
14 Oct 2025
Photography during night or in dark conditions typically suffers from noise, low light and blurring issues due to the dim environment and the common use of long exposure. Although Deblurring and Low-light Image Enhancement (LLIE) are related under these conditions, most approaches in image restoration solve these tasks separately. In this paper, we present an efficient and robust neural network for multi-task low-light image restoration. Instead of following the current tendency of Transformer-based models, we propose new attention mechanisms to enhance the receptive field of efficient CNNs. Our method reduces the computational costs in terms of parameters and MAC operations compared to previous methods. Our model, DarkIR, achieves new state-of-the-art results on the popular LOLBlur, LOLv2 and Real-LOLBlur datasets, being able to generalize on real-world night and dark images. Code and models at this https URL
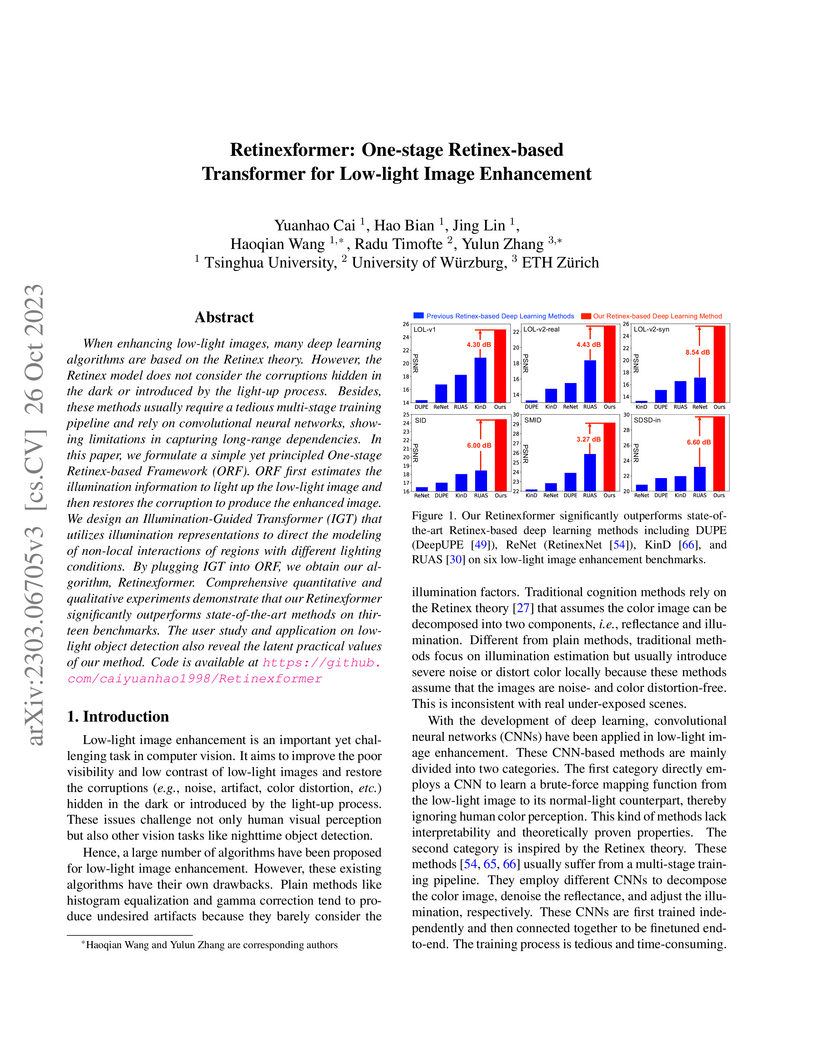
26 Oct 2023



When enhancing low-light images, many deep learning algorithms are based on the Retinex theory. However, the Retinex model does not consider the corruptions hidden in the dark or introduced by the light-up process. Besides, these methods usually require a tedious multi-stage training pipeline and rely on convolutional neural networks, showing limitations in capturing long-range dependencies. In this paper, we formulate a simple yet principled One-stage Retinex-based Framework (ORF). ORF first estimates the illumination information to light up the low-light image and then restores the corruption to produce the enhanced image. We design an Illumination-Guided Transformer (IGT) that utilizes illumination representations to direct the modeling of non-local interactions of regions with different lighting conditions. By plugging IGT into ORF, we obtain our algorithm, Retinexformer. Comprehensive quantitative and qualitative experiments demonstrate that our Retinexformer significantly outperforms state-of-the-art methods on thirteen benchmarks. The user study and application on low-light object detection also reveal the latent practical values of our method. Code, models, and results are available at this https URL

25 Sep 2024
InstructIR introduces the first all-in-one image restoration model capable of high-quality image recovery guided by natural human instructions. The system achieves an average PSNR of 29.55 dB on a 5-degradation benchmark, representing a 1dB improvement over previous state-of-the-art all-in-one methods, and enables controllable enhancement through sequential text prompts.

15 May 2023


Plug-and-play Image Restoration (IR) has been widely recognized as a flexible and interpretable method for solving various inverse problems by utilizing any off-the-shelf denoiser as the implicit image prior. However, most existing methods focus on discriminative Gaussian denoisers. Although diffusion models have shown impressive performance for high-quality image synthesis, their potential to serve as a generative denoiser prior to the plug-and-play IR methods remains to be further explored. While several other attempts have been made to adopt diffusion models for image restoration, they either fail to achieve satisfactory results or typically require an unacceptable number of Neural Function Evaluations (NFEs) during inference. This paper proposes DiffPIR, which integrates the traditional plug-and-play method into the diffusion sampling framework. Compared to plug-and-play IR methods that rely on discriminative Gaussian denoisers, DiffPIR is expected to inherit the generative ability of diffusion models. Experimental results on three representative IR tasks, including super-resolution, image deblurring, and inpainting, demonstrate that DiffPIR achieves state-of-the-art performance on both the FFHQ and ImageNet datasets in terms of reconstruction faithfulness and perceptual quality with no more than 100 NFEs. The source code is available at {\url{this https URL}}

05 May 2024
Multi-Task Reinforcement Learning (MTRL) tackles the long-standing problem of
endowing agents with skills that generalize across a variety of problems. To
this end, sharing representations plays a fundamental role in capturing both
unique and common characteristics of the tasks. Tasks may exhibit similarities
in terms of skills, objects, or physical properties while leveraging their
representations eases the achievement of a universal policy. Nevertheless, the
pursuit of learning a shared set of diverse representations is still an open
challenge. In this paper, we introduce a novel approach for representation
learning in MTRL that encapsulates common structures among the tasks using
orthogonal representations to promote diversity. Our method, named Mixture Of
Orthogonal Experts (MOORE), leverages a Gram-Schmidt process to shape a shared
subspace of representations generated by a mixture of experts. When
task-specific information is provided, MOORE generates relevant representations
from this shared subspace. We assess the effectiveness of our approach on two
MTRL benchmarks, namely MiniGrid and MetaWorld, showing that MOORE surpasses
related baselines and establishes a new state-of-the-art result on MetaWorld.

13 Mar 2025

Recent advancements in all-in-one image restoration models have
revolutionized the ability to address diverse degradations through a unified
framework. However, parameters tied to specific tasks often remain inactive for
other tasks, making mixture-of-experts (MoE) architectures a natural extension.
Despite this, MoEs often show inconsistent behavior, with some experts
unexpectedly generalizing across tasks while others struggle within their
intended scope. This hinders leveraging MoEs' computational benefits by
bypassing irrelevant experts during inference. We attribute this undesired
behavior to the uniform and rigid architecture of traditional MoEs. To address
this, we introduce ``complexity experts" -- flexible expert blocks with varying
computational complexity and receptive fields. A key challenge is assigning
tasks to each expert, as degradation complexity is unknown in advance. Thus, we
execute tasks with a simple bias toward lower complexity. To our surprise, this
preference effectively drives task-specific allocation, assigning tasks to
experts with the appropriate complexity. Extensive experiments validate our
approach, demonstrating the ability to bypass irrelevant experts during
inference while maintaining superior performance. The proposed MoCE-IR model
outperforms state-of-the-art methods, affirming its efficiency and practical
applicability. The source code and models are publicly available at
\href{this https URL}{\texttt{eduardzamfir.github.io/MoCE-IR/}}

14 Apr 2025

This paper presents a comprehensive review of the NTIRE 2025 Challenge on
Single-Image Efficient Super-Resolution (ESR). The challenge aimed to advance
the development of deep models that optimize key computational metrics, i.e.,
runtime, parameters, and FLOPs, while achieving a PSNR of at least 26.90 dB on
the dataset and 26.99 dB on the
dataset. A robust participation saw
\textbf{244} registered entrants, with \textbf{43} teams submitting valid
entries. This report meticulously analyzes these methods and results,
emphasizing groundbreaking advancements in state-of-the-art single-image ESR
techniques. The analysis highlights innovative approaches and establishes
benchmarks for future research in the field.
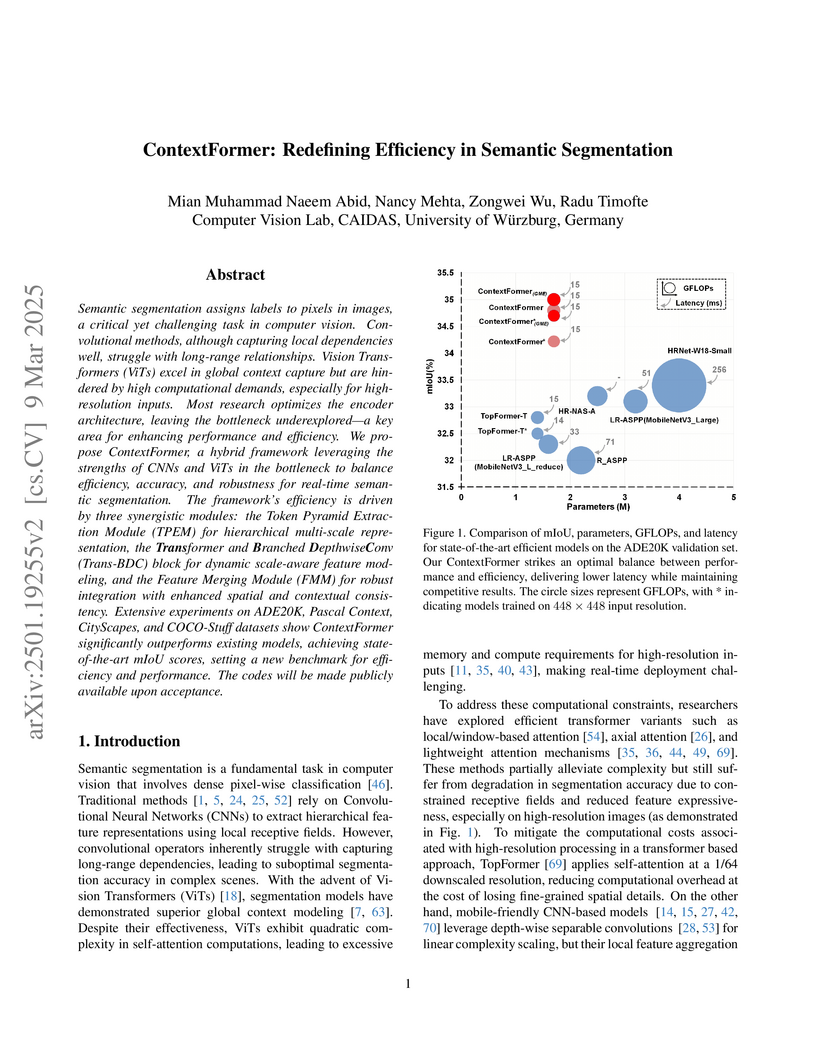
09 Mar 2025
Semantic segmentation assigns labels to pixels in images, a critical yet
challenging task in computer vision. Convolutional methods, although capturing
local dependencies well, struggle with long-range relationships. Vision
Transformers (ViTs) excel in global context capture but are hindered by high
computational demands, especially for high-resolution inputs. Most research
optimizes the encoder architecture, leaving the bottleneck underexplored - a
key area for enhancing performance and efficiency. We propose ContextFormer, a
hybrid framework leveraging the strengths of CNNs and ViTs in the bottleneck to
balance efficiency, accuracy, and robustness for real-time semantic
segmentation. The framework's efficiency is driven by three synergistic
modules: the Token Pyramid Extraction Module (TPEM) for hierarchical
multi-scale representation, the Transformer and Branched DepthwiseConv
(Trans-BDC) block for dynamic scale-aware feature modeling, and the Feature
Merging Module (FMM) for robust integration with enhanced spatial and
contextual consistency. Extensive experiments on ADE20K, Pascal Context,
CityScapes, and COCO-Stuff datasets show ContextFormer significantly
outperforms existing models, achieving state-of-the-art mIoU scores, setting a
new benchmark for efficiency and performance. The codes will be made publicly
available upon acceptance.

06 Feb 2023
AuthentiSense, from Technical University of Darmstadt and University of Würzburg in collaboration with KOBIL, introduces a user-agnostic, scalable behavioral biometrics system for mobile devices utilizing few-shot learning on motion sensor data. The system achieves an F1-score of up to 0.97 and rapid authentication within one second, significantly improving continuous security with minimal user enrollment effort.

15 Apr 2024
We present ANYU, a new virtually augmented version of the NYU depth v2 dataset, designed for monocular depth estimation. In contrast to the well-known approach where full 3D scenes of a virtual world are utilized to generate artificial datasets, ANYU was created by incorporating RGB-D representations of virtual reality objects into the original NYU depth v2 images. We specifically did not match each generated virtual object with an appropriate texture and a suitable location within the real-world image. Instead, an assignment of texture, location, lighting, and other rendering parameters was randomized to maximize a diversity of the training data, and to show that it is randomness that can improve the generalizing ability of a dataset. By conducting extensive experiments with our virtually modified dataset and validating on the original NYU depth v2 and iBims-1 benchmarks, we show that ANYU improves the monocular depth estimation performance and generalization of deep neural networks with considerably different architectures, especially for the current state-of-the-art VPD model. To the best of our knowledge, this is the first work that augments a real-world dataset with randomly generated virtual 3D objects for monocular depth estimation. We make our ANYU dataset publicly available in two training configurations with 10% and 100% additional synthetically enriched RGB-D pairs of training images, respectively, for efficient training and empirical exploration of virtual augmentation at this https URL

17 Feb 2025

Continual learning (CL) is the sub-field of machine learning concerned with
accumulating knowledge in dynamic environments. So far, CL research has mainly
focused on incremental classification tasks, where models learn to classify new
categories while retaining knowledge of previously learned ones. Here, we argue
that maintaining such a focus limits both theoretical development and practical
applicability of CL methods. Through a detailed analysis of concrete examples -
including multi-target classification, robotics with constrained output spaces,
learning in continuous task domains, and higher-level concept memorization - we
demonstrate how current CL approaches often fail when applied beyond standard
classification. We identify three fundamental challenges: (C1) the nature of
continuity in learning problems, (C2) the choice of appropriate spaces and
metrics for measuring similarity, and (C3) the role of learning objectives
beyond classification. For each challenge, we provide specific recommendations
to help move the field forward, including formalizing temporal dynamics through
distribution processes, developing principled approaches for continuous task
spaces, and incorporating density estimation and generative objectives. In so
doing, this position paper aims to broaden the scope of CL research while
strengthening its theoretical foundations, making it more applicable to
real-world problems.

27 Mar 2024
Accurate vegetation models can produce further insights into the complex interaction between vegetation activity and ecosystem processes. Previous research has established that long-term trends and short-term variability of temperature and precipitation affect vegetation activity. Motivated by the recent success of Transformer-based Deep Learning models for medium-range weather forecasting, we adapt the publicly available pre-trained FourCastNet to model vegetation activity while accounting for the short-term dynamics of climate variability. We investigate how the learned global representation of the atmosphere's state can be transferred to model the normalized difference vegetation index (NDVI). Our model globally estimates vegetation activity at a resolution of \SI{0.25}{\degree} while relying only on meteorological data. We demonstrate that leveraging pre-trained weather models improves the NDVI estimates compared to learning an NDVI model from scratch. Additionally, we compare our results to other recent data-driven NDVI modeling approaches from machine learning and ecology literature. We further provide experimental evidence on how much data and training time is necessary to turn FourCastNet into an effective vegetation model. Code and models will be made available upon publication.

24 Apr 2024
This paper reviews the NTIRE 2024 RAW Image Super-Resolution Challenge, highlighting the proposed solutions and results. New methods for RAW Super-Resolution could be essential in modern Image Signal Processing (ISP) pipelines, however, this problem is not as explored as in the RGB domain. Th goal of this challenge is to upscale RAW Bayer images by 2x, considering unknown degradations such as noise and blur. In the challenge, a total of 230 participants registered, and 45 submitted results during thee challenge period. The performance of the top-5 submissions is reviewed and provided here as a gauge for the current state-of-the-art in RAW Image Super-Resolution.

25 Jun 2024
This paper provides a comprehensive review of the NTIRE 2024 challenge, focusing on efficient single-image super-resolution (ESR) solutions and their outcomes. The task of this challenge is to super-resolve an input image with a magnification factor of x4 based on pairs of low and corresponding high-resolution images. The primary objective is to develop networks that optimize various aspects such as runtime, parameters, and FLOPs, while still maintaining a peak signal-to-noise ratio (PSNR) of approximately 26.90 dB on the DIV2K_LSDIR_valid dataset and 26.99 dB on the DIV2K_LSDIR_test dataset. In addition, this challenge has 4 tracks including the main track (overall performance), sub-track 1 (runtime), sub-track 2 (FLOPs), and sub-track 3 (parameters). In the main track, all three metrics (ie runtime, FLOPs, and parameter count) were considered. The ranking of the main track is calculated based on a weighted sum-up of the scores of all other sub-tracks. In sub-track 1, the practical runtime performance of the submissions was evaluated, and the corresponding score was used to determine the ranking. In sub-track 2, the number of FLOPs was considered. The score calculated based on the corresponding FLOPs was used to determine the ranking. In sub-track 3, the number of parameters was considered. The score calculated based on the corresponding parameters was used to determine the ranking. RLFN is set as the baseline for efficiency measurement. The challenge had 262 registered participants, and 34 teams made valid submissions. They gauge the state-of-the-art in efficient single-image super-resolution. To facilitate the reproducibility of the challenge and enable other researchers to build upon these findings, the code and the pre-trained model of validated solutions are made publicly available at this https URL.
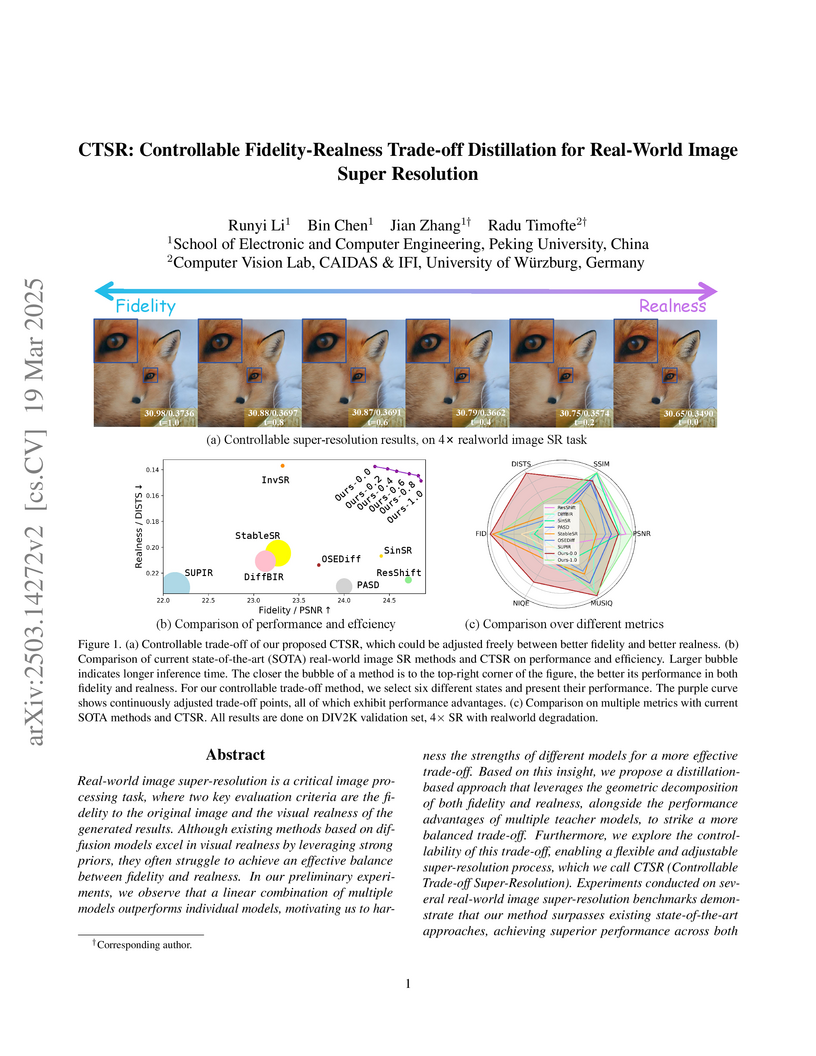
19 Mar 2025

Real-world image super-resolution is a critical image processing task, where
two key evaluation criteria are the fidelity to the original image and the
visual realness of the generated results. Although existing methods based on
diffusion models excel in visual realness by leveraging strong priors, they
often struggle to achieve an effective balance between fidelity and realness.
In our preliminary experiments, we observe that a linear combination of
multiple models outperforms individual models, motivating us to harness the
strengths of different models for a more effective trade-off. Based on this
insight, we propose a distillation-based approach that leverages the geometric
decomposition of both fidelity and realness, alongside the performance
advantages of multiple teacher models, to strike a more balanced trade-off.
Furthermore, we explore the controllability of this trade-off, enabling a
flexible and adjustable super-resolution process, which we call CTSR
(Controllable Trade-off Super-Resolution). Experiments conducted on several
real-world image super-resolution benchmarks demonstrate that our method
surpasses existing state-of-the-art approaches, achieving superior performance
across both fidelity and realness metrics.

21 Oct 2025
Even small electrostatic potentials can dramatically influence the band structure of narrow-, broken-, and inverted-gap materials. A quantitative understanding often necessitates a self-consistent Hartree approach. The valence and conduction band states strongly hybridize and/or cross in these systems. This makes distinguishing between electrons and holes impossible and the assumption of a flat charge carrier distribution at the charge neutrality point hard to justify. Consequently the wide-gap approach often fails in these systems. An alternative is the full-band envelope-function approach by Andlauer and Vogl, which has been implemented into the open-source software package kdotpy (arXiv:2407.12651). We show that this approach and implementation gives numerically stable and quantitatively accurate results where the conventional method fails by modeling the experimental subband density evolution with top-gate voltage in thick (26 nm - 110 nm), topologically inverted HgTe quantum wells. We expect our openly-available implementation to greatly benefit the investigation of narrow-, broken-, and inverted-gap materials.

25 Apr 2024

This paper introduces a novel benchmark as part of the AIS 2024 Real-Time Image Super-Resolution (RTSR) Challenge, which aims to upscale compressed images from 540p to 4K resolution (4x factor) in real-time on commercial GPUs. For this, we use a diverse test set containing a variety of 4K images ranging from digital art to gaming and photography. The images are compressed using the modern AVIF codec, instead of JPEG. All the proposed methods improve PSNR fidelity over Lanczos interpolation, and process images under 10ms. Out of the 160 participants, 25 teams submitted their code and models. The solutions present novel designs tailored for memory-efficiency and runtime on edge devices. This survey describes the best solutions for real-time SR of compressed high-resolution images.

20 Jun 2024
Modular vision-language models (Vision-LLMs) align pretrained image encoders with (frozen) large language models (LLMs) and post-hoc condition LLMs to `understand' the image input. With the abundance of readily available high-quality English image-text data as well as strong monolingual English LLMs, the research focus has been on English-only Vision-LLMs. Multilingual vision-language models are still predominantly obtained via expensive end-to-end pretraining, resulting in comparatively smaller models, trained on limited multilingual image data supplemented with text-only multilingual corpora. We present mBLIP, the first Vision-LLM leveraging multilingual LLMs, which we obtain in a computationally efficient manner on consumer-level hardware. To this end, we \textit{re-align} an image encoder previously tuned to an English LLM to a new, multilingual LLM using only a few million multilingual training examples derived from a mix of vision-and-language tasks, which we obtain by machine-translating high-quality English data to 95 languages. On the IGLUE benchmark and XM3600, mBLIP yields results competitive with state-of-the-art models and it greatly outperforms strong English-only Vision-LLMs like Llava 1.5. We release our model, code, and train data at \url{this https URL}.

18 Mar 2025

Non-reciprocal interactions in elastic media give rise to rich
non-equilibrium behaviors, but controllable experimental realizations of such
odd elastic phenomena remain scarce. Building on recent breakthroughs in
electrical analogs of non-Hermitian solid-state systems, we design and analyze
scalable odd electrical circuits (OECs) as exact analogs of an odd solid. We
show that electrical work can be extracted from OECs via cyclic excitations and
trace the apparent energy gain back to active circuit elements. We show that
OECs host oscillatory modes that resemble recent experimental observations in
living chiral crystals and identify active resonances that reveal a perspective
on odd elasticity as a mechanism for mechanical amplification.

14 Mar 2024

Humans are adept at leveraging visual cues from lip movements for recognizing speech in adverse listening conditions. Audio-Visual Speech Recognition (AVSR) models follow similar approach to achieve robust speech recognition in noisy conditions. In this work, we present a multilingual AVSR model incorporating several enhancements to improve performance and audio noise robustness. Notably, we adapt the recently proposed Fast Conformer model to process both audio and visual modalities using a novel hybrid CTC/RNN-T architecture. We increase the amount of audio-visual training data for six distinct languages, generating automatic transcriptions of unlabelled multilingual datasets (VoxCeleb2 and AVSpeech). Our proposed model achieves new state-of-the-art performance on the LRS3 dataset, reaching WER of 0.8%. On the recently introduced MuAViC benchmark, our model yields an absolute average-WER reduction of 11.9% in comparison to the original baseline. Finally, we demonstrate the ability of the proposed model to perform audio-only, visual-only, and audio-visual speech recognition at test time.
There are no more papers matching your filters at the moment.
