
01 Feb 2024
The rapid progress of Large Models (LMs) has recently revolutionized various fields of deep learning with remarkable grades, ranging from Natural Language Processing (NLP) to Computer Vision (CV). However, LMs are increasingly challenged and criticized by academia and industry due to their powerful performance but untrustworthy behavior, which urgently needs to be alleviated by reliable methods. Despite the abundance of literature on trustworthy LMs in NLP, a systematic survey specifically delving into the trustworthiness of LMs in CV remains absent. In order to mitigate this gap, we summarize four relevant concerns that obstruct the trustworthy usage in vision of LMs in this survey, including 1) human misuse, 2) vulnerability, 3) inherent issue and 4) interpretability. By highlighting corresponding challenge, countermeasures, and discussion in each topic, we hope this survey will facilitate readers' understanding of this field, promote alignment of LMs with human expectations and enable trustworthy LMs to serve as welfare rather than disaster for human society.
26 May 2023

Plan-and-Solve (PS) Prompting, developed by researchers at Singapore Management University and collaborators, enhances zero-shot Chain-of-Thought reasoning in Large Language Models by guiding them through a two-phase process of planning and execution. This method reduces calculation and missing-step errors, achieving accuracy comparable to few-shot methods on arithmetic reasoning tasks and outperforming Zero-shot CoT across multiple domains.

25 Sep 2025

MMR1, a framework developed by Nanyang Technological University, Alibaba Group's DAMO Academy, and Singapore University of Technology and Design, enhances multimodal reasoning by stabilizing reinforcement learning through Variance-Aware Sampling (VAS) and releasing extensive, high-quality multimodal Chain-of-Thought (CoT) datasets. The MMR1 7B model achieves state-of-the-art performance on several mathematical and logical reasoning benchmarks, including MathVerse, MathVision, LogicVista, and ChartQA.

26 Nov 2025
Researchers from Nanjing University of Science and Technology, Baidu Inc., Adelaide AIML, and Singapore University of Technology and Design introduced ViLoMem, a dual-stream memory framework, enabling multimodal large language models (MLLMs) to learn from past multimodal reasoning and perception errors. The framework achieved consistent improvements in accuracy across six multimodal benchmarks, including gains of up to +6.48 on MathVision for GPT-4.1.

03 Dec 2025


Humans naturally adapt to diverse environments by learning underlying rules across worlds with different dynamics, observations, and reward structures. In contrast, existing agents typically demonstrate improvements via self-evolving within a single domain, implicitly assuming a fixed environment distribution. Cross-environment learning has remained largely unmeasured: there is no standard collection of controllable, heterogeneous environments, nor a unified way to represent how agents learn. We address these gaps in two steps. First, we propose AutoEnv, an automated framework that treats environments as factorizable distributions over transitions, observations, and rewards, enabling low-cost (4.12 USD on average) generation of heterogeneous worlds. Using AutoEnv, we construct AutoEnv-36, a dataset of 36 environments with 358 validated levels, on which seven language models achieve 12-49% normalized reward, demonstrating the challenge of AutoEnv-36. Second, we formalize agent learning as a component-centric process driven by three stages of Selection, Optimization, and Evaluation applied to an improvable agent component. Using this formulation, we design eight learning methods and evaluate them on AutoEnv-36. Empirically, the gain of any single learning method quickly decrease as the number of environments increases, revealing that fixed learning methods do not scale across heterogeneous environments. Environment-adaptive selection of learning methods substantially improves performance but exhibits diminishing returns as the method space expands. These results highlight both the necessity and the current limitations of agent learning for scalable cross-environment generalization, and position AutoEnv and AutoEnv-36 as a testbed for studying cross-environment agent learning. The code is avaiable at this https URL.
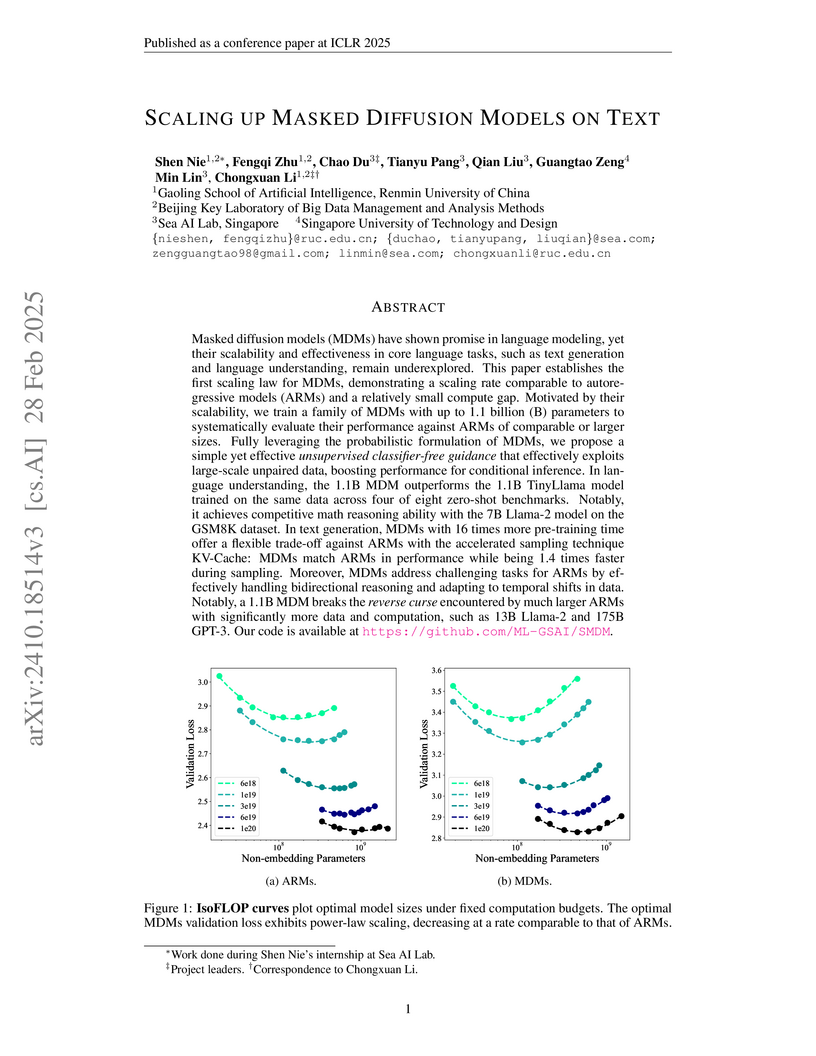
28 Feb 2025
Researchers from Renmin University and Sea AI Lab established the first scaling law for Masked Diffusion Models (MDMs) on text, demonstrating their ability to achieve competitive performance with Autoregressive Models (ARMs) while uniquely addressing ARMs' limitations in bidirectional reasoning and temporal data shifts through a novel unsupervised classifier-free guidance. A 1.1B MDM matched the performance of a 7B Llama-2 on mathematical reasoning and surpassed ARMs on reverse curse tasks, showing strong potential as an alternative paradigm.

28 Apr 2025
A 3B-parameter Vision-Language-Action model combines Qwen-2.5-VL-3B with FAST+ tokenization to enable real-time robotic control on consumer GPUs, achieving comparable or better performance than larger models across simulation and real-world robot manipulation tasks while reducing computational requirements by 57%.

19 Feb 2025
 University of Toronto
University of Toronto Google DeepMind
Google DeepMind University of WaterlooCharles University
University of WaterlooCharles University Harvard University
Harvard University Anthropic
Anthropic Carnegie Mellon University
Carnegie Mellon University Université de Montréal
Université de Montréal University College London
University College London University of OxfordUniversity of Bonn
University of OxfordUniversity of Bonn Stanford University
Stanford University University of Michigan
University of Michigan Meta
Meta Johns Hopkins UniversitySingapore University of Technology and Design
Johns Hopkins UniversitySingapore University of Technology and Design University of St AndrewsÉcole Polytechnique Fédérale de LausanneMax Planck Institute for Human DevelopmentCzech Technical UniversityTeesside UniversityCentre for the Governance of AIApollo ResearchFAR AIApart ResearchCenter on Long-Term RiskUniversity of StirlingCooperative AI FoundationPRISM AI
University of St AndrewsÉcole Polytechnique Fédérale de LausanneMax Planck Institute for Human DevelopmentCzech Technical UniversityTeesside UniversityCentre for the Governance of AIApollo ResearchFAR AIApart ResearchCenter on Long-Term RiskUniversity of StirlingCooperative AI FoundationPRISM AI

A landmark collaborative study from 44 researchers across 30 major institutions establishes the first comprehensive framework for understanding multi-agent AI risks, identifying three critical failure modes and seven key risk factors while providing concrete evidence from both historical examples and novel experiments to guide future safety efforts.

04 Jun 2024
We present TinyLlama, a compact 1.1B language model pretrained on around 1
trillion tokens for approximately 3 epochs. Building on the architecture and
tokenizer of Llama 2, TinyLlama leverages various advances contributed by the
open-source community (e.g., FlashAttention and Lit-GPT), achieving better
computational efficiency. Despite its relatively small size, TinyLlama
demonstrates remarkable performance in a series of downstream tasks. It
significantly outperforms existing open-source language models with comparable
sizes. Our model checkpoints and code are publicly available on GitHub at
https://github.com/jzhang38/TinyLlama.

22 Oct 2025


Researchers from the National University of Singapore and collaborators developed MLR-Bench, a new benchmark to evaluate AI agents on open-ended machine learning research, comprising 201 real-world tasks, an LLM-based judge, and an agent scaffold. Their findings indicate current AI agents struggle with scientific soundness and often hallucinate experimental results, while the LLM judge's evaluations align closely with human experts.

27 Oct 2025



MOOSE-CHEM is an agentic Large Language Model framework that mathematically decomposes scientific hypothesis generation into tractable steps, demonstrating LLMs' ability to rediscover novel, Nature/Science-level chemistry hypotheses from unseen literature by identifying latent knowledge associations. This framework achieved high similarity to ground truth hypotheses and outperformed existing baselines on a rigorous, expert-validated benchmark.

11 Oct 2025

Researchers from SUTD, NTU, and Alibaba's Tongyi Lab introduced WebDetective, a hint-free multi-hop deep search benchmark, and a diagnostic evaluation framework to assess large language model (LLM) agents. Their comprehensive analysis of 25 frontier models revealed that even advanced LLMs achieve only around 50% Pass@1 on hint-free tasks and frequently struggle with evidence synthesis and appropriate refusal.

20 Feb 2024




The research introduces GLAN (Generalized LLM-Augmented iNstruction tuning), an approach for generating comprehensive instruction data for training Language Models by systematically decomposing a human knowledge taxonomy. This method reduces reliance on existing datasets or extensive human curation, requiring only a taxonomy as input. GLAN-tuned Mistral 7B models demonstrate improved performance in mathematical reasoning, coding, logical reasoning, and academic benchmarks, outperforming larger models like WizardLM-13B on certain tasks.

10 Oct 2025
Researchers demonstrated that large language models (LLMs) fail to distinguish between factual information and associated hallucinations because both leverage similar internal parametric knowledge representations and processing pathways. The study revealed that LLM internal states primarily reflect patterns of knowledge recall rather than factual correctness, challenging assumptions about their intrinsic "self-awareness" of knowledge boundaries.

16 Jun 2025

Satori trains a single Large Language Model (LLM) to perform autoregressive search internally using a Chain-of-Action-Thought format and a two-stage reinforcement learning pipeline. The approach achieves state-of-the-art performance among small models on mathematical reasoning benchmarks and demonstrates strong generalization across diverse out-of-domain tasks by internalizing self-reflection and self-exploration capabilities.

17 Dec 2024
Researchers at the Singapore University of Technology and Design developed EMMA-X, an embodied multimodal action model that enhances robot policies with visually grounded chain-of-thought and look-ahead spatial reasoning. This approach leads to a 24.17% increase in task success rate over the OpenVLA baseline on real-world robot manipulation tasks, particularly improving performance in scenarios requiring complex spatial understanding and generalization to new instructions.

15 May 2025

This survey by MiroMind and affiliated universities synthesizes open-source replication studies of DeepSeek-R1, detailing methodologies for reasoning language models (RLMs) through supervised fine-tuning (SFT) and reinforcement learning from verifiable rewards (RLVR). It highlights the critical role of high-quality data and adapted RL algorithms in achieving strong reasoning capabilities, also identifying emerging research directions and challenges.

08 Oct 2024
Researchers developed Math-LLaVA, a multimodal large language model fine-tuned on the synthesized MathV360K dataset, which achieves 46.6% accuracy on MathVista, marking a 19-point increase over the LLaVA-1.5 base model and demonstrating performance comparable to GPT-4V.

19 Sep 2025

Researchers from Martian Learning and Nvidia demonstrated that security interventions can be efficiently transferred between diverse Large Language Models by mapping their activation spaces, leveraging non-linear autoencoders to mitigate backdoor behaviors and create 'lightweight safety switches' that reduce computational overhead compared to traditional methods.

07 Oct 2025
Researchers from SUTD and ECNU developed an LLM-driven framework that redefines text clustering as a two-stage classification task, eliminating the need for external embedding models or traditional algorithms. This approach achieved higher clustering performance across five diverse datasets, often outperforming state-of-the-art baselines and providing interpretable, human-readable cluster labels.
There are no more papers matching your filters at the moment.
