
09 Apr 2024



Multi-view diffusion models, obtained by applying Supervised Finetuning (SFT)
to text-to-image diffusion models, have driven recent breakthroughs in
text-to-3D research. However, due to the limited size and quality of existing
3D datasets, they still suffer from multi-view inconsistencies and Neural
Radiance Field (NeRF) reconstruction artifacts. We argue that multi-view
diffusion models can benefit from further Reinforcement Learning Finetuning
(RLFT), which allows models to learn from the data generated by themselves and
improve beyond their dataset limitations during SFT. To this end, we introduce
Carve3D, an improved RLFT algorithm coupled with a novel Multi-view
Reconstruction Consistency (MRC) metric, to enhance the consistency of
multi-view diffusion models. To measure the MRC metric on a set of multi-view
images, we compare them with their corresponding NeRF renderings at the same
camera viewpoints. The resulting model, which we denote as Carve3DM,
demonstrates superior multi-view consistency and NeRF reconstruction quality
than existing models. Our results suggest that pairing SFT with Carve3D's RLFT
is essential for developing multi-view-consistent diffusion models, mirroring
the standard Large Language Model (LLM) alignment pipeline. Our code, training
and testing data, and video results are available at:
https://desaixie.github.io/carve-3d.

01 Nov 2024
We present LRM-Zero, a Large Reconstruction Model (LRM) trained entirely on synthesized 3D data, achieving high-quality sparse-view 3D reconstruction. The core of LRM-Zero is our procedural 3D dataset, Zeroverse, which is automatically synthesized from simple primitive shapes with random texturing and augmentations (e.g., height fields, boolean differences, and wireframes). Unlike previous 3D datasets (e.g., Objaverse) which are often captured or crafted by humans to approximate real 3D data, Zeroverse completely ignores realistic global semantics but is rich in complex geometric and texture details that are locally similar to or even more intricate than real objects. We demonstrate that our LRM-Zero, trained with our fully synthesized Zeroverse, can achieve high visual quality in the reconstruction of real-world objects, competitive with models trained on Objaverse. We also analyze several critical design choices of Zeroverse that contribute to LRM-Zero's capability and training stability. Our work demonstrates that 3D reconstruction, one of the core tasks in 3D vision, can potentially be addressed without the semantics of real-world objects. The Zeroverse's procedural synthesis code and interactive visualization are available at: this https URL.

27 Nov 2025

We propose a method to reconstruct dynamic fire in 3D from a limited set of camera views with a Gaussian-based spatiotemporal representation. Capturing and reconstructing fire and its dynamics is highly challenging due to its volatile nature, transparent quality, and multitude of high-frequency features. Despite these challenges, we aim to reconstruct fire from only three views, which consequently requires solving for under-constrained geometry. We solve this by separating the static background from the dynamic fire region by combining dense multi-view stereo images with monocular depth priors. The fire is initialized as a 3D flow field, obtained by fusing per-view dense optical flow projections. To capture the high frequency features of fire, each 3D Gaussian encodes a lifetime and linear velocity to match the dense optical flow. To ensure sub-frame temporal alignment across cameras we employ a custom hardware synchronization pattern -- allowing us to reconstruct fire with affordable commodity hardware. Our quantitative and qualitative validations across numerous reconstruction experiments demonstrate robust performance for diverse and challenging real fire scenarios.
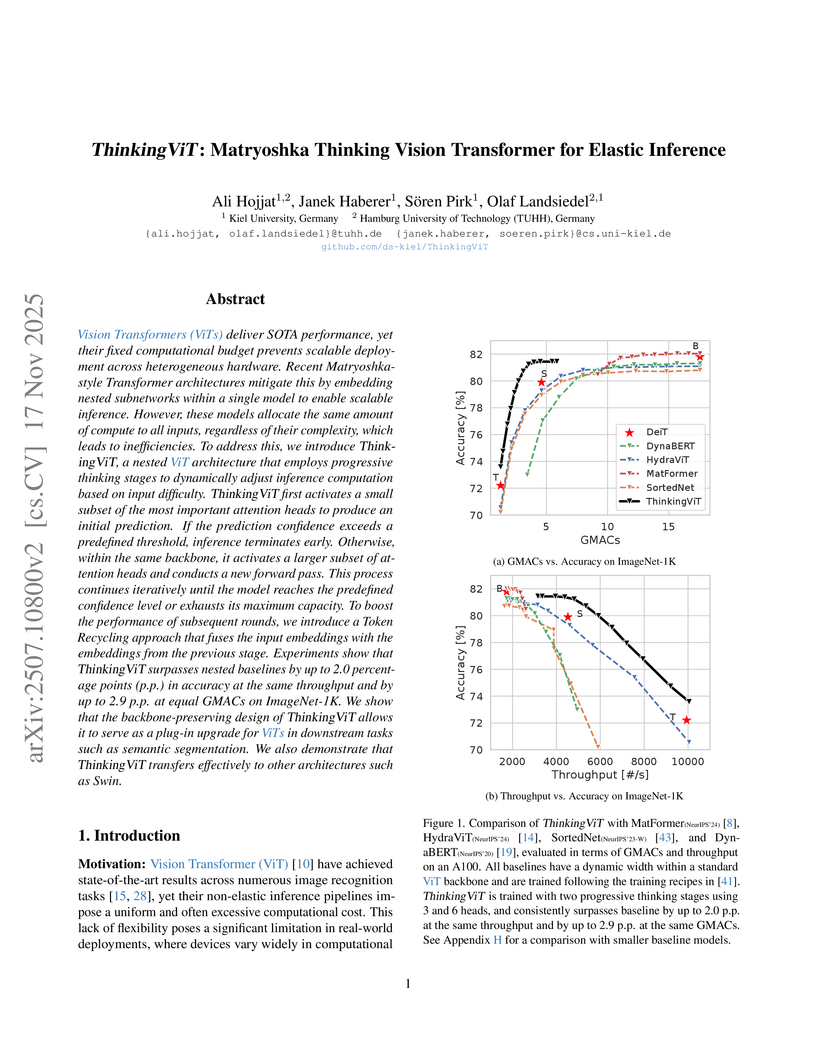
17 Nov 2025
ViTs deliver SOTA performance, yet their fixed computational budget prevents scalable deployment across heterogeneous hardware. Recent Matryoshka-style Transformer architectures mitigate this by embedding nested subnetworks within a single model to enable scalable inference. However, these models allocate the same amount of compute to all inputs, regardless of their complexity, which leads to inefficiencies. To address this, we introduce ThinkingViT, a nested ViT architecture that employs progressive thinking stages to dynamically adjust inference computation based on input difficulty. ThinkingViT first activates a small subset of the most important attention heads to produce an initial prediction. If the prediction confidence exceeds a predefined threshold, inference terminates early. Otherwise, within the same backbone, it activates a larger subset of attention heads and conducts a new forward pass. This process continues iteratively until the model reaches the predefined confidence level or exhausts its maximum capacity. To boost the performance of subsequent rounds, we introduce a Token Recycling approach that fuses the input embeddings with the embeddings from the previous stage. Experiments show that ThinkingViT surpasses nested baselines by up to 2.0 percentage points (p.p.) in accuracy at the same throughput and by up to 2.9 p.p. at equal GMACs on ImageNet-1K. We show that the backbone-preserving design of ThinkingViT allows it to serve as a plug-in upgrade for ViTs in downstream tasks such as semantic segmentation. We also demonstrate that ThinkingViT transfers effectively to other architectures such as Swin. The source code is available at this https URL.

02 Aug 2025

Automated bioacoustic analysis is essential for biodiversity monitoring and conservation, requiring advanced deep learning models that can adapt to diverse bioacoustic tasks. This article presents a comprehensive review of large-scale pretrained bioacoustic foundation models and systematically investigates their transferability across multiple bioacoustic classification tasks. We overview bioacoustic representation learning including major pretraining data sources and benchmarks. On this basis, we review bioacoustic foundation models by thoroughly analysing design decisions such as model architecture, pretraining scheme, and training paradigm. Additionally, we evaluate selected foundation models on classification tasks from the BEANS and BirdSet benchmarks, comparing the generalisability of learned representations under both linear and attentive probing strategies. Our comprehensive experimental analysis reveals that BirdMAE, trained on large-scale bird song data with a self-supervised objective, achieves the best performance on the BirdSet benchmark. On BEANS, BEATs, the extracted encoder of the NatureLM-audio large audio model, is slightly better. Both transformer-based models require attentive probing to extract the full performance of their representations. ConvNext and Perch models trained with supervision on large-scale bird song data remain competitive for passive acoustic monitoring classification tasks of BirdSet in linear probing settings. Training a new linear classifier has clear advantages over evaluating these models without further training. While on BEANS, the baseline model BEATs trained with self-supervision on AudioSet outperforms bird-specific models when evaluated with attentive probing. These findings provide valuable guidance for practitioners selecting appropriate models to adapt them to new bioacoustic classification tasks via probing.

22 Jul 2025
To ensure animal welfare and effective management in pig farming, monitoring individual behavior is a crucial prerequisite. While monitoring tasks have traditionally been carried out manually, advances in machine learning have made it possible to collect individualized information in an increasingly automated way. Central to these methods is the localization of animals across space (object detection) and time (multi-object tracking). Despite extensive research of these two tasks in pig farming, a systematic benchmarking study has not yet been conducted. In this work, we address this gap by curating two datasets: PigDetect for object detection and PigTrack for multi-object tracking. The datasets are based on diverse image and video material from realistic barn conditions, and include challenging scenarios such as occlusions or bad visibility. For object detection, we show that challenging training images improve detection performance beyond what is achievable with randomly sampled images alone. Comparing different approaches, we found that state-of-the-art models offer substantial improvements in detection quality over real-time alternatives. For multi-object tracking, we observed that SORT-based methods achieve superior detection performance compared to end-to-end trainable models. However, end-to-end models show better association performance, suggesting they could become strong alternatives in the future. We also investigate characteristic failure cases of end-to-end models, providing guidance for future improvements. The detection and tracking models trained on our datasets perform well in unseen pens, suggesting good generalization capabilities. This highlights the importance of high-quality training data. The datasets and research code are made publicly available to facilitate reproducibility, re-use and further development.

29 Nov 2024
The rapid growth of camera-based IoT devices demands the need for efficient
video compression, particularly for edge applications where devices face
hardware constraints, often with only 1 or 2 MB of RAM and unstable internet
connections. Traditional and deep video compression methods are designed for
high-end hardware, exceeding the capabilities of these constrained devices.
Consequently, video compression in these scenarios is often limited to M-JPEG
due to its high hardware efficiency and low complexity. This paper introduces ,
an open-source adaptive bitrate video compression model tailored for
resource-limited IoT settings. MCUCoder features an ultra-lightweight encoder
with only 10.5K parameters and a minimal 350KB memory footprint, making it
well-suited for edge devices and MCUs. While MCUCoder uses a similar amount of
energy as M-JPEG, it reduces bitrate by 55.65% on the MCL-JCV dataset and
55.59% on the UVG dataset, measured in MS-SSIM. Moreover, MCUCoder supports
adaptive bitrate streaming by generating a latent representation that is sorted
by importance, allowing transmission based on available bandwidth. This ensures
smooth real-time video transmission even under fluctuating network conditions
on low-resource devices. Source code available at
this https URL

27 Oct 2025
We consider the problem of recovering a latent signal from its noisy observation . The unknown law of , and in particular its support , are accessible only through a large sample of i.i.d.\ observations. We further assume to be a low-dimensional submanifold of a high-dimensional Euclidean space . As a filter or denoiser , we suggest an estimator of the metric projection of onto the manifold . To compute this estimator, we study an auxiliary semiparametric model in which is obtained by adding isotropic Laplace noise to . Using score matching within a corresponding diffusion model, we obtain an estimator of the Bayesian posterior in this setup. Our main theoretical results show that, in the limit of high dimension , this posterior is concentrated near the desired metric projection .

18 May 2025
Deep learning (DL) has greatly advanced audio classification, yet the field
is limited by the scarcity of large-scale benchmark datasets that have
propelled progress in other domains. While AudioSet is a pivotal step to bridge
this gap as a universal-domain dataset, its restricted accessibility and
limited range of evaluation use cases challenge its role as the sole resource.
Therefore, we introduce BirdSet, a large-scale benchmark dataset for audio
classification focusing on avian bioacoustics. BirdSet surpasses AudioSet with
over 6,800 recording hours () from nearly 10,000 classes
() for training and more than 400 hours
() across eight strongly labeled evaluation datasets. It
serves as a versatile resource for use cases such as multi-label
classification, covariate shift or self-supervised learning. We benchmark six
well-known DL models in multi-label classification across three distinct
training scenarios and outline further evaluation use cases in audio
classification. We host our dataset on Hugging Face for easy accessibility and
offer an extensive codebase to reproduce our results.

14 Apr 2025
We address the challenge of constructing a consistent and photorealistic
Neural Radiance Field in inhomogeneously illuminated, scattering environments
with unknown, co-moving light sources. While most existing works on underwater
scene representation focus on a static homogeneous illumination, limited
attention has been paid to scenarios such as when a robot explores water deeper
than a few tens of meters, where sunlight becomes insufficient. To address
this, we propose a novel illumination field locally attached to the camera,
enabling the capture of uneven lighting effects within the viewing frustum. We
combine this with a volumetric medium representation to an overall method that
effectively handles interaction between dynamic illumination field and static
scattering medium. Evaluation results demonstrate the effectiveness and
flexibility of our approach.

15 Jan 2024
Physics-Informed Neural Networks for High-Frequency and Multi-Scale Problems using Transfer Learning
Physics-Informed Neural Networks for High-Frequency and Multi-Scale Problems using Transfer Learning
Physics-informed neural network (PINN) is a data-driven solver for partial and ordinary differential equations(ODEs/PDEs). It provides a unified framework to address both forward and inverse problems. However, the complexity of the objective function often leads to training failures. This issue is particularly prominent when solving high-frequency and multi-scale problems. We proposed using transfer learning to boost the robustness and convergence of training PINN, starting training from low-frequency problems and gradually approaching high-frequency problems. Through two case studies, we discovered that transfer learning can effectively train PINN to approximate solutions from low-frequency problems to high-frequency problems without increasing network parameters. Furthermore, it requires fewer data points and less training time. We elaborately described our training strategy, including optimizer selection, and suggested guidelines for using transfer learning to train neural networks for solving more complex problems.

25 May 2021
While deep learning strategies achieve outstanding results in computer vision tasks, one issue remains: The current strategies rely heavily on a huge amount of labeled data. In many real-world problems, it is not feasible to create such an amount of labeled training data. Therefore, it is common to incorporate unlabeled data into the training process to reach equal results with fewer labels. Due to a lot of concurrent research, it is difficult to keep track of recent developments. In this survey, we provide an overview of often used ideas and methods in image classification with fewer labels. We compare 34 methods in detail based on their performance and their commonly used ideas rather than a fine-grained taxonomy. In our analysis, we identify three major trends that lead to future research opportunities. 1. State-of-the-art methods are scaleable to real-world applications in theory but issues like class imbalance, robustness, or fuzzy labels are not considered. 2. The degree of supervision which is needed to achieve comparable results to the usage of all labels is decreasing and therefore methods need to be extended to settings with a variable number of classes. 3. All methods share some common ideas but we identify clusters of methods that do not share many ideas. We show that combining ideas from different clusters can lead to better performance.

30 Jan 2025
Modern web applications demand scalable and modular architectures, driving the adoption of micro-frontends. This paper introduces Bundler-Independent Module Federation (BIMF) as a New Idea, enabling runtime module loading without relying on traditional bundlers, thereby enhancing flexibility and team collaboration. This paper presents the initial implementation of BIMF, emphasizing benefits such as shared dependency management and modular performance optimization. We address key challenges, including debugging, observability, and performance bottlenecks, and propose solutions such as distributed tracing, server-side rendering, and intelligent prefetching. Future work will focus on evaluating observability tools, improving developer experience, and implementing performance optimizations to fully realize BIMF's potential in micro-frontend architectures.

05 Dec 2024
The architecture of Vision Transformers (ViTs), particularly the Multi-head Attention (MHA) mechanism, imposes substantial hardware demands. Deploying ViTs on devices with varying constraints, such as mobile phones, requires multiple models of different sizes. However, this approach has limitations, such as training and storing each required model separately. This paper introduces HydraViT, a novel approach that addresses these limitations by stacking attention heads to achieve a scalable ViT. By repeatedly changing the size of the embedded dimensions throughout each layer and their corresponding number of attention heads in MHA during training, HydraViT induces multiple subnetworks. Thereby, HydraViT achieves adaptability across a wide spectrum of hardware environments while maintaining performance. Our experimental results demonstrate the efficacy of HydraViT in achieving a scalable ViT with up to 10 subnetworks, covering a wide range of resource constraints. HydraViT achieves up to 5 p.p. more accuracy with the same GMACs and up to 7 p.p. more accuracy with the same throughput on ImageNet-1K compared to the baselines, making it an effective solution for scenarios where hardware availability is diverse or varies over time. Source code available at this https URL.

18 Nov 2025
DNA and other biopolymers are being investigated as new computing substrates and alternative to silicon-based digital computers. However, the established top-down design of biomolecular interaction networks remains challenging and does not fully exploit biomolecular self-assembly capabilities. Outside the field of computation, directed evolution has been used as a tool for goal directed optimization of DNA sequences. Here, we propose integrating directed evolution with DNA-based reservoir computing to enable in-material optimization and adaptation. Simulations of colloidal bead networks connected via DNA strands demonstrate a physical reservoir capable of non-linear time-series prediction tasks, including Volterra series and Mackey-Glass chaotic dynamics. Reservoir computing performance, quantified by normalized mean squared error (NMSE), strongly depends on network topology, suggesting task-specific optimal network configurations. Implementing genetic algorithms to evolve DNA-encoded network connectivity effectively identified well-performing reservoir networks. Directed evolution improved reservoir performance across multiple tasks, outperforming random network selection. Remarkably, sequential training on distinct tasks resulted in reservoir populations maintaining performance on prior tasks. Our findings indicate that DNA-bead networks offer sufficient complexity for reservoir computing, and that directed evolution robustly optimizes performance.

14 Dec 2023
Machine learning has had an enormous impact in many scientific disciplines. Also in the field of low-temperature plasma modeling and simulation it has attracted significant interest within the past years. Whereas its application should be carefully assessed in general, many aspects of plasma modeling and simulation have benefited substantially from recent developments within the field of machine learning and data-driven modeling. In this survey, we approach two main objectives: (a) We review the state-of-the-art focusing on approaches to low-temperature plasma modeling and simulation. By dividing our survey into plasma physics, plasma chemistry, plasma-surface interactions, and plasma process control, we aim to extensively discuss relevant examples from literature. (b) We provide a perspective of potential advances to plasma science and technology. We specifically elaborate on advances possibly enabled by adaptation from other scientific disciplines. We argue that not only the known unknowns, but also unknown unknowns may be discovered due to the inherent propensity of data-driven methods to spotlight hidden patterns in data.

25 Jan 2025
The latest surveys estimate an increasing number of connected Internet-of-Things (IoT) devices (around 16 billion) despite the sector's shortage of manufacturers. All these devices deployed into the wild will collect data to guide decision-making that can be made automatically by other systems, humans, or hybrid approaches. In this work, we conduct an initial investigation of benchmark configuration options for IoT Platforms that process data ingested by such devices in real-time using the MQTT protocol. We identified metrics and related MQTT configurable parameters in the system's component deployment for an MQTT bridge architecture. For this purpose, we benchmark a real-world IoT platform's operational data flow design to monitor the surrounding environment remotely. We consider the MQTT broker solution and the system's real-time ingestion and bridge processing portion of the platform to be the system under test. In the benchmark, we investigate two architectural deployment options for the bridge component to gain insights into the latency and reliability of MQTT bridge deployments in which data is provided in a cross-organizational context. Our results indicate that the number of bridge components, MQTT packet sizes, and the topic name can impact the quality attributes in IoT architectures using MQTT protocol.

12 Mar 2025
Kieker Observability Framework Version 2 evolves to offer comprehensive observability for distributed microservice systems, enabling the collection and processing of metrics, logs, and distributed traces. The framework maintains low overhead and demonstrates interoperability with OpenTelemetry through a reproducible tool artifact, visualizing dynamic architectural behavior.

12 Nov 2025


Isolated rapid eye movement sleep behavior disorder (iRBD) is a major prodromal marker of -synucleinopathies, often preceding the clinical onset of Parkinson's disease, dementia with Lewy bodies, or multiple system atrophy. While wrist-worn actimeters hold significant potential for detecting RBD in large-scale screening efforts by capturing abnormal nocturnal movements, they become inoperable without a reliable and efficient analysis pipeline. This study presents ActiTect, a fully automated, open-source machine learning tool to identify RBD from actigraphy recordings. To ensure generalizability across heterogeneous acquisition settings, our pipeline includes robust preprocessing and automated sleep-wake detection to harmonize multi-device data and extract physiologically interpretable motion features characterizing activity patterns. Model development was conducted on a cohort of 78 individuals, yielding strong discrimination under nested cross-validation (AUROC = 0.95). Generalization was confirmed on a blinded local test set (n = 31, AUROC = 0.86) and on two independent external cohorts (n = 113, AUROC = 0.84; n = 57, AUROC = 0.94). To assess real-world robustness, leave-one-dataset-out cross-validation across the internal and external cohorts demonstrated consistent performance (AUROC range = 0.84-0.89). A complementary stability analysis showed that key predictive features remained reproducible across datasets, supporting the final pooled multi-center model as a robust pre-trained resource for broader deployment. By being open-source and easy to use, our tool promotes widespread adoption and facilitates independent validation and collaborative improvements, thereby advancing the field toward a unified and generalizable RBD detection model using wearable devices.

08 May 2025
Emulating the neural-like information processing dynamics of the brain
provides a time and energy efficient approach for solving complex problems.
While the majority of neuromorphic hardware currently developed rely on large
arrays of highly organized building units, such as in rigid crossbar
architectures, in biological neuron assemblies make use of dynamic transitions
within highly parallel, reconfigurable connection schemes. Neuroscience
suggests that efficiency of information processing in the brain rely on dynamic
interactions and signal propagations which are self-tuned and non-rigid.
Brain-like dynamic and avalanche criticality have already been found in a
variety of self-organized networks of nanoobjects, such as nanoparticles (NP)
or nanowires. Here we report on the dynamics of the electrical spiking signals
from Ag-based self-organized nanoparticle networks (NPNs) at the example of
monometallic Ag NPNs, bimetallic AgAu alloy NPNs and composite Ag/ZrN NPNs,
which combine two distinct NP species. We present time series recordings of the
resistive switching responses in each network and showcase the determination of
switching events as well as the evaluation of avalanche criticality. In each
case, for Ag NPN, AgAu NPN and Ag/ZrN NPN, the agreement of three independently
derived estimates of the characteristic exponent provides evidence for
avalanche criticality. The study shows that Ag-based NPNs offer a broad range
of versatility for integration purposes into physical computing systems without
destroying their critical dynamics, as the composition of these NPNs can be
modified to suit specific requirements for integration.
There are no more papers matching your filters at the moment.
