
30 Jan 2025
Designing a qubit architecture is one of the most critical challenges in achieving scalable and fault-tolerant quantum computing as the performance of a quantum computer is heavily dependent on the coherence times, connectivity and low noise environments. Superconducting qubits have emerged as a frontrunner among many competing technologies, primarily because of their speed of operations, relatively well-developed and offer a promising path toward scalability. Here, we address the challenges of optimizing superconducting qubit hardware through the development of a comprehensive theoretical framework that spans the entire process - from design to the calibration of hardware through quantum gate execution. We develop this framework in four key steps: circuit design, electromagnetic analysis, spectral analysis, and pulse sequencing with calibration. We first refine the qubit's core components - such as capacitance, Josephson junctions, and resonators - to set the foundation for strong performance. The electromagnetic analysis, using the Lumped Oscillator model, allows us to map out the capacitance matrix, ensuring that we minimize spectral dispersion while maximizing coherence times. Following this, we conduct spectral analysis to fine-tune the qubit's frequency spectrum and coherence properties, ensuring that the qubit parameters are optimized. Finally, we focus on pulse sequencing, including pulse-width optimization, DRAG optimization, and randomized benchmarking, to achieve high gate fidelity. We applied this framework to both Transmon and Fluxonium qubits, obtaining results that closely match those found in experimental studies. This work provides a detailed and practical approach to the design, optimization, and calibration of superconducting qubits, contributing to the broader effort to develop scalable quantum computing technologies.

07 Apr 2023
Facial expression recognition (FER) algorithms work well in constrained
environments with little or no occlusion of the face. However, real-world face
occlusion is prevalent, most notably with the need to use a face mask in the
current Covid-19 scenario. While there are works on the problem of occlusion in
FER, little has been done before on the particular face mask scenario.
Moreover, the few works in this area largely use synthetically created masked
FER datasets. Motivated by these challenges posed by the pandemic to FER, we
present a novel dataset, the Masked Student Dataset of Expressions or MSD-E,
consisting of 1,960 real-world non-masked and masked facial expression images
collected from 142 individuals. Along with the issue of obfuscated facial
features, we illustrate how other subtler issues in masked FER are represented
in our dataset. We then provide baseline results using ResNet-18, finding that
its performance dips in the non-masked case when trained for FER in the
presence of masks. To tackle this, we test two training paradigms: contrastive
learning and knowledge distillation, and find that they increase the model's
performance in the masked scenario while maintaining its non-masked
performance. We further visualise our results using t-SNE plots and Grad-CAM,
demonstrating that these paradigms capitalise on the limited features available
in the masked scenario. Finally, we benchmark SOTA methods on MSD-E.

01 Oct 2025
We propose a novel fractal based interpolation scheme termed Rational Cubic Trigonometric Zipper Fractal Interpolation Functions (RCTZFIFs) designed to model and preserve the inherent geometric property, positivity, in given datasets. The method employs a combination of rational cubic trigonometric functions within a zipper fractal framework, offering enhanced flexibility through shape parameters and scaling factors. Rigorous error analysis is presented to establish the convergence of the proposed zipper fractal interpolants to the underlying classical fractal functions, and subsequently, to the data-generating function. We derive necessary constraints on the scaling factors and shape parameters to ensure positivity preservation. By carefully selecting the signature, shape parameters, and scaling factors within these bounds, we construct a class of RCTZFIFs that effectively preserve the positive nature of the data, as compared to a reference interpolant that may violate this property. Numerical experiments and visualisations demonstrate the efficacy and robustness of our approach in preserving positivity while offering fractal flexibility.

03 Mar 2025
Deep neural networks (DNNS) excel at learning from static datasets but
struggle with continual learning, where data arrives sequentially. Catastrophic
forgetting, the phenomenon of forgetting previously learned knowledge, is a
primary challenge. This paper introduces EXponentially Averaged Class-wise
Feature Significance (EXACFS) to mitigate this issue in the class incremental
learning (CIL) setting. By estimating the significance of model features for
each learned class using loss gradients, gradually aging the significance
through the incremental tasks and preserving the significant features through a
distillation loss, EXACFS effectively balances remembering old knowledge
(stability) and learning new knowledge (plasticity). Extensive experiments on
CIFAR-100 and ImageNet-100 demonstrate EXACFS's superior performance in
preserving stability while acquiring plasticity.

13 Dec 2022
We consider an additional food provided prey-predator model exhibiting
Holling type IV functional response with combined continuous white noise and
discontinuous L\'evy noise. We prove the existence and uniqueness of global
positive solutions for the considered model. By considering the quality and
quantity of additional food as control parameters, we formulate a time-optimal
control problem. We obtain the condition for the existence of an optimal
control. Furthermore, making use of the arrow condition of the sufficient
stochastic maximum principle, we characterize the optimal quality of additional
food and optimal quantity of additional food. Numerical results are given to
illustrate the theoretical findings with applications in biological
conservation and pest management.

07 Apr 2019
Sketching is more fundamental to human cognition than speech. Deep Neural
Networks (DNNs) have achieved the state-of-the-art in speech-related tasks but
have not made significant development in generating stroke-based sketches a.k.a
sketches in vector format. Though there are Variational Auto Encoders (VAEs)
for generating sketches in vector format, there is no Generative Adversarial
Network (GAN) architecture for the same. In this paper, we propose a standalone
GAN architecture SkeGAN and a VAE-GAN architecture VASkeGAN, for sketch
generation in vector format. SkeGAN is a stochastic policy in Reinforcement
Learning (RL), capable of generating both multidimensional continuous and
discrete outputs. VASkeGAN hybridizes a VAE and a GAN, in order to couple the
efficient representation of data by VAE with the powerful generating
capabilities of a GAN, to produce visually appealing sketches. We also propose
a new metric called the Ske-score which quantifies the quality of vector
sketches. We have validated that SkeGAN and VASkeGAN generate visually
appealing sketches by using Human Turing Test and Ske-score.

22 Aug 2022
Dynamic Adaptive Threshold based Learning for Noisy Annotations Robust Facial Expression Recognition
Dynamic Adaptive Threshold based Learning for Noisy Annotations Robust Facial Expression Recognition
The real-world facial expression recognition (FER) datasets suffer from noisy annotations due to crowd-sourcing, ambiguity in expressions, the subjectivity of annotators and inter-class similarity. However, the recent deep networks have strong capacity to memorize the noisy annotations leading to corrupted feature embedding and poor generalization. To handle noisy annotations, we propose a dynamic FER learning framework (DNFER) in which clean samples are selected based on dynamic class specific threshold during training. Specifically, DNFER is based on supervised training using selected clean samples and unsupervised consistent training using all the samples. During training, the mean posterior class probabilities of each mini-batch is used as dynamic class-specific threshold to select the clean samples for supervised training. This threshold is independent of noise rate and does not need any clean data unlike other methods. In addition, to learn from all samples, the posterior distributions between weakly-augmented image and strongly-augmented image are aligned using an unsupervised consistency loss. We demonstrate the robustness of DNFER on both synthetic as well as on real noisy annotated FER datasets like RAFDB, FERPlus, SFEW and AffectNet.

11 Oct 2022
In spite of years of research, the mechanisms that underlie the development of schizophrenia, as well as its relapse, symptomatology, and treatment, continue to be a mystery. The absence of appropriate analytic tools to deal with the variable and complicated nature of schizophrenia may be one of the factors that contribute to the development of this disorder. Deep learning is a subfield of artificial intelligence that was inspired by the nervous system. In recent years, deep learning has made it easier to model and analyse complicated, high-dimensional, and nonlinear systems. Research on schizophrenia is one of the many areas of study that has been revolutionised as a result of the outstanding accuracy that deep learning algorithms have demonstrated in classification and prediction tasks. Deep learning has the potential to become a powerful tool for understanding the mechanisms that are at the root of schizophrenia. In addition, a growing variety of techniques aimed at improving model interpretability and causal reasoning are contributing to this trend. Using multi-site fMRI data and a variety of deep learning approaches, this study seeks to identify different types of schizophrenia. Our proposed method of temporal aggregation of the 4D fMRI data outperforms existing work. In addition, this study aims to shed light on the strength of connections between various brain areas in schizophrenia individuals.

04 Apr 2023
In this work, we develop language models for the Sanskrit language, namely Bidirectional Encoder Representations from Transformers (BERT) and its variants: A Lite BERT (ALBERT), and Robustly Optimized BERT (RoBERTa) using Devanagari Sanskrit text corpus. Then we extracted the features for the given text from these models. We applied the dimensional reduction and clustering techniques on the features to generate an extractive summary for a given Sanskrit document. Along with the extractive text summarization techniques, we have also created and released a Sanskrit Devanagari text corpus publicly.

24 Sep 2023
In recent years, time-optimal control studies on additional food provided prey-predator systems have gained significant attention from researchers in the field of mathematical biology. In this study, we initially consider an additional food provided prey-predator model exhibiting Holling type-III functional response and the intra-specific competition among predators. We prove the existence and uniqueness of global positive solutions for the proposed model. We do the time optimal control studies with respect quality and quantity of additional food as control variables by transforming the independent variable in the control system. Making use of the Pontraygin maximum principle, we characterize the optimal quality of additional food and optimal quantity of additional food. We show that the findings of these time-optimal control studies on additional food provided prey-predator systems involving Holling type III functional response have the potential to be applied to a variety of problems in pest management. In the later half of this study, we consider an additional food provided prey-predator model exhibiting Holling type-IV functional response and study the above aspects for this system.

13 Mar 2024
Tuberculosis (TB) remains a global health threat, ranking among the leading
causes of mortality worldwide. In this context, machine learning (ML) has
emerged as a transformative force, providing innovative solutions to the
complexities associated with TB treatment.This study explores how machine
learning, especially with tabular data, can be used to predict Tuberculosis
(TB) treatment outcomes more accurately. It transforms this prediction task
into a binary classification problem, generating risk scores from patient data
sourced from NIKSHAY, India's national TB control program, which includes over
500,000 patient records.
Data preprocessing is a critical component of the study, and the model
achieved an recall of 98% and an AUC-ROC score of 0.95 on the validation set,
which includes 20,000 patient records.We also explore the use of Natural
Language Processing (NLP) for improved model learning. Our results,
corroborated by various metrics and ablation studies, validate the
effectiveness of our approach. The study concludes by discussing the potential
ramifications of our research on TB eradication efforts and proposing potential
avenues for future work. This study marks a significant stride in the battle
against TB, showcasing the potential of machine learning in healthcare.

25 Mar 2024
Rhymes and poems are a powerful medium for transmitting cultural norms and
societal roles. However, the pervasive existence of gender stereotypes in these
works perpetuates biased perceptions and limits the scope of individuals'
identities. Past works have shown that stereotyping and prejudice emerge in
early childhood, and developmental research on causal mechanisms is critical
for understanding and controlling stereotyping and prejudice. This work
contributes by gathering a dataset of rhymes and poems to identify gender
stereotypes and propose a model with 97% accuracy to identify gender bias.
Gender stereotypes were rectified using a Large Language Model (LLM) and its
effectiveness was evaluated in a comparative survey against human educator
rectifications. To summarize, this work highlights the pervasive nature of
gender stereotypes in literary works and reveals the potential of LLMs to
rectify gender stereotypes. This study raises awareness and promotes
inclusivity within artistic expressions, making a significant contribution to
the discourse on gender equality.

26 May 2024
Tuberculosis remains a significant global health challenge, with millions of
new cases reported annually. Recent studies suggest that expanding the
accessibility of TB intervention programs can lead to a substantial decrease in
both TB incidence and prevalence. This paper initiates by examining a
deterministic mathematical model for TB transmission, aiming to analyze the
underlying dynamics. Subsequently, an optimal control problem is formulated to
enhance TB control measures, encompassing Tuberculosis Preventive Treatment
(TPT) and other initiatives targeting malnutrition and diabetes. Through
simulation studies, the effectiveness of the control program is assessed. The
model dynamics allow us to identify the pseudo-prevalence and incidence. To
determine the potential long-term trajectory of TB and to acquire future
projections a cost-effectiveness analysis is performed using ACER, AIR, ICER,
and four quadrants to compare competing interventions. In conclusion, this work
provides valuable insights into TB and strategies for its control and cost
effectiveness.

08 Jul 2025
Ramanujan sums have attracted significant attention in both mathematical and engineering disciplines due to their diverse applications. In this paper, we introduce an algebraic generalization of Ramanujan sums, derived through polynomial remaindering. This generalization is motivated by its applications in Restricted Partition Theory and Coding Theory. Our investigation focuses on the properties of these sums and expresses them as finite trigonometric sums subject to a coprime condition. Interestingly, these finite trigonometric sums with a coprime condition, which arise naturally in our context, were recently introduced as an analogue of Ramanujan sums by Berndt, Kim, and Zahaescu. Furthermore, we provide an explicit formula for the size of Levenshtein codes with an additional parity condition (also known as Shifted Varshamov-Tenengolts deletion correction codes), which have found many interesting applications in studying the Little-Offord problem, DNA-based data storage and distributed synchronization. Specifically, we present an explicit formula for a particularly important open case for or are divisible by and for small values of .

24 Dec 2024
Gastrointestinal (GI) bleeding is a serious medical condition that presents significant diagnostic challenges, particularly in settings with limited access to healthcare resources. Wireless Capsule Endoscopy (WCE) has emerged as a powerful diagnostic tool for visualizing the GI tract, but it requires time-consuming manual analysis by experienced gastroenterologists, which is prone to human error and inefficient given the increasing number of this http URL address this challenge, we propose ClassifyViStA, an AI-based framework designed for the automated detection and classification of bleeding and non-bleeding frames from WCE videos. The model consists of a standard classification path, augmented by two specialized branches: an implicit attention branch and a segmentation this http URL attention branch focuses on the bleeding regions, while the segmentation branch generates accurate segmentation masks, which are used for classification and interpretability. The model is built upon an ensemble of ResNet18 and VGG16 architectures to enhance classification performance. For the bleeding region detection, we implement a Soft Non-Maximum Suppression (Soft NMS) approach with YOLOv8, which improves the handling of overlapping bounding boxes, resulting in more accurate and nuanced this http URL system's interpretability is enhanced by using the segmentation masks to explain the classification results, offering insights into the decision-making process similar to the way a gastroenterologist identifies bleeding regions. Our approach not only automates the detection of GI bleeding but also provides an interpretable solution that can ease the burden on healthcare professionals and improve diagnostic efficiency. Our code is available at ClassifyViStA.

09 Apr 2025
In the study of Ramanujan sums, the so-called regular -function is a set-valued multiplicative function that tracks certain subsets of the divisor sets of natural numbers. McCarthy provided a generalization of the Ramanujan sum using these regular -function based arithmetic convolutions. This approach has recently attracted considerable interest from several researchers. In this paper, we extend McCarthy's generalization by introducing two regular -functions corresponding to both parameters in the Ramanujan sum. Fortunately, these sums exhibit several properties of the Ramanujan sums. We also generalize the greatest common divisor (GCD) function and the Von Sterneck formula. Our introduction of two regular -functions into these expressions enables us to explore a novel perspective on the connection between these expressions and the order relation between the two regular -functions. In particular, we establish the necessary and sufficient conditions for orthogonality and Dedekind-Hölder's identity (i.e., Ramanujan sum = Von Sterneck function) to hold. Our primary motivation for this further generalization proposed in this paper is expansions of arithmetic functions based on arbitrary regular -functions. To the best of our knowledge, the expansions of arbitrary -functions discussed here are new in the literature.
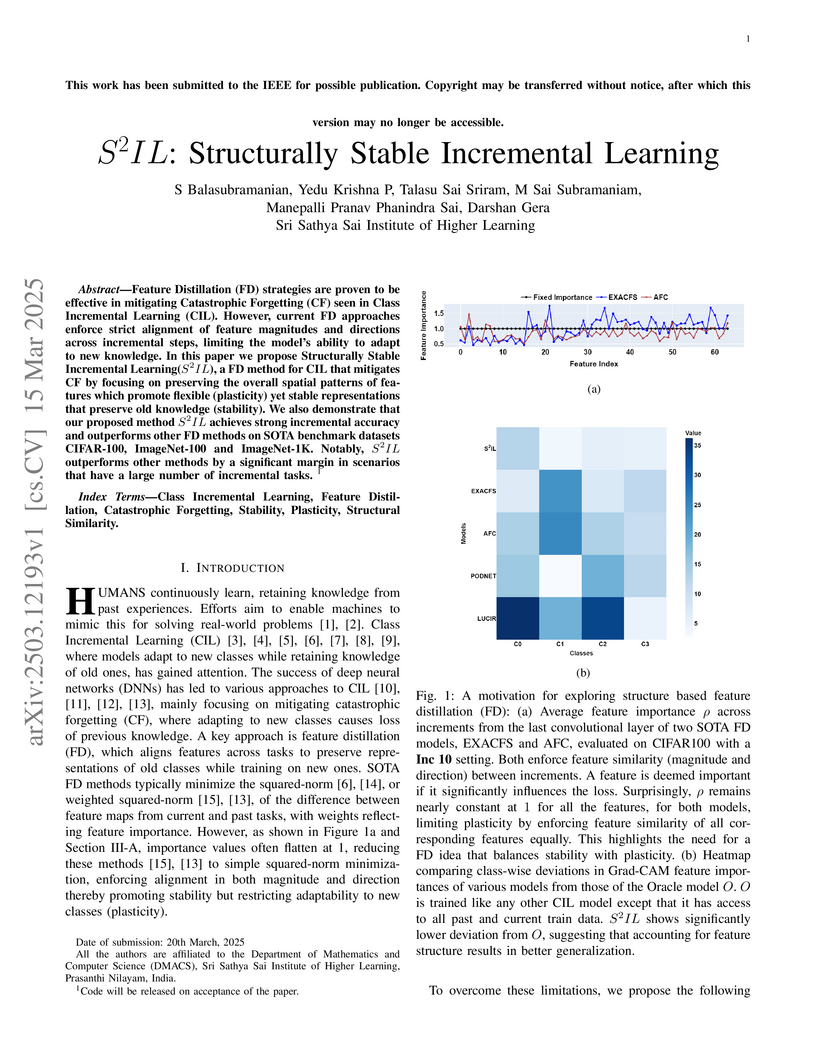
15 Mar 2025
Feature Distillation (FD) strategies are proven to be effective in mitigating
Catastrophic Forgetting (CF) seen in Class Incremental Learning (CIL). However,
current FD approaches enforce strict alignment of feature magnitudes and
directions across incremental steps, limiting the model's ability to adapt to
new knowledge. In this paper we propose Structurally Stable Incremental
Learning(S22IL), a FD method for CIL that mitigates CF by focusing on
preserving the overall spatial patterns of features which promote flexible
(plasticity) yet stable representations that preserve old knowledge
(stability). We also demonstrate that our proposed method S2IL achieves strong
incremental accuracy and outperforms other FD methods on SOTA benchmark
datasets CIFAR-100, ImageNet-100 and ImageNet-1K. Notably, S2IL outperforms
other methods by a significant margin in scenarios that have a large number of
incremental tasks.

25 Apr 2025
The dynamics of predator-prey systems influenced by intra-specific
competition and additional food resources have increasingly become a subject of
rigorous study in the realm of mathematical biology. In this study, we consider
an additional food provided prey-predator model exhibiting Holling type-III
functional response and the intra-specific competition among predators. We
prove the existence and uniqueness of global positive solutions for the
proposed model. We study the existence and stability of equilibrium points and
further explore the possible bifurcations. We numerically depict the presence
of Hysteresis loop in the system. We further study the global dynamics of the
system and discuss the consequences of providing additional food. Later, we do
the time-optimal control studies with respect to the quality and quantity of
additional food as control variables by transforming the independent variable
in the control system. We show that the findings of these dynamics and control
studies emphasises the role of additional food and intra-specific competition
in bio-control of pests.

29 Apr 2025
The influence of competition and additional food on prey-predator dynamics
has attracted considerable interest from mathematical biology researchers in
recent times. In this study, we consider an additional food provided
prey-predator model exhibiting Holling type-IV functional response among
mutually interferring predators. We prove the existence and uniqueness of
global positive solutions for the proposed model. We study the existence and
stability of equilibrium points and further explored bifurcations with respect
to the additional food and competition. We further study the global dynamics of
the system and discuss the consequences of providing additional food. Later, we
do the time-optimal control studies with respect to the quality and quantity of
additional food as control variables by transforming the independent variable
in the control system. Making use of the Pontraygin maximum principle, we
characterize the optimal quality of additional food and optimal quantity of
additional food. We further enhanced the model by incorpoating both continuous
and discrete noise. We further characterized and numerically simulated the
stochastic optimal controls through Sufficient Stochastic Maximum Principle. We
show that the findings of these dynamics and control studies have the potential
to be applied to a variety of problems in pest management.

04 Jul 2025
A high-precision experiment in search of the predicted Efimov state in at 7.458 MeV excitation energy was performed. Using a state-of-the-art detector system and novel analysis techniques, it was possible to observe the Efimov state at the predicted energy level above the 3 threshold with much better sensitivity in the excitation energy spectrum compared to the existing data. The mutual resonance (91.84 keV) condition filters out a total of 21 probable Efimov state events around 7.458 MeV. With 2 confidence, it gives an upper limit of 0.014 for the Efimov state -decay width relative to that of the Hoyle state, which is about an order of magnitude smaller than the latest upper limit found in the literature. This observation was supported by a new penetrability calculation assuming a relatively extended structure of the Efimov state compared to the Hoyle state. The effect of the Efimov state was also explored in a nuclear astrophysical scenario, where the triple- reaction rate, including both the Hoyle state and the Efimov state, was found to be larger than the allowed limit, while the temperature dependence of the combined rate was found to be compatible with the helium shell flash criterion of the AGB stars.
There are no more papers matching your filters at the moment.
