
23 Oct 2020
HiFi-GAN introduces a Generative Adversarial Network architecture that achieves high-fidelity speech synthesis while maintaining high computational efficiency. It leverages a novel Multi-Period Discriminator and an improved Multi-Receptive Field generator to produce near human-quality audio at hundreds to thousands of times faster than real-time on GPU and over 13 times faster on CPU, significantly advancing the state of the art in vocoder performance.

11 Jun 2021

VITS, developed by Kakao Enterprise and KAIST, introduces an end-to-end text-to-speech model that integrates conditional VAEs, normalizing flows, and adversarial training to produce highly natural speech. The model achieves a Mean Opinion Score (MOS) of 4.37, comparable to ground truth recordings, and generates diverse speech rhythms through its stochastic duration predictor.

10 Jun 2021


Researchers from Kakao Enterprise and Kakao Brain introduce ViLT, a Vision-and-Language Transformer that processes visual inputs directly from image patches, bypassing traditional convolutional networks or region supervision. This architecture achieves an order of magnitude faster inference while maintaining competitive performance across various vision-and-language tasks like visual question answering and image-text retrieval.

23 Oct 2020

Recently, text-to-speech (TTS) models such as FastSpeech and ParaNet have been proposed to generate mel-spectrograms from text in parallel. Despite the advantage, the parallel TTS models cannot be trained without guidance from autoregressive TTS models as their external aligners. In this work, we propose Glow-TTS, a flow-based generative model for parallel TTS that does not require any external aligner. By combining the properties of flows and dynamic programming, the proposed model searches for the most probable monotonic alignment between text and the latent representation of speech on its own. We demonstrate that enforcing hard monotonic alignments enables robust TTS, which generalizes to long utterances, and employing generative flows enables fast, diverse, and controllable speech synthesis. Glow-TTS obtains an order-of-magnitude speed-up over the autoregressive model, Tacotron 2, at synthesis with comparable speech quality. We further show that our model can be easily extended to a multi-speaker setting.

21 Nov 2022

Recently, diffusion models have shown remarkable results in image synthesis by gradually removing noise and amplifying signals. Although the simple generative process surprisingly works well, is this the best way to generate image data? For instance, despite the fact that human perception is more sensitive to the low frequencies of an image, diffusion models themselves do not consider any relative importance of each frequency component. Therefore, to incorporate the inductive bias for image data, we propose a novel generative process that synthesizes images in a coarse-to-fine manner. First, we generalize the standard diffusion models by enabling diffusion in a rotated coordinate system with different velocities for each component of the vector. We further propose a blur diffusion as a special case, where each frequency component of an image is diffused at different speeds. Specifically, the proposed blur diffusion consists of a forward process that blurs an image and adds noise gradually, after which a corresponding reverse process deblurs an image and removes noise progressively. Experiments show that the proposed model outperforms the previous method in FID on LSUN bedroom and church datasets. Code is available at this https URL.

08 Apr 2022
Researchers at Kakao Enterprise's AI Lab demonstrated the superior performance of self-supervised learning (SSL) models, specifically fine-tuned HuBERT Large, for automatic pronunciation assessment. Their method achieved a state-of-the-art Pearson Correlation Coefficient of 0.82 for holistic pronunciation scores on the KESL dataset, significantly outperforming traditional and other deep learning baselines.

07 Dec 2022
In image classification, "debiasing" aims to train a classifier to be less susceptible to dataset bias, the strong correlation between peripheral attributes of data samples and a target class. For example, even if the frog class in the dataset mainly consists of frog images with a swamp background (i.e., bias-aligned samples), a debiased classifier should be able to correctly classify a frog at a beach (i.e., bias-conflicting samples). Recent debiasing approaches commonly use two components for debiasing, a biased model and a debiased model . is trained to focus on bias-aligned samples (i.e., overfitted to the bias) while is mainly trained with bias-conflicting samples by concentrating on samples which fails to learn, leading to be less susceptible to the dataset bias. While the state-of-the-art debiasing techniques have aimed to better train , we focus on training , an overlooked component until now. Our empirical analysis reveals that removing the bias-conflicting samples from the training set for is important for improving the debiasing performance of . This is due to the fact that the bias-conflicting samples work as noisy samples for amplifying the bias for since those samples do not include the bias attribute. To this end, we propose a simple yet effective data sample selection method which removes the bias-conflicting samples to construct a bias-amplified dataset for training . Our data sample selection method can be directly applied to existing reweighting-based debiasing approaches, obtaining consistent performance boost and achieving the state-of-the-art performance on both synthetic and real-world datasets.

04 Sep 2023
Despite recent advancements in deep learning, deep neural networks continue
to suffer from performance degradation when applied to new data that differs
from training data. Test-time adaptation (TTA) aims to address this challenge
by adapting a model to unlabeled data at test time. TTA can be applied to
pretrained networks without modifying their training procedures, enabling them
to utilize a well-formed source distribution for adaptation. One possible
approach is to align the representation space of test samples to the source
distribution (\textit{i.e.,} feature alignment). However, performing feature
alignment in TTA is especially challenging in that access to labeled source
data is restricted during adaptation. That is, a model does not have a chance
to learn test data in a class-discriminative manner, which was feasible in
other adaptation tasks (\textit{e.g.,} unsupervised domain adaptation) via
supervised losses on the source data. Based on this observation, we propose a
simple yet effective feature alignment loss, termed as Class-Aware Feature
Alignment (CAFA), which simultaneously 1) encourages a model to learn target
representations in a class-discriminative manner and 2) effectively mitigates
the distribution shifts at test time. Our method does not require any
hyper-parameters or additional losses, which are required in previous
approaches. We conduct extensive experiments on 6 different datasets and show
our proposed method consistently outperforms existing baselines.

17 Jun 2022
Hairstyle transfer is the task of modifying a source hairstyle to a target one. Although recent hairstyle transfer models can reflect the delicate features of hairstyles, they still have two major limitations. First, the existing methods fail to transfer hairstyles when a source and a target image have different poses (e.g., viewing direction or face size), which is prevalent in the real world. Also, the previous models generate unrealistic images when there is a non-trivial amount of regions in the source image occluded by its original hair. When modifying long hair to short hair, shoulders or backgrounds occluded by the long hair need to be inpainted. To address these issues, we propose a novel framework for pose-invariant hairstyle transfer, HairFIT. Our model consists of two stages: 1) flow-based hair alignment and 2) hair synthesis. In the hair alignment stage, we leverage a keypoint-based optical flow estimator to align a target hairstyle with a source pose. Then, we generate a final hairstyle-transferred image in the hair synthesis stage based on Semantic-region-aware Inpainting Mask (SIM) estimator. Our SIM estimator divides the occluded regions in the source image into different semantic regions to reflect their distinct features during the inpainting. To demonstrate the effectiveness of our model, we conduct quantitative and qualitative evaluations using multi-view datasets, K-hairstyle and VoxCeleb. The results indicate that HairFIT achieves a state-of-the-art performance by successfully transferring hairstyles between images of different poses, which has never been achieved before.
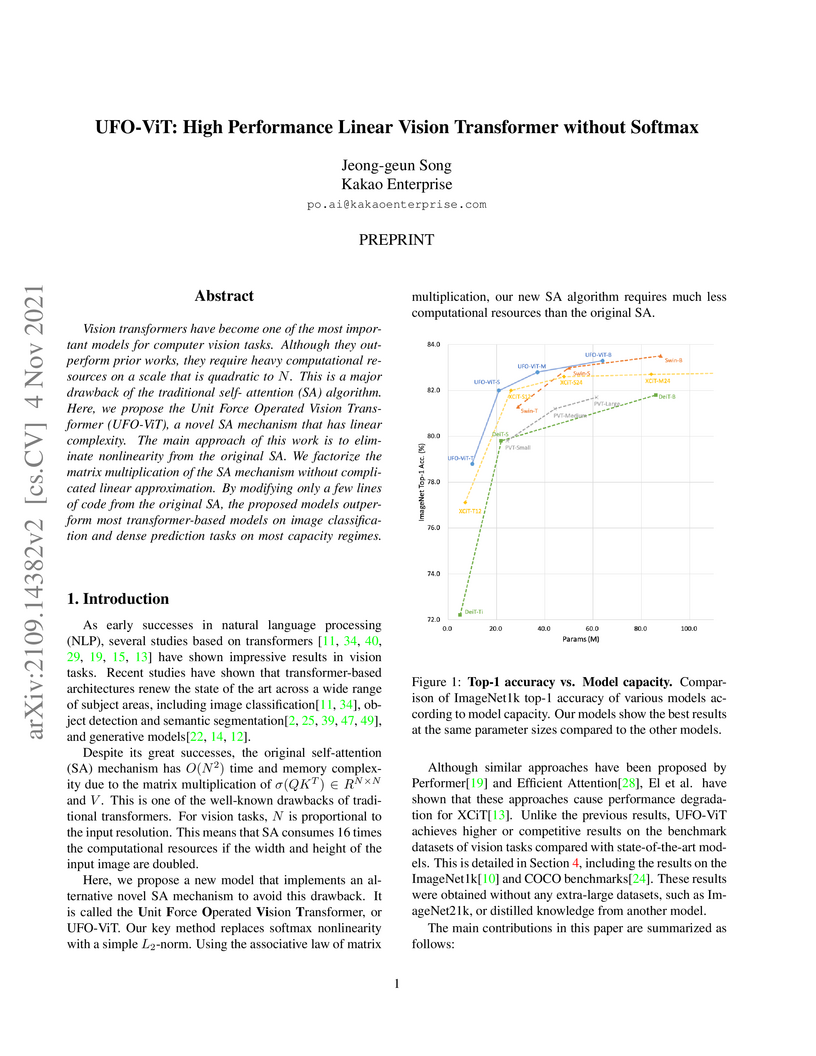
04 Nov 2021
Vision transformers have become one of the most important models for computer vision tasks. Although they outperform prior works, they require heavy computational resources on a scale that is quadratic to . This is a major drawback of the traditional self-attention (SA) algorithm. Here, we propose the Unit Force Operated Vision Transformer (UFO-ViT), a novel SA mechanism that has linear complexity. The main approach of this work is to eliminate nonlinearity from the original SA. We factorize the matrix multiplication of the SA mechanism without complicated linear approximation. By modifying only a few lines of code from the original SA, the proposed models outperform most transformer-based models on image classification and dense prediction tasks on most capacity regimes.

09 Sep 2020
Mutual learning is an ensemble training strategy to improve generalization by
transferring individual knowledge to each other while simultaneously training
multiple models. In this work, we propose an effective mutual learning method
for deep metric learning, called Diversified Mutual Metric Learning, which
enhances embedding models with diversified mutual learning. We transfer
relational knowledge for deep metric learning by leveraging three kinds of
diversities in mutual learning: (1) model diversity from different
initializations of models, (2) temporal diversity from different frequencies of
parameter update, and (3) view diversity from different augmentations of
inputs. Our method is particularly adequate for inductive transfer learning at
the lack of large-scale data, where the embedding model is initialized with a
pretrained model and then fine-tuned on a target dataset. Extensive experiments
show that our method significantly improves individual models as well as their
ensemble. Finally, the proposed method with a conventional triplet loss
achieves the state-of-the-art performance of Recall@1 on standard datasets:
69.9 on CUB-200-2011 and 89.1 on CARS-196.

11 Aug 2022
Due to the curse of statistical heterogeneity across clients, adopting a
personalized federated learning method has become an essential choice for the
successful deployment of federated learning-based services. Among diverse
branches of personalization techniques, a model mixture-based personalization
method is preferred as each client has their own personalized model as a result
of federated learning. It usually requires a local model and a federated model,
but this approach is either limited to partial parameter exchange or requires
additional local updates, each of which is helpless to novel clients and
burdensome to the client's computational capacity. As the existence of a
connected subspace containing diverse low-loss solutions between two or more
independent deep networks has been discovered, we combined this interesting
property with the model mixture-based personalized federated learning method
for improved performance of personalization. We proposed SuPerFed, a
personalized federated learning method that induces an explicit connection
between the optima of the local and the federated model in weight space for
boosting each other. Through extensive experiments on several benchmark
datasets, we demonstrated that our method achieves consistent gains in both
personalization performance and robustness to problematic scenarios possible in
realistic services.

13 Oct 2022


Recent work on tokenizer-free multilingual pretrained models show promising
results in improving cross-lingual transfer and reducing engineering overhead
(Clark et al., 2022; Xue et al., 2022). However, these works mainly focus on
reporting accuracy on a limited set of tasks and data settings, placing less
emphasis on other important factors when tuning and deploying the models in
practice, such as memory usage, inference speed, and fine-tuning data
robustness. We attempt to fill this gap by performing a comprehensive empirical
comparison of multilingual tokenizer-free and subword-based models considering
these various dimensions. Surprisingly, we find that subword-based models might
still be the most practical choice in many settings, achieving better
performance for lower inference latency and memory usage. Based on these
results, we encourage future work in tokenizer-free methods to consider these
factors when designing and evaluating new models.

02 Dec 2020
Face anti-spoofing aims to prevent false authentications of face recognition systems by distinguishing whether an image is originated from a human face or a spoof medium. We propose a novel method called Doubly Adversarial Suppression Network (DASN) for domain-agnostic face anti-spoofing; DASN improves the generalization ability to unseen domains by learning to effectively suppress spoof-irrelevant factors (SiFs) (e.g., camera sensors, illuminations). To achieve our goal, we introduce two types of adversarial learning schemes. In the first adversarial learning scheme, multiple SiFs are suppressed by deploying multiple discrimination heads that are trained against an encoder. In the second adversarial learning scheme, each of the discrimination heads is also adversarially trained to suppress a spoof factor, and the group of the secondary spoof classifier and the encoder aims to intensify the spoof factor by overcoming the suppression. We evaluate the proposed method on four public benchmark datasets, and achieve remarkable evaluation results. The results demonstrate the effectiveness of the proposed method.

13 Apr 2020
This paper attempts to analyze the Korean sentence classification system for
a chatbot. Sentence classification is the task of classifying an input sentence
based on predefined categories. However, spelling or space error contained in
the input sentence causes problems in morphological analysis and tokenization.
This paper proposes a novel approach of Integrated Eojeol (Korean syntactic
word separated by space) Embedding to reduce the effect that poorly analyzed
morphemes may make on sentence classification. It also proposes two noise
insertion methods that further improve classification performance. Our
evaluation results indicate that the proposed system classifies erroneous
sentences more accurately than the baseline system by 17%p.0

19 Oct 2020
The complete sharing of parameters for multilingual translation (1-1) has
been the mainstream approach in current research. However, degraded performance
due to the capacity bottleneck and low maintainability hinders its extensive
adoption in industries. In this study, we revisit the multilingual neural
machine translation model that only share modules among the same languages (M2)
as a practical alternative to 1-1 to satisfy industrial requirements. Through
comprehensive experiments, we identify the benefits of multi-way training and
demonstrate that the M2 can enjoy these benefits without suffering from the
capacity bottleneck. Furthermore, the interlingual space of the M2 allows
convenient modification of the model. By leveraging trained modules, we find
that incrementally added modules exhibit better performance than singly trained
models. The zero-shot performance of the added modules is even comparable to
supervised models. Our findings suggest that the M2 can be a competent
candidate for multilingual translation in industries.

08 Feb 2021
We propose a novel distance-based regularization method for deep metric learning called Multi-level Distance Regularization (MDR). MDR explicitly disturbs a learning procedure by regularizing pairwise distances between embedding vectors into multiple levels that represents a degree of similarity between a pair. In the training stage, the model is trained with both MDR and an existing loss function of deep metric learning, simultaneously; the two losses interfere with the objective of each other, and it makes the learning process difficult. Moreover, MDR prevents some examples from being ignored or overly influenced in the learning process. These allow the parameters of the embedding network to be settle on a local optima with better generalization. Without bells and whistles, MDR with simple Triplet loss achieves the-state-of-the-art performance in various benchmark datasets: CUB-200-2011, Cars-196, Stanford Online Products, and In-Shop Clothes Retrieval. We extensively perform ablation studies on its behaviors to show the effectiveness of MDR. By easily adopting our MDR, the previous approaches can be improved in performance and generalization ability.

14 Sep 2021
Non-autoregressive neural machine translation (NART) models suffer from the
multi-modality problem which causes translation inconsistency such as token
repetition. Most recent approaches have attempted to solve this problem by
implicitly modeling dependencies between outputs. In this paper, we introduce
AligNART, which leverages full alignment information to explicitly reduce the
modality of the target distribution. AligNART divides the machine translation
task into alignment estimation and translation with aligned
decoder inputs, guiding the decoder to focus on simplified one-to-one
translation. To alleviate the alignment estimation problem, we further propose
a novel alignment decomposition method. Our experiments show that AligNART
outperforms previous non-iterative NART models that focus on explicit modality
reduction on WMT14 EnDe and WMT16 RoEn.
Furthermore, AligNART achieves BLEU scores comparable to those of the
state-of-the-art connectionist temporal classification based models on WMT14
EnDe. We also observe that AligNART effectively addresses the
token repetition problem even without sequence-level knowledge distillation.

25 Oct 2021
Image classification models tend to make decisions based on peripheral attributes of data items that have strong correlation with a target variable (i.e., dataset bias). These biased models suffer from the poor generalization capability when evaluated on unbiased datasets. Existing approaches for debiasing often identify and emphasize those samples with no such correlation (i.e., bias-conflicting) without defining the bias type in advance. However, such bias-conflicting samples are significantly scarce in biased datasets, limiting the debiasing capability of these approaches. This paper first presents an empirical analysis revealing that training with "diverse" bias-conflicting samples beyond a given training set is crucial for debiasing as well as the generalization capability. Based on this observation, we propose a novel feature-level data augmentation technique in order to synthesize diverse bias-conflicting samples. To this end, our method learns the disentangled representation of (1) the intrinsic attributes (i.e., those inherently defining a certain class) and (2) bias attributes (i.e., peripheral attributes causing the bias), from a large number of bias-aligned samples, the bias attributes of which have strong correlation with the target variable. Using the disentangled representation, we synthesize bias-conflicting samples that contain the diverse intrinsic attributes of bias-aligned samples by swapping their latent features. By utilizing these diversified bias-conflicting features during the training, our approach achieves superior classification accuracy and debiasing results against the existing baselines on synthetic and real-world datasets.

18 Dec 2021
This paper presents our work on the Situated Interactive MultiModal Conversations 2.0 challenge held at Dialog State Tracking Challenge 10. SIMMC 2.0 includes 4 subtasks, and we introduce our multimodal approaches for the subtask \#1, \#2 and the generation of subtask \#4. SIMMC 2.0 dataset is a multimodal dataset containing image and text information, which is more challenging than the problem of only text-based conversations because it must be solved by understanding the relationship between image and text. Therefore, since there is a limit to solving only text models such as BERT or GPT2, we propose a multimodal model combining image and text. We first pretrain the multimodal model to understand the relationship between image and text, then finetune our model for each task. We achieve the 3rd best performance in subtask \#1, \#2 and a runner-up in the generation of subtask \#4. The source code is available at this https URL.
There are no more papers matching your filters at the moment.
