
24 Nov 2023

This survey systematically reviews recent advancements in Spatio-Temporal Graph Neural Networks (STGNNs) for predictive learning across various urban computing domains, including transportation and environmental modeling. It provides a structured analysis of STGNN architectures, their methods for spatio-temporal dependency capture, and integrations with advanced learning frameworks, while also identifying current limitations and outlining future research directions in the field.

16 Jun 2024

As cities continue to burgeon, Urban Computing emerges as a pivotal
discipline for sustainable development by harnessing the power of cross-domain
data fusion from diverse sources (e.g., geographical, traffic, social media,
and environmental data) and modalities (e.g., spatio-temporal, visual, and
textual modalities). Recently, we are witnessing a rising trend that utilizes
various deep-learning methods to facilitate cross-domain data fusion in smart
cities. To this end, we propose the first survey that systematically reviews
the latest advancements in deep learning-based data fusion methods tailored for
urban computing. Specifically, we first delve into data perspective to
comprehend the role of each modality and data source. Secondly, we classify the
methodology into four primary categories: feature-based, alignment-based,
contrast-based, and generation-based fusion methods. Thirdly, we further
categorize multi-modal urban applications into seven types: urban planning,
transportation, economy, public safety, society, environment, and energy.
Compared with previous surveys, we focus more on the synergy of deep learning
methods with urban computing applications. Furthermore, we shed light on the
interplay between Large Language Models (LLMs) and urban computing, postulating
future research directions that could revolutionize the field. We firmly
believe that the taxonomy, progress, and prospects delineated in our survey
stand poised to significantly enrich the research community. The summary of the
comprehensive and up-to-date paper list can be found at
https://github.com/yoshall/Awesome-Multimodal-Urban-Computing.

20 Oct 2023



Temporal data, notably time series and spatio-temporal data, are prevalent in real-world applications. They capture dynamic system measurements and are produced in vast quantities by both physical and virtual sensors. Analyzing these data types is vital to harnessing the rich information they encompass and thus benefits a wide range of downstream tasks. Recent advances in large language and other foundational models have spurred increased use of these models in time series and spatio-temporal data mining. Such methodologies not only enable enhanced pattern recognition and reasoning across diverse domains but also lay the groundwork for artificial general intelligence capable of comprehending and processing common temporal data. In this survey, we offer a comprehensive and up-to-date review of large models tailored (or adapted) for time series and spatio-temporal data, spanning four key facets: data types, model categories, model scopes, and application areas/tasks. Our objective is to equip practitioners with the knowledge to develop applications and further research in this underexplored domain. We primarily categorize the existing literature into two major clusters: large models for time series analysis (LM4TS) and spatio-temporal data mining (LM4STD). On this basis, we further classify research based on model scopes (i.e., general vs. domain-specific) and application areas/tasks. We also provide a comprehensive collection of pertinent resources, including datasets, model assets, and useful tools, categorized by mainstream applications. This survey coalesces the latest strides in large model-centric research on time series and spatio-temporal data, underscoring the solid foundations, current advances, practical applications, abundant resources, and future research opportunities.

21 Mar 2024



Trajectory computing is a pivotal domain encompassing trajectory data
management and mining, garnering widespread attention due to its crucial role
in various practical applications such as location services, urban traffic, and
public safety. Traditional methods, focusing on simplistic spatio-temporal
features, face challenges of complex calculations, limited scalability, and
inadequate adaptability to real-world complexities. In this paper, we present a
comprehensive review of the development and recent advances in deep learning
for trajectory computing (DL4Traj). We first define trajectory data and provide
a brief overview of widely-used deep learning models. Systematically, we
explore deep learning applications in trajectory management (pre-processing,
storage, analysis, and visualization) and mining (trajectory-related
forecasting, trajectory-related recommendation, trajectory classification,
travel time estimation, anomaly detection, and mobility generation). Notably,
we encapsulate recent advancements in Large Language Models (LLMs) that hold
the potential to augment trajectory computing. Additionally, we summarize
application scenarios, public datasets, and toolkits. Finally, we outline
current challenges in DL4Traj research and propose future directions. Relevant
papers and open-source resources have been collated and are continuously
updated at:
\href{https://github.com/yoshall/Awesome-Trajectory-Computing}{DL4Traj Repo}.

08 Aug 2025
The proliferation of artificial intelligence has enabled a diversity of applications that bridge the gap between digital and physical worlds. As physical environments are too complex to model through a single information acquisition approach, it is crucial to fuse multimodal data generated by different sources, such as sensors, devices, systems, and people, to solve a problem in the real world. Unfortunately, it is neither applicable nor sustainable to deploy new resources to collect original data from scratch for every problem. Thus, when data is inadequate in the domain of problem, it is vital to fuse knowledge from multimodal data that is already available in other domains. We call this cross-domain knowledge fusion. Existing research focus on fusing multimodal data in a single domain, supposing the knowledge from different datasets is intrinsically aligned; however, this assumption may not hold in the scenarios of cross-domain knowledge fusion. In this paper, we formally define the cross-domain multimodal data fusion problem, discussing its unique challenges, differences and advantages beyond data fusion in a single domain. We propose a four-layer framework, consisting of Domains, Links, Models and Data layers, answering three key questions:"what to fuse", "why can be fused", and "how to fuse". The Domains Layer selects relevant data from different domains for a given problem. The Links Layer reveals the philosophy of knowledge alignment beyond specific model structures. The Models Layer provides two knowledge fusion paradigms based on the fundamental mechanisms for processing data. The Data Layer turns data of different structures, resolutions, scales and distributions into a consistent representation that can be fed into an AI model. With this framework, we can design solutions that fuse cross-domain multimodal data effectively for solving real-world problems.

17 Oct 2024
Referring multi-object tracking (RMOT) is an emerging cross-modal task that aims to locate an arbitrary number of target objects and maintain their identities referred by a language expression in a video. This intricate task involves the reasoning of linguistic and visual modalities, along with the temporal association of target objects. However, the seminal work employs only loose feature fusion and overlooks the utilization of long-term information on tracked objects. In this study, we introduce a compact Transformer-based method, termed TenRMOT. We conduct feature fusion at both encoding and decoding stages to fully exploit the advantages of Transformer architecture. Specifically, we incrementally perform cross-modal fusion layer-by-layer during the encoding phase. In the decoding phase, we utilize language-guided queries to probe memory features for accurate prediction of the desired objects. Moreover, we introduce a query update module that explicitly leverages temporal prior information of the tracked objects to enhance the consistency of their trajectories. In addition, we introduce a novel task called Referring Multi-Object Tracking and Segmentation (RMOTS) and construct a new dataset named Ref-KITTI Segmentation. Our dataset consists of 18 videos with 818 expressions, and each expression averages 10.7 masks, which poses a greater challenge compared to the typical single mask in most existing referring video segmentation datasets. TenRMOT demonstrates superior performance on both the referring multi-object tracking and the segmentation tasks.

25 Feb 2024

Trajectory representation learning plays a pivotal role in supporting various downstream tasks. Traditional methods in order to filter the noise in GPS trajectories tend to focus on routing-based methods used to simplify the trajectories. However, this approach ignores the motion details contained in the GPS data, limiting the representation capability of trajectory representation learning. To fill this gap, we propose a novel representation learning framework that Joint GPS and Route Modelling based on self-supervised technology, namely JGRM. We consider GPS trajectory and route as the two modes of a single movement observation and fuse information through inter-modal information interaction. Specifically, we develop two encoders, each tailored to capture representations of route and GPS trajectories respectively. The representations from the two modalities are fed into a shared transformer for inter-modal information interaction. Eventually, we design three self-supervised tasks to train the model. We validate the effectiveness of the proposed method on two real datasets based on extensive experiments. The experimental results demonstrate that JGRM outperforms existing methods in both road segment representation and trajectory representation tasks. Our source code is available at Anonymous Github.

05 Apr 2023
Offline reinforcement learning (RL) methods can generally be categorized into two types: RL-based and Imitation-based. RL-based methods could in principle enjoy out-of-distribution generalization but suffer from erroneous off-policy evaluation. Imitation-based methods avoid off-policy evaluation but are too conservative to surpass the dataset. In this study, we propose an alternative approach, inheriting the training stability of imitation-style methods while still allowing logical out-of-distribution generalization. We decompose the conventional reward-maximizing policy in offline RL into a guide-policy and an execute-policy. During training, the guide-poicy and execute-policy are learned using only data from the dataset, in a supervised and decoupled manner. During evaluation, the guide-policy guides the execute-policy by telling where it should go so that the reward can be maximized, serving as the \textit{Prophet}. By doing so, our algorithm allows \textit{state-compositionality} from the dataset, rather than \textit{action-compositionality} conducted in prior imitation-style methods. We dumb this new approach Policy-guided Offline RL (\texttt{POR}). \texttt{POR} demonstrates the state-of-the-art performance on D4RL, a standard benchmark for offline RL. We also highlight the benefits of \texttt{POR} in terms of improving with supplementary suboptimal data and easily adapting to new tasks by only changing the guide-poicy.

16 Jan 2025



The ever-increasing sensor service, though opening a precious path and providing a deluge of earth system data for deep-learning-oriented earth science, sadly introduce a daunting obstacle to their industrial level deployment. Concretely, earth science systems rely heavily on the extensive deployment of sensors, however, the data collection from sensors is constrained by complex geographical and social factors, making it challenging to achieve comprehensive coverage and uniform deployment. To alleviate the obstacle, traditional approaches to sensor deployment utilize specific algorithms to design and deploy sensors. These methods \textit{dynamically adjust the activation times of sensors to optimize the detection process across each sub-region}. Regrettably, formulating an activation strategy generally based on historical observations and geographic characteristics, which make the methods and resultant models were neither simple nor practical. Worse still, the complex technical design may ultimately lead to a model with weak generalizability. In this paper, we introduce for the first time the concept of spatio-temporal data dynamic sparse training and are committed to adaptively, dynamically filtering important sensor distributions. To our knowledge, this is the \textbf{first} proposal (\textit{termed DynST}) of an \textbf{industry-level} deployment optimization concept at the data level. However, due to the existence of the temporal dimension, pruning of spatio-temporal data may lead to conflicts at different timestamps. To achieve this goal, we employ dynamic merge technology, along with ingenious dimensional mapping to mitigate potential impacts caused by the temporal aspect. During the training process, DynST utilize iterative pruning and sparse training, repeatedly identifying and dynamically removing sensor perception areas that contribute the least to future predictions.

08 Apr 2022
The Constraints Penalized Q-learning (CPQ) algorithm enables learning high-reward, safety-constrained policies solely from mixed, potentially unsafe offline datasets. It achieves this by explicitly penalizing out-of-distribution actions in the cost function and ensuring reward Q-value backups and policy selection only consider safe state-action pairs.

27 Jun 2024
Personalized Federated Continual Learning (PFCL) is a new practical scenario that poses greater challenges in sharing and personalizing knowledge. PFCL not only relies on knowledge fusion for server aggregation at the global spatial-temporal perspective but also needs model improvement for each client according to the local requirements. Existing methods, whether in Personalized Federated Learning (PFL) or Federated Continual Learning (FCL), have overlooked the multi-granularity representation of knowledge, which can be utilized to overcome Spatial-Temporal Catastrophic Forgetting (STCF) and adopt generalized knowledge to itself by coarse-to-fine human cognitive mechanisms. Moreover, it allows more effectively to personalized shared knowledge, thus serving its own purpose. To this end, we propose a novel concept called multi-granularity prompt, i.e., coarse-grained global prompt acquired through the common model learning process, and fine-grained local prompt used to personalize the generalized representation. The former focuses on efficiently transferring shared global knowledge without spatial forgetting, and the latter emphasizes specific learning of personalized local knowledge to overcome temporal forgetting. In addition, we design a selective prompt fusion mechanism for aggregating knowledge of global prompts distilled from different clients. By the exclusive fusion of coarse-grained knowledge, we achieve the transmission and refinement of common knowledge among clients, further enhancing the performance of personalization. Extensive experiments demonstrate the effectiveness of the proposed method in addressing STCF as well as improving personalized performance. Our code now is available at this https URL.

20 Jul 2022
Researchers from JD Technology and Tsinghua University developed Discriminator-Weighted Behavioral Cloning (DWBC), an offline imitation learning algorithm that learns effective policies from mixed expert and suboptimal demonstrations without online interaction or explicit annotations. DWBC significantly outperformed baselines on most robotic locomotion and manipulation tasks, often achieving expert-level performance, while being computationally efficient.
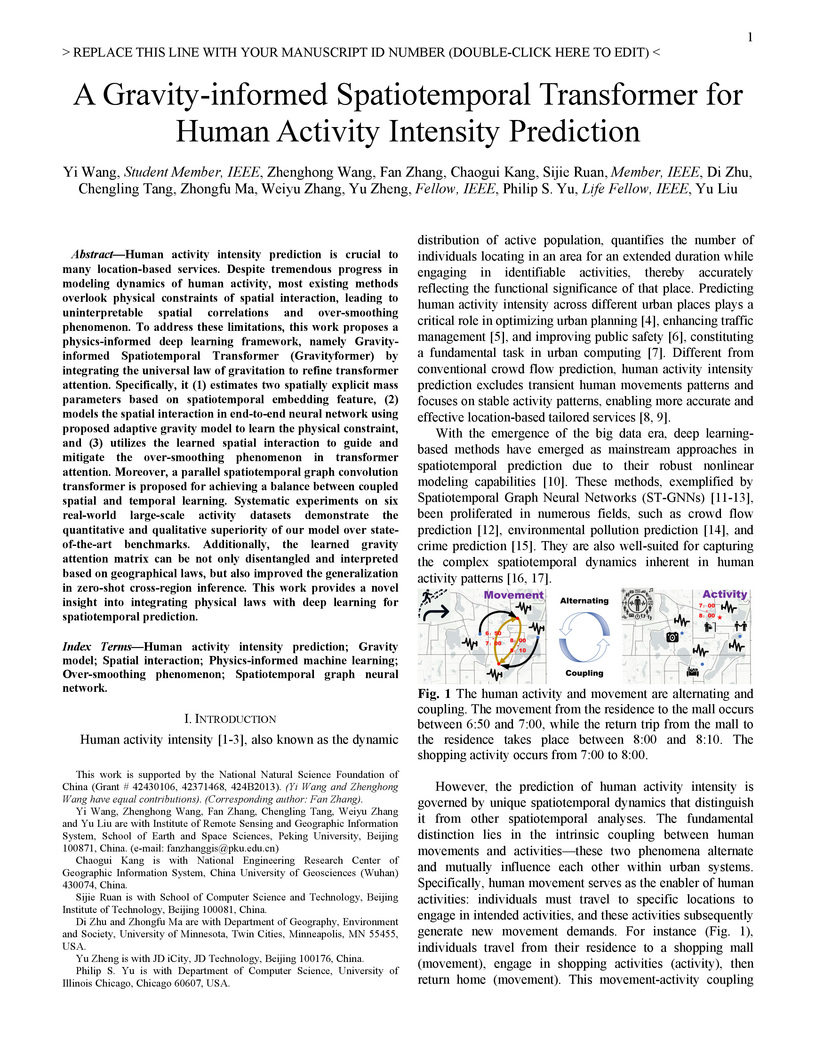
24 Oct 2025

Human activity intensity prediction is crucial to many location-based services. Despite tremendous progress in modeling dynamics of human activity, most existing methods overlook physical constraints of spatial interaction, leading to uninterpretable spatial correlations and over-smoothing phenomenon. To address these limitations, this work proposes a physics-informed deep learning framework, namely Gravity-informed Spatiotemporal Transformer (Gravityformer) by integrating the universal law of gravitation to refine transformer attention. Specifically, it (1) estimates two spatially explicit mass parameters based on spatiotemporal embedding feature, (2) models the spatial interaction in end-to-end neural network using proposed adaptive gravity model to learn the physical constraint, and (3) utilizes the learned spatial interaction to guide and mitigate the over-smoothing phenomenon in transformer attention. Moreover, a parallel spatiotemporal graph convolution transformer is proposed for achieving a balance between coupled spatial and temporal learning. Systematic experiments on six real-world large-scale activity datasets demonstrate the quantitative and qualitative superiority of our model over state-of-the-art benchmarks. Additionally, the learned gravity attention matrix can be not only disentangled and interpreted based on geographical laws, but also improved the generalization in zero-shot cross-region inference. This work provides a novel insight into integrating physical laws with deep learning for spatiotemporal prediction.

10 Jan 2023

Offline imitation learning (IL) is a powerful method to solve decision-making
problems from expert demonstrations without reward labels. Existing offline IL
methods suffer from severe performance degeneration under limited expert data.
Including a learned dynamics model can potentially improve the state-action
space coverage of expert data, however, it also faces challenging issues like
model approximation/generalization errors and suboptimality of rollout data. In
this paper, we propose the Discriminator-guided Model-based offline Imitation
Learning (DMIL) framework, which introduces a discriminator to simultaneously
distinguish the dynamics correctness and suboptimality of model rollout data
against real expert demonstrations. DMIL adopts a novel
cooperative-yet-adversarial learning strategy, which uses the discriminator to
guide and couple the learning process of the policy and dynamics model,
resulting in improved model performance and robustness. Our framework can also
be extended to the case when demonstrations contain a large proportion of
suboptimal data. Experimental results show that DMIL and its extension achieve
superior performance and robustness compared to state-of-the-art offline IL
methods under small datasets.

14 Oct 2021
Most prior approaches to offline reinforcement learning (RL) utilize \textit{behavior regularization}, typically augmenting existing off-policy actor critic algorithms with a penalty measuring divergence between the policy and the offline data. However, these approaches lack guaranteed performance improvement over the behavior policy. In this work, we start from the performance difference between the learned policy and the behavior policy, we derive a new policy learning objective that can be used in the offline setting, which corresponds to the advantage function value of the behavior policy, multiplying by a state-marginal density ratio. We propose a practical way to compute the density ratio and demonstrate its equivalence to a state-dependent behavior regularization. Unlike state-independent regularization used in prior approaches, this \textit{soft} regularization allows more freedom of policy deviation at high confidence states, leading to better performance and stability. We thus term our resulting algorithm Soft Behavior-regularized Actor Critic (SBAC). Our experimental results show that SBAC matches or outperforms the state-of-the-art on a set of continuous control locomotion and manipulation tasks.

12 Jul 2022


Data insufficiency problems (i.e., data missing and label scarcity) caused by inadequate services and infrastructures or imbalanced development levels of cities have seriously affected the urban computing tasks in real scenarios. Prior transfer learning methods inspire an elegant solution to the data insufficiency, but are only concerned with one kind of insufficiency issue and fail to give consideration to both sides. In addition, most previous cross-city transfer methods overlook inter-city data privacy which is a public concern in practical applications. To address the above challenging problems, we propose a novel Cross-city Federated Transfer Learning framework (CcFTL) to cope with the data insufficiency and privacy problems. Concretely, CcFTL transfers the relational knowledge from multiple rich-data source cities to the target city. Besides, the model parameters specific to the target task are firstly trained on the source data and then fine-tuned to the target city by parameter transfer. With our adaptation of federated training and homomorphic encryption settings, CcFTL can effectively deal with the data privacy problem among cities. We take the urban region profiling as an application of smart cities and evaluate the proposed method with a real-world study. The experiments demonstrate the notable superiority of our framework over several competitive state-of-the-art methods.

07 Sep 2021

We consider adversarial attacks to a black-box model when no queries are
allowed. In this setting, many methods directly attack surrogate models and
transfer the obtained adversarial examples to fool the target model. Plenty of
previous works investigated what kind of attacks to the surrogate model can
generate more transferable adversarial examples, but their performances are
still limited due to the mismatches between surrogate models and the target
model. In this paper, we tackle this problem from a novel angle -- instead of
using the original surrogate models, can we obtain a Meta-Surrogate Model (MSM)
such that attacks to this model can be easier transferred to other models? We
show that this goal can be mathematically formulated as a well-posed
(bi-level-like) optimization problem and design a differentiable attacker to
make training feasible. Given one or a set of surrogate models, our method can
thus obtain an MSM such that adversarial examples generated on MSM enjoy
eximious transferability. Comprehensive experiments on Cifar-10 and ImageNet
demonstrate that by attacking the MSM, we can obtain stronger transferable
adversarial examples to fool black-box models including adversarially trained
ones, with much higher success rates than existing methods. The proposed method
reveals significant security challenges of deep models and is promising to be
served as a state-of-the-art benchmark for evaluating the robustness of deep
models in the black-box setting.

14 Apr 2023


In the field of artificial intelligence for science, it is consistently an essential challenge to face a limited amount of labeled data for real-world problems. The prevailing approach is to pretrain a powerful task-agnostic model on a large unlabeled corpus but may struggle to transfer knowledge to downstream tasks. In this study, we propose InstructMol, a semi-supervised learning algorithm, to take better advantage of unlabeled examples. It introduces an instructor model to provide the confidence ratios as the measurement of pseudo-labels' reliability. These confidence scores then guide the target model to pay distinct attention to different data points, avoiding the over-reliance on labeled data and the negative influence of incorrect pseudo-annotations. Comprehensive experiments show that InstructBio substantially improves the generalization ability of molecular models, in not only molecular property predictions but also activity cliff estimations, demonstrating the superiority of the proposed method. Furthermore, our evidence indicates that InstructBio can be equipped with cutting-edge pretraining methods and used to establish large-scale and task-specific pseudo-labeled molecular datasets, which reduces the predictive errors and shortens the training process. Our work provides strong evidence that semi-supervised learning can be a promising tool to overcome the data scarcity limitation and advance molecular representation learning.

03 Dec 2024
Uplift modeling comprises a collection of machine learning techniques
designed for managers to predict the incremental impact of specific actions on
customer outcomes. However, accurately estimating this incremental impact poses
significant challenges due to the necessity of determining the difference
between two mutually exclusive outcomes for each individual. In our study, we
introduce two novel modifications to the established Gradient Boosting Decision
Trees (GBDT) technique. These modifications sequentially learn the causal
effect, addressing the counterfactual dilemma. Each modification innovates upon
the existing technique in terms of the ensemble learning method and the
learning objective, respectively. Experiments with large-scale datasets
validate the effectiveness of our methods, consistently achieving substantial
improvements over baseline models.

28 Jan 2023
Offline safe RL is of great practical relevance for deploying agents in real-world applications. However, acquiring constraint-satisfying policies from the fixed dataset is non-trivial for conventional approaches. Even worse, the learned constraints are stationary and may become invalid when the online safety requirement changes. In this paper, we present a novel offline safe RL approach referred to as SaFormer, which tackles the above issues via conditional sequence modeling. In contrast to existing sequence models, we propose cost-related tokens to restrict the action space and a posterior safety verification to enforce the constraint explicitly. Specifically, SaFormer performs a two-stage auto-regression conditioned by the maximum remaining cost to generate feasible candidates. It then filters out unsafe attempts and executes the optimal action with the highest expected return. Extensive experiments demonstrate the efficacy of SaFormer featuring (1) competitive returns with tightened constraint satisfaction; (2) adaptability to the in-range cost values of the offline data without retraining; (3) generalizability for constraints beyond the current dataset.
There are no more papers matching your filters at the moment.
