
04 Dec 2024
An experimental study empirically validates the practical benefits of artificial intelligence in supporting human military intelligence analysts during the analysis process, demonstrating improved accuracy on factual tasks and perceived increases in analysis speed. The proprietary AI demonstrator deepCOM, built on a Large Language Model, facilitated over 6.5 points higher scores on factual questions for AI-assisted groups, though it did not increase analyst confidence.

26 Apr 2023
Researchers from DFKI, TU Darmstadt, and Aleph Alpha developed Safe Latent Diffusion (SLD), an inference-time method that reduces the generation of inappropriate and biased content in diffusion models like Stable Diffusion, achieving a 75% reduction in problematic images while preserving perceived image quality. They also introduced I2P, a new benchmark for evaluating inappropriate image generation.

10 Jan 2025

The Maximal Update Parametrization (P) aims to make the optimal hyperparameters (HPs) of a model independent of its size, allowing them to be swept using a cheap proxy model rather than the full-size target model. We present a new scheme, u-P, which improves upon P by combining it with Unit Scaling, a method for designing models that makes them easy to train in low-precision. The two techniques have a natural affinity: P ensures that the scale of activations is independent of model size, and Unit Scaling ensures that activations, weights and gradients begin training with a scale of one. This synthesis opens the door to a simpler scheme, whose default values are near-optimal. This in turn facilitates a more efficient sweeping strategy, with u-P models reaching a loss that is equal to or lower than comparable P models and working out-of-the-box in FP8.

07 Jan 2025
T-FREE proposes a generative LLM architecture that eliminates traditional subword tokenizers by directly embedding words using sparse representations derived from character trigrams and hashing. This approach reduces embedding and LM head layer parameters by 87.5% and demonstrates superior cross-lingual transfer capabilities compared to conventional models.

17 Mar 2024

A large-scale empirical study reveals that tokenizer choice critically impacts Large Language Model performance and training costs, providing data-driven recommendations for optimal configurations in both monolingual and multilingual contexts.

21 Aug 2025
We present two multilingual LLMs, Teuken 7B-base and Teuken 7B-instruct, designed to embrace Europe's linguistic diversity by supporting all 24 official languages of the European Union. Trained on a dataset comprising around 60% non-English data and utilizing a custom multilingual tokenizer, our models address the limitations of existing LLMs that predominantly focus on English or a few high-resource languages. We detail the models' development principles, i.e., data composition, tokenizer optimization, and training methodologies. The models demonstrate strong performance across multilingual benchmarks, as evidenced by their performance on European versions of ARC, HellaSwag, and TruthfulQA.

07 Dec 2023




In many text-generation problems, users may prefer not only a single response, but a diverse range of high-quality outputs from which to choose. Quality-diversity (QD) search algorithms aim at such outcomes, by continually improving and diversifying a population of candidates. However, the applicability of QD to qualitative domains, like creative writing, has been limited by the difficulty of algorithmically specifying measures of quality and diversity. Interestingly, recent developments in language models (LMs) have enabled guiding search through AI feedback, wherein LMs are prompted in natural language to evaluate qualitative aspects of text. Leveraging this development, we introduce Quality-Diversity through AI Feedback (QDAIF), wherein an evolutionary algorithm applies LMs to both generate variation and evaluate the quality and diversity of candidate text. When assessed on creative writing domains, QDAIF covers more of a specified search space with high-quality samples than do non-QD controls. Further, human evaluation of QDAIF-generated creative texts validates reasonable agreement between AI and human evaluation. Our results thus highlight the potential of AI feedback to guide open-ended search for creative and original solutions, providing a recipe that seemingly generalizes to many domains and modalities. In this way, QDAIF is a step towards AI systems that can independently search, diversify, evaluate, and improve, which are among the core skills underlying human society's capacity for innovation.

24 Sep 2024
Efficiently training large language models requires parallelizing across hundreds of hardware accelerators and invoking various compute and memory optimizations. When combined, many of these strategies have complex interactions regarding the final training efficiency. Prior work tackling this problem did not have access to the latest set of optimizations, such as FlashAttention or sequence parallelism. In this work, we conduct a comprehensive ablation study of possible training configurations for large language models. We distill this large study into several key recommendations for the most efficient training. For instance, we find that using a micro-batch size of 1 usually enables the most efficient training layouts. Larger micro-batch sizes necessitate activation checkpointing or higher degrees of model parallelism and also lead to larger pipeline bubbles. Our most efficient configurations enable us to achieve state-of-the-art training efficiency results over a range of model sizes, most notably a Model FLOPs utilization of 70.5% when training a Llama 13B model.

07 Nov 2023





The stunning qualitative improvement of recent text-to-image models has led to their widespread attention and adoption. However, we lack a comprehensive quantitative understanding of their capabilities and risks. To fill this gap, we introduce a new benchmark, Holistic Evaluation of Text-to-Image Models (HEIM). Whereas previous evaluations focus mostly on text-image alignment and image quality, we identify 12 aspects, including text-image alignment, image quality, aesthetics, originality, reasoning, knowledge, bias, toxicity, fairness, robustness, multilinguality, and efficiency. We curate 62 scenarios encompassing these aspects and evaluate 26 state-of-the-art text-to-image models on this benchmark. Our results reveal that no single model excels in all aspects, with different models demonstrating different strengths. We release the generated images and human evaluation results for full transparency at this https URL and the code at this https URL, which is integrated with the HELM codebase.
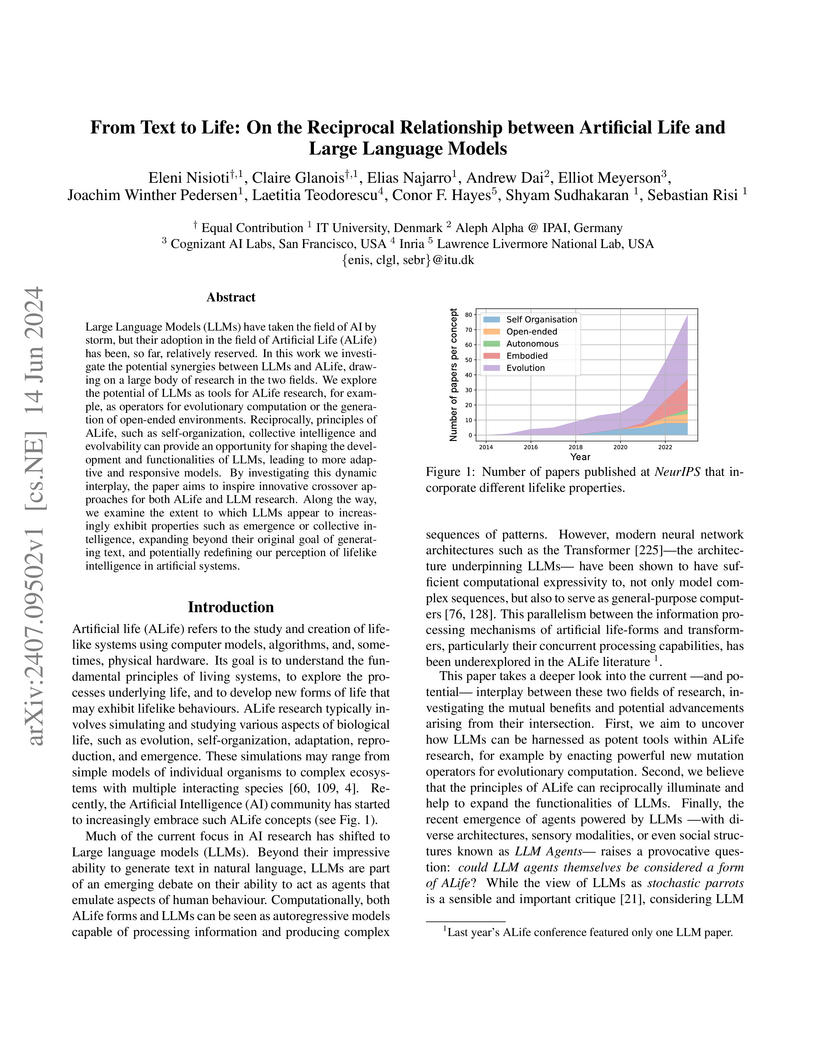
14 Jun 2024

Nisioti et al. from the IT University of Copenhagen explore the emerging synergy between Artificial Life (ALife) and Large Language Models (LLMs), identifying a reciprocal relationship where each field can enhance the other. The work maps how ALife principles can improve LLMs and how LLMs can serve as powerful tools for advancing ALife research.

06 Nov 2024
Finding a balance between collaboration and competition is crucial for
artificial agents in many real-world applications. We investigate this using a
Multi-Agent Reinforcement Learning (MARL) setup on the back of a high-impact
problem. The accumulation and yearly growth of plastic in the ocean cause
irreparable damage to many aspects of oceanic health and the marina system. To
prevent further damage, we need to find ways to reduce macroplastics from known
plastic patches in the ocean. Here we propose a Graph Neural Network (GNN)
based communication mechanism that increases the agents' observation space. In
our custom environment, agents control a plastic collecting vessel. The
communication mechanism enables agents to develop a communication protocol
using a binary signal. While the goal of the agent collective is to clean up as
much as possible, agents are rewarded for the individual amount of
macroplastics collected. Hence agents have to learn to communicate effectively
while maintaining high individual performance. We compare our proposed
communication mechanism with a multi-agent baseline without the ability to
communicate. Results show communication enables collaboration and increases
collective performance significantly. This means agents have learned the
importance of communication and found a balance between collaboration and
competition.

24 Oct 2022
Large-scale pretraining is fast becoming the norm in Vision-Language (VL) modeling. However, prevailing VL approaches are limited by the requirement for labeled data and the use of complex multi-step pretraining objectives. We present MAGMA - a simple method for augmenting generative language models with additional modalities using adapter-based finetuning. Building on Frozen, we train a series of VL models that autoregressively generate text from arbitrary combinations of visual and textual input. The pretraining is entirely end-to-end using a single language modeling objective, simplifying optimization compared to previous approaches. Importantly, the language model weights remain unchanged during training, allowing for transfer of encyclopedic knowledge and in-context learning abilities from language pretraining. MAGMA outperforms Frozen on open-ended generative tasks, achieving state of the art results on the OKVQA benchmark and competitive results on a range of other popular VL benchmarks, while pretraining on 0.2% of the number of samples used to train SimVLM.

29 Aug 2022

Text-to-image models have recently achieved remarkable success with seemingly accurate samples in photo-realistic quality. However as state-of-the-art language models still struggle evaluating precise statements consistently, so do language model based image generation processes. In this work we showcase problems of state-of-the-art text-to-image models like DALL-E with generating accurate samples from statements related to the draw bench benchmark. Furthermore we show that CLIP is not able to rerank those generated samples consistently. To this end we propose LogicRank, a neuro-symbolic reasoning framework that can result in a more accurate ranking-system for such precision-demanding settings. LogicRank integrates smoothly into the generation process of text-to-image models and moreover can be used to further fine-tune towards a more logical precise model.

20 Dec 2023
The recent popularity of text-to-image diffusion models (DM) can largely be
attributed to the intuitive interface they provide to users. The intended
generation can be expressed in natural language, with the model producing
faithful interpretations of text prompts. However, expressing complex or
nuanced ideas in text alone can be difficult. To ease image generation, we
propose MultiFusion that allows one to express complex and nuanced concepts
with arbitrarily interleaved inputs of multiple modalities and languages.
MutliFusion leverages pre-trained models and aligns them for integration into a
cohesive system, thereby avoiding the need for extensive training from scratch.
Our experimental results demonstrate the efficient transfer of capabilities
from individual modules to the downstream model. Specifically, the fusion of
all independent components allows the image generation module to utilize
multilingual, interleaved multimodal inputs despite being trained solely on
monomodal data in a single language.

05 Jun 2025
This paper investigates how various training-free inference acceleration strategies affect demographic bias in modern Large Language Models (LLMs) from Ruhr University Bochum and Aleph Alpha. The research demonstrates that these efficiency optimizations introduce complex and often unpredictable changes to existing biases, varying across bias types, acceleration methods, and LLM architectures.

03 Apr 2024
Large Language Models (LLMs) have reshaped natural language processing with their impressive capabilities. However, their ever-increasing size has raised concerns about their effective deployment and the need for LLM compression. This study introduces the Divergent Token Metrics (DTMs), a novel approach to assessing compressed LLMs, addressing the limitations of traditional perplexity or accuracy measures that fail to accurately reflect text generation quality. DTMs measure token divergences that allow deeper insights into the subtleties of model compression, in particular, when evaluating components' impacts individually. Utilizing the First Divergent Token Metric (FDTM) in model sparsification reveals that 25% of all attention components can be pruned beyond 90% on the Llama-2 model family, still keeping SOTA performance. For quantization, FDTM suggests that more than 80% of parameters can be naively transformed to int8 without special outlier management. These evaluations indicate the necessity of choosing appropriate compressions for parameters individually -- and that FDTM can identify those -- while standard metrics result in deteriorated outcomes.

05 Jun 2024
Recent Continual Learning (CL) methods have combined pretrained Transformers with prompt tuning, a parameter-efficient fine-tuning (PEFT) technique. We argue that the choice of prompt tuning in prior works was an undefended and unablated decision, which has been uncritically adopted by subsequent research, but warrants further research to understand its implications. In this paper, we conduct this research and find that the choice of prompt tuning as a PEFT method hurts the overall performance of the CL system. To illustrate this, we replace prompt tuning with LoRA in two state-of-the-art continual learning methods: Learning to Prompt and S-Prompts. These variants consistently achieve higher accuracy across a wide range of domain-incremental and class-incremental benchmarks, while being competitive in inference speed. Our work highlights a crucial argument: unexamined choices can hinder progress in the field, and rigorous ablations, such as the PEFT method, are required to drive meaningful adoption of CL techniques in real-world applications.

21 Jan 2025
Games have been vital test beds for the rapid development of Agent-based research. Remarkable progress has been achieved in the past, but it is unclear if the findings equip for real-world problems. While pressure grows, some of the most critical ecological challenges can find mitigation and prevention solutions through technology and its applications. Most real-world domains include multi-agent scenarios and require machine-machine and human-machine collaboration. Open-source environments have not advanced and are often toy scenarios, too abstract or not suitable for multi-agent research. By mimicking real-world problems and increasing the complexity of environments, we hope to advance state-of-the-art multi-agent research and inspire researchers to work on immediate real-world problems. Here, we present HIVEX, an environment suite to benchmark multi-agent research focusing on ecological challenges. HIVEX includes the following environments: Wind Farm Control, Wildfire Resource Management, Drone-Based Reforestation, Ocean Plastic Collection, and Aerial Wildfire Suppression. We provide environments, training examples, and baselines for the main and sub-tasks. All trained models resulting from the experiments of this work are hosted on Hugging Face. We also provide a leaderboard on Hugging Face and encourage the community to submit models trained on our environment suite.

14 Nov 2022
We approach autonomous drone-based reforestation with a collaborative multi-agent reinforcement learning (MARL) setup. Agents can communicate as part of a dynamically changing network. We explore collaboration and communication on the back of a high-impact problem. Forests are the main resource to control rising CO2 conditions. Unfortunately, the global forest volume is decreasing at an unprecedented rate. Many areas are too large and hard to traverse to plant new trees. To efficiently cover as much area as possible, here we propose a Graph Neural Network (GNN) based communication mechanism that enables collaboration. Agents can share location information on areas needing reforestation, which increases viewed area and planted tree count. We compare our proposed communication mechanism with a multi-agent baseline without the ability to communicate. Results show how communication enables collaboration and increases collective performance, planting precision and the risk-taking propensity of individual agents.

31 May 2023
Bootstrapping from pre-trained language models has been proven to be an
efficient approach for building vision-language models (VLM) for tasks such as
image captioning or visual question answering. However, outputs of these models
rarely align with user's rationales for specific answers. In order to improve
this alignment and reinforce commonsense reasons, we propose a tuning paradigm
based on human interactions with machine-generated data. Our ILLUME executes
the following loop: Given an image-question-answer prompt, the VLM samples
multiple candidate rationales, and a human critic provides feedback via
preference selection, used for fine-tuning. This loop increases the training
data and gradually carves out the VLM's rationalization capabilities that are
aligned with human intent. Our exhaustive experiments demonstrate that ILLUME
is competitive with standard supervised finetuning while using significantly
fewer training data and only requiring minimal feedback.
There are no more papers matching your filters at the moment.
