.i.d. models by deriving a system of partial differential equations that characterizes asymptotically unbiased priors. Furthermore, we establish a necessary and sufficient condition for the existence of such priors and propose a simple procedure for constructing them. The proposed method is applied to the linear regression model and the nested error regression model (also known as the random effects model). Simulation studies evaluate the frequentist properties of the Bayes estimator under the asymptotically unbiased prior for the nested error regression model, highlighting its effectiveness in small-sample settings.

19 Nov 2024

Recent advances in fine-tuning Vision-Language Models (VLMs) have witnessed
the success of prompt tuning and adapter tuning, while the classic model
fine-tuning on inherent parameters seems to be overlooked. It is believed that
fine-tuning the parameters of VLMs with few-shot samples corrupts the
pre-trained knowledge since fine-tuning the CLIP model even degrades
performance. In this paper, we revisit this viewpoint, and propose a new
perspective: fine-tuning the specific parameters instead of all will uncover
the power of classic model fine-tuning on VLMs. Through our meticulous study,
we propose ClipFit, a simple yet effective method to fine-tune CLIP without
introducing any overhead of extra parameters. We demonstrate that by only
fine-tuning the specific bias terms and normalization layers, ClipFit can
improve the performance of zero-shot CLIP by 7.27\% average harmonic mean
accuracy. Lastly, to understand how fine-tuning in CLIPFit affects the
pre-trained models, we conducted extensive experimental analyses w.r.t. changes
in internal parameters and representations. We found that low-level text bias
layers and the first layer normalization layer change much more than other
layers. The code is available at \url{this https URL}.

25 Feb 2025

The imperative to eliminate undesirable data memorization underscores the
significance of machine unlearning for large language models (LLMs). Recent
research has introduced a series of promising unlearning methods, notably
boosting the practical significance of the field. Nevertheless, adopting a
proper evaluation framework to reflect the true unlearning efficacy is also
essential yet has not received adequate attention. This paper seeks to refine
the evaluation of LLM unlearning by addressing two key challenges -- a) the
robustness of evaluation metrics and b) the trade-offs between competing goals.
The first challenge stems from findings that current metrics are susceptible to
various red teaming scenarios. It indicates that they may not reflect the true
extent of knowledge retained by LLMs but rather tend to mirror superficial
model behaviors, thus prone to attacks. We address this issue by devising and
assessing a series of candidate metrics, selecting the most robust ones under
various types of attacks. The second challenge arises from the conflicting
goals of eliminating unwanted knowledge while retaining those of others. This
trade-off between unlearning and retention often fails to conform the Pareto
frontier, rendering it subtle to compare the efficacy between methods that
excel only in either unlearning or retention. We handle this issue by proposing
a calibration method that can restore the original performance on non-targeted
data after unlearning, thereby allowing us to focus exclusively on assessing
the strength of unlearning. Our evaluation framework notably enhances the
effectiveness when assessing and comparing various LLM unlearning methods,
further allowing us to benchmark existing works, identify their proper
hyper-parameters, and explore new tricks to enhance their practical efficacy.

05 Jun 2025

Large language model (LLM) unlearning has demonstrated its essential role in
removing privacy and copyright-related responses, crucial for their legal and
safe applications. However, the pursuit of complete unlearning often comes with
substantial costs due to its compromises in their general functionality,
leading to a notorious trade-off between unlearning and retention. It motivates
this paper to explore enhanced unlearning schemes that can mitigate this
trade-off. Specifically, we propose Gradient Rectified Unlearning (GRU), an
improved framework that regulates the directions of gradient updates during the
unlearning procedure such that their side impacts on other, unrelated responses
can be minimized. GRU is easy and general to implement, demonstrating practical
effectiveness across a variety of well-established unlearning benchmarks.

24 Jul 2025

Black-box optimization (BBO) is used in materials design, drug discovery, and hyperparameter tuning in machine learning. The world is experiencing several of these problems. In this review, a factorization machine with quantum annealing or with quadratic-optimization annealing (FMQA) algorithm to realize fast computations of BBO using Ising machines (IMs) is discussed. The FMQA algorithm uses a factorization machine (FM) as a surrogate model for BBO. The FM model can be directly transformed into a quadratic unconstrained binary optimization model that can be solved using IMs. This makes it possible to optimize the acquisition function in BBO, which is a difficult task using conventional methods without IMs. Consequently, it has the advantage of handling large BBO problems. To be able to perform BBO with the FMQA algorithm immediately, we introduce the FMQA algorithm along with Python packages to run it. In addition, we review examples of applications of the FMQA algorithm in various fields, including physics, chemistry, materials science, and social sciences. These successful examples include binary and integer optimization problems, as well as more general optimization problems involving graphs, networks, and strings, using a binary variational autoencoder. We believe that BBO using the FMQA algorithm will become a key technology in IMs including quantum annealers.

15 Oct 2025

Large language model (LLM) alignment is typically achieved through learning from human preference comparisons, making the quality of preference data critical to its success. Existing studies often pre-process raw training datasets to identify valuable preference pairs using external reward models or off-the-shelf LLMs, achieving improved overall performance but rarely examining whether individual, selected data point is genuinely beneficial. We assess data quality through individual influence on validation data using our newly proposed truncated influence function (TIF), which mitigates the over-scoring present in traditional measures and reveals that preference data quality is inherently a property of the model. In other words, a data pair that benefits one model may harm another. This leaves the need to improve the preference data selection approaches to be adapting to specific models. To this end, we introduce two candidate scoring functions (SFs) that are computationally simpler than TIF and positively correlated with it. They are also model dependent and can serve as potential indicators of individual data quality for preference data selection. Furthermore, we observe that these SFs inherently exhibit errors when compared to TIF. To this end, we combine them to offset their diverse error sources, resulting in a simple yet effective data selection rule that enables the models to achieve a more precise selection of valuable preference data. We conduct experiments across diverse alignment benchmarks and various LLM families, with results demonstrating that better alignment performance can be achieved using less data, showing the generality of our findings and new methods.

16 Jan 2025


SoccerSynth-Detection is a synthetic dataset generated from an enhanced soccer simulator that provides pixel-accurate bounding box annotations for players and balls. Models trained on this dataset demonstrate generalization to real-world soccer videos and consistently improve performance as a pre-training resource, particularly in low-data scenarios.

23 Oct 2025
Transformers have demonstrated exceptional performance across a wide range of domains. While their ability to perform reinforcement learning in-context has been established both theoretically and empirically, their behavior in non-stationary environments remains less understood. In this study, we address this gap by showing that transformers can achieve nearly optimal dynamic regret bounds in non-stationary settings. We prove that transformers are capable of approximating strategies used to handle non-stationary environments and can learn the approximator in the in-context learning setup. Our experiments further show that transformers can match or even outperform existing expert algorithms in such environments.

12 Oct 2022
SPD domain-specific batch normalization to crack interpretable unsupervised domain adaptation in EEG
SPD domain-specific batch normalization to crack interpretable unsupervised domain adaptation in EEG
Electroencephalography (EEG) provides access to neuronal dynamics non-invasively with millisecond resolution, rendering it a viable method in neuroscience and healthcare. However, its utility is limited as current EEG technology does not generalize well across domains (i.e., sessions and subjects) without expensive supervised re-calibration. Contemporary methods cast this transfer learning (TL) problem as a multi-source/-target unsupervised domain adaptation (UDA) problem and address it with deep learning or shallow, Riemannian geometry aware alignment methods. Both directions have, so far, failed to consistently close the performance gap to state-of-the-art domain-specific methods based on tangent space mapping (TSM) on the symmetric positive definite (SPD) manifold. Here, we propose a theory-based machine learning framework that enables, for the first time, learning domain-invariant TSM models in an end-to-end fashion. To achieve this, we propose a new building block for geometric deep learning, which we denote SPD domain-specific momentum batch normalization (SPDDSMBN). A SPDDSMBN layer can transform domain-specific SPD inputs into domain-invariant SPD outputs, and can be readily applied to multi-source/-target and online UDA scenarios. In extensive experiments with 6 diverse EEG brain-computer interface (BCI) datasets, we obtain state-of-the-art performance in inter-session and -subject TL with a simple, intrinsically interpretable network architecture, which we denote TSMNet.

05 Feb 2025




In the last decade, the rapid development of deep learning (DL) has made it
possible to perform automatic, accurate, and robust Change Detection (CD) on
large volumes of Remote Sensing Images (RSIs). However, despite advances in CD
methods, their practical application in real-world contexts remains limited due
to the diverse input data and the applicational context. For example, the
collected RSIs can be time-series observations, and more informative results
are required to indicate the time of change or the specific change category.
Moreover, training a Deep Neural Network (DNN) requires a massive amount of
training samples, whereas in many cases these samples are difficult to collect.
To address these challenges, various specific CD methods have been developed
considering different application scenarios and training resources.
Additionally, recent advancements in image generation, self-supervision, and
visual foundation models (VFMs) have opened up new approaches to address the
'data-hungry' issue of DL-based CD. The development of these methods in broader
application scenarios requires further investigation and discussion. Therefore,
this article summarizes the literature methods for different CD tasks and the
available strategies and techniques to train and deploy DL-based CD methods in
sample-limited scenarios. We expect that this survey can provide new insights
and inspiration for researchers in this field to develop more effective CD
methods that can be applied in a wider range of contexts.

03 May 2022


A study precisely characterizes how a single gradient step on a two-layer neural network's first layer initiates feature learning, demonstrating improved prediction risk over random features. The analysis shows that large learning rates enable the network to learn nonlinear components of the target function, moving beyond the capabilities of fixed-feature kernel models.

02 Aug 2018


Uncertainty computation in deep learning is essential to design robust and reliable systems. Variational inference (VI) is a promising approach for such computation, but requires more effort to implement and execute compared to maximum-likelihood methods. In this paper, we propose new natural-gradient algorithms to reduce such efforts for Gaussian mean-field VI. Our algorithms can be implemented within the Adam optimizer by perturbing the network weights during gradient evaluations, and uncertainty estimates can be cheaply obtained by using the vector that adapts the learning rate. This requires lower memory, computation, and implementation effort than existing VI methods, while obtaining uncertainty estimates of comparable quality. Our empirical results confirm this and further suggest that the weight-perturbation in our algorithm could be useful for exploration in reinforcement learning and stochastic optimization.

31 Oct 2025
Despite remarkable progress in recent years, vision language models (VLMs) remain prone to overconfidence and hallucinations on tasks such as Visual Question Answering (VQA) and Visual Reasoning. Bayesian methods can potentially improve reliability by helping models selectively predict, that is, models respond only when they are sufficiently confident. Unfortunately, Bayesian methods are often assumed to be costly and ineffective for large models, and so far there exists little evidence to show otherwise, especially for multimodal applications. Here, we show the effectiveness and competitive edge of variational Bayes for selective prediction in VQA for the first time. We build on recent advances in variational methods for deep learning and propose an extension called "Variational VQA". This method improves calibration and yields significant gains for selective prediction on VQA and Visual Reasoning, particularly when the error tolerance is low (). Often, just one posterior sample can yield more reliable answers than those obtained by models trained with AdamW. In addition, we propose a new risk-averse selector that outperforms standard sample averaging by considering the variance of predictions. Overall, we present compelling evidence that variational learning is a viable option to make large VLMs safer and more trustworthy.

28 Jul 2025
Sparse regularization is fundamental in signal processing for efficient signal recovery and feature extraction. However, it faces a fundamental dilemma: the most powerful sparsity-inducing penalties are often non-differentiable, conflicting with gradient-based optimizers that dominate the field. We introduce WEEP (Weakly-convex Envelope of Piecewise Penalty), a novel, fully differentiable sparse regularizer derived from the weakly-convex envelope framework. WEEP provides strong, unbiased sparsity while maintaining full differentiability and L-smoothness, making it natively compatible with any gradient-based optimizer. This resolves the conflict between statistical performance and computational tractability. We demonstrate superior performance compared to the L1-norm and other established non-convex sparse regularizers on challenging signal and image denoising tasks.

15 Oct 2025
Vision-Language-Action (VLA) models have achieved revolutionary progress in robot learning, enabling robots to execute complex physical robot tasks from natural language instructions. Despite this progress, their adversarial robustness remains underexplored. In this work, we propose both adversarial patch attack and corresponding defense strategies for VLA models. We first introduce the Embedding Disruption Patch Attack (EDPA), a model-agnostic adversarial attack that generates patches directly placeable within the camera's view. In comparison to prior methods, EDPA can be readily applied to different VLA models without requiring prior knowledge of the model architecture, or the controlled robotic manipulator. EDPA constructs these patches by (i) disrupting the semantic alignment between visual and textual latent representations, and (ii) maximizing the discrepancy of latent representations between adversarial and corresponding clean visual inputs. Through the optimization of these objectives, EDPA distorts the VLA's interpretation of visual information, causing the model to repeatedly generate incorrect actions and ultimately result in failure to complete the given robotic task. To counter this, we propose an adversarial fine-tuning scheme for the visual encoder, in which the encoder is optimized to produce similar latent representations for both clean and adversarially perturbed visual inputs. Extensive evaluations on the widely recognized LIBERO robotic simulation benchmark demonstrate that EDPA substantially increases the task failure rate of cutting-edge VLA models, while our proposed defense effectively mitigates this degradation. The codebase is accessible via the homepage at this https URL.

25 Feb 2022
As an example of the nonlinear Fokker-Planck equation, the mean field Langevin dynamics recently attracts attention due to its connection to (noisy) gradient descent on infinitely wide neural networks in the mean field regime, and hence the convergence property of the dynamics is of great theoretical interest. In this work, we give a concise and self-contained convergence rate analysis of the mean field Langevin dynamics with respect to the (regularized) objective function in both continuous and discrete time settings. The key ingredient of our proof is a proximal Gibbs distribution associated with the dynamics, which, in combination with techniques in [Vempala and Wibisono (2019)], allows us to develop a simple convergence theory parallel to classical results in convex optimization. Furthermore, we reveal that connects to the duality gap in the empirical risk minimization setting, which enables efficient empirical evaluation of the algorithm convergence.
There are no more papers matching your filters at the moment.
