
08 Sep 2025
Path-aware networks promise enhanced performance and resilience through multipath transport, but a lack of empirical data on their real-world dynamics hinders the design of effective protocols. This paper presents a longitudinal measurement study of the SCION architecture on the global SCIONLab testbed, characterizing the path stability, diversity, and performance crucial for protocols like Multipath QUIC (MPQUIC). Our measurements reveal a dynamic environment, with significant control-plane churn and short path lifetimes in parts of the testbed. We identify and characterize path discrepancy, a phenomenon where routing policies create asymmetric path availability between endpoints. Furthermore, we observe a performance trade-off where concurrent multipath transmissions can improve aggregate throughput but may degrade the latency and reliability of individual paths. These findings demonstrate that protocols such as MPQUIC should explicitly account for high churn and path asymmetry, challenging common assumptions in multipath protocol design.

30 Sep 2025
The increasing adoption of AI-generated code has reshaped modern software development, introducing syntactic and semantic variations in cloned code. Unlike traditional human-written clones, AI-generated clones exhibit systematic syntactic patterns and semantic differences learned from large-scale training data. This shift presents new challenges for classical code clone detection (CCD) tools, which have historically been validated primarily on human-authored codebases and optimized to detect syntactic (Type 1-3) and limited semantic clones. Given that AI-generated code can produce both syntactic and complex semantic clones, it is essential to evaluate the effectiveness of classical CCD tools within this new paradigm. In this paper, we systematically evaluate nine widely used CCD tools using GPTCloneBench, a benchmark containing GPT-3-generated clones. To contextualize and validate our results, we further test these detectors on established human-authored benchmarks, BigCloneBench and SemanticCloneBench, to measure differences in performance between traditional and AI-generated clones. Our analysis demonstrates that classical CCD tools, particularly those enhanced by effective normalization techniques, retain considerable effectiveness against AI-generated clones, while some exhibit notable performance variation compared to traditional benchmarks. This paper contributes by (1) evaluating classical CCD tools against AI-generated clones, providing critical insights into their current strengths and limitations; (2) highlighting the role of normalization techniques in improving detection accuracy; and (3) delivering detailed scalability and execution-time analyses to support practical CCD tool selection.

27 Mar 2025
This paper introduces an innovative state estimator, MUSE (MUlti-sensor State
Estimator), designed to enhance state estimation's accuracy and real-time
performance in quadruped robot navigation. The proposed state estimator builds
upon our previous work presented in [1]. It integrates data from a range of
onboard sensors, including IMUs, encoders, cameras, and LiDARs, to deliver a
comprehensive and reliable estimation of the robot's pose and motion, even in
slippery scenarios. We tested MUSE on a Unitree Aliengo robot, successfully
closing the locomotion control loop in difficult scenarios, including slippery
and uneven terrain. Benchmarking against Pronto [2] and VILENS [3] showed 67.6%
and 26.7% reductions in translational errors, respectively. Additionally, MUSE
outperformed DLIO [4], a LiDAR-inertial odometry system in rotational errors
and frequency, while the proprioceptive version of MUSE (P-MUSE) outperformed
TSIF [5], with a 45.9% reduction in absolute trajectory error (ATE).
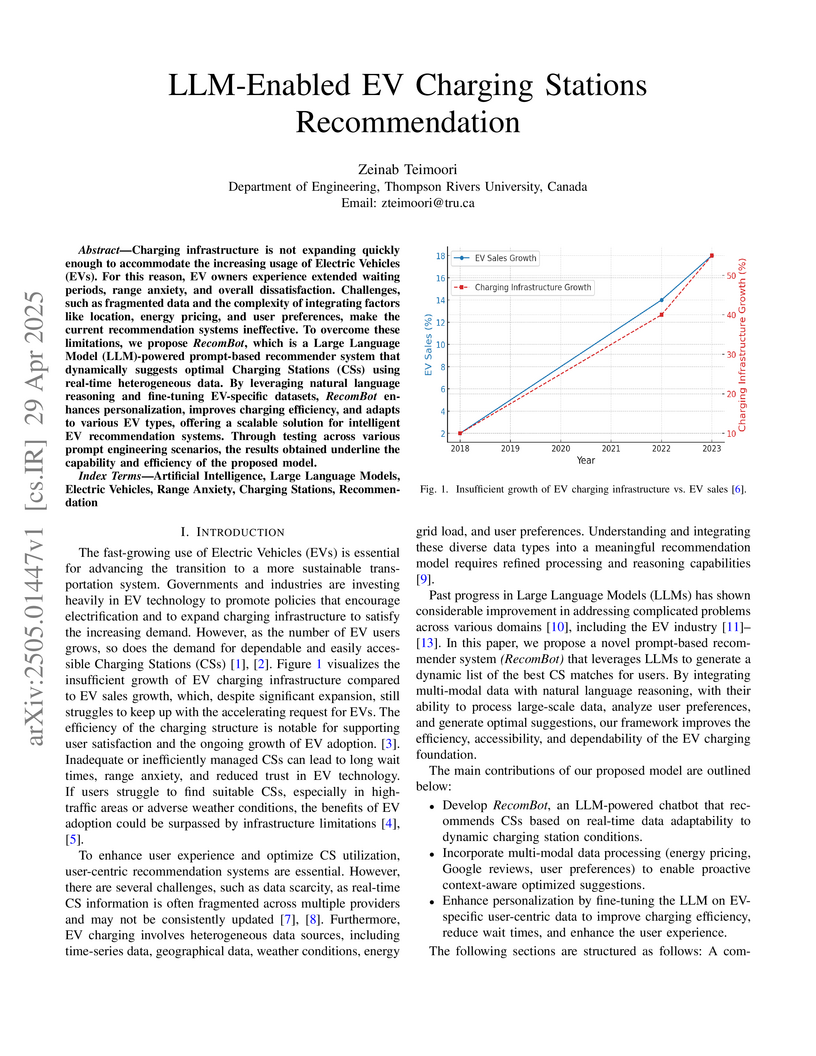
29 Apr 2025
Charging infrastructure is not expanding quickly enough to accommodate the
increasing usage of Electric Vehicles (EVs). For this reason, EV owners
experience extended waiting periods, range anxiety, and overall
dissatisfaction. Challenges, such as fragmented data and the complexity of
integrating factors like location, energy pricing, and user preferences, make
the current recommendation systems ineffective. To overcome these limitations,
we propose RecomBot, which is a Large Language Model (LLM)-powered prompt-based
recommender system that dynamically suggests optimal Charging Stations (CSs)
using real-time heterogeneous data. By leveraging natural language reasoning
and fine-tuning EV-specific datasets, RecomBot enhances personalization,
improves charging efficiency, and adapts to various EV types, offering a
scalable solution for intelligent EV recommendation systems. Through testing
across various prompt engineering scenarios, the results obtained underline the
capability and efficiency of the proposed model.

29 Apr 2025

Researchers from IIT and KAIST develop multi-sensor fusion frameworks (E-InEKF and E-IS) for quadruped robots that integrate LiDAR and GPS data with proprioceptive sensing while preserving group-affine properties, demonstrating reduced position drift and improved accuracy compared to state-of-the-art methods like LIO-SAM and FAST-LIO2 in both indoor and outdoor environments.

28 May 2023
The independent domination number of a graph is the minimum cardinality of a maximal independent set of , also called an -set. The -graph of is the graph whose vertices correspond to the -sets, and where two -sets are adjacent if and only if they differ by two adjacent vertices. Not all graphs are -graph realizable, that is, given a target graph , there does not necessarily exist a source graph such that is the -graph of . We consider a class of graphs called "theta graphs": a theta graph is the union of three internally disjoint nontrivial paths with the same two distinct end vertices. We characterize theta graphs that are -graph realizable, showing that there are only finitely many that are not. We also characterize those line graphs and claw-free graphs that are -graphs, and show that all -connected cubic bipartite planar graphs are -graphs.

26 Aug 2021
This paper concerns the estimation problem of attitude, position, and linear velocity of a rigid-body autonomously navigating with six degrees of freedom (6 DoF). The navigation dynamics are highly nonlinear and are modeled on the matrix Lie group of the extended Special Euclidean Group . A computationally cheap geometric nonlinear stochastic navigation filter is proposed on with guaranteed transient and steady-state performance. The proposed filter operates based on a fusion of sensor measurements collected by a low-cost inertial measurement unit (IMU) and features (obtained by a vision unit). The closed loop error signals are guaranteed to be almost semi-globally uniformly ultimately bounded in the mean square from almost any initial condition. The equivalent quaternion representation is included in the Appendix. The filter is proposed in continuous form, and its discrete form is tested on a real-world dataset of measurements collected by a quadrotor navigating in three dimensional (3D) space. Keywords: Localization, navigation, position and orientation estimation, stochastic systems, GPS-denied navigation observer, navigation estimator, vision-aided inertial navigation systems (VA-INSs), stochastic differential equation, Gaussian noise, sensor fusion.

16 Sep 2025
With the massive deployment of IoT devices in 6G networks, several critical challenges have emerged, such as large communication overhead, coverage limitations, and limited battery lifespan. FL, WPT, multi-antenna AP, and RIS can mitigate these challenges by reducing the need for large data transmissions, enabling sustainable energy harvesting, and optimizing the propagation environment. Compared to conventional RIS, STAR-RIS not only extends coverage from half-space to full-space but also improves energy saving through appropriate mode selection. Motivated by the need for sustainable, low-latency, and energy-efficient communication in large-scale IoT networks, this paper investigates the efficient STAR-RIS mode in the uplink and downlink phases of a WPT-FL multi-antenna AP network with non-orthogonal multiple access to minimize energy consumption, a joint optimization that remains largely unexplored in existing works on RIS or STAR-RIS. We formulate a non-convex energy minimization problem for different STAR-RIS modes, i.e., energy splitting (ES) and time switching (TS), in both uplink and downlink transmission phases, where STAR-RIS phase shift vectors, beamforming matrices, time and power for harvesting, uplink transmission, and downlink transmission, local processing time, and computation frequency for each user are jointly optimized. To tackle the non-convexity, the problem is decoupled into two subproblems: the first subproblem optimizes STAR-RIS phase shift vectors and beamforming matrices across all WPT-FL phases using block coordinate descent over either semi-definite programming or Rayleigh quotient problems, while the second one allocates time, power, and computation frequency via the one-dimensional search algorithms or the bisection algorithm.

11 Mar 2023
The independent domination number of a graph is the minimum cardinality of a maximal independent set of , also called an -set. The -graph of , denoted , is the graph whose vertices correspond to the -sets, and where two -sets are adjacent if and only if they differ by two adjacent vertices. We show that not all graphs are -graph realizable, that is, given a target graph , there does not necessarily exist a source graph such that is isomorphic to . Examples of such graphs include and . We build a series of tools to show that known -graphs can be used to construct new -graphs and apply these results to build other classes of -graphs, such as block graphs, hypercubes, forests, cacti, and unicyclic graphs.

22 Nov 2017
Software game is a kind of application that is used not only for
entertainment, but also for serious purposes that can be applicable to
different domains such as education, business, and health care. Although the
game development process differs from the traditional software development
process because it involves interdisciplinary activities. Software engineering
techniques are still important for game development because they can help the
developer to achieve maintainability, flexibility, lower effort and cost, and
better design. The purpose of this study is to assesses the state of the art
research on the game development software engineering process and highlight
areas that need further consideration by researchers. In the study, we used a
systematic literature review methodology based on well-known digital libraries.
The largest number of studies have been reported in the production phase of the
game development software engineering process life cycle, followed by the
pre-production phase. By contrast, the post-production phase has received much
less research activity than the pre-production and production phases. The
results of this study suggest that the game development software engineering
process has many aspects that need further attention from researchers; that
especially includes the postproduction phase.

29 Sep 2023
QCD Laplace sum-rules are used to examine the constituent mass spectrum of heavy-light [Qq] diquarks with and . As in previous sum-rule studies, the negative parity [Qq] diquark mass predictions do not stabilize, so the sum-rule analysis focuses on positive parity [Qq] diquarks. Doubly-strange [ss] diquarks are also examined, but the resulting sum rules do not stabilize. Hence there is no sum-rule evidence for [ss] diquark states, aiding the interpretation of sum-rule analyses of fully-strange tetraquark states. The SU(3) flavour splitting effects for [Qq] diquarks are obtained by calculating QCD correlation functions of diquark composite operators up to next-to-leading order in perturbation theory, leading-order in the strange quark mass, and in the chiral limit for non-strange (u,d) quarks with an isospin-symmetric vacuum <\bar nn>=<\bar uu>=<\bar dd>. Apart from the strange quark mass parameter , the strange quark condensate parameter \kappa=<\bar ss>/<\bar nn> has an important impact on SU(3) flavour splittings. A Laplace sum-rule analysis methodology is developed for the mass difference between the strange and non-strange heavy-light diquarks to reduce the theoretical uncertainties from all other QCD input parameters. The mass splitting is found to decrease with increasing , providing an upper bound on where the mass hierarchy reverses. In the typical QCD sum-rule range 0.56<\kappa< 0.74, 55~MeV < M_{[cs]}-M_{[cn]} < 100~MeV and 75~MeV < M_{[bs]}-M_{[bn]}< 150~MeV, with a slight tendency for larger splittings for the channels. These constituent mass splitting results are discussed in comparison with values used in constituent diquark models for tetraquark and pentaquark hadronic states.

12 Dec 2018
We have been thinking about other aspects of software engineering for many
years; the missing link in engineering software is the soft skills set,
essential in the software development process. Although soft skills are among
the most important aspects in the creation of software, they are often
overlooked by educators and practitioners. One of the main reasons for the
oversight is that soft skills are usually related to social and personality
factors, i.e., teamwork, motivation, commitment, leadership, multi-culturalism,
emotions, interpersonal skills, etc. This editorial is a manifesto declaring
the importance of soft skills in software engineering with the intention to
draw professionals attention to these topics. We have approached this issue by
mentioning what we know about the field, what we believe to be evident, and
which topics need further investigation. Important references to back up our
claims are also included. Software engineers take pride in the depth of their
technical expertise, which separates them from the crowd. But, what makes a
good software engineer? First, it is the technical knowledge of relevant
methodologies and techniques (i.e. hard skills), as well as the skills
necessary for applying that knowledge in practice. Second, but nonetheless
important, it is a set of soft skills, in particular collaboration,
communication, problem-solving and similar interpersonal and critical thinking
skills that are expected from software engineering professionals. In other
words, software engineers need both hard and soft skills in order to be
successful at the workplace.

18 May 2019
In this paper, we argue that machine learning techniques are not ready for
malware detection in the wild. Given the current trend in malware development
and the increase of unconventional malware attacks, we expect that dynamic
malware analysis is the future for antimalware detection and prevention
systems. A comprehensive review of machine learning for malware detection is
presented. Then, we discuss how malware detection in the wild present unique
challenges for the current state-of-the-art machine learning techniques. We
defined three critical problems that limit the success of malware detectors
powered by machine learning in the wild. Next, we discuss possible solutions to
these challenges and present the requirements of next-generation malware
detection. Finally, we outline potential research directions in machine
learning for malware detection.

24 Sep 2020
A geometric nonlinear observer algorithm for Simultaneous Localization and
Mapping (SLAM) developed on the Lie group of \mathbb{SLAM}_{n}\left(3\right) is
proposed. The presented novel solution estimates the vehicle's pose (i.e.
attitude and position) with respect to landmarks simultaneously positioning the
reference features in the global frame. The proposed estimator on manifold is
characterized by predefined measures of transient and steady-state performance.
Dynamically reducing boundaries guide the error function of the system to
reduce asymptotically to the origin from its starting position within a large
given set. The proposed observer has the ability to use the available velocity
and feature measurements directly. Also, it compensates for unknown constant
bias attached to velocity measurements. Unit-qauternion of the proposed
observer is presented. Numerical results reveal effectiveness of the proposed
observer. Keywords: Nonlinear filter algorithm, Nonlinear observer for
Simultaneous Localization and Mapping, Nonlinear estimator, nonlinear SLAM
observer on manifold, nonlinear SLAM filter on matrix Lie Group, observer
design, asymptotic stability, systematic convergence, Prescribed performance
function, pose estimation, attitude filter, position filter, feature filter,
landmark filter, gradient based SLAM observer, gradient based observer for
SLAM, adaptive estimate, SLAM observer, observer SLAM framework, equivariant
observer, inertial vision unit, visual, SLAM filter, SE(3), SO(3).

26 Mar 2021

There exists many resource allocation problems in the field of wireless
communications which can be formulated as the generalized assignment problems
(GAP). GAP is a generic form of linear sum assignment problem (LSAP) and is
more challenging to solve owing to the presence of both equality and inequality
constraints. We propose a novel deep unsupervised learning (DUL) approach to
solve GAP in a time-efficient manner. More specifically, we propose a new
approach that facilitates to train a deep neural network (DNN) using a
customized loss function. This customized loss function constitutes the
objective function and penalty terms corresponding to both equality and
inequality constraints. Furthermore, we propose to employ a Softmax activation
function at the output of DNN along with tensor splitting which simplifies the
customized loss function and guarantees to meet the equality constraint. As a
case-study, we consider a typical user-association problem in a wireless
network, formulate it as GAP, and consequently solve it using our proposed DUL
approach. Numerical results demonstrate that the proposed DUL approach provides
near-optimal results with significantly lower time-complexity.

24 Jul 2015
We review the literature relating to soft skills and the software engineering
and information systems domain before describing a study based on 650 job
advertisements posted on well-known recruitment sites from a range of
geographical locations including, North America, Europe, Asia and Australia.
The study makes use of nine defined soft skills to assess the level of demand
for each of these skills related to individual job roles within the software
industry. This work reports some of the vital statistics from industry about
the requirements of soft skills in various roles of software development
phases. The work also highlights the variation in the types of skills required
for each of the roles. We found that currently although the software industry
is paying attention to soft skills up to some extent while hiring but there is
a need to further acknowledge the role of these skills in software development.
The objective of this paper is to analyze the software industry soft skills
requirements for various software development positions, such as system
analyst, designer, programmer, and tester. We pose two research questions,
namely, (1) What soft skills are appropriate to different software development
lifecycle roles, and (2) Up to what extend does the software industry consider
soft skills when hiring an employee. The study suggests that there is a further
need of acknowledgment of the significance of soft skills from employers in
software industry.

10 Jan 2022
In order to meet the extremely heterogeneous requirements of the next
generation wireless communication networks, research community is increasingly
dependent on using machine learning solutions for real-time decision-making and
radio resource management. Traditional machine learning employs fully
centralized architecture in which the entire training data is collected at one
node e.g., cloud server, that significantly increases the communication
overheads and also raises severe privacy concerns. Towards this end, a
distributed machine learning paradigm termed as Federated learning (FL) has
been proposed recently. In FL, each participating edge device trains its local
model by using its own training data. Then, via the wireless channels the
weights or parameters of the locally trained models are sent to the central PS,
that aggregates them and updates the global model. On one hand, FL plays an
important role for optimizing the resources of wireless communication networks,
on the other hand, wireless communications is crucial for FL. Thus, a
`bidirectional' relationship exists between FL and wireless communications.
Although FL is an emerging concept, many publications have already been
published in the domain of FL and its applications for next generation wireless
networks. Nevertheless, we noticed that none of the works have highlighted the
bidirectional relationship between FL and wireless communications. Therefore,
the purpose of this survey paper is to bridge this gap in literature by
providing a timely and comprehensive discussion on the interdependency between
FL and wireless communications.

08 Sep 2023
 University of Toronto
University of Toronto McGill University
McGill University University of British Columbia
University of British Columbia Yale University
Yale University Arizona State University
Arizona State University Perimeter Institute for Theoretical PhysicsNational Research Council Canada
Perimeter Institute for Theoretical PhysicsNational Research Council Canada MIT
MIT University of GroningenMIT Kavli Institute for Astrophysics and Space ResearchWest Virginia UniversityCanadian Institute for Theoretical AstrophysicsDunlap Institute for Astronomy and AstrophysicsUniversity of British Columbia OkanaganThompson Rivers UniversityDominion Radio Astrophysical Observatory
University of GroningenMIT Kavli Institute for Astrophysics and Space ResearchWest Virginia UniversityCanadian Institute for Theoretical AstrophysicsDunlap Institute for Astronomy and AstrophysicsUniversity of British Columbia OkanaganThompson Rivers UniversityDominion Radio Astrophysical ObservatoryWe report the detection of 21 cm emission at an average redshift in the cross-correlation of data from the Canadian Hydrogen Intensity Mapping Experiment (CHIME) with measurements of the Lyman- forest from eBOSS. Data collected by CHIME over 88 days in the ~MHz frequency band (1.8 < z < 2.5) are formed into maps of the sky and high-pass delay filtered to suppress the foreground power, corresponding to removing cosmological scales with at the average redshift. Line-of-sight spectra to the eBOSS background quasar locations are extracted from the CHIME maps and combined with the Lyman- forest flux transmission spectra to estimate the 21 cm-Lyman- cross-correlation function. Fitting a simulation-derived template function to this measurement results in a detection significance. The coherent accumulation of the signal through cross-correlation is sufficient to enable a detection despite excess variance from foreground residuals times brighter than the expected thermal noise level in the correlation function. These results are the highest-redshift measurement of \tcm emission to date, and set the stage for future 21 cm intensity mapping analyses at z>1.8.

21 Jan 2021
This paper concerns the problem of attitude determination and estimation. The early applications considered algebraic methods of attitude determination. Attitude determination algorithms were supplanted by the Gaussian attitude estimation filters (which continue to be widely used in commercial applications). However, the sensitivity of the Gaussian attitude filter to the measurement noise prompted the introduction of the nonlinear attitude filters which account for the nonlinear nature of the attitude dynamics problem and allow for a simpler filter derivation. This paper presents a survey of several types of attitude determination and estimation algorithms. Each category is detailed and illustrated with literature examples in both continuous and discrete form. A comparison between these algorithms is demonstrated in terms of transient and steady-state error through simulation results. The comparison is supplemented by statistical analysis of the error-related mean, infinity norm, and standard deviation of each algorithm in the steady-state. Keywords: Comparative Study, Attitude, Determination, Estimation, Filter, Adaptive Filter, Gaussian Filter, Nonlinear Filter, Overview, Review, Rodrigues Vector, Special Orthogonal Group, Unit-quaternion, Angle-axis, Determinstic, Stochastic, Continuous, Discrete, Multiplicative extended kalman filter, KF, EKF, MEKF, white noise, colored noise.

10 Dec 2014

This work brings together ideas of mixing graph colourings, discrete
homotopy, and precolouring extension. A particular focus is circular
colourings. We prove that all the -colourings of a graph can be
obtained by successively recolouring a single vertex provided
along the lines of Cereceda, van den Heuvel and Johnson's result for
-colourings. We give various bounds for such mixing results and discuss
their sharpness, including cases where the bounds for circular and classical
colourings coincide. As a corollary, we obtain an Albertson-type extension
theorem for -precolourings of circular cliques. Such a result was first
conjectured by Albertson and West. General results on homomorphism mixing are
presented, including a characterization of graphs for which the
endomorphism monoid can be generated through the mixing process. As in similar
work of Brightwell and Winkler, the concept of dismantlability plays a key
role.
There are no more papers matching your filters at the moment.
