
05 Sep 2024




OpenVLA introduces a fully open-source, 7B-parameter Vision-Language-Action model that sets a new state of the art for generalist robot manipulation, outperforming larger closed-source models by 16.5% absolute success rate. The model also demonstrates effective and efficient fine-tuning strategies for adapting to new robot setups and tasks on commodity hardware.

14 Mar 2024

Researchers from Columbia University, Google DeepMind, and MIT present Diffusion Policy, a framework that leverages denoising diffusion probabilistic models for learning visuomotor robot policies. This approach achieves an average 46.9% success rate improvement over baselines in simulation and robust real-world performance on complex manipulation tasks by effectively modeling multimodal action distributions.
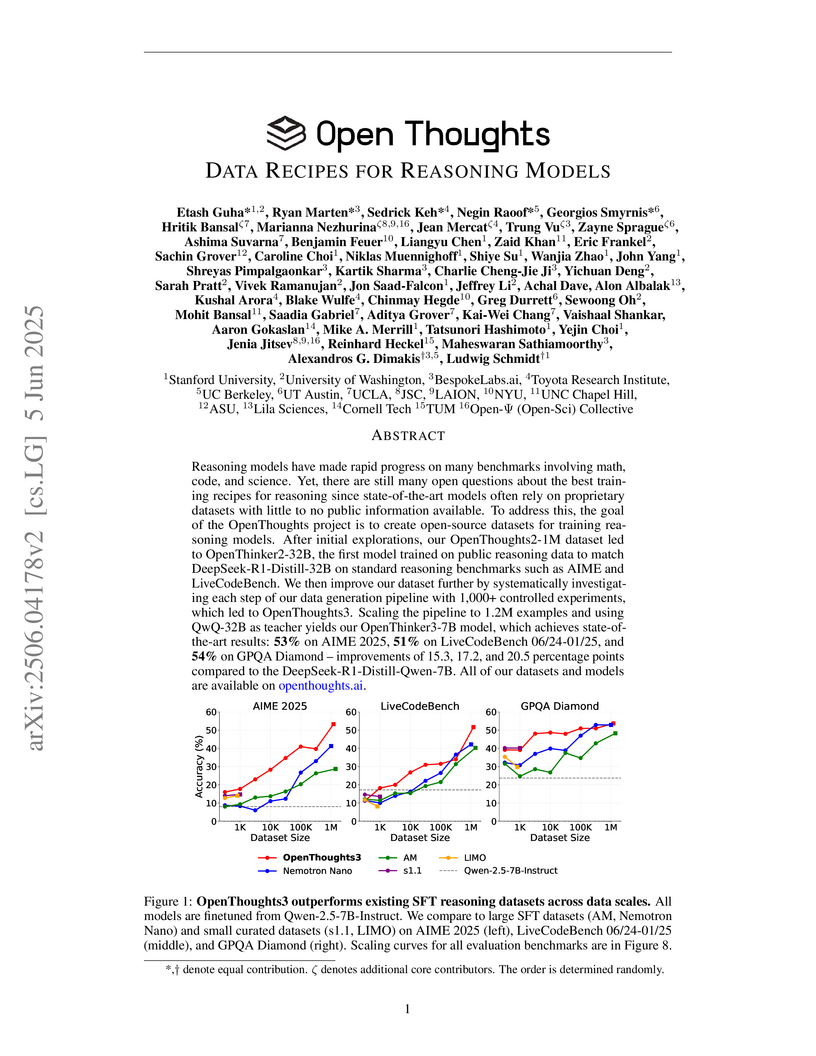
05 Jun 2025





The OpenThoughts project systematically investigated data curation for supervised fine-tuning, developing the OpenThoughts3 dataset and OpenThinker3-7B model to address the opacity of proprietary reasoning model training. OpenThinker3-7B achieved new state-of-the-art results for open-data 7B scale models, outperforming DeepSeek-R1-Distill-7B by 12.4 percentage points on average across 12 reasoning benchmarks.

09 Dec 2024



DPPO introduces a policy optimization framework for fine-tuning pre-trained diffusion-based robot policies using policy gradient methods, demonstrating robust training, improved performance, and a substantial reduction in the sim-to-real gap on various manipulation tasks.

10 Nov 2025
A new framework, PhysWorld, enables robots to learn and execute complex manipulation tasks in a zero-shot manner by generating physically feasible actions from task-conditioned videos. It rebuilds the physical world from generated visual data, leading to an 82% average success rate in real-world tasks and significantly reducing grasping failures from 18% to 3%.

21 Apr 2025




DataComp-LM introduces a standardized, large-scale benchmark for evaluating language model training data curation strategies, complete with an openly released corpus, framework, and models. Its DCLM-BASELINE 7B model, trained on carefully filtered Common Crawl data, achieves 64% MMLU 5-shot accuracy, outperforming previous open-data state-of-the-art models while requiring substantially less compute.

07 Jul 2025
Researchers at the Toyota Research Institute conducted a rigorous evaluation of Large Behavior Models (LBMs) for dexterous manipulation, demonstrating that LBMs finetuned on specific tasks consistently outperform single-task policies, exhibiting greater robustness to distribution shifts and requiring significantly less task-specific data (e.g., less than 30% in simulation) to achieve comparable performance.

23 May 2025
Unified World Models (UWM), developed by researchers at the University of Washington and Toyota Research Institute, presents a diffusion-based framework that unifies robot policy learning and world modeling within a single transformer, enabling it to learn from both action-labeled robotic data and action-free video datasets. The model demonstrates improved task success rates and robustness on real-world robot manipulation tasks, outperforming existing baselines.
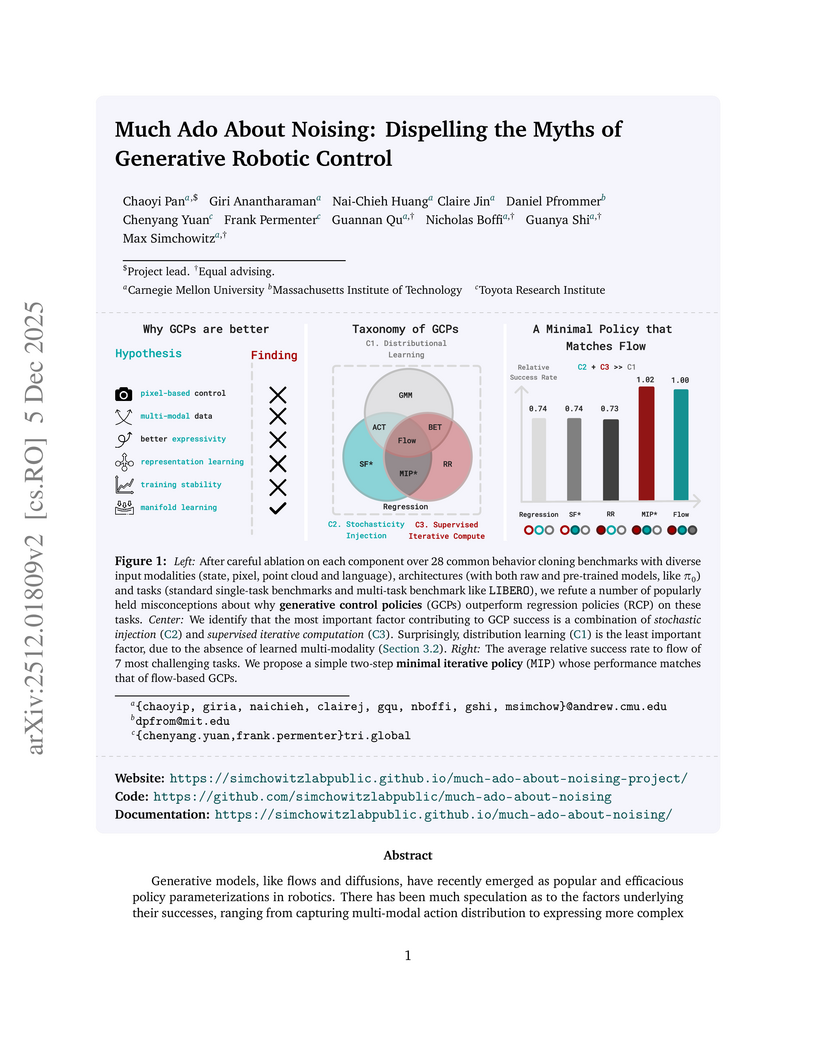
05 Dec 2025
Researchers from Carnegie Mellon University, MIT, and Toyota Research Institute reveal that the superior performance of Generative Control Policies (GCPs) in robotics largely stems from training-time stochasticity and supervised iterative computation, not their generative objective or ability to model multi-modal action distributions. Their proposed Minimal Iterative Policy (MIP), which integrates these two components, achieves performance comparable to complex flow-based GCPs across various behavior cloning benchmarks.
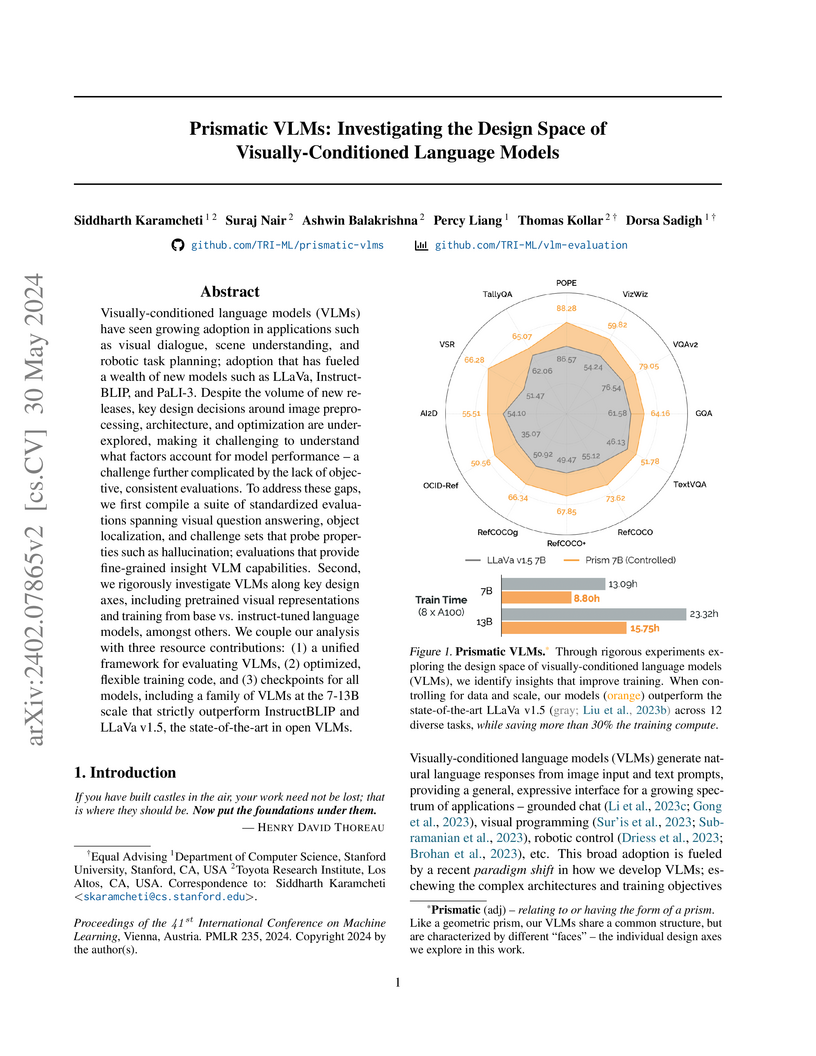
30 May 2024
The work systematically explores the design space of visually-conditioned language models (VLMs), providing empirical insights into image processing, visual representations, and training methodologies. It identifies key factors for VLM performance and efficiency, culminating in the development of PRISM models which demonstrate improved performance over existing open-source state-of-the-art VLMs across a standardized evaluation suite.

29 Jan 2025

A new comprehensive benchmark, PhysBench, evaluates Vision-Language Models' (VLMs) understanding of the physical world, revealing an average accuracy of approximately 40% across 75 models. The proposed PhysAgent framework enhances VLMs' physical reasoning by 18.4% for GPT-4o on this benchmark, directly improving robotic manipulation task performance.

09 Oct 2025
Humanoid Everyday introduces a large-scale, multimodal dataset of over 10.3k trajectories across 260 diverse tasks for real-world humanoid manipulation, collected using a high-efficiency teleoperation pipeline. It also presents a cloud-based platform for standardized policy evaluation, revealing that even leading imitation learning models like GR00T N1.5 struggle significantly with high-dimensional humanoid control and complex tasks such as loco-manipulation.

20 Mar 2023
A framework named Zero-1-to-3 generates novel views of an object from a single RGB image and reconstructs its 3D model without requiring category-specific 3D training data. It leverages implicit 3D knowledge within large pre-trained 2D diffusion models, demonstrating robust generalization across object types and achieving accurate 3D representations.

01 Aug 2025
A "Video Policy" framework developed by Columbia University and Toyota Research Institute leverages video generation as a proxy for robot policy acquisition, demonstrating improved generalization and sample efficiency in visuomotor learning, including state-of-the-art results with as few as 50 human demonstrations per task.

14 May 2025
Researchers from UC Berkeley and Toyota Research Institute introduce Real2Render2Real (R2R2R), a framework that generates diverse robot training data from smartphone videos without requiring dynamics simulation or robot hardware, achieving 51 demonstrations per minute compared to 1.7 via human teleoperation while matching teleoperation-trained policy performance.

30 Oct 2025

Gu et al. developed SAFE, an efficient multitask failure detection system for generalist Vision-Language-Action (VLA) models, which leverages internal VLA features and functional Conformal Prediction. The system demonstrated superior failure detection performance and real-time computational efficiency on unseen robotic manipulation tasks in both simulation and real-world experiments.

08 Oct 2025
RoLA converts any single in-the-wild image into a physically accurate, interactive robotic environment, enabling scalable generation of visuomotor demonstrations for training robust robot policies. This framework facilitates robot learning from diverse ambient visual data, allowing successful real-world deployment across various robotic systems.

23 Sep 2025


In robot imitation learning, policy performance is tightly coupled with the quality and composition of the demonstration data. Yet, developing a precise understanding of how individual demonstrations contribute to downstream outcomes - such as closed-loop task success or failure - remains a persistent challenge. We propose CUPID, a robot data curation method based on a novel influence function-theoretic formulation for imitation learning policies. Given a set of evaluation rollouts, CUPID estimates the influence of each training demonstration on the policy's expected return. This enables ranking and selection of demonstrations according to their impact on the policy's closed-loop performance. We use CUPID to curate data by 1) filtering out training demonstrations that harm policy performance and 2) subselecting newly collected trajectories that will most improve the policy. Extensive simulated and hardware experiments show that our approach consistently identifies which data drives test-time performance. For example, training with less than 33% of curated data can yield state-of-the-art diffusion policies on the simulated RoboMimic benchmark, with similar gains observed in hardware. Furthermore, hardware experiments show that our method can identify robust strategies under distribution shift, isolate spurious correlations, and even enhance the post-training of generalist robot policies. Videos and code are made available at: this https URL.

15 Apr 2025
A framework from Carnegie Mellon and Toyota Research Institute enables zero-shot robotic grasping by combining octree-based 3D shape reconstruction with grasp pose prediction from single RGB-D images, achieving state-of-the-art performance on the GraspNet-1B benchmark while generalizing to novel real-world objects through training on synthetic data.

01 Aug 2025
We introduce AllTracker: a model that estimates long-range point tracks by way of estimating the flow field between a query frame and every other frame of a video. Unlike existing point tracking methods, our approach delivers high-resolution and dense (all-pixel) correspondence fields, which can be visualized as flow maps. Unlike existing optical flow methods, our approach corresponds one frame to hundreds of subsequent frames, rather than just the next frame. We develop a new architecture for this task, blending techniques from existing work in optical flow and point tracking: the model performs iterative inference on low-resolution grids of correspondence estimates, propagating information spatially via 2D convolution layers, and propagating information temporally via pixel-aligned attention layers. The model is fast and parameter-efficient (16 million parameters), and delivers state-of-the-art point tracking accuracy at high resolution (i.e., tracking 768x1024 pixels, on a 40G GPU). A benefit of our design is that we can train jointly on optical flow datasets and point tracking datasets, and we find that doing so is crucial for top performance. We provide an extensive ablation study on our architecture details and training recipe, making it clear which details matter most. Our code and model weights are available at this https URL
There are no more papers matching your filters at the moment.
