
10 Jun 2025


Memory is crucial for enabling agents to tackle complex tasks with temporal
and spatial dependencies. While many reinforcement learning (RL) algorithms
incorporate memory, the field lacks a universal benchmark to assess an agent's
memory capabilities across diverse scenarios. This gap is particularly evident
in tabletop robotic manipulation, where memory is essential for solving tasks
with partial observability and ensuring robust performance, yet no standardized
benchmarks exist. To address this, we introduce MIKASA (Memory-Intensive Skills
Assessment Suite for Agents), a comprehensive benchmark for memory RL, with
three key contributions: (1) we propose a comprehensive classification
framework for memory-intensive RL tasks, (2) we collect MIKASA-Base -- a
unified benchmark that enables systematic evaluation of memory-enhanced agents
across diverse scenarios, and (3) we develop MIKASA-Robo (pip install
mikasa-robo-suite) -- a novel benchmark of 32 carefully designed
memory-intensive tasks that assess memory capabilities in tabletop robotic
manipulation. Our work introduces a unified framework to advance memory RL
research, enabling more robust systems for real-world use. MIKASA is available
at this https URL

05 Aug 2025

Researchers identified interpretable internal features in Large Language Models responsible for reasoning processes using Sparse Autoencoders and a novel metric called ReasonScore. This work established a causal link between these features and the models' observable reasoning behavior, leading to performance improvements on benchmarks and insights into how reasoning capabilities emerge during fine-tuning.

15 May 2025
Researchers from AIRI and Skoltech developed AriGraph, a memory architecture that integrates semantic and episodic memory into a dynamic knowledge graph for Large Language Model (LLM) agents. This system enables LLM agents to autonomously learn and update structured world models, leading to superior performance in complex, partially observable text-based games and achieving human-level scores in some tasks.

17 May 2025
The CrafText benchmark is introduced to evaluate instruction following in complex, dynamic, multimodal environments. It provides a challenging platform where current methods demonstrate suboptimal performance, particularly in linguistic and goal generalization, highlighting areas for future research.

08 Dec 2022

Researchers at the Neural Networks and Deep Learning Lab at MIPT and AIRI developed the Recurrent Memory Transformer (RMT), an architecture that extends Transformer models' ability to process long sequences by incorporating explicit, learnable memory tokens. RMT achieves superior long-term dependency handling and memory efficiency on algorithmic tasks and language modeling, while also enabling existing pre-trained models to process significantly longer texts for classification tasks.

01 Oct 2025
HSE University researchers developed a fully Riemannian framework for Low-Rank Adaptation (LoRA), optimizing adapters directly on the fixed-rank matrix manifold using the novel Riemannion optimizer and a gradient-informed initialization. This approach resolves parametrization ambiguity and achieves higher accuracy, faster convergence, and greater stability in fine-tuning large language models and diffusion models.

06 Aug 2025

Researchers from HSE University and AIRI introduce matrix-free randomized algorithms, TwINEst and TwINEst++, for accurately estimating the two-to-infinity and one-to-two matrix norms. These algorithms provide theoretical convergence guarantees and empirical evidence showing superior accuracy and stability, which translates to improved generalization and adversarial robustness when used as regularizers in deep learning and recommender systems.

11 Jun 2025

This paper introduces Reinforcement Learning via Self-Confidence (RLSC), a method that fine-unes large language models by maximizing their internal confidence in generated outputs. This approach achieves substantial performance gains across challenging mathematical reasoning benchmarks, with up to a 21.7% increase on Minerva Math, without requiring human labels or external reward models.

14 Oct 2024
Recently, the use of transformers in offline reinforcement learning has become a rapidly developing area. This is due to their ability to treat the agent's trajectory in the environment as a sequence, thereby reducing the policy learning problem to sequence modeling. In environments where the agent's decisions depend on past events (POMDPs), it is essential to capture both the event itself and the decision point in the context of the model. However, the quadratic complexity of the attention mechanism limits the potential for context expansion. One solution to this problem is to extend transformers with memory mechanisms. This paper proposes a Recurrent Action Transformer with Memory (RATE), a novel model architecture that incorporates a recurrent memory mechanism designed to regulate information retention. To evaluate our model, we conducted extensive experiments on memory-intensive environments (ViZDoom-Two-Colors, T-Maze, Memory Maze, Minigrid-Memory), classic Atari games, and MuJoCo control environments. The results show that using memory can significantly improve performance in memory-intensive environments, while maintaining or improving results in classic environments. We believe that our results will stimulate research on memory mechanisms for transformers applicable to offline reinforcement learning.

07 Nov 2024

Optimal Flow Matching (OFM) introduces a method to learn generative flows with perfectly straight trajectories, directly recovering the optimal transport map in a single training step. The approach achieves superior performance on high-dimensional optimal transport benchmarks and competitive results in unpaired image-to-image translation while enabling efficient one-step inference.

06 Nov 2024

A new benchmark, BABILong, evaluates large language models' ability to perform complex reasoning over extremely long contexts, extending up to 50 million tokens. Evaluations reveal that popular LLMs effectively utilize only 10-20% of their stated context for reasoning, whereas specialized recurrent architectures like RMT and ARMT demonstrate superior performance on sequences reaching tens of millions of tokens.

07 Aug 2025
The recently proposed Large Concept Model (LCM) generates text by predicting a sequence of sentence-level embeddings and training with either mean-squared error or diffusion objectives. We present SONAR-LLM, a decoder-only transformer that "thinks" in the same continuous SONAR embedding space, yet is supervised through token-level cross-entropy propagated via the frozen SONAR decoder. This hybrid objective retains the semantic abstraction of LCM while eliminating its diffusion sampler and restoring a likelihood-based training signal. Across model sizes from 39M to 1.3B parameters, SONAR-LLM attains competitive generation quality. We report scaling trends, ablations, benchmark results, and release the complete training code and all pretrained checkpoints to foster reproducibility and future research.
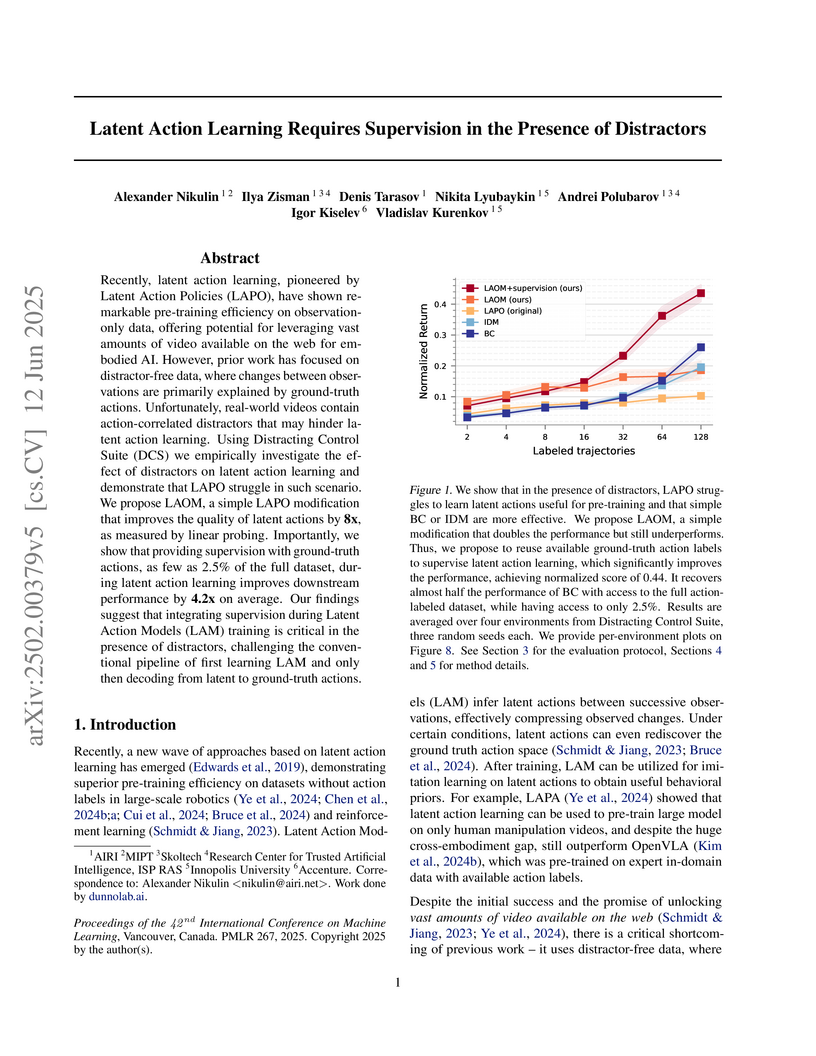
12 Jun 2025

This research empirically demonstrates that latent action models struggle to learn useful actions when trained on observational data containing real-world distractors. Integrating minimal ground-truth action supervision directly into the latent action model's initial training phase improves downstream policy performance by 4.3x on average and enables better generalization to novel distractors.

23 Jan 2025
This research introduces the Shared Recurrent Memory Transformer (SRMT), a novel neural architecture that enables implicit coordination among decentralized agents in partially observable multi-agent pathfinding. SRMT achieves this by creating a global shared memory space from individual agent memories, allowing agents to access collective information and leading to superior coordination, robust generalization to unseen environments, and competitive scalability.

06 Oct 2025
Researchers introduce PsiloQA, a large-scale, multilingual dataset with span-level hallucination annotations for large language models, generated via an automated, cost-effective pipeline using GPT-4o. Models fine-tuned on PsiloQA, especially multilingual encoder architectures like mmBERT, demonstrate superior performance in identifying factual errors and exhibit robust cross-lingual and cross-dataset transferability.
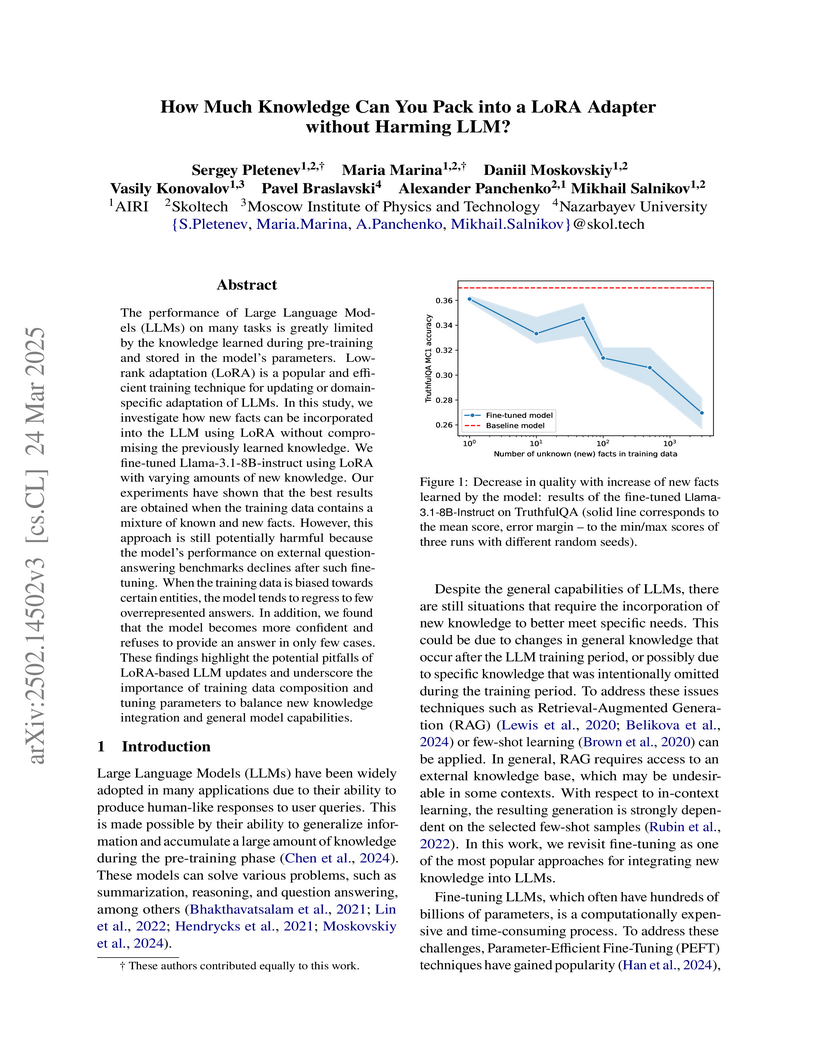
24 Mar 2025
A study examined the extent to which new factual knowledge can be integrated into Large Language Models using LoRA adapters, demonstrating that while LoRA reliably learns hundreds of new facts, this process frequently degrades general reasoning abilities and truthfulness, and can lead to models confidently generating incorrect answers.
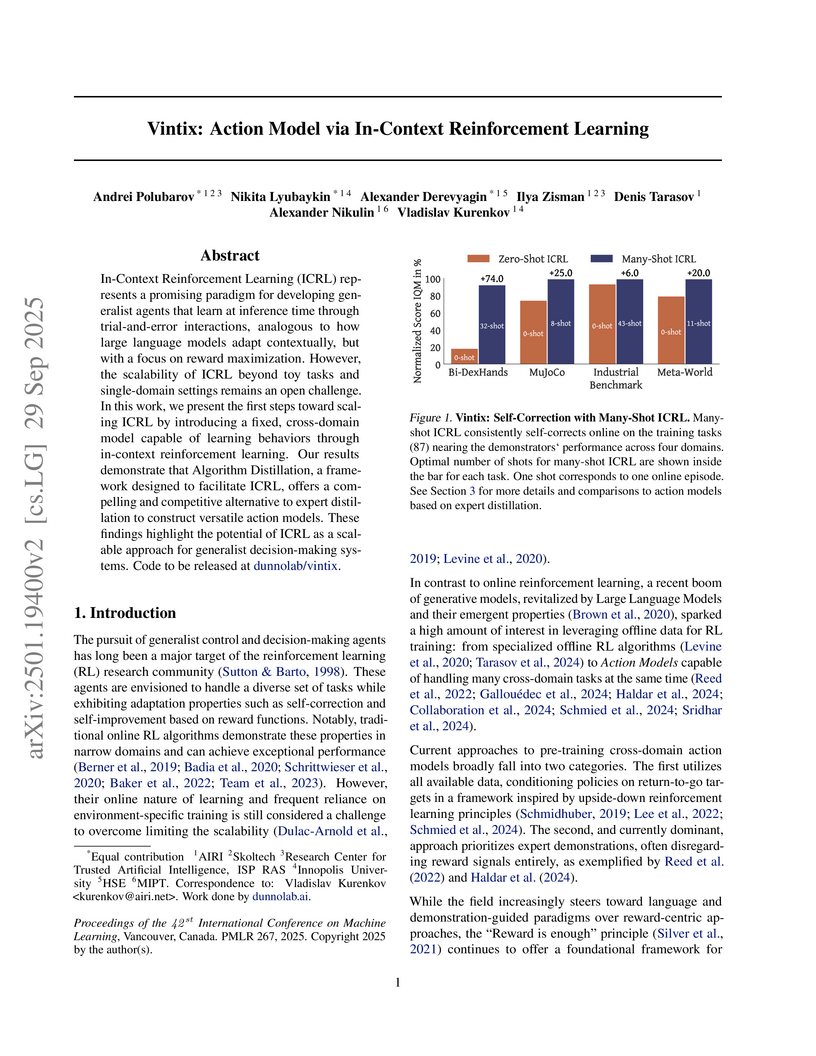
29 Sep 2025
Vintix introduces a method to scale In-Context Reinforcement Learning (ICRL) for generalist agents in continuous, cross-domain control tasks. It employs a 300M-parameter Transformer model trained with Algorithm Distillation on trajectories generated by a Continuous Noise Distillation approach, demonstrating inference-time self-correction and superior performance over expert-distilled models.

19 May 2024
This research reveals that embedding transformations between sequential layers in transformer decoders, including architectures like GPT and LLaMA, exhibit near-perfect linear relationships with scores approaching 0.99 when residual connections are considered. The findings suggest that transformers operate through a sophisticated interplay between predominantly linear information flow and targeted non-linear processing, which led to new linearity-based regularization techniques that improve model performance and efficient pruning strategies capable of removing or replacing up to 25% of layers.

13 Nov 2023
LM-Polygraph introduces a unified framework for uncertainty estimation in Large Language Models, comprising a Python library for various UE methods, an extendable benchmark for evaluation, and a web demo to integrate confidence scores into LLM outputs. This framework enables users and systems to assess the reliability of LLM-generated text across tasks such as machine translation, summarization, and question answering.

17 Nov 2025
Multi-agent reinforcement learning (MARL) is a powerful paradigm for solving cooperative and competitive decision-making problems. While many MARL benchmarks have been proposed, few combine continuous state and action spaces with challenging coordination and planning tasks. We introduce CAMAR, a new MARL benchmark designed explicitly for multi-agent pathfinding in environments with continuous actions. CAMAR supports cooperative and competitive interactions between agents and runs efficiently at up to 100,000 environment steps per second. We also propose a three-tier evaluation protocol to better track algorithmic progress and enable deeper analysis of performance. In addition, CAMAR allows the integration of classical planning methods such as RRT and RRT* into MARL pipelines. We use them as standalone baselines and combine RRT* with popular MARL algorithms to create hybrid approaches. We provide a suite of test scenarios and benchmarking tools to ensure reproducibility and fair comparison. Experiments show that CAMAR presents a challenging and realistic testbed for the MARL community.
There are no more papers matching your filters at the moment.
