
05 Sep 2019



This work introduces Weight Agnostic Neural Networks (WANNs), architectures evolved to perform tasks with a single, randomly sampled shared weight parameter across all connections. This approach demonstrates that significant computational capability can be intrinsically encoded in a network's topology, achieving strong performance on continuous control and supervised learning benchmarks without explicit weight training.

14 Apr 2025

Explanation methods help understand the reasons for a model's prediction. These methods are increasingly involved in model debugging, performance optimization, and gaining insights into the workings of a model. With such critical applications of these methods, it is imperative to measure the uncertainty associated with the explanations generated by these methods. In this paper, we propose a pipeline to ascertain the explanation uncertainty of neural networks by combining uncertainty estimation methods and explanation methods. We use this pipeline to produce explanation distributions for the CIFAR-10, FER+, and California Housing datasets. By computing the coefficient of variation of these distributions, we evaluate the confidence in the explanation and determine that the explanations generated using Guided Backpropagation have low uncertainty associated with them. Additionally, we compute modified pixel insertion/deletion metrics to evaluate the quality of the generated explanations.

28 Mar 2025
Sonar sensing is fundamental for underwater robotics, but limited by
capabilities of AI systems, which need large training datasets. Public data in
sonar modalities is lacking. This paper presents the Marine Debris
Forward-Looking Sonar datasets, with three different settings (watertank,
turntable, flooded quarry) increasing dataset diversity and multiple computer
vision tasks: object classification, object detection, semantic segmentation,
patch matching, and unsupervised learning. We provide full dataset description,
basic analysis and initial results for some tasks. We expect the research
community will benefit from this dataset, which is publicly available at
this https URL

05 Dec 2021
Reinforcement Learning (RL) based solutions are being adopted in a variety of domains including robotics, health care and industrial automation. Most focus is given to when these solutions work well, but they fail when presented with out of distribution inputs. RL policies share the same faults as most machine learning models. Out of distribution detection for RL is generally not well covered in the literature, and there is a lack of benchmarks for this task. In this work we propose a benchmark to evaluate OOD detection methods in a Reinforcement Learning setting, by modifying the physical parameters of non-visual standard environments or corrupting the state observation for visual environments. We discuss ways to generate custom RL environments that can produce OOD data, and evaluate three uncertainty methods for the OOD detection task. Our results show that ensemble methods have the best OOD detection performance with a lower standard deviation across multiple environments.

10 May 2021

More and more, optimization methods are used to find diverse solution sets. We compare solution diversity in multi-objective optimization, multimodal optimization, and quality diversity in a simple domain. We show that multiobjective optimization does not always produce much diversity, multimodal optimization produces higher fitness solutions, and quality diversity is not sensitive to genetic neutrality and creates the most diverse set of solutions. An autoencoder is used to discover phenotypic features automatically, producing an even more diverse solution set with quality diversity. Finally, we make recommendations about when to use which approach.

24 Jul 2024

Customers' reviews and feedback play crucial role on electronic commerce~(E-commerce) platforms like Amazon, Zalando, and eBay in influencing other customers' purchasing decisions. However, there is a prevailing concern that sellers often post fake or spam reviews to deceive potential customers and manipulate their opinions about a product. Over the past decade, there has been considerable interest in using machine learning (ML) and deep learning (DL) models to identify such fraudulent reviews. Unfortunately, the decisions made by complex ML and DL models - which often function as \emph{black-boxes} - can be surprising and difficult for general users to comprehend. In this paper, we propose an explainable framework for detecting fake reviews with high precision in identifying fraudulent content with explanations and investigate what information matters most for explaining particular decisions by conducting empirical user evaluation. Initially, we develop fake review detection models using DL and transformer models including XLNet and DistilBERT. We then introduce layer-wise relevance propagation (LRP) technique for generating explanations that can map the contributions of words toward the predicted class. The experimental results on two benchmark fake review detection datasets demonstrate that our predictive models achieve state-of-the-art performance and outperform several existing methods. Furthermore, the empirical user evaluation of the generated explanations concludes which important information needs to be considered in generating explanations in the context of fake review identification.

14 Jul 2025
Automating labor-intensive tasks such as crop monitoring with robots is essential for enhancing production and conserving resources. However, autonomously monitoring horticulture crops remains challenging due to their complex structures, which often result in fruit occlusions. Existing view planning methods attempt to reduce occlusions but either struggle to achieve adequate coverage or incur high robot motion costs. We introduce a global optimization approach for view motion planning that aims to minimize robot motion costs while maximizing fruit coverage. To this end, we leverage coverage constraints derived from the set covering problem (SCP) within a shortest Hamiltonian path problem (SHPP) formulation. While both SCP and SHPP are well-established, their tailored integration enables a unified framework that computes a global view path with minimized motion while ensuring full coverage of selected targets. Given the NP-hard nature of the problem, we employ a region-prior-based selection of coverage targets and a sparse graph structure to achieve effective optimization outcomes within a limited time. Experiments in simulation demonstrate that our method detects more fruits, enhances surface coverage, and achieves higher volume accuracy than the motion-efficient baseline with a moderate increase in motion cost, while significantly reducing motion costs compared to the coverage-focused baseline. Real-world experiments further confirm the practical applicability of our approach.

13 May 2025
Unmanned Aerial Vehicles (UAVs) are increasingly used for reforestation and
forest monitoring, including seed dispersal in hard-to-reach terrains. However,
a detailed understanding of the forest floor remains a challenge due to high
natural variability, quickly changing environmental parameters, and ambiguous
annotations due to unclear definitions. To address this issue, we adapt the
Segment Anything Model (SAM), a vision foundation model with strong
generalization capabilities, to segment forest floor objects such as tree
stumps, vegetation, and woody debris. To this end, we employ
parameter-efficient fine-tuning (PEFT) to fine-tune a small subset of
additional model parameters while keeping the original weights fixed. We adjust
SAM's mask decoder to generate masks corresponding to our dataset categories,
allowing for automatic segmentation without manual prompting. Our results show
that the adapter-based PEFT method achieves the highest mean intersection over
union (mIoU), while Low-rank Adaptation (LoRA), with fewer parameters, offers a
lightweight alternative for resource-constrained UAV platforms.

11 Dec 2024
Integrating machine learning techniques in established numerical solvers represents a modern approach to enhancing computational fluid dynamics simulations. Within the lattice Boltzmann method (LBM), the collision operator serves as an ideal entry point to incorporate machine learning techniques to enhance its accuracy and stability. In this work, an invariant neural network is constructed, acting on an equivariant collision operator, optimizing the relaxation rates of non-physical moments. This optimization enhances robustness to symmetry transformations and ensures consistent behavior across geometric operations. The proposed neural collision operator (NCO) is trained using forced isotropic turbulence simulations driven by spectral forcing, ensuring stable turbulence statistics. The desired performance is achieved by minimizing the energy spectrum discrepancy between direct numerical simulations and underresolved simulations over a specified wave number range. The loss function is further extended to tailor numerical dissipation at high wave numbers, ensuring robustness without compromising accuracy at low and intermediate wave numbers. The NCO's performance is demonstrated using three-dimensional Taylor-Green vortex (TGV) flows, where it accurately predicts the dynamics even in highly underresolved simulations. Compared to other LBM models, such as the BGK and KBC operators, the NCO exhibits superior accuracy while maintaining stability. In addition, the operator shows robust performance in alternative configurations, including turbulent three-dimensional cylinder flow. Finally, an alternative training procedure using time-dependent quantities is introduced. It is based on a reduced TGV model along with newly proposed symmetry boundary conditions. The reduction in memory consumption enables training at higher Reynolds numbers, successfully leading to stable yet accurate simulations.

23 Mar 2020
Grasp verification is advantageous for autonomous manipulation robots as they
provide the feedback required for higher level planning components about
successful task completion. However, a major obstacle in doing grasp
verification is sensor selection. In this paper, we propose a vision based
grasp verification system using machine vision cameras, with the verification
problem formulated as an image classification task. Machine vision cameras
consist of a camera and a processing unit capable of on-board deep learning
inference. The inference in these low-power hardware are done near the data
source, reducing the robot's dependence on a centralized server, leading to
reduced latency, and improved reliability. Machine vision cameras provide the
deep learning inference capabilities using different neural accelerators.
Although, it is not clear from the documentation of these cameras what is the
effect of these neural accelerators on performance metrics such as latency and
throughput. To systematically benchmark these machine vision cameras, we
propose a parameterized model generator that generates end to end models of
Convolutional Neural Networks(CNN). Using these generated models we benchmark
latency and throughput of two machine vision cameras, JeVois A33 and Sipeed
Maix Bit. Our experiments demonstrate that the selected machine vision camera
and the deep learning models can robustly verify grasp with 97% per frame
accuracy.

17 Nov 2021
The lattice Boltzmann method (LBM) is an efficient simulation technique for computational fluid mechanics and beyond. It is based on a simple stream-and-collide algorithm on Cartesian grids, which is easily compatible with modern machine learning architectures. While it is becoming increasingly clear that deep learning can provide a decisive stimulus for classical simulation techniques, recent studies have not addressed possible connections between machine learning and LBM. Here, we introduce Lettuce, a PyTorch-based LBM code with a threefold aim. Lettuce enables GPU accelerated calculations with minimal source code, facilitates rapid prototyping of LBM models, and enables integrating LBM simulations with PyTorch's deep learning and automatic differentiation facility. As a proof of concept for combining machine learning with the LBM, a neural collision model is developed, trained on a doubly periodic shear layer and then transferred to a different flow, a decaying turbulence. We also exemplify the added benefit of PyTorch's automatic differentiation framework in flow control and optimization. To this end, the spectrum of a forced isotropic turbulence is maintained without further constraining the velocity field. The source code is freely available from this https URL.

31 Oct 2023
Recent technological advancements have led to a large number of patents in a
diverse range of domains, making it challenging for human experts to analyze
and manage. State-of-the-art methods for multi-label patent classification rely
on deep neural networks (DNNs), which are complex and often considered
black-boxes due to their opaque decision-making processes. In this paper, we
propose a novel deep explainable patent classification framework by introducing
layer-wise relevance propagation (LRP) to provide human-understandable
explanations for predictions. We train several DNN models, including Bi-LSTM,
CNN, and CNN-BiLSTM, and propagate the predictions backward from the output
layer up to the input layer of the model to identify the relevance of words for
individual predictions. Considering the relevance score, we then generate
explanations by visualizing relevant words for the predicted patent class.
Experimental results on two datasets comprising two-million patent texts
demonstrate high performance in terms of various evaluation measures. The
explanations generated for each prediction highlight important relevant words
that align with the predicted class, making the prediction more understandable.
Explainable systems have the potential to facilitate the adoption of complex
AI-enabled methods for patent classification in real-world applications.

03 Oct 2022
Recent advances in Explainable AI (XAI) increased the demand for deployment of safe and interpretable AI models in various industry sectors. Despite the latest success of deep neural networks in a variety of domains, understanding the decision-making process of such complex models still remains a challenging task for domain experts. Especially in the financial domain, merely pointing to an anomaly composed of often hundreds of mixed type columns, has limited value for experts. Hence, in this paper, we propose a framework for explaining anomalies using denoising autoencoders designed for mixed type tabular data. We specifically focus our technique on anomalies that are erroneous observations. This is achieved by localizing individual sample columns (cells) with potential errors and assigning corresponding confidence scores. In addition, the model provides the expected cell value estimates to fix the errors. We evaluate our approach based on three standard public tabular datasets (Credit Default, Adult, IEEE Fraud) and one proprietary dataset (Holdings). We find that denoising autoencoders applied to this task already outperform other approaches in the cell error detection rates as well as in the expected value rates. Additionally, we analyze how a specialized loss designed for cell error detection can further improve these metrics. Our framework is designed for a domain expert to understand abnormal characteristics of an anomaly, as well as to improve in-house data quality management processes.

21 Mar 2017
Neuroevolution methods evolve the weights of a neural network, and in some cases the topology, but little work has been done to analyze the effect of evolving the activation functions of individual nodes on network size, which is important when training networks with a small number of samples. In this work we extend the neuroevolution algorithm NEAT to evolve the activation function of neurons in addition to the topology and weights of the network. The size and performance of networks produced using NEAT with uniform activation in all nodes, or homogenous networks, is compared to networks which contain a mixture of activation functions, or heterogenous networks. For a number of regression and classification benchmarks it is shown that, (1) qualitatively different activation functions lead to different results in homogeneous networks, (2) the heterogeneous version of NEAT is able to select well performing activation functions, (3) producing heterogeneous networks that are significantly smaller than homogeneous networks.
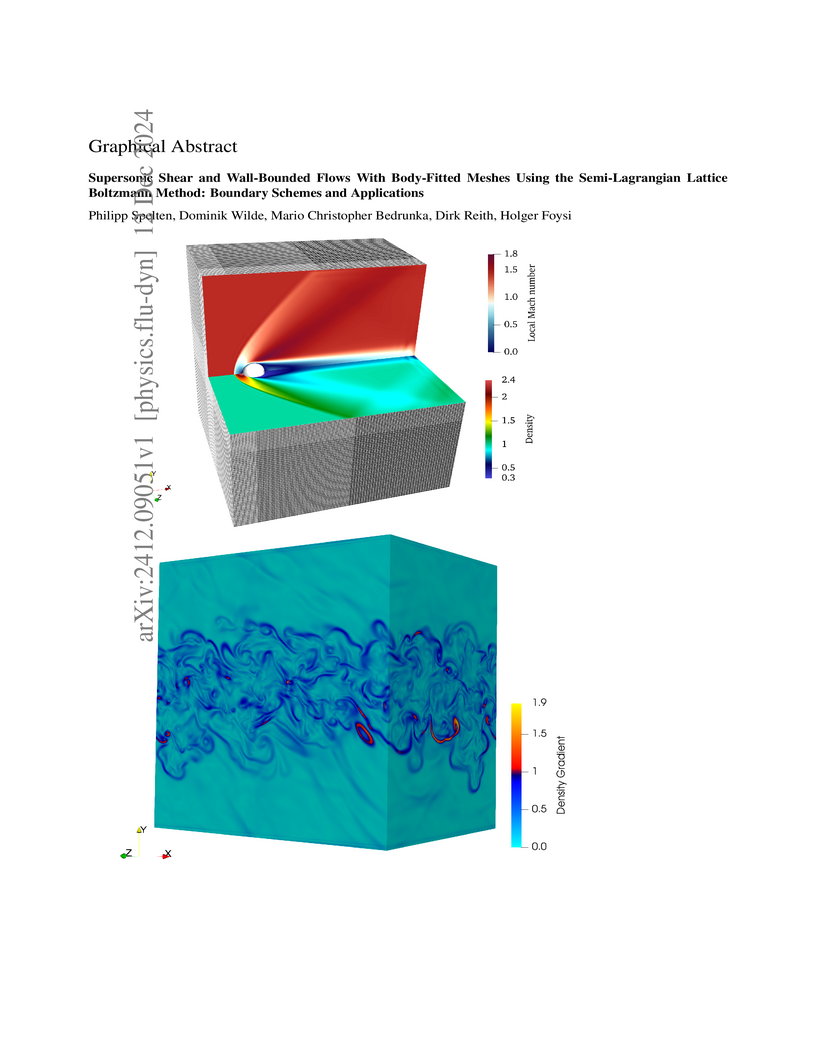
12 Dec 2024
Lattice Boltzmann method (LBM) simulations of incompressible flows are nowadays common and well-established. However, for compressible turbulent flows with strong variable density and intrinsic compressibility effects, results are relatively scarce. Only recently, progress was made regarding compressible LBM, usually applied to simple one and two-dimensional test cases due to the increased computational expense. The recently developed semi-Lagrangian lattice Boltzmann method (SLLBM) is capable of simulating two- and three-dimensional viscous compressible flows. This paper presents bounce-back, thermal, inlet, and outlet boundary conditions new to the method and their application to problems including heated or cooled walls, often required for supersonic flow cases. Using these boundary conditions, the SLLBM's capabilities are demonstrated in various test cases, including a supersonic 2D NACA-0012 airfoil, flow around a 3D sphere, and, to the best of our knowledge, for the first time, the 3D simulation of a supersonic turbulent channel flow at a bulk Mach number of Ma=1.5 and a 3D temporal supersonic compressible mixing layer at convective Mach numbers ranging from Ma=0.3 to Ma=1.2. The results show that the compressible SLLBM is able to adequately capture intrinsic and variable density compressibility effects.

11 Nov 2022
Safety-critical applications like autonomous driving use Deep Neural Networks (DNNs) for object detection and segmentation. The DNNs fail to predict when they observe an Out-of-Distribution (OOD) input leading to catastrophic consequences. Existing OOD detection methods were extensively studied for image inputs but have not been explored much for LiDAR inputs. So in this study, we proposed two datasets for benchmarking OOD detection in 3D semantic segmentation. We used Maximum Softmax Probability and Entropy scores generated using Deep Ensembles and Flipout versions of RandLA-Net as OOD scores. We observed that Deep Ensembles out perform Flipout model in OOD detection with greater AUROC scores for both datasets.

04 Jun 2023
Saliency methods are frequently used to explain Deep Neural Network-based models. Adebayo et al.'s work on evaluating saliency methods for classification models illustrate certain explanation methods fail the model and data randomization tests. However, on extending the tests for various state of the art object detectors we illustrate that the ability to explain a model is more dependent on the model itself than the explanation method. We perform sanity checks for object detection and define new qualitative criteria to evaluate the saliency explanations, both for object classification and bounding box decisions, using Guided Backpropagation, Integrated Gradients, and their Smoothgrad versions, together with Faster R-CNN, SSD, and EfficientDet-D0, trained on COCO. In addition, the sensitivity of the explanation method to model parameters and data labels varies class-wise motivating to perform the sanity checks for each class. We find that EfficientDet-D0 is the most interpretable method independent of the saliency method, which passes the sanity checks with little problems.

05 Jul 2020
The encoding of solutions in black-box optimization is a delicate, handcrafted balance between expressiveness and domain knowledge -- between exploring a wide variety of solutions, and ensuring that those solutions are useful. Our main insight is that this process can be automated by generating a dataset of high-performing solutions with a quality diversity algorithm (here, MAP-Elites), then learning a representation with a generative model (here, a Variational Autoencoder) from that dataset. Our second insight is that this representation can be used to scale quality diversity optimization to higher dimensions -- but only if we carefully mix solutions generated with the learned representation and those generated with traditional variation operators. We demonstrate these capabilities by learning an low-dimensional encoding for the inverse kinematics of a thousand joint planar arm. The results show that learned representations make it possible to solve high-dimensional problems with orders of magnitude fewer evaluations than the standard MAP-Elites, and that, once solved, the produced encoding can be used for rapid optimization of novel, but similar, tasks. The presented techniques not only scale up quality diversity algorithms to high dimensions, but show that black-box optimization encodings can be automatically learned, rather than hand designed.

17 Apr 2018
Surrogate-assistance approaches have long been used in computationally expensive domains to improve the data-efficiency of optimization algorithms. Neuroevolution, however, has so far resisted the application of these techniques because it requires the surrogate model to make fitness predictions based on variable topologies, instead of a vector of parameters. Our main insight is that we can sidestep this problem by using kernel-based surrogate models, which require only the definition of a distance measure between individuals. Our second insight is that the well-established Neuroevolution of Augmenting Topologies (NEAT) algorithm provides a computationally efficient distance measure between dissimilar networks in the form of "compatibility distance", initially designed to maintain topological diversity. Combining these two ideas, we introduce a surrogate-assisted neuroevolution algorithm that combines NEAT and a surrogate model built using a compatibility distance kernel. We demonstrate the data-efficiency of this new algorithm on the low dimensional cart-pole swing-up problem, as well as the higher dimensional half-cheetah running task. In both tasks the surrogate-assisted variant achieves the same or better results with several times fewer function evaluations as the original NEAT.

15 Jun 2018
Design optimization techniques are often used at the beginning of the design process to explore the space of possible designs. In these domains illumination algorithms, such as MAP-Elites, are promising alternatives to classic optimization algorithms because they produce diverse, high-quality solutions in a single run, instead of only a single near-optimal solution. Unfortunately, these algorithms currently require a large number of function evaluations, limiting their applicability. In this article we introduce a new illumination algorithm, Surrogate-Assisted Illumination (SAIL), that leverages surrogate modeling techniques to create a map of the design space according to user-defined features while minimizing the number of fitness evaluations. On a 2-dimensional airfoil optimization problem SAIL produces hundreds of diverse but high-performing designs with several orders of magnitude fewer evaluations than MAP-Elites or CMA-ES. We demonstrate that SAIL is also capable of producing maps of high-performing designs in realistic 3-dimensional aerodynamic tasks with an accurate flow simulation. Data-efficient design exploration with SAIL can help designers understand what is possible, beyond what is optimal, by considering more than pure objective-based optimization.
There are no more papers matching your filters at the moment.
