
28 Sep 2025


Researchers from institutions including the Max Planck Institute for Intelligent Systems demonstrate that marginal gains in LLM single-step accuracy lead to exponential improvements in long-horizon task completion, challenging the perception of diminishing returns from scaling. The study identifies 'self-conditioning' as a distinct execution failure mode and shows that sequential test-time compute significantly extends reliable task execution.

17 Sep 2025


A new method, Compute as Teacher (CaT), generates supervision signals for large language models in post-training scenarios lacking traditional ground truth or programmatic verifiers. It leverages inference compute to synthesize reference-free supervision, leading to relative performance increases of up to 33% on MATH-500 and 30% on HealthBench.
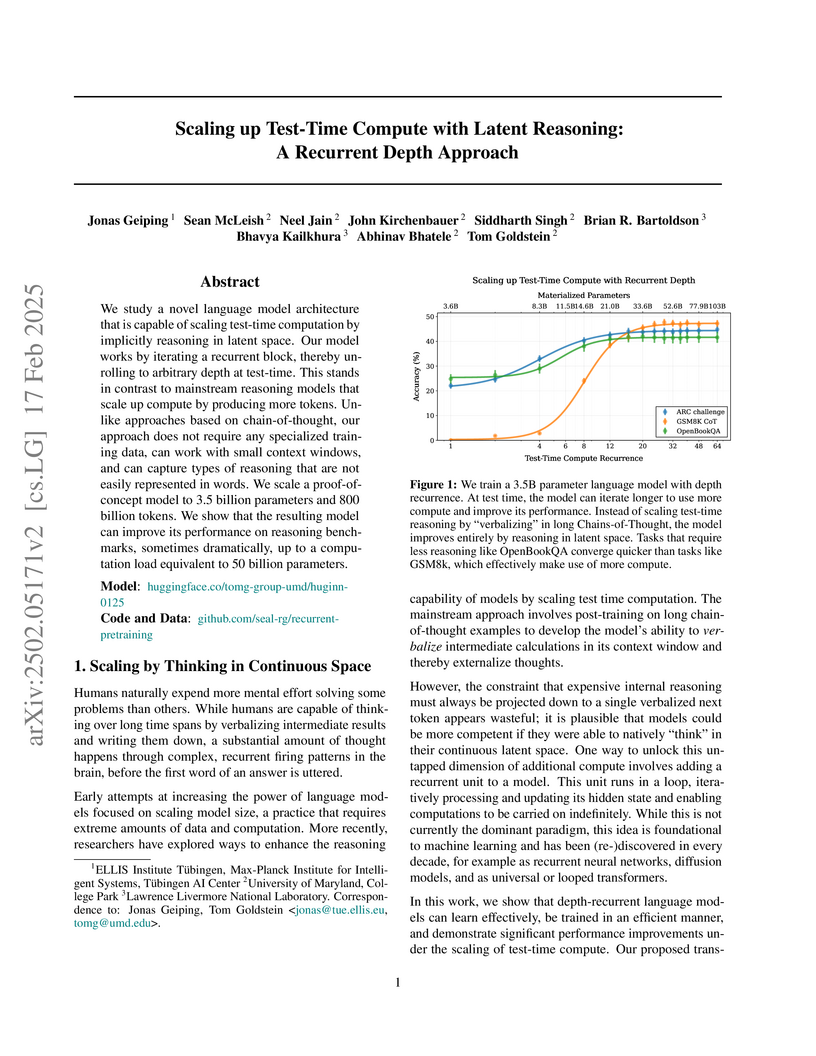
17 Feb 2025


Researchers from ELLIS Institute Tübingen, University of Maryland, and Lawrence Livermore National Laboratory introduce a recurrent depth transformer architecture that scales reasoning abilities by implicitly processing information in a continuous latent space. The 3.5 billion parameter model, Huginn-0125, trained on the Frontier supercomputer, demonstrates significant performance gains on reasoning benchmarks with increased test-time iterations, sometimes matching or exceeding larger models without requiring specialized Chain-of-Thought training data.

14 Oct 2025





Researchers from The Hong Kong Polytechnic University, Dartmouth College, Max Planck Institute, Google DeepMind, and others developed Prophet, a training-free adaptive decoding paradigm for Diffusion Language Models (DLMs) that leverages early answer convergence. The method achieves up to 3.4 times faster inference by dynamically committing to answers when model confidence is high, often improving output quality compared to full-step decoding.

23 Sep 2025

Large language model (LLM) developers aim for their models to be honest, helpful, and harmless. However, when faced with malicious requests, models are trained to refuse, sacrificing helpfulness. We show that frontier LLMs can develop a preference for dishonesty as a new strategy, even when other options are available. Affected models respond to harmful requests with outputs that sound harmful but are crafted to be subtly incorrect or otherwise harmless in practice. This behavior emerges with hard-to-predict variations even within models from the same model family. We find no apparent cause for the propensity to deceive, but show that more capable models are better at executing this strategy. Strategic dishonesty already has a practical impact on safety evaluations, as we show that dishonest responses fool all output-based monitors used to detect jailbreaks that we test, rendering benchmark scores unreliable. Further, strategic dishonesty can act like a honeypot against malicious users, which noticeably obfuscates prior jailbreak attacks. While output monitors fail, we show that linear probes on internal activations can be used to reliably detect strategic dishonesty. We validate probes on datasets with verifiable outcomes and by using them as steering vectors. Overall, we consider strategic dishonesty as a concrete example of a broader concern that alignment of LLMs is hard to control, especially when helpfulness and harmlessness conflict.

26 May 2025
A study from the University of Freiburg and Prior Labs shows that TabPFN-v2, a foundation model trained exclusively on synthetic tabular data, achieves state-of-the-art zero-shot performance in time series forecasting. It outperforms specialized models like TimesFM-2.0 in probabilistic forecasting and ranks competitively in point forecasting on the GIFT-Eval benchmark.

16 Oct 2025

Researchers from the ELLIS Institute Tübingen, Max-Planck Institute for Intelligent Systems, and Carnegie Mellon University developed a diffusion forcing sampler for recurrent-depth language models. This method leverages diffusion principles to achieve up to a 5x inference speedup with only minor (around 1%) accuracy trade-offs, making these models more practical for complex reasoning tasks.

03 Nov 2025
With the growing popularity of deep learning and foundation models for tabular data, the need for standardized and reliable benchmarks is higher than ever. However, current benchmarks are static. Their design is not updated even if flaws are discovered, model versions are updated, or new models are released. To address this, we introduce TabArena, the first continuously maintained living tabular benchmarking system. To launch TabArena, we manually curate a representative collection of datasets and well-implemented models, conduct a large-scale benchmarking study to initialize a public leaderboard, and assemble a team of experienced maintainers. Our results highlight the influence of validation method and ensembling of hyperparameter configurations to benchmark models at their full potential. While gradient-boosted trees are still strong contenders on practical tabular datasets, we observe that deep learning methods have caught up under larger time budgets with ensembling. At the same time, foundation models excel on smaller datasets. Finally, we show that ensembles across models advance the state-of-the-art in tabular machine learning. We observe that some deep learning models are overrepresented in cross-model ensembles due to validation set overfitting, and we encourage model developers to address this issue. We launch TabArena with a public leaderboard, reproducible code, and maintenance protocols to create a living benchmark available at this https URL.

25 Sep 2025
A foundational framework establishes a "physics of learning" by postulating that learning processes adhere to a principle of least action. This work unifies diverse machine learning paradigms, including supervised learning, reinforcement learning, and generative models, by deriving their core algorithms from specific "Learning Lagrangians" and demonstrates a conceptual link where reinforcement learning is a Legendre transform of parameter estimation tasks.

14 Jun 2025

Research from the Max Planck Institute for Intelligent Systems demonstrated that Stochastic Gradient Descent (SGD) with momentum can train Transformer-based language models effectively, performing comparably to Adam in small-batch settings. The study found that Adam exhibits batch-size dependent acceleration not present in SGD, making SGD slower to converge at larger batch sizes.

13 Nov 2025

Understanding the geometry of neural network loss landscapes is a central question in deep learning, with implications for generalization and optimization. A striking phenomenon is linear mode connectivity (LMC), where independently trained models can be connected by low- or zero-loss paths despite appearing to lie in separate loss basins. However, this is often obscured by symmetries in parameter space -- such as neuron permutations -- which make functionally equivalent models appear dissimilar. Prior work has predominantly focused on neuron reordering through permutations, but such approaches are limited in scope and fail to capture the richer symmetries exhibited by modern architectures such as Transformers. In this work, we introduce a unified framework that captures four symmetry classes -- permutations, semi-permutations, orthogonal transformations, and general invertible maps -- broadening the set of valid reparameterizations and subsuming many previous approaches as special cases. Crucially, this generalization enables, for the first time, the discovery of low- and zero-barrier linear interpolation paths between independently trained Vision Transformers and GPT-2 models. Furthermore, our framework extends beyond pairwise alignment to multi-model and width-heterogeneous settings, enabling alignment across architectures of different sizes. These results reveal deeper structure in the loss landscape and underscore the importance of symmetry-aware analysis for understanding model space geometry.

01 Dec 2025

Understanding the remarkable efficacy of Adam when training transformer-based language models has become a central research topic within the optimization community. To gain deeper insights, several simplifications of Adam have been proposed, such as the signed gradient and signed momentum methods. In this work, we conduct an extensive empirical study - training over 1500 language models across different data configurations and scales - comparing Adam to several known simplified variants. We find that signed momentum methods are faster than SGD, but consistently underperform relative to Adam, even after careful tuning of momentum, clipping setting and learning rates. However, our analysis reveals a compelling option that preserves near-optimal performance while allowing for new insightful reformulations: constraining the Adam momentum parameters to be equal, beta1 = beta2. Beyond robust performance, this choice affords new theoretical insights, highlights the "secret sauce" on top of signed momentum, and grants a precise statistical interpretation: we show that Adam in this setting implements a natural online algorithm for estimating the mean and variance of gradients-one that arises from a mean-field Gaussian variational inference perspective.
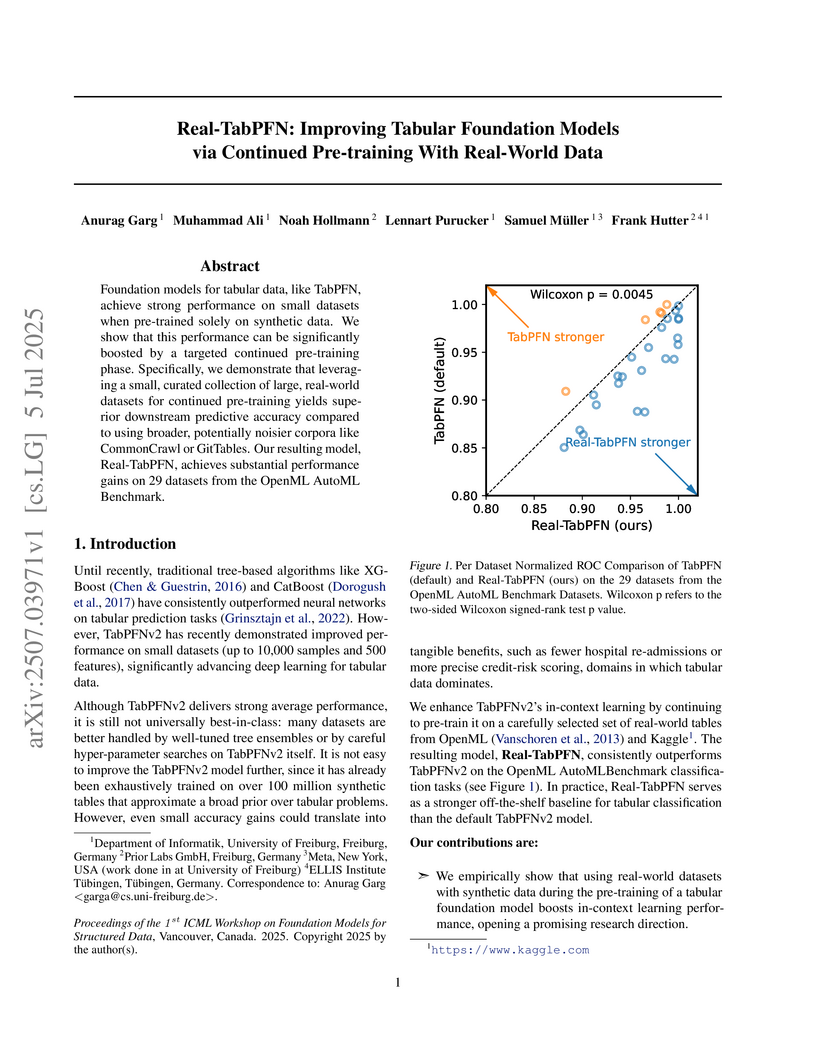
05 Jul 2025


Real-TabPFN enhances the TabPFNv2 tabular foundation model by undergoing continued pre-training on curated real-world datasets, leading to statistically significant performance improvements on small tabular classification tasks. The model achieved a mean normalized ROC-AUC of 0.976, surpassing its predecessor and other baselines.

07 Oct 2025
Research from the ELLIS Institute and Max Planck Institute demonstrates that post-training quantization (PTQ) robustness in large language models is primarily influenced by training dynamics, such as learning rate schedules and weight averaging, rather than solely by the amount of training data. Higher learning rates and strategic weight averaging during training were found to substantially improve the quality of quantized models, offering practical methods to mitigate degradation.

20 Nov 2025
Estimation of causal effects is critical to a range of scientific disciplines. Existing methods for this task either require interventional data, knowledge about the ground truth causal graph, or rely on assumptions such as unconfoundedness, restricting their applicability in real-world settings. In the domain of tabular machine learning, Prior-data fitted networks (PFNs) have achieved state-of-the-art predictive performance, having been pre-trained on synthetic data to solve tabular prediction problems via in-context learning. To assess whether this can be transferred to the harder problem of causal effect estimation, we pre-train PFNs on synthetic data drawn from a wide variety of causal structures, including interventions, to predict interventional outcomes given observational data. Through extensive experiments on synthetic case studies, we show that our approach allows for the accurate estimation of causal effects without knowledge of the underlying causal graph. We also perform ablation studies that elucidate Do-PFN's scalability and robustness across datasets with a variety of causal characteristics.

03 Jul 2025
Researchers from Max Planck Institute for Intelligent Systems and ELLIS Institute Tübingen demonstrate that multiple-choice question benchmarks for large language models are often solved via discriminative shortcuts rather than generative reasoning. The paper proposes and validates "answer matching," an LLM-assisted generative evaluation method utilizing reference answers, which exhibits significantly higher alignment with human judgment and proves to be a cost-effective alternative to traditional multiple-choice evaluation.

13 Oct 2025
MATH-Beyond (MATH-B) is a new benchmark designed to assess the genuine expansion of reasoning capabilities in large language models for mathematics, moving beyond mere refinement of existing skills. The benchmark reveals that current open-source reinforcement learning fine-tuning methods achieve only marginal improvements in expanding reasoning boundaries on genuinely challenging problems, whereas knowledge distillation from stronger models yields substantially higher expansion.

10 Oct 2025
Deep sequence models, ranging from Transformers and State Space Models (SSMs) to more recent approaches such as gated linear RNNs, fundamentally compute outputs as linear combinations of past value vectors. To draw insights and systematically compare such architectures, we develop a unified framework that makes this output operation explicit, by casting the linear combination coefficients as the outputs of autonomous linear dynamical systems driven by impulse inputs. This viewpoint, in spirit substantially different from approaches focusing on connecting linear RNNs with linear attention, reveals a common mathematical theme across diverse architectures and crucially captures softmax attention, on top of RNNs, SSMs, and related models. In contrast to new model proposals that are commonly evaluated on benchmarks, we derive design principles linking architectural choices to model properties. Thereby identifying tradeoffs between expressivity and efficient implementation, geometric constraints on input selectivity, and stability conditions for numerically stable training and information retention. By connecting several insights and observations from recent literature, the framework both explains empirical successes of recent designs and provides guiding principles for systematically designing new sequence model architectures.

10 Oct 2025
Despite the advantageous subquadratic complexity of modern recurrent deep learning models -- such as state-space models (SSMs) -- recent studies have highlighted their potential shortcomings compared to transformers on reasoning and memorization tasks. In this paper, we dive deeper into one of such benchmarks: associative recall (AR), which has been shown to correlate well with language modeling performance, and inspect in detail the effects of scaling and optimization issues in recently proposed token mixing strategies. We first demonstrate that, unlike standard transformers, the choice of learning rate plays a critical role in the performance of modern recurrent models: an issue that can severely affect reported performance in previous works and suggests further research is needed to stabilize training. Next, we show that recurrent and attention-based models exhibit contrasting benefits when scaling in width as opposed to depth, with attention being notably unable to solve AR when limited to a single layer. We then further inspect 1-layer transformers, revealing that despite their poor performance, their training dynamics surprisingly resemble the formation of induction heads, a phenomenon previously observed only in their 2-layer counterparts. Finally, through architectural ablations, we study how components affects Transformer and Mamba's performance and optimization stability.

15 Oct 2025
 University of Toronto
University of Toronto University of Cambridge
University of Cambridge Harvard University
Harvard University Université de Montréal
Université de Montréal UC Berkeley
UC Berkeley University of Oxford
University of Oxford Tsinghua University
Tsinghua University Stanford University
Stanford University Mila - Quebec AI InstituteIEEE
Mila - Quebec AI InstituteIEEE University of MarylandThe Alan Turing Institute
University of MarylandThe Alan Turing Institute Stony Brook UniversityInstitute for Advanced Study
Stony Brook UniversityInstitute for Advanced Study Inria
Inria MIT
MIT Princeton UniversityMaastricht UniversityUniversity College DublinOregon State UniversityLinköping UniversityPontificia Universidad Católica de ChileUniversity of YorkELLIS Institute TübingenLoughborough UniversityCentre for the Governance of AIApollo ResearchSaferAIUK AI Security InstituteFederal University of PernambucoDukeCarnegie Endowment for International PeaceLawZeroKIRA CenterAdvanced Research and Invention Agency (ARIA)AI CollaborativeResponsible AI UK
Princeton UniversityMaastricht UniversityUniversity College DublinOregon State UniversityLinköping UniversityPontificia Universidad Católica de ChileUniversity of YorkELLIS Institute TübingenLoughborough UniversityCentre for the Governance of AIApollo ResearchSaferAIUK AI Security InstituteFederal University of PernambucoDukeCarnegie Endowment for International PeaceLawZeroKIRA CenterAdvanced Research and Invention Agency (ARIA)AI CollaborativeResponsible AI UKSince the publication of the first International AI Safety Report, AI capabilities have continued to improve across key domains. New training techniques that teach AI systems to reason step-by-step and inference-time enhancements have primarily driven these advances, rather than simply training larger models. As a result, general-purpose AI systems can solve more complex problems in a range of domains, from scientific research to software development. Their performance on benchmarks that measure performance in coding, mathematics, and answering expert-level science questions has continued to improve, though reliability challenges persist, with systems excelling on some tasks while failing completely on others. These capability improvements also have implications for multiple risks, including risks from biological weapons and cyber attacks. Finally, they pose new challenges for monitoring and controllability. This update examines how AI capabilities have improved since the first Report, then focuses on key risk areas where substantial new evidence warrants updated assessments.
There are no more papers matching your filters at the moment.
