
03 Sep 2025



This paper addresses the issues of parameter redundancy, rigid structure, and limited task adaptability in the fine-tuning of large language models. It proposes an adapter-based fine-tuning method built on a structure-learnable mechanism. By introducing differentiable gating functions and structural sparsity control variables, the method enables automatic optimization of adapter insertion points, activation paths, and module combinations. This allows the model to adjust its structure flexibly in multi-task settings to match different task characteristics. With the backbone parameters kept frozen, the method uses a structure search mechanism to guide the dynamic construction of task-specific efficient substructures during training. This significantly improves parameter utilization and representational capacity. In addition, the paper designs a set of sensitivity analysis experiments to systematically evaluate the effects of sparsity weight, noise injection ratio, and data perturbation on model performance. These experiments verify the stability and robustness of the proposed method across various multi-task natural language understanding tasks. The experimental results show that the proposed method outperforms mainstream parameter-efficient tuning techniques on multiple tasks. It achieves a better balance among accuracy, compression rate, and robustness to noise and perturbation.

02 Oct 2025
The central path revolutionized the study of optimization in the 1980s and 1990s due to its favorable convergence properties, and as such, it has been investigated analytically, algorithmically, and computationally. Past pursuits have primarily focused on linking iterative approximation algorithms to the central path in the design of efficient algorithms to solve large, and sometimes novel, optimization problems. This algorithmic intent has meant that the central path has rarely been celebrated as an aesthetic entity in low dimensions, with the only meager exceptions being illustrative examples in textbooks. We undertake this low dimensional investigation and illustrate the artistic use of the central path to create aesthetic tilings and flower-like constructs in two and three dimensions, an endeavor that combines mathematical rigor and artistic sensibilities. The result is a fanciful and enticing collection of patterns that, beyond computer generated images, supports math-aesthetic designs for novelties and museum-quality pieces of art.

29 Aug 2023
We extract mathematical concepts from mathematical text using generative large language models (LLMs) like ChatGPT, contributing to the field of automatic term extraction (ATE) and mathematical text processing, and also to the study of LLMs themselves. Our work builds on that of others in that we aim for automatic extraction of terms (keywords) in one mathematical field, category theory, using as a corpus the 755 abstracts from a snapshot of the online journal "Theory and Applications of Categories", circa 2020. Where our study diverges from previous work is in (1) providing a more thorough analysis of what makes mathematical term extraction a difficult problem to begin with; (2) paying close attention to inter-annotator disagreements; (3) providing a set of guidelines which both human and machine annotators could use to standardize the extraction process; (4) introducing a new annotation tool to help humans with ATE, applicable to any mathematical field and even beyond mathematics; (5) using prompts to ChatGPT as part of the extraction process, and proposing best practices for such prompts; and (6) raising the question of whether ChatGPT could be used as an annotator on the same level as human experts. Our overall findings are that the matter of mathematical ATE is an interesting field which can benefit from participation by LLMs, but LLMs themselves cannot at this time surpass human performance on it.

05 Dec 2021



Human brains are known to be capable of speeding up visual recognition of
repeatedly presented objects through faster memory encoding and accessing
procedures on activated neurons. For the first time, we borrow and distill such
a capability into a semantic memory design, namely SMTM, to improve on-device
CNN inference. SMTM employs a hierarchical memory architecture to leverage the
long-tail distribution of objects of interest, and further incorporates several
novel techniques to put it into effects: (1) it encodes high-dimensional
feature maps into low-dimensional, semantic vectors for low-cost yet accurate
cache and lookup; (2) it uses a novel metric in determining the exit timing
considering different layers' inherent characteristics; (3) it adaptively
adjusts the cache size and semantic vectors to fit the scene dynamics. SMTM is
prototyped on commodity CNN engine and runs on both mobile CPU and GPU.
Extensive experiments on large-scale datasets and models show that SMTM can
significantly speed up the model inference over standard approach (up to 2X)
and prior cache designs (up to 1.5X), with acceptable accuracy loss.

13 Aug 2025
This study proposes an unsupervised anomaly detection method for distributed backend service systems, addressing practical challenges such as complex structural dependencies, diverse behavioral evolution, and the absence of labeled data. The method constructs a dynamic graph based on service invocation relationships and applies graph convolution to extract high-order structural representations from multi-hop topologies. A Transformer is used to model the temporal behavior of each node, capturing long-term dependencies and local fluctuations. During the feature fusion stage, a learnable joint embedding mechanism integrates structural and behavioral representations into a unified anomaly vector. A nonlinear mapping is then applied to compute anomaly scores, enabling an end-to-end detection process without supervision. Experiments on real-world cloud monitoring data include sensitivity analyses across different graph depths, sequence lengths, and data perturbations. Results show that the proposed method outperforms existing models on several key metrics, demonstrating stronger expressiveness and stability in capturing anomaly propagation paths and modeling dynamic behavior sequences, with high potential for practical deployment.

02 Jul 2022

This paper presents the DeltaZ robot, a centimeter-scale, low-cost,
delta-style robot that allows for a broad range of capabilities and robust
functionalities. Current technologies allow DeltaZ to be 3D-printed from soft
and rigid materials so that it is easy to assemble and maintain, and lowers the
barriers to utilize. Functionality of the robot stems from its three
translational degrees of freedom and a closed form kinematic solution which
makes manipulation problems more intuitive compared to other manipulators.
Moreover, the low cost of the robot presents an opportunity to democratize
manipulators for a research setting. We also describe how the robot can be used
as a reinforcement learning benchmark. Open-source 3D-printable designs and
code are available to the public.

18 Jan 2019
The advantage of optical bistability (OB) using three-level
electromagnetically induced transparency (EIT) atomic system over the two-level
system is its controllability, as absorption, dispersion, and optical
nonlinearity in one of the atomic transitions can be modified considerably by
the field interacting with nearby atomic transitions. This is due to induced
atomic coherences generated in such EIT system. The inclusion of near
dipole-dipole (NDD) interaction among atoms further modifies absorption,
dispersion, and optical nonlinearity of three-level EIT system and the OB can
also be controlled by this interaction, producing OB to multistability.

17 Jul 2025
This paper proposes a reinforcement learning-based method for microservice resource scheduling and optimization, aiming to address issues such as uneven resource allocation, high latency, and insufficient throughput in traditional microservice architectures. In microservice systems, as the number of services and the load increase, efficiently scheduling and allocating resources such as computing power, memory, and storage becomes a critical research challenge. To address this, the paper employs an intelligent scheduling algorithm based on reinforcement learning. Through the interaction between the agent and the environment, the resource allocation strategy is continuously optimized. In the experiments, the paper considers different resource conditions and load scenarios, evaluating the proposed method across multiple dimensions, including response time, throughput, resource utilization, and cost efficiency. The experimental results show that the reinforcement learning-based scheduling method significantly improves system response speed and throughput under low load and high concurrency conditions, while also optimizing resource utilization and reducing energy consumption. Under multi-dimensional resource conditions, the proposed method can consider multiple objectives and achieve optimized resource scheduling. Compared to traditional static resource allocation methods, the reinforcement learning model demonstrates stronger adaptability and optimization capability. It can adjust resource allocation strategies in real time, thereby maintaining good system performance in dynamically changing load and resource environments.

13 Mar 2024
The self-interaction spin-2 approach to general relativity (GR) has been extremely influential in the particle physics community. Leaving no doubt regarding its heuristic value, we argue that a view of the metric field of GR as nothing but a stand-in for a self-coupling field in flat spacetime runs into a dilemma: either the view is physically incomplete in so far as it requires recourse to GR after all, or it leads to an absurd multiplication of alternative viewpoints on GR rendering any understanding of the metric field as nothing but a spin-2 field in flat spacetime unjustified.

21 Mar 2022
Progress in pre-trained language models has led to a surge of impressive
results on downstream tasks for natural language understanding. Recent work on
probing pre-trained language models uncovered a wide range of linguistic
properties encoded in their contextualized representations. However, it is
unclear whether they encode semantic knowledge that is crucial to symbolic
inference methods. We propose a methodology for probing linguistic information
for logical inference in pre-trained language model representations. Our
probing datasets cover a list of linguistic phenomena required by major
symbolic inference systems. We find that (i) pre-trained language models do
encode several types of linguistic information for inference, but there are
also some types of information that are weakly encoded, (ii) language models
can effectively learn missing linguistic information through fine-tuning.
Overall, our findings provide insights into which aspects of linguistic
information for logical inference do language models and their pre-training
procedures capture. Moreover, we have demonstrated language models' potential
as semantic and background knowledge bases for supporting symbolic inference
methods.

17 Feb 2025

Rate-Splitting Multiple Access (RSMA) is a powerful and versatile physical
layer multiple access technique that generalizes and has better interference
management capabilities than 5G-based Space Division Multiple Access (SDMA). It
is also a rapidly maturing technology, all of which makes it a natural
successor to SDMA in 6G. In this article, we describe RSMA's suitability for 6G
by presenting: i) link and system level simulations of RSMA's performance gains
over SDMA in realistic environments, and (ii) pioneering experimental results
that demonstrate RSMA's gains over SDMA for key use cases like enhanced Mobile
Broadband (eMBb), and Integrated Sensing and Communications (ISAC). We also
comment on the status of standardization activities for RSMA.

03 Oct 2024
This paper presents a deep learning-based framework for predicting the dynamic performance of suspension systems in multi-axle vehicles, emphasizing the integration of machine learning with traditional vehicle dynamics modeling. A Multi-Task Deep Belief Network Deep Neural Network (MTL-DBN-DNN) was developed to capture the relationships between key vehicle parameters and suspension performance metrics. The model was trained on data generated from numerical simulations and demonstrated superior prediction accuracy compared to conventional DNN models. A comprehensive sensitivity analysis was conducted to assess the impact of various vehicle and suspension parameters on dynamic suspension performance. Additionally, the Suspension Dynamic Performance Index (SDPI) was introduced as a holistic measure to quantify overall suspension performance, accounting for the combined effects of multiple parameters. The findings highlight the effectiveness of multitask learning in improving predictive models for complex vehicle systems.

24 Sep 2025

Ramsey's theorem states that for all finite colorings of an infinite set, there exists an infinite homogeneous subset. What if we seek a homogeneous subset that is also order-equivalent to the original set? Let be a linearly ordered set and . The big Ramsey degree of in , denoted , is the least integer such that, for any finite coloring of the -subsets of , there exists such that (i) is order-equivalent to , and (ii) if the coloring is restricted to the -subsets of then at most colors are used.
Mašulović \& Šobot (2019) showed that . From this one can obtain . We give a direct proof that .
Mašulović and Šobot (2019) also showed that for all countable ordinals \alpha < \omega^\omega, and for all , is finite. We find exact value of for all ordinals less than and all .
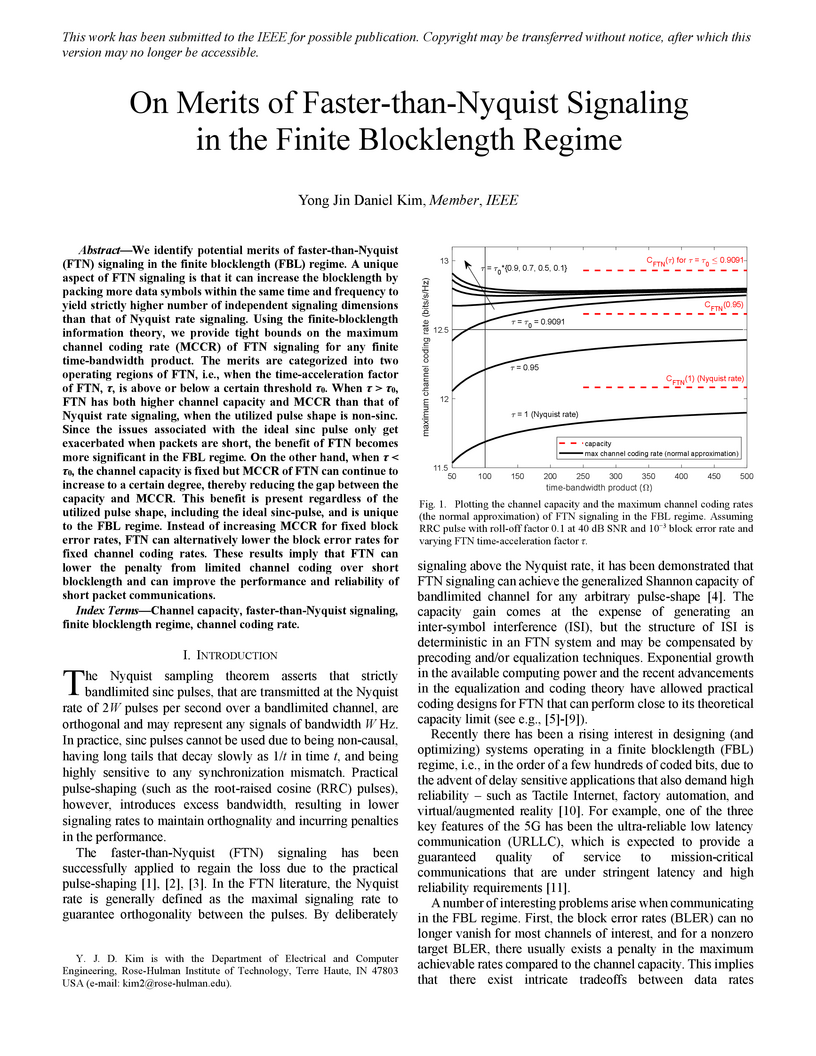
25 Apr 2024
We identify potential merits of faster-than-Nyquist (FTN) signaling in the finite blocklength (FBL) regime. A unique aspect of FTN signaling is that it can increase the blocklength by packing more data symbols within the same time and frequency to yield strictly higher number of independent signaling dimensions than that of Nyquist rate signaling. Using the finite-blocklength information theory, we provide tight bounds on the maximum channel coding rate (MCCR) of FTN signaling for any finite time-bandwidth product. The merits are categorized into two operating regions of FTN, i.e., when the time-acceleration factor of FTN, , is above or below a certain threshold . When \tau > \tau_{0}, FTN has both higher channel capacity and MCCR than that of Nyquist rate signaling, when the utilized pulse shape is non-sinc. Since the issues associated with the ideal sinc pulse only get exacerbated when packets are short, the benefit of FTN becomes more significant in the FBL regime. On the other hand, when \tau < \tau_{0}, the channel capacity is fixed but MCCR of FTN can continue to increase to a certain degree, thereby reducing the gap between the capacity and MCCR. This benefit is present regardless of the utilized pulse shape, including the ideal sinc-pulse, and is unique to the FBL regime. Instead of increasing MCCR for fixed block error rates, FTN can alternatively lower the block error rates for fixed channel coding rates. These results imply that FTN can lower the penalty from limited channel coding over short blocklength and can improve the performance and reliability of short packet communications.

12 Sep 2024
We study lattice polytopes which arise as the convex hull of chip vectors for \textit{self-reachable} chip configurations on a tree . We show that these polytopes always have the integer decomposition property and characterize the vertex sets of these polytopes. Additionally, in the case of self-reachable configurations with the smallest possible number of chips, we show that these polytopes are unimodularly equivalent to a unit cube.

18 Sep 2024

Many commonly studied species now have more than one chromosome-scale genome assembly, revealing a large amount of genetic diversity previously missed by approaches that map short reads to a single reference. However, many species still lack multiple reference genomes and correctly aligning references to build pangenomes is challenging, limiting our ability to study this missing genomic variation in population genetics. Here, we argue that -mers are a crucial stepping stone to bridging the reference-focused paradigms of population genetics with the reference-free paradigms of pangenomics. We review current literature on the uses of -mers for performing three core components of most population genetics analyses: identifying, measuring, and explaining patterns of genetic variation. We also demonstrate how different -mer-based measures of genetic variation behave in population genetic simulations according to the choice of , depth of sequencing coverage, and degree of data compression. Overall, we find that -mer-based measures of genetic diversity scale consistently with pairwise nucleotide diversity () up to values of about () for neutrally evolving populations. For populations with even more variation, using shorter -mers will maintain the scalability up to at least . Furthermore, in our simulated populations, -mer dissimilarity values can be reliably approximated from counting bloom filters, highlighting a potential avenue to decreasing the memory burden of -mer based genomic dissimilarity analyses. For future studies, there is a great opportunity to further develop methods to identifying selected loci using -mers.

25 Sep 2024
This paper presents a comprehensive numerical analysis of centrifugal clutch systems integrated with a two-speed automatic transmission, a key component in automotive torque transfer. Centrifugal clutches enable torque transmission based on rotational speed without external controls. The study systematically examines various clutch configurations effects on transmission dynamics, focusing on torque transfer, upshifting, and downshifting behaviors under different conditions. A Deep Neural Network (DNN) model predicts clutch engagement using parameters such as spring preload and shoe mass, offering an efficient alternative to complex simulations. The integration of deep learning and numerical modeling provides critical insights for optimizing clutch designs, enhancing transmission performance and efficiency.

04 Mar 2025

Autonomous robotic systems hold potential for improving renal tumor resection
accuracy and patient outcomes. We present a fluorescence-guided robotic system
capable of planning and executing incision paths around exophytic renal tumors
with a clinically relevant resection margin. Leveraging point cloud
observations, the system handles irregular tumor shapes and distinguishes
healthy from tumorous tissue based on near-infrared imaging, akin to
indocyanine green staining in partial nephrectomy. Tissue-mimicking phantoms
are crucial for the development of autonomous robotic surgical systems for
interventions where acquiring ex-vivo animal tissue is infeasible, such as
cancer of the kidney and renal pelvis. To this end, we propose novel
hydrogel-based kidney phantoms with exophytic tumors that mimic the physical
and visual behavior of tissue, and are compatible with electrosurgical
instruments, a common limitation of silicone-based phantoms. In contrast to
previous hydrogel phantoms, we mix the material with near-infrared dye to
enable fluorescence-guided tumor segmentation. Autonomous real-world robotic
experiments validate our system and phantoms, achieving an average margin
accuracy of 1.44 mm in a completion time of 69 sec.

09 Mar 2025

Perfectly Matched Layers (PML) has become a very common method for the
numerical approximation of wave and wave-like equations on unbounded domains.
This technique allows one to obtain accurate solutions while working on a
finite computational domain, and the technique is relatively simple to
implement. Results concerning the accuracy of the PML method have been
obtained, but mostly with regard problems at a fixed frequency. In this paper
we provide very explicit time-domain bounds on the accuracy of PML for the
two-dimensional wave equation and illustrate our conclusions with some
numerical examples.

09 Aug 2025
This paper proposes a spatiotemporal graph neural network-based performance prediction algorithm to address the challenge of forecasting performance fluctuations in distributed backend systems with multi-level service call structures. The method abstracts system states at different time slices into a sequence of graph structures. It integrates the runtime features of service nodes with the invocation relationships among services to construct a unified spatiotemporal modeling framework. The model first applies a graph convolutional network to extract high-order dependency information from the service topology. Then it uses a gated recurrent network to capture the dynamic evolution of performance metrics over time. A time encoding mechanism is also introduced to enhance the model's ability to represent non-stationary temporal sequences. The architecture is trained in an end-to-end manner, optimizing the multi-layer nested structure to achieve high-precision regression of future service performance metrics. To validate the effectiveness of the proposed method, a large-scale public cluster dataset is used. A series of multi-dimensional experiments are designed, including variations in time windows and concurrent load levels. These experiments comprehensively evaluate the model's predictive performance and stability. The experimental results show that the proposed model outperforms existing representative methods across key metrics such as MAE, RMSE, and R2. It maintains strong robustness under varying load intensities and structural complexities. These results demonstrate the model's practical potential for backend service performance management tasks.
There are no more papers matching your filters at the moment.
