
29 May 2025
This paper introduces the Combinatorial Rising Bandit (CRB) framework to model online decision-making with combinatorial actions and improving rewards, where base arms can be shared across multiple super arms. The proposed Combinatorial Rising Upper Confidence Bound (CRUCB) algorithm achieves near-optimal regret bounds and outperforms existing methods in synthetic tasks and deep reinforcement learning navigation problems.

04 Dec 2024




We present the first circularly polarized Floquet engineering time-resolved Resonant Inelastic X-ray Scattering (tr-RIXS) experiment in HLiIrO, an iridium-based Kitaev system. Our calculations and experimental results are consistent with the modification of the low energy magnetic excitations in HLiIrO only during illumination by the laser pulse, consistent with the Floquet engineering of the exchange interactions. However, the penetration length mismatch between the X-ray probe and laser pump and the intrinsic complexity of Kitaev magnets prevented us from unequivocally extracting towards which ground HLiIrO was driven. We outline possible solutions to these challenges for Floquet stabilization and observation of the Kitaev Quantum Spin Liquid limit by RIXS.

09 Mar 2022
This paper from POSTECH and Kakao Brain presents a novel autoregressive image generation framework using Residual Quantization (RQ-VAE) and an RQ-Transformer. The approach enables efficient and high-fidelity image synthesis by creating compact, precise discrete representations, leading to state-of-the-art performance on various benchmarks with significantly faster sampling speeds compared to prior autoregressive models.

20 Dec 2024





This paper introduces a method to align DINOv2's visual features with text for both image-level and pixel-level tasks

22 Sep 2025
In this paper, we propose VideoFrom3D, a novel framework for synthesizing high-quality 3D scene videos from coarse geometry, a camera trajectory, and a reference image. Our approach streamlines the 3D graphic design workflow, enabling flexible design exploration and rapid production of deliverables. A straightforward approach to synthesizing a video from coarse geometry might condition a video diffusion model on geometric structure. However, existing video diffusion models struggle to generate high-fidelity results for complex scenes due to the difficulty of jointly modeling visual quality, motion, and temporal consistency. To address this, we propose a generative framework that leverages the complementary strengths of image and video diffusion models. Specifically, our framework consists of a Sparse Anchor-view Generation (SAG) and a Geometry-guided Generative Inbetweening (GGI) module. The SAG module generates high-quality, cross-view consistent anchor views using an image diffusion model, aided by Sparse Appearance-guided Sampling. Building on these anchor views, GGI module faithfully interpolates intermediate frames using a video diffusion model, enhanced by flow-based camera control and structural guidance. Notably, both modules operate without any paired dataset of 3D scene models and natural images, which is extremely difficult to obtain. Comprehensive experiments show that our method produces high-quality, style-consistent scene videos under diverse and challenging scenarios, outperforming simple and extended baselines.

26 May 2019

The Set Transformer introduces a deep learning architecture designed to process set-structured data by employing attention mechanisms to model inter-element interactions while maintaining permutation invariance. It achieves improved performance on tasks such as amortized clustering and point cloud classification, facilitated by the efficient Induced Set Attention Block (ISAB) and flexible Pooling by Multihead Attention (PMA).
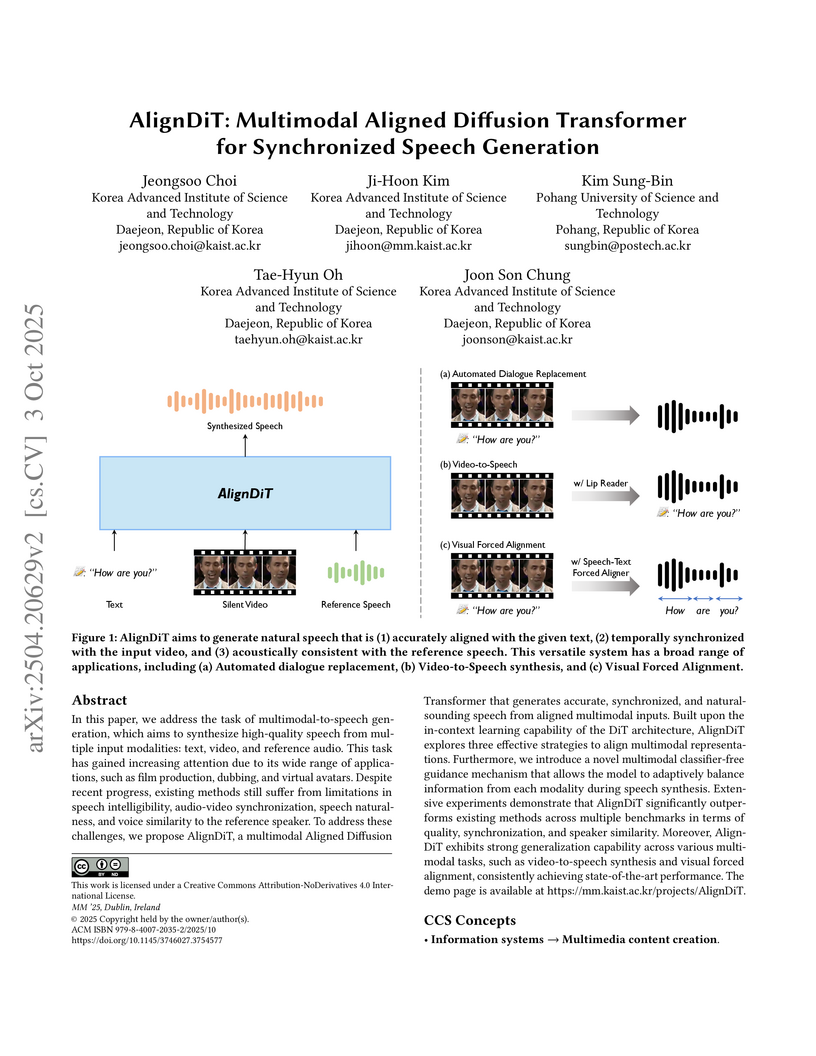
03 Oct 2025

In this paper, we address the task of multimodal-to-speech generation, which aims to synthesize high-quality speech from multiple input modalities: text, video, and reference audio. This task has gained increasing attention due to its wide range of applications, such as film production, dubbing, and virtual avatars. Despite recent progress, existing methods still suffer from limitations in speech intelligibility, audio-video synchronization, speech naturalness, and voice similarity to the reference speaker. To address these challenges, we propose AlignDiT, a multimodal Aligned Diffusion Transformer that generates accurate, synchronized, and natural-sounding speech from aligned multimodal inputs. Built upon the in-context learning capability of the DiT architecture, AlignDiT explores three effective strategies to align multimodal representations. Furthermore, we introduce a novel multimodal classifier-free guidance mechanism that allows the model to adaptively balance information from each modality during speech synthesis. Extensive experiments demonstrate that AlignDiT significantly outperforms existing methods across multiple benchmarks in terms of quality, synchronization, and speaker similarity. Moreover, AlignDiT exhibits strong generalization capability across various multimodal tasks, such as video-to-speech synthesis and visual forced alignment, consistently achieving state-of-the-art performance. The demo page is available at this https URL.

03 Apr 2025

VoiceCraft-Dub extends Neural Codec Language Models to incorporate visual information, enabling automated video dubbing that generates high-quality speech synchronized with lip movements and preserving emotional expressiveness. Human evaluations show it outperforms existing methods in perceived naturalness and lip synchronization.
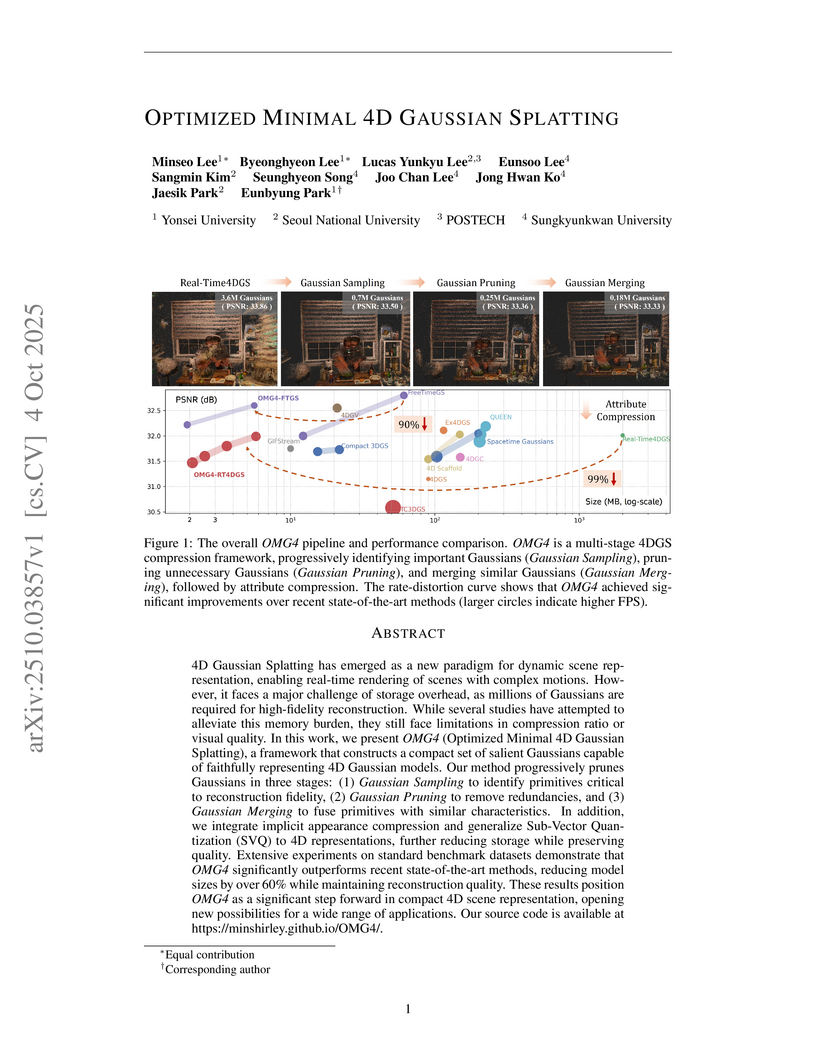
04 Oct 2025

OMG4 (Optimized Minimal 4D Gaussian Splatting) introduces a framework that dramatically reduces the memory footprint of 4D Gaussian Splatting models, enabling up to a 99% storage reduction from gigabytes to a few megabytes. This approach, developed by researchers from Yonsei University, Seoul National University, POSTECH, and Sungkyunkwan University, maintains or improves visual fidelity and significantly boosts rendering frame rates on dynamic scenes, making these models more practical for real-world applications.

02 Aug 2025
Image tokenizers form the foundation of modern text-to-image generative models but are notoriously difficult to train. Furthermore, most existing text-to-image models rely on large-scale, high-quality private datasets, making them challenging to replicate. In this work, we introduce Text-Aware Transformer-based 1-Dimensional Tokenizer (TA-TiTok), an efficient and powerful image tokenizer that can utilize either discrete or continuous 1-dimensional tokens. TA-TiTok uniquely integrates textual information during the tokenizer decoding stage (i.e., de-tokenization), accelerating convergence and enhancing performance. TA-TiTok also benefits from a simplified, yet effective, one-stage training process, eliminating the need for the complex two-stage distillation used in previous 1-dimensional tokenizers. This design allows for seamless scalability to large datasets. Building on this, we introduce a family of text-to-image Masked Generative Models (MaskGen), trained exclusively on open data while achieving comparable performance to models trained on private data. We aim to release both the efficient, strong TA-TiTok tokenizers and the open-data, open-weight MaskGen models to promote broader access and democratize the field of text-to-image masked generative models.

01 Oct 2025
A new framework, Contextualized Structured Radiology Report Generation (C-SRRG), integrates diverse clinical context such as multi-view images and prior studies into automated report creation. This method improves the quality of structured radiology reports and substantially mitigates temporal hallucinations in generated text.

19 Oct 2025
Generate, but Verify: Reducing Hallucination in Vision-Language Models with Retrospective Resampling
Generate, but Verify: Reducing Hallucination in Vision-Language Models with Retrospective Resampling

Vision-Language Models (VLMs) excel at visual understanding but often suffer from visual hallucinations, where they generate descriptions of nonexistent objects, actions, or concepts, posing significant risks in safety-critical applications. Existing hallucination mitigation methods typically follow one of two paradigms: generation adjustment, which modifies decoding behavior to align text with visual inputs, and post-hoc verification, where external models assess and correct outputs. While effective, generation adjustment methods often rely on heuristics and lack correction mechanisms, while post-hoc verification is complicated, typically requiring multiple models and tending to reject outputs rather than refine them. In this work, we introduce REVERSE, a unified framework that integrates hallucination-aware training with on-the-fly self-verification. By leveraging a new hallucination-verification dataset containing over 1.3M semi-synthetic samples, along with a novel inference-time retrospective resampling technique, our approach enables VLMs to both detect hallucinations during generation and dynamically revise those hallucinations. Our evaluations show that REVERSE achieves state-of-the-art hallucination reduction, outperforming the best existing methods by up to 12% on CHAIR-MSCOCO and 34% on HaloQuest. Our dataset, model, and code are available at: this https URL.

19 Sep 2025
We propose Camera Splatting, a novel view optimization framework for novel view synthesis. Each camera is modeled as a 3D Gaussian, referred to as a camera splat, and virtual cameras, termed point cameras, are placed at 3D points sampled near the surface to observe the distribution of camera splats. View optimization is achieved by continuously and differentiably refining the camera splats so that desirable target distributions are observed from the point cameras, in a manner similar to the original 3D Gaussian splatting. Compared to the Farthest View Sampling (FVS) approach, our optimized views demonstrate superior performance in capturing complex view-dependent phenomena, including intense metallic reflections and intricate textures such as text.

04 Oct 2024

CushionCache, developed by researchers from POSTECH and Google, introduces a learned prefix to Large Language Models that acts as an attention sink, effectively mitigating activation outliers. This strategy enables high-quality per-tensor static activation quantization, achieving substantial improvements in accuracy and perplexity for various LLMs.

17 Mar 2025

Following the success of Large Language Models (LLMs), expanding their
boundaries to new modalities represents a significant paradigm shift in
multimodal understanding. Human perception is inherently multimodal, relying
not only on text but also on auditory and visual cues for a complete
understanding of the world. In recognition of this fact, audio-visual LLMs have
recently emerged. Despite promising developments, the lack of dedicated
benchmarks poses challenges for understanding and evaluating models. In this
work, we show that audio-visual LLMs struggle to discern subtle relationships
between audio and visual signals, leading to hallucinations and highlighting
the need for reliable benchmarks. To address this, we introduce AVHBench, the
first comprehensive benchmark specifically designed to evaluate the perception
and comprehension capabilities of audio-visual LLMs. Our benchmark includes
tests for assessing hallucinations, as well as the cross-modal matching and
reasoning abilities of these models. Our results reveal that most existing
audio-visual LLMs struggle with hallucinations caused by cross-interactions
between modalities, due to their limited capacity to perceive complex
multimodal signals and their relationships. Additionally, we demonstrate that
simple training with our AVHBench improves robustness of audio-visual LLMs
against hallucinations. Dataset: this https URL

19 Oct 2025

A study by Fu et al. from KAUST and POSTECH critically examined data-driven methods for reconstructing hyperspectral images from RGB inputs, revealing that current high benchmark scores mask severe overfitting to datasets and catastrophic failure in distinguishing metameric colors. Their optics-aware analysis demonstrated that incorporating realistic optical aberrations into the image formation model significantly improves spectral reconstruction accuracy by providing learned side-channel cues.

01 May 2019
Relational Knowledge Distillation (RKD) introduces a method to transfer structural relationships among data examples from a teacher to a student model, diverging from conventional individual output matching. This approach enables student models to often surpass their teacher's performance, achieving state-of-the-art results in metric learning and demonstrating strong complementarity with existing knowledge distillation techniques.

08 Oct 2025
Researchers from GIST, Seoul National University, and POSTECH introduce Online Generic Event Boundary Detection (On-GEBD) and the ESTimator model, which uses principles from human cognition to identify taxonomy-free event boundaries in real-time video streams. ESTimator outperforms existing online baselines, achieving an average F1 score of 0.748 on Kinetics-GEBD, and demonstrates strong zero-shot generalization to unseen datasets.
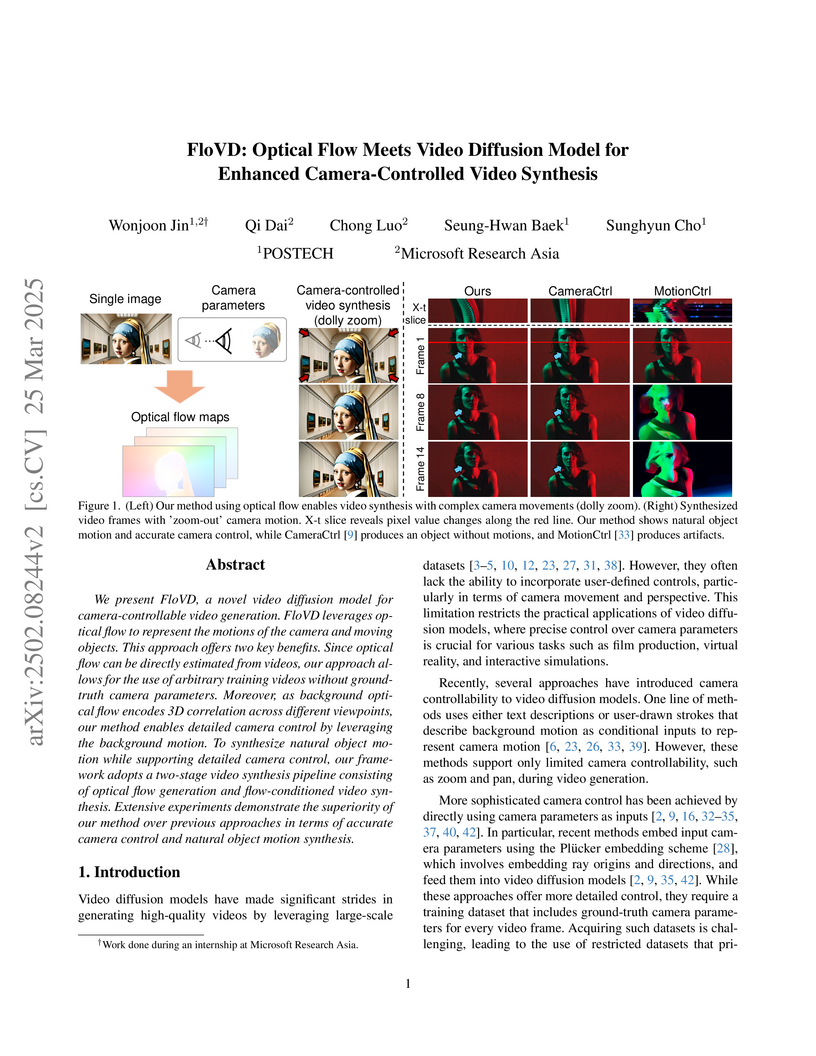
25 Mar 2025
A two-stage video diffusion model, FloVD, synthesizes camera-controlled videos with natural object motions by leveraging optical flow as a unified motion representation, circumventing the reliance on ground-truth camera parameters during training. The approach outperforms previous methods in camera trajectory accuracy on RealEstate10K and yields higher quality videos with dynamic object movements across various Pexels datasets.

10 Oct 2025

Image retouching not only enhances visual quality but also serves as a means of expressing personal preferences and emotions. However, existing learning-based approaches require large-scale paired data and operate as black boxes, making the retouching process opaque and limiting their adaptability to handle diverse, user- or image-specific adjustments. In this work, we propose RetouchLLM, a training-free white-box image retouching system, which requires no training data and performs interpretable, code-based retouching directly on high-resolution images. Our framework progressively enhances the image in a manner similar to how humans perform multi-step retouching, allowing exploration of diverse adjustment paths. It comprises of two main modules: a visual critic that identifies differences between the input and reference images, and a code generator that produces executable codes. Experiments demonstrate that our approach generalizes well across diverse retouching styles, while natural language-based user interaction enables interpretable and controllable adjustments tailored to user intent.
There are no more papers matching your filters at the moment.
