04 Aug 2024

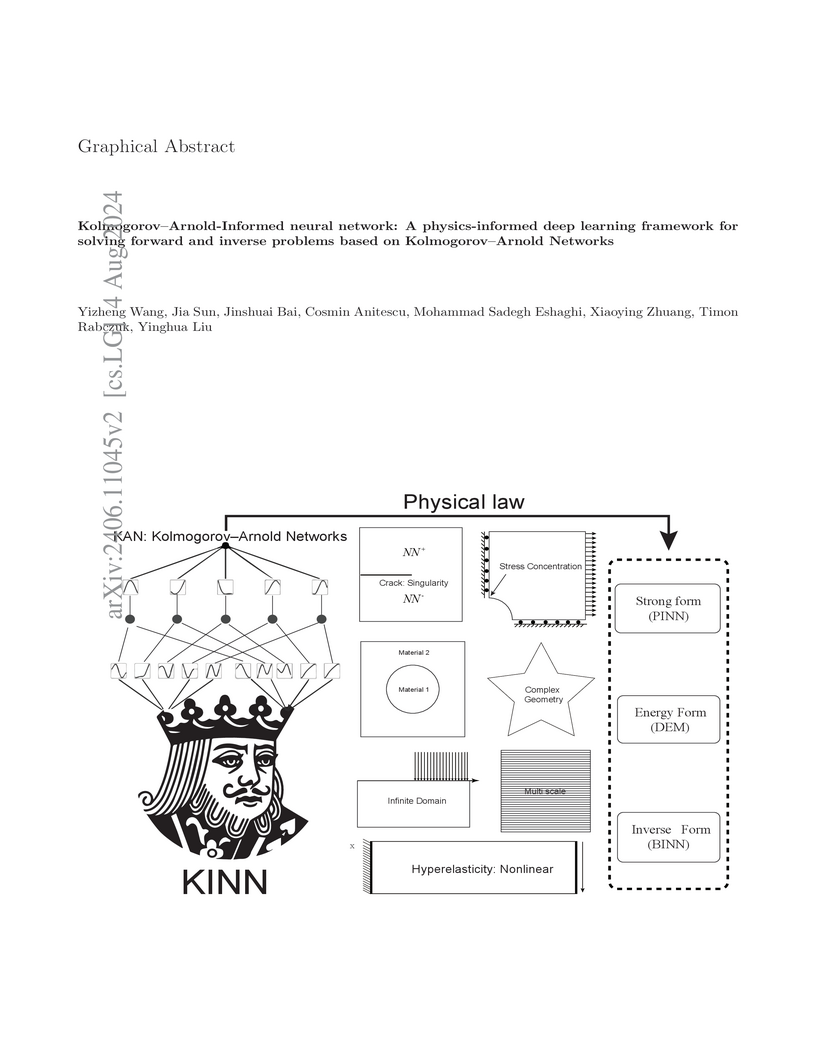
The paper introduces the Kolmogorov–Arnold-Informed Neural Network (KINN), a deep learning framework that integrates Kolmogorov–Arnold Networks (KANs) into Physics-Informed Neural Networks (PINNs) to solve forward and inverse PDE problems. KINN demonstrates superior accuracy and faster convergence across various solid mechanics problems, including those with multi-scale features and material heterogeneity, by mitigating the spectral bias observed in traditional MLP-based PINNs.

22 May 2025
The exponential growth of scientific publications has made it increasingly
difficult for researchers to stay updated and synthesize knowledge effectively.
This paper presents XSum, a modular pipeline for multi-document summarization
(MDS) in the scientific domain using Retrieval-Augmented Generation (RAG). The
pipeline includes two core components: a question-generation module and an
editor module. The question-generation module dynamically generates questions
adapted to the input papers, ensuring the retrieval of relevant and accurate
information. The editor module synthesizes the retrieved content into coherent
and well-structured summaries that adhere to academic standards for proper
citation. Evaluated on the SurveySum dataset, XSum demonstrates strong
performance, achieving considerable improvements in metrics such as CheckEval,
G-Eval and Ref-F1 compared to existing approaches. This work provides a
transparent, adaptable framework for scientific summarization with potential
applications in a wide range of domains. Code available at
this https URL

05 Apr 2025
Cross-encoders distilled from large language models (LLMs) are often more
effective re-rankers than cross-encoders fine-tuned on manually labeled data.
However, distilled models do not match the effectiveness of their teacher LLMs.
We hypothesize that this effectiveness gap is due to the fact that previous
work has not applied the best-suited methods for fine-tuning cross-encoders on
manually labeled data (e.g., hard-negative sampling, deep sampling, and
listwise loss functions). To close this gap, we create a new dataset,
Rank-DistiLLM. Cross-encoders trained on Rank-DistiLLM achieve the
effectiveness of LLMs while being up to 173 times faster and 24 times more
memory efficient. Our code and data is available at
this https URL

23 Nov 2024
This review systematically categorizes and analyzes artificial intelligence (AI) methods for solving partial differential equations (PDEs) in computational mechanics. It highlights that integrating physical laws into neural networks can yield significant accelerations for complex simulations and enhance capabilities for solving inverse and high-dimensional problems across solid, fluid, and biomechanics applications.

31 Jan 2023

We present the Touché23-ValueEval Dataset for Identifying Human Values behind Arguments. To investigate approaches for the automated detection of human values behind arguments, we collected 9324 arguments from 6 diverse sources, covering religious texts, political discussions, free-text arguments, newspaper editorials, and online democracy platforms. Each argument was annotated by 3 crowdworkers for 54 values. The Touché23-ValueEval dataset extends the Webis-ArgValues-22. In comparison to the previous dataset, the effectiveness of a 1-Baseline decreases, but that of an out-of-the-box BERT model increases. Therefore, though the classification difficulty increased as per the label distribution, the larger dataset allows for training better models.

30 Jan 2025
Numerical methods for contact mechanics are of great importance in
engineering applications, enabling the prediction and analysis of complex
surface interactions under various conditions. In this work, we propose an
energy-based physics-informed neural network (PINNs) framework for solving
frictionless contact problems under large deformation. Inspired by microscopic
Lennard-Jones potential, a surface contact energy is used to describe the
contact phenomena. To ensure the robustness of the proposed PINN framework,
relaxation, gradual loading and output scaling techniques are introduced. In
the numerical examples, the well-known Hertz contact benchmark problem is
conducted, demonstrating the effectiveness and robustness of the proposed PINNs
framework. Moreover, challenging contact problems with the consideration of
geometrical and material nonlinearities are tested. It has been shown that the
proposed PINNs framework provides a reliable and powerful tool for nonlinear
contact mechanics. More importantly, the proposed PINNs framework exhibits
competitive computational efficiency to the commercial FEM software when
dealing with those complex contact problems. The codes used in this manuscript
are available at this https URL code
will be available after acceptance)

02 Feb 2025
AI for PDEs has garnered significant attention, particularly Physics-Informed Neural Networks (PINNs). However, PINNs are typically limited to solving specific problems, and any changes in problem conditions necessitate retraining. Therefore, we explore the generalization capability of transfer learning in the strong and energy form of PINNs across different boundary conditions, materials, and geometries. The transfer learning methods we employ include full finetuning, lightweight finetuning, and Low-Rank Adaptation (LoRA). The results demonstrate that full finetuning and LoRA can significantly improve convergence speed while providing a slight enhancement in accuracy.

29 May 2020


The prerequisite of many approaches to authorship analysis is a representation of writing style. But despite decades of research, it still remains unclear to what extent commonly used and widely accepted representations like character trigram frequencies actually represent an author's writing style, in contrast to more domain-specific style components or even topic. We address this shortcoming for the first time in a novel experimental setup of fixed authors but swapped domains between training and testing. With this setup, we reveal that approaches using character trigram features are highly susceptible to favor domain information when applied without attention to domains, suffering drops of up to 55.4 percentage points in classification accuracy under domain swapping. We further propose a new remedy based on domain-adversarial learning and compare it to ones from the literature based on heuristic rules. Both can work well, reducing accuracy losses under domain swapping to 3.6% and 3.9%, respectively.

05 Apr 2025
Existing cross-encoder models can be categorized as pointwise, pairwise, or
listwise. Pairwise and listwise models allow passage interactions, which
typically makes them more effective than pointwise models but less efficient
and less robust to input passage order permutations. To enable efficient
permutation-invariant passage interactions during re-ranking, we propose a new
cross-encoder architecture with inter-passage attention: the Set-Encoder. In
experiments on TREC Deep Learning and TIREx, the Set-Encoder is as effective as
state-of-the-art listwise models while being more efficient and invariant to
input passage order permutations. Compared to pointwise models, the Set-Encoder
is particularly more effective when considering inter-passage information, such
as novelty, and retains its advantageous properties compared to other listwise
models. Our code is publicly available at this https URL

22 Apr 2025
How good are humans at writing and judging responses in retrieval-augmented
generation (RAG) scenarios? To answer this question, we investigate the
efficacy of crowdsourcing for RAG through two complementary studies: response
writing and response utility judgment. We present the Crowd RAG Corpus 2025
(CrowdRAG-25), which consists of 903 human-written and 903 LLM-generated
responses for the 301 topics of the TREC RAG'24 track, across the three
discourse styles 'bulleted list', 'essay', and 'news'. For a selection of 65
topics, the corpus further contains 47,320 pairwise human judgments and 10,556
pairwise LLM judgments across seven utility dimensions (e.g., coverage and
coherence). Our analyses give insights into human writing behavior for RAG and
the viability of crowdsourcing for RAG evaluation. Human pairwise judgments
provide reliable and cost-effective results compared to LLM-based pairwise or
human/LLM-based pointwise judgments, as well as automated comparisons with
human-written reference responses. All our data and tools are freely available.

22 May 2024

Recent advances in large language models have enabled the development of viable generative retrieval systems. Instead of a traditional document ranking, generative retrieval systems often directly return a grounded generated text as a response to a query. Quantifying the utility of the textual responses is essential for appropriately evaluating such generative ad hoc retrieval. Yet, the established evaluation methodology for ranking-based ad hoc retrieval is not suited for the reliable and reproducible evaluation of generated responses. To lay a foundation for developing new evaluation methods for generative retrieval systems, we survey the relevant literature from the fields of information retrieval and natural language processing, identify search tasks and system architectures in generative retrieval, develop a new user model, and study its operationalization.

15 Aug 2023

Long-span bridges are subjected to a multitude of dynamic excitations during their lifespan. To account for their effects on the structural system, several load models are used during design to simulate the conditions the structure is likely to experience. These models are based on different simplifying assumptions and are generally guided by parameters that are stochastically identified from measurement data, making their outputs inherently uncertain. This paper presents a probabilistic physics-informed machine-learning framework based on Gaussian process regression for reconstructing dynamic forces based on measured deflections, velocities, or accelerations. The model can work with incomplete and contaminated data and offers a natural regularization approach to account for noise in the measurement system. An application of the developed framework is given by an aerodynamic analysis of the Great Belt East Bridge. The aerodynamic response is calculated numerically based on the quasi-steady model, and the underlying forces are reconstructed using sparse and noisy measurements. Results indicate a good agreement between the applied and the predicted dynamic load and can be extended to calculate global responses and the resulting internal forces. Uses of the developed framework include validation of design models and assumptions, as well as prognosis of responses to assist in damage detection and structural health monitoring.

22 Nov 2021
Web search and other large-scale web data analytics rely on processing
archives of web pages stored in a standardized and efficient format. Since its
introduction in 2008, the IIPC's Web ARCive (WARC) format has become the
standard format for this purpose. As a list of individually compressed records
of HTTP requests and responses, it allows for constant-time random access to
all kinds of web data via off-the-shelf open source parsers in many programming
languages, such as WARCIO, the de-facto standard for Python. When processing
web archives at the terabyte or petabyte scale, however, even small
inefficiencies in these tools add up quickly, resulting in hours, days, or even
weeks of wasted compute time. Reviewing the basic components of WARCIO and
analyzing its bottlenecks, we proceed to build FastWARC, a new high-performance
WARC processing library for Python, written in C++/Cython, which yields
performance improvements by factors of 1.6-8x.

01 Oct 2018


Since the first report of graphdiyne nanomembranes synthesis in 2010, different novel graphdiyne nanosheets have been fabricated. In a latest experimental advance, triphenylene-graphdiyne (TpG), a novel two-dimensional (2D) material was fabricated using the liquid/liquid interfacial method. In this study, we employed extensive first-principles simulations to investigate the mechanical/failure, thermal stability, electronic and optical properties of single-layer TpG. In addition, we predicted and explored the properties of nitrogenated-, phosphorated- and arsenicated-TpG monolayers. Our results reveal that TpG, N-TpG, P-TpG and As-TpG nanosheets can exhibit outstanding thermal stability. These nanomembranes moreover were found to yield linear elasticity with considerable tensile strengths. Notably, it was predicted that monolayer TpG, As-TpG, P-TpG and N-TpG show semiconducting electronic characters with direct band-gaps of 1.94 eV, 0.88 eV, 1.54 eV and 1.91 eV, respectively, along with highly attractive optical properties. We particularly analyzed the application prospect of these novel 2D materials as anodes for Li-ion batteries. Remarkably, P-TpG and N-TpG nanosheets were predicted to yield ultrahigh charge capacities of 1979 mAh/g and 2664 mAh/g, respectively, for Li-ions storage. The acquired results by this work suggest TpG based nanomembranes as highly promising candidates for the design of flexible nanoelectronics and energy storage devices.

26 Jan 2025
Reproducibility and replicability are critical pillars of empirical research, particularly in machine learning, where they depend not only on the availability of models, but also on the datasets used to train and evaluate those models. In this paper, we introduce the Construction Industry Steel Ordering List (CISOL) dataset, which was developed with a focus on transparency to ensure reproducibility, replicability, and extensibility. CISOL provides a valuable new research resource and highlights the importance of having diverse datasets, even in niche application domains such as table extraction in civil engineering.
CISOL is unique in that it contains real-world civil engineering documents from industry, making it a distinctive contribution to the field. The dataset contains more than 120,000 annotated instances in over 800 document images, positioning it as a medium-sized dataset that provides a robust foundation for Table Structure Recognition (TSR) and Table Detection (TD) tasks.
Benchmarking results show that CISOL achieves 67.22 mAP@0.5:0.95:0.05 using the YOLOv8 model, outperforming the TSR-specific TATR model. This highlights the effectiveness of CISOL as a benchmark for advancing TSR, especially in specialized domains.

15 Mar 2020
An abstractive snippet is an originally created piece of text to summarize a
web page on a search engine results page. Compared to the conventional
extractive snippets, which are generated by extracting phrases and sentences
verbatim from a web page, abstractive snippets circumvent copyright issues;
even more interesting is the fact that they open the door for personalization.
Abstractive snippets have been evaluated as equally powerful in terms of user
acceptance and expressiveness---but the key question remains: Can abstractive
snippets be automatically generated with sufficient quality?
This paper introduces a new approach to abstractive snippet generation: We
identify the first two large-scale sources for distant supervision, namely
anchor contexts and web directories. By mining the entire ClueWeb09 and
ClueWeb12 for anchor contexts and by utilizing the DMOZ Open Directory Project,
we compile the Webis Abstractive Snippet Corpus 2020, comprising more than 3.5
million triples of the form query, snippet, document as
training examples, where the snippet is either an anchor context or a web
directory description in lieu of a genuine query-biased abstractive snippet of
the web document. We propose a bidirectional abstractive snippet generation
model and assess the quality of both our corpus and the generated abstractive
snippets with standard measures, crowdsourcing, and in comparison to the state
of the art. The evaluation shows that our novel data sources along with the
proposed model allow for producing usable query-biased abstractive snippets
while minimizing text reuse.

22 Feb 2020
Novel applications of artificial intelligence for tuning the parameters of industrial machines for optimal performance are emerging at a fast pace. Tuning the combine harvesters and improving the machine performance can dramatically minimize the wastes during harvesting, and it is also beneficial to machine maintenance. Literature includes several soft computing, machine learning and optimization methods that had been used to model the function of harvesters of various crops. Due to the complexity of the problem, machine learning methods had been recently proposed to predict the optimal performance with promising results. In this paper, through proposing a novel hybrid machine learning model based on artificial neural networks integrated with particle swarm optimization (ANN-PSO), the performance analysis of a common combine harvester is presented. The hybridization of machine learning methods with soft computing techniques has recently shown promising results to improve the performance of the combine harvesters. This research aims at improving the results further by providing more stable models with higher accuracy.

22 Feb 2020
Hybridization of machine learning methods with soft computing techniques is
an essential approach to improve the performance of the prediction models.
Hybrid machine learning models, particularly, have gained popularity in the
advancement of the high-performance control systems. Higher accuracy and better
performance for prediction models of exergy destruction and energy consumption
used in the control circuit of heating, ventilation, and air conditioning
(HVAC) systems can be highly economical in the industrial scale to save energy.
This research proposes two hybrid models of adaptive neuro-fuzzy inference
system-particle swarm optimization (ANFIS-PSO), and adaptive neuro-fuzzy
inference system-genetic algorithm (ANFIS-GA) for HVAC. The results are further
compared with the single ANFIS model. The ANFIS-PSO model with the RMSE of
0.0065, MAE of 0.0028, and R2 equal to 0.9999, with a minimum deviation of
0.0691 (KJ/s), outperforms the ANFIS-GA and single ANFIS models.

15 Apr 2024
Evaluating the quality of arguments is a crucial aspect of any system leveraging argument mining. However, it is a challenge to obtain reliable and consistent annotations regarding argument quality, as this usually requires domain-specific expertise of the annotators. Even among experts, the assessment of argument quality is often inconsistent due to the inherent subjectivity of this task. In this paper, we study the potential of using state-of-the-art large language models (LLMs) as proxies for argument quality annotators. To assess the capability of LLMs in this regard, we analyze the agreement between model, human expert, and human novice annotators based on an established taxonomy of argument quality dimensions. Our findings highlight that LLMs can produce consistent annotations, with a moderately high agreement with human experts across most of the quality dimensions. Moreover, we show that using LLMs as additional annotators can significantly improve the agreement between annotators. These results suggest that LLMs can serve as a valuable tool for automated argument quality assessment, thus streamlining and accelerating the evaluation of large argument datasets.

30 Apr 2024
Conversational search engines such as YouChat and Microsoft Copilot use large language models (LLMs) to generate responses to queries. It is only a small step to also let the same technology insert ads within the generated responses - instead of separately placing ads next to a response. Inserted ads would be reminiscent of native advertising and product placement, both of which are very effective forms of subtle and manipulative advertising. Considering the high computational costs associated with LLMs, for which providers need to develop sustainable business models, users of conversational search engines may very well be confronted with generated native ads in the near future. In this paper, we thus take a first step to investigate whether LLMs can also be used as a countermeasure, i.e., to block generated native ads. We compile the Webis Generated Native Ads 2024 dataset of queries and generated responses with automatically inserted ads, and evaluate whether LLMs or fine-tuned sentence transformers can detect the ads. In our experiments, the investigated LLMs struggle with the task but sentence transformers achieve precision and recall values above 0.9.
There are no more papers matching your filters at the moment.
