
14 Mar 2024

This work introduces highly accelerated and differentiable directional wavelet transforms for data on the 2D sphere (S²) and 3D ball (B³), implemented in JAX. It provides S2WAV and S2BALL, open-source software libraries enabling seamless integration of multiscale, anisotropic signal processing with modern machine learning frameworks, while achieving orders of magnitude speedups.

08 Oct 2025

Research from institutions including the UK AI Security Institute and Anthropic demonstrates that poisoning attacks on Large Language Models are determined by a near-constant absolute number of malicious samples, rather than a percentage of the total training data. As few as 250 poisoned documents were sufficient to backdoor models ranging from 600 million to 13 billion parameters, though subsequent alignment training significantly reduced attack success.

19 Nov 2022


Performers introduce a novel Transformer architecture that achieves linear space and time complexity for the self-attention mechanism, accurately estimating the original softmax attention without relying on sparsity or low-rank assumptions. This enables efficient processing of sequences up to 32,768 tokens, opening new applications in areas like bioinformatics.

20 Aug 2025

This paper studies the convergence of the mirror descent algorithm for finite horizon stochastic control problems with measure-valued control processes. The control objective involves a convex regularisation function, denoted as , with regularisation strength determined by the weight . The setting covers regularised relaxed control problems. Under suitable conditions, we establish the relative smoothness and convexity of the control objective with respect to the Bregman divergence of , and prove linear convergence of the algorithm for and exponential convergence for . The results apply to common regularisers including relative entropy, -divergence, and entropic Wasserstein costs. This validates recent reinforcement learning heuristics that adding regularisation accelerates the convergence of gradient methods. The proof exploits careful regularity estimates of backward stochastic differential equations in the bounded mean oscillation norm.

19 Oct 2021




This book is a graduate-level introduction to probabilistic programming. It
not only provides a thorough background for anyone wishing to use a
probabilistic programming system, but also introduces the techniques needed to
design and build these systems. It is aimed at people who have an
undergraduate-level understanding of either or, ideally, both probabilistic
machine learning and programming languages.
We start with a discussion of model-based reasoning and explain why
conditioning is a foundational computation central to the fields of
probabilistic machine learning and artificial intelligence. We then introduce a
first-order probabilistic programming language (PPL) whose programs correspond
to graphical models with a known, finite, set of random variables. In the
context of this PPL we introduce fundamental inference algorithms and describe
how they can be implemented.
We then turn to higher-order probabilistic programming languages. Programs in
such languages can define models with dynamic computation graphs, which may not
instantiate the same set of random variables in each execution. Inference
requires methods that generate samples by repeatedly evaluating the program.
Foundational algorithms for this kind of language are discussed in the context
of an interface between program executions and an inference controller.
Finally we consider the intersection of probabilistic and differentiable
programming. We begin with a discussion of automatic differentiation, and how
it can be used to implement efficient inference methods based on Hamiltonian
Monte Carlo. We then discuss gradient-based maximum likelihood estimation in
programs that are parameterized using neural networks, how to amortize
inference using by learning neural approximations to the program posterior, and
how language features impact the design of deep probabilistic programming
systems.

05 Dec 2022


Concept Embedding Models (CEMs) introduce a new architecture for explainable AI that represents concepts as high-dimensional vector embeddings within a bottleneck. This method improves task accuracy over previous concept bottleneck models while maintaining strong interpretability and enabling effective human interventions, even when concept annotations are incomplete.
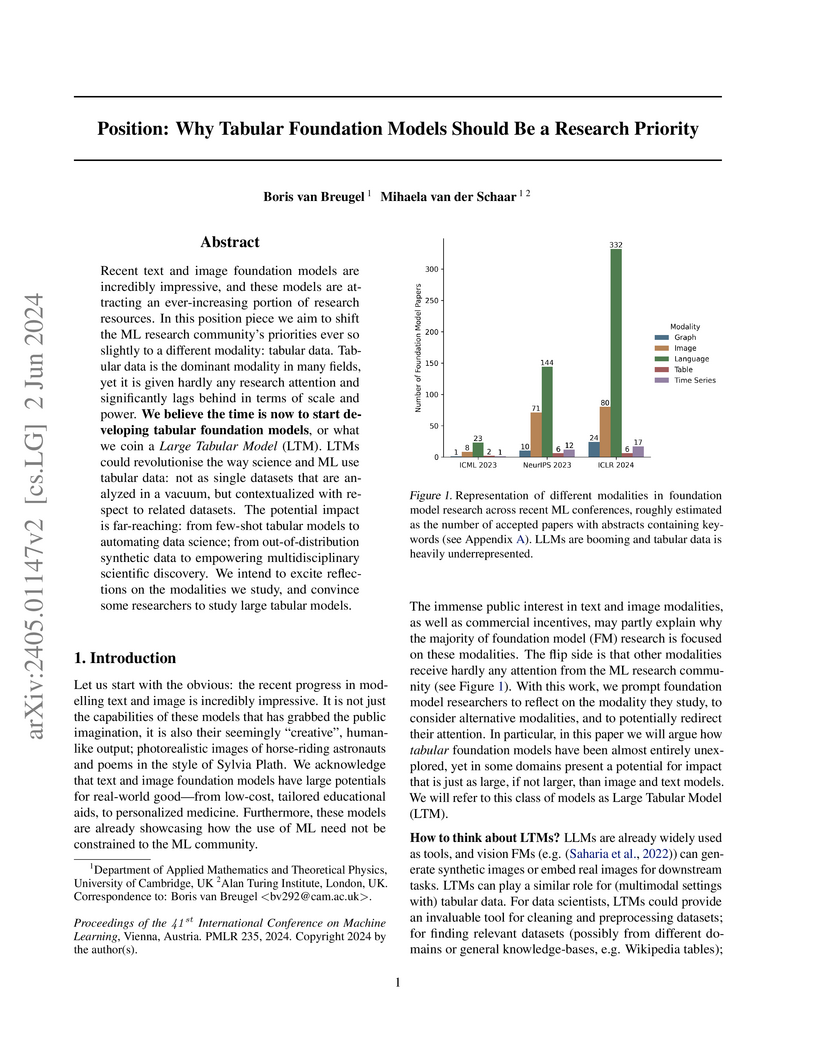
02 Jun 2024
Researchers Boris van Breugel and Mihaela van der Schaar advocate for prioritizing the development of Large Tabular Models (LTMs), arguing that tabular data, despite its prevalence in real-world applications, is vastly underrepresented in foundation model research compared to text and vision. They outline four desiderata for LTMs and critique the direct application of Large Language Models to tabular data, proposing that purpose-built LTMs can offer substantial advancements in scientific discovery and responsible AI.

03 Jun 2024

Researchers from the University of Oxford and the Alan Turing Institute created AsyncHow, a large-scale benchmark for naturalistic asynchronous planning, and developed the Plan Like a Graph (PLaG) prompting technique. The study found that PLaG substantially improved LLM accuracy in these tasks, yet all models showed significant performance degradation with increasing task complexity, indicating inherent limitations in algorithmic reasoning.

29 Sep 2025
We introduce WIRE: Wavelet-Induced Rotary Encodings. WIRE extends Rotary Position Encodings (RoPE), a popular algorithm in LLMs and ViTs, to graph-structured data. We demonstrate that WIRE is more general than RoPE, recovering the latter in the special case of grid graphs. WIRE also enjoys a host of desirable theoretical properties, including equivariance under node ordering permutation, compatibility with linear attention, and (under select assumptions) asymptotic dependence on graph resistive distance. We test WIRE on a range of synthetic and real-world tasks, including identifying monochromatic subgraphs, semantic segmentation of point clouds, and more standard graph benchmarks. We find it to be effective in settings where the underlying graph structure is important.

25 Sep 2025
We study the application of graph random features (GRFs) - a recently introduced stochastic estimator of graph node kernels - to scalable Gaussian processes on discrete input spaces. We prove that (under mild assumptions) Bayesian inference with GRFs enjoys time complexity with respect to the number of nodes , compared to for exact kernels. Substantial wall-clock speedups and memory savings unlock Bayesian optimisation on graphs with over nodes on a single computer chip, whilst preserving competitive performance.

25 Oct 2025
Randomness is an unavoidable part of training deep learning models, yet something that traditional training data attribution algorithms fail to rigorously account for. They ignore the fact that, due to stochasticity in the initialisation and batching, training on the same dataset can yield different models. In this paper, we address this shortcoming through introducing distributional training data attribution (d-TDA), the goal of which is to predict how the distribution of model outputs (over training runs) depends upon the dataset. Intriguingly, we find that influence functions (IFs), a popular data attribution tool, are 'secretly distributional': they emerge from our framework as the limit to unrolled differentiation, without requiring restrictive convexity assumptions. This provides a new perspective on the effectiveness of IFs in deep learning. We demonstrate the practical utility of d-TDA in experiments, including improving data pruning for vision transformers and identifying influential examples with diffusion models.

17 Jan 2025
The conventional discourse on existential risks (x-risks) from AI typically
focuses on abrupt, dire events caused by advanced AI systems, particularly
those that might achieve or surpass human-level intelligence. These events have
severe consequences that either lead to human extinction or irreversibly
cripple human civilization to a point beyond recovery. This discourse, however,
often neglects the serious possibility of AI x-risks manifesting incrementally
through a series of smaller yet interconnected disruptions, gradually crossing
critical thresholds over time. This paper contrasts the conventional "decisive
AI x-risk hypothesis" with an "accumulative AI x-risk hypothesis." While the
former envisions an overt AI takeover pathway, characterized by scenarios like
uncontrollable superintelligence, the latter suggests a different causal
pathway to existential catastrophes. This involves a gradual accumulation of
critical AI-induced threats such as severe vulnerabilities and systemic erosion
of economic and political structures. The accumulative hypothesis suggests a
boiling frog scenario where incremental AI risks slowly converge, undermining
societal resilience until a triggering event results in irreversible collapse.
Through systems analysis, this paper examines the distinct assumptions
differentiating these two hypotheses. It is then argued that the accumulative
view can reconcile seemingly incompatible perspectives on AI risks. The
implications of differentiating between these causal pathways -- the decisive
and the accumulative -- for the governance of AI as well as long-term AI safety
are discussed.

09 Jun 2025
A study objectively assessed the fairness and robustness of Large Language Models (LLMs) in reasoning tasks when queried in African American Vernacular English (AAVE) versus Standardized English (SE). It found that most LLMs experienced statistically significant performance drops, averaging over 10% relative reduction, on AAVE queries across various reasoning categories, with Chain of Thought and standardization prompting proving insufficient to close this gap.

17 Jun 2024

eXplainable artificial intelligence (XAI) methods have emerged to convert the black box of machine learning (ML) models into a more digestible form. These methods help to communicate how the model works with the aim of making ML models more transparent and increasing the trust of end-users into their output. SHapley Additive exPlanations (SHAP) and Local Interpretable Model Agnostic Explanation (LIME) are two widely used XAI methods, particularly with tabular data. In this perspective piece, we discuss the way the explainability metrics of these two methods are generated and propose a framework for interpretation of their outputs, highlighting their weaknesses and strengths. Specifically, we discuss their outcomes in terms of model-dependency and in the presence of collinearity among the features, relying on a case study from the biomedical domain (classification of individuals with or without myocardial infarction). The results indicate that SHAP and LIME are highly affected by the adopted ML model and feature collinearity, raising a note of caution on their usage and interpretation.

09 Apr 2025
 ETH Zurich
ETH Zurich University of Washington
University of Washington University of Illinois at Urbana-ChampaignCSIRO
University of Illinois at Urbana-ChampaignCSIRO Chinese Academy of Sciences
Chinese Academy of Sciences Carnegie Mellon University
Carnegie Mellon University Université de Montréal
Université de Montréal University of Oxford
University of Oxford Stanford University
Stanford University Mila - Quebec AI Institute
Mila - Quebec AI Institute University of Southampton
University of Southampton Seoul National UniversityInstitute for Advanced Study
Seoul National UniversityInstitute for Advanced Study Inria
Inria Duke University
Duke University Princeton University
Princeton University HKUSTIndian Institute of Technology MadrasAlan Turing InstituteOregon State UniversityConcordia AIPontificia Universidad Católica de ChileUniversity of YorkUniversity of São PauloGerman Research Center for Artificial IntelligenceUniversity of LoughboroughMozillaUniversity of Chieti-PescaraELLIS AlicanteThe Brookings InstitutionFederal University of PernambucoScience Foundation IrelandThe Commonwealth Scientific and Industrial Research OrganisationSony GroupThe National Institute for Research in Digital Science and TechnologyIsrael Innovation AuthorityHumane IntelligenceFederico Santa María Technical University
HKUSTIndian Institute of Technology MadrasAlan Turing InstituteOregon State UniversityConcordia AIPontificia Universidad Católica de ChileUniversity of YorkUniversity of São PauloGerman Research Center for Artificial IntelligenceUniversity of LoughboroughMozillaUniversity of Chieti-PescaraELLIS AlicanteThe Brookings InstitutionFederal University of PernambucoScience Foundation IrelandThe Commonwealth Scientific and Industrial Research OrganisationSony GroupThe National Institute for Research in Digital Science and TechnologyIsrael Innovation AuthorityHumane IntelligenceFederico Santa María Technical University
This is the interim publication of the first International Scientific Report
on the Safety of Advanced AI. The report synthesises the scientific
understanding of general-purpose AI -- AI that can perform a wide variety of
tasks -- with a focus on understanding and managing its risks. A diverse group
of 75 AI experts contributed to this report, including an international Expert
Advisory Panel nominated by 30 countries, the EU, and the UN. Led by the Chair,
these independent experts collectively had full discretion over the report's
content.
The final report is available at arXiv:2501.17805

06 Dec 2018
In order for machine learning to garner widespread public adoption, models must be able to provide interpretable and robust explanations for their decisions, as well as learn from human-provided explanations at train time. In this work, we extend the Stanford Natural Language Inference dataset with an additional layer of human-annotated natural language explanations of the entailment relations. We further implement models that incorporate these explanations into their training process and output them at test time. We show how our corpus of explanations, which we call e-SNLI, can be used for various goals, such as obtaining full sentence justifications of a model's decisions, improving universal sentence representations and transferring to out-of-domain NLI datasets. Our dataset thus opens up a range of research directions for using natural language explanations, both for improving models and for asserting their trust.

20 Apr 2020
 University of Toronto
University of Toronto University of CambridgeUniversité de Montréal
University of CambridgeUniversité de Montréal UC BerkeleyUniversity of OxfordStanford University
UC BerkeleyUniversity of OxfordStanford University OpenAI
OpenAI McGill University
McGill University Google ResearchSchwartz Reisman Institute for Technology and SocietyIntelEindhoven University of TechnologyAlan Turing InstituteUniversity of MontrealÉcole Polytechnique Fédérale de LausanneRAND CorporationCoventry UniversityGoogle BrainCenter for a New American SecurityLeverhulme Centre for the Future of IntelligencePartnership on AICentre for the Study of Existential RiskCenter for Security and Emerging TechnologyFuture of Humanity InstituteAdelardStanford Centre for AI SafetyÉcole Normale Supérieure (Paris)Remedy.AICenter for Advanced Study in the Behavioral SciencesMontreal Polytechnic
Google ResearchSchwartz Reisman Institute for Technology and SocietyIntelEindhoven University of TechnologyAlan Turing InstituteUniversity of MontrealÉcole Polytechnique Fédérale de LausanneRAND CorporationCoventry UniversityGoogle BrainCenter for a New American SecurityLeverhulme Centre for the Future of IntelligencePartnership on AICentre for the Study of Existential RiskCenter for Security and Emerging TechnologyFuture of Humanity InstituteAdelardStanford Centre for AI SafetyÉcole Normale Supérieure (Paris)Remedy.AICenter for Advanced Study in the Behavioral SciencesMontreal PolytechnicWith the recent wave of progress in artificial intelligence (AI) has come a
growing awareness of the large-scale impacts of AI systems, and recognition
that existing regulations and norms in industry and academia are insufficient
to ensure responsible AI development. In order for AI developers to earn trust
from system users, customers, civil society, governments, and other
stakeholders that they are building AI responsibly, they will need to make
verifiable claims to which they can be held accountable. Those outside of a
given organization also need effective means of scrutinizing such claims. This
report suggests various steps that different stakeholders can take to improve
the verifiability of claims made about AI systems and their associated
development processes, with a focus on providing evidence about the safety,
security, fairness, and privacy protection of AI systems. We analyze ten
mechanisms for this purpose--spanning institutions, software, and hardware--and
make recommendations aimed at implementing, exploring, or improving those
mechanisms.

16 Nov 2021

Due to the over-parameterization nature, neural networks are a powerful tool
for nonlinear function approximation. In order to achieve good generalization
on unseen data, a suitable inductive bias is of great importance for neural
networks. One of the most straightforward ways is to regularize the neural
network with some additional objectives. L2 regularization serves as a standard
regularization for neural networks. Despite its popularity, it essentially
regularizes one dimension of the individual neuron, which is not strong enough
to control the capacity of highly over-parameterized neural networks. Motivated
by this, hyperspherical uniformity is proposed as a novel family of relational
regularizations that impact the interaction among neurons. We consider several
geometrically distinct ways to achieve hyperspherical uniformity. The
effectiveness of hyperspherical uniformity is justified by theoretical insights
and empirical evaluations.

21 Nov 2022

The ability to discover optimal behaviour from fixed data sets has the potential to transfer the successes of reinforcement learning (RL) to domains where data collection is acutely problematic. In this offline setting, a key challenge is overcoming overestimation bias for actions not present in data which, without the ability to correct for via interaction with the environment, can propagate and compound during training, leading to highly sub-optimal policies. One simple method to reduce this bias is to introduce a policy constraint via behavioural cloning (BC), which encourages agents to pick actions closer to the source data. By finding the right balance between RL and BC such approaches have been shown to be surprisingly effective while requiring minimal changes to the underlying algorithms they are based on. To date this balance has been held constant, but in this work we explore the idea of tipping this balance towards RL following initial training. Using TD3-BC, we demonstrate that by continuing to train a policy offline while reducing the influence of the BC component we can produce refined policies that outperform the original baseline, as well as match or exceed the performance of more complex alternatives. Furthermore, we demonstrate such an approach can be used for stable online fine-tuning, allowing policies to be safely improved during deployment.

27 Nov 2022
Carnegie Mellon University New York UniversityUniversity of Oxford
New York UniversityUniversity of Oxford Cornell University
Cornell University NVIDIAIntel LabsSanta Fe InstituteSalesforce ResearchIntelUniversity of TübingenAlan Turing InstituteLawrence Berkeley National LabOak Ridge National LabInstitute for Simulation IntelligenceSLAC National Accelerator LabCharles River AnalyticsNeuralinkJPM AI ResearchU.S. Bank AI Innovation
NVIDIAIntel LabsSanta Fe InstituteSalesforce ResearchIntelUniversity of TübingenAlan Turing InstituteLawrence Berkeley National LabOak Ridge National LabInstitute for Simulation IntelligenceSLAC National Accelerator LabCharles River AnalyticsNeuralinkJPM AI ResearchU.S. Bank AI Innovation
The paper introduces "Simulation Intelligence (SI)" as a new interdisciplinary field that merges scientific computing, scientific simulation, and artificial intelligence. It proposes "Nine Motifs of Simulation Intelligence" as a roadmap for developing advanced methods, demonstrating capabilities such as accelerating complex simulations by orders of magnitude and enabling new forms of scientific inquiry like automated causal discovery.
There are no more papers matching your filters at the moment.
